") 如何使用Docker容器中的TensorFlow目標(biāo)檢測(cè)API
如何使用Docker容器中的TensorFlow目標(biāo)檢測(cè)API
本文展示了如何使用 Docker 容器中的 TensorFlow 目標(biāo)檢測(cè) API,通過網(wǎng)絡(luò)攝像頭執(zhí)行實(shí)時(shí)目標(biāo)檢測(cè),同時(shí)進(jìn)行視頻后處理。作者使用的是 OpenCV 和 Python3 多進(jìn)程和多線程庫。本文重點(diǎn)介紹了項(xiàng)目中出現(xiàn)的問題以及作者采用的解決方案。
完整代碼地址:https://github.com/lbeaucourt/Object-detection
用 YouTube 視頻進(jìn)行視頻處理測(cè)試
動(dòng)機(jī)
我是從這篇文章《Building a Real-Time Object Recognition App with Tensorflow and OpenCV》(https://towardsdatascience.com/building-a-real-time-object-recognition-app-with-tensorflow-and-opencv-b7a2b4ebdc32)開始探索實(shí)時(shí)目標(biāo)檢測(cè)問題,這促使我研究 Python 多進(jìn)程庫,使用這篇文章(https://www.pyimagesearch.com/2015/12/21/increasing-webcam-fps-with-python-and-opencv/)中介紹的方法提高每秒幀數(shù)(frames per second,F(xiàn)PS)。為了進(jìn)一步加強(qiáng)項(xiàng)目的可移植性,我試著將自己的項(xiàng)目整合到 Docker 容器中。這一過程的主要困難在于處理流入和流出容器的視頻流。
此外,我還在項(xiàng)目中添加了視頻后處理功能,這一功能也使用了多進(jìn)程,以減少視頻處理的時(shí)間(如果使用原始的 TensorFlow 目標(biāo)檢測(cè) API 處理視頻,會(huì)需要非常非常長(zhǎng)的時(shí)間)。
在我的個(gè)人電腦上可以同時(shí)進(jìn)行高性能的實(shí)時(shí)目標(biāo)檢測(cè)和視頻后處理工作,該過程僅使用了 8GB 的 CPU。
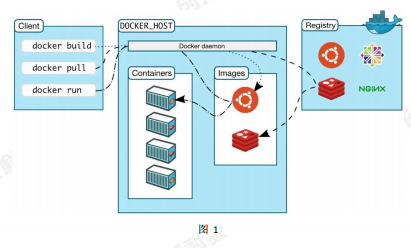
用于數(shù)據(jù)科學(xué)的 Docker
鑒于大量文章對(duì) TensorFlow 目標(biāo)檢測(cè) API 的實(shí)現(xiàn)進(jìn)行了說明,因此此處不再贅述。作為一名數(shù)據(jù)科學(xué)家,我將展示如何在日常工作中使用 Docker。請(qǐng)注意,我用的是來自 Tensorflow 的經(jīng)典 ssd_mobilenet_v2_coco 模型。我在本地復(fù)制了模型(.pb 文件)和對(duì)應(yīng)的標(biāo)簽映射,以便后續(xù)個(gè)人模型的運(yùn)行。
我相信現(xiàn)在使用 Docker 已經(jīng)是數(shù)據(jù)科學(xué)家最基礎(chǔ)的技能了。在數(shù)據(jù)科學(xué)和機(jī)器學(xué)習(xí)的世界中,每周都會(huì)發(fā)布許多新的算法、工具和程序,在個(gè)人電腦上安裝并測(cè)試它們很容易讓系統(tǒng)崩潰(親身經(jīng)歷!)。為了防止這一悲慘事件的發(fā)生,我現(xiàn)在用 Docker 創(chuàng)建數(shù)據(jù)科學(xué)工作空間。
你可以在我的庫中找到該項(xiàng)目的相關(guān) Docker 文件。以下是我安裝 TensorFlow 目標(biāo)檢測(cè)的方法(按照官方安裝指南進(jìn)行):
# Install tensorFlow RUN pip install -U tensorflow # Install tensorflow models object detection RUN git clone https://github.com/tensorflow/models /usr/local/lib/python3.5/dist-packages/tensorflow/models RUN apt-get install -y protobuf-compiler python-pil python-lxml python-tk #Set TF object detection available ENV PYTHONPATH "$PYTHONPATH:/usr/local/lib/python3.5/dist-packages/tensorflow/models/research:/usr/local/lib/python3.5/dist-packages/tensorflow/models/research/slim" RUN cd /usr/local/lib/python3.5/dist-packages/tensorflow/models/research && protoc object_detection/protos/*.proto --python_out=.
同樣,我還安裝了 OpenCV:
# Install OpenCV RUN git clone https://github.com/opencv/opencv.git /usr/local/src/opencv RUN cd /usr/local/src/opencv/ && mkdir build RUN cd /usr/local/src/opencv/build && cmake -D CMAKE_INSTALL_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local/ .. && make -j4 && make install
建立圖像會(huì)花幾分鐘的時(shí)間,但是之后用起來就會(huì)又快又容易。
實(shí)時(shí)目標(biāo)檢測(cè)
首先我試著將目標(biāo)檢測(cè)應(yīng)用于網(wǎng)絡(luò)攝像頭視頻流。《Building a Real-Time Object Recognition App with Tensorflow and OpenCV》完整地介紹了這項(xiàng)工作的主體部分。困難在于如何將網(wǎng)絡(luò)攝像頭視頻流傳送到 Docker 容器 中,并使用 X11 服務(wù)器恢復(fù)輸出流,使視頻得以顯示出來。
將視頻流傳送到容器中
使用 Linux 的話,設(shè)備在 /dev/ 目錄中,而且通常可以作為文件進(jìn)行操作。一般而言,你的筆記本電腦攝像頭是「0」設(shè)備。為了將視頻流傳送到 docker 容器中,要在運(yùn)行 docker 圖像時(shí)使用設(shè)備參數(shù):
docker run --device=/dev/video0
對(duì) Mac 和 Windows 用戶而言,將網(wǎng)絡(luò)攝像頭視頻流傳送到容器中的方法就沒有 Linux 那么簡(jiǎn)單了(盡管 Mac 是基于 Unix 的)。本文并未對(duì)此進(jìn)行詳細(xì)敘述,但 Windows 用戶可以使用 Virtual Box 啟動(dòng) docker 容器來解決該問題。
從容器中恢復(fù)視頻流
解決這個(gè)問題時(shí)花了我一些時(shí)間(但解決方案仍舊不盡如人意)。我在 http://wiki.ros.org/docker/Tutorials/GUI 網(wǎng)頁發(fā)現(xiàn)了一些使用 Docker 圖形用戶界面的有用信息,尤其是將容器和主機(jī)的 X 服務(wù)器連接,以顯示視頻。
首先,你必須要放開 xhost 權(quán)限,這樣 docker 容器才能通過讀寫進(jìn) X11 unix socket 進(jìn)行正確顯示。首先要讓 docker 獲取 X 服務(wù)器主機(jī)的權(quán)限(這并非最安全的方式):
xhost +local:docker
在成功使用該項(xiàng)目后,再將控制權(quán)限改回默認(rèn)值:
xhost -local:docker
創(chuàng)建兩個(gè)環(huán)境變量 XSOCK 和 XAUTH:
XSOCK=/tmp/.X11-unix XAUTH=/tmp/.docker.xauth
XSOCK 指 X11 Unix socket,XAUTH 指具備適當(dāng)權(quán)限的 X 認(rèn)證文件:
xauth nlist $DISPLAY | sed -e 's/^..../ffff/' | xauth -f $XAUTH nmerge -
最后,我們還要更新 docker 運(yùn)行的命令行。我們發(fā)送 DISPLAY 環(huán)境變量,為 X11 Unix socket 和帶有環(huán)境變量 XAUTHORITY 的 X 認(rèn)證文件安裝卷:
docker run -it --rm --device=/dev/video0 -e DISPLAY=$DISPLAY -v $XSOCK:$XSOCK -v $XAUTH:$XAUTH -e XAUTHORITY=$XAUTH
現(xiàn)在我們可以運(yùn)行 docker 容器了,而它完成后是這樣的:
工作中的我和其他物體(因?yàn)楹π呔筒宦赌樍耍?/p>
盡管主機(jī)配置有 X 服務(wù)器,但我還是無法完全刪除我代碼中疑似錯(cuò)誤的部分。OpenCV 需要通過調(diào)用 Python 腳本使用 cv2.imshow 函數(shù)進(jìn)行「初始化」。我收到了以下錯(cuò)誤信息:
The program 'frame' received an X Window System error.
然后,我可以調(diào)用 Python 主腳本(my-object-detection.py),視頻流也可以發(fā)送到主機(jī)的顯示器了。我對(duì)使用第一個(gè) Python 腳本初始化 X11 系統(tǒng)的解決方法并不十分滿意,但是我尚未發(fā)現(xiàn)其他可以解決這一問題的辦法。
視頻處理
為了成功用網(wǎng)絡(luò)攝像頭實(shí)時(shí)運(yùn)行目標(biāo)檢測(cè) API,我用了線程和多進(jìn)程 Python 庫。線程用來讀取網(wǎng)絡(luò)攝像頭的視頻流,幀按隊(duì)列排列,等待一批 worker 進(jìn)行處理(在這個(gè)過程中 TensorFlow 目標(biāo)檢測(cè)仍在運(yùn)行)。
就視頻處理而言,使用線程是不可能的,因?yàn)楸仨毾茸x取所有視頻幀,worker 才能對(duì)輸入隊(duì)列中的第一幀視頻應(yīng)用目標(biāo)檢測(cè)。當(dāng)輸入隊(duì)列滿了時(shí),后面讀取的視頻幀會(huì)丟失。也許使用大量 worker 和多個(gè)隊(duì)列可以解決這一問題(但會(huì)產(chǎn)生大量的計(jì)算損失)。
簡(jiǎn)單隊(duì)列的另一個(gè)問題是,由于分析時(shí)間不斷變化,輸出隊(duì)列中的視頻幀無法以與輸入隊(duì)列相同的順序發(fā)布。
為了添加視頻處理功能,我刪除了讀取視頻幀的線程,而是通過以下代碼來讀取視頻幀:
while True: # Check input queue is not full if not input_q.full(): # Read frame and store in input queue ret, frame = vs.read() if ret: input_q.put((int(vs.get(cv2.CAP_PROP_POS_FRAMES)),frame))
如果輸入隊(duì)列未滿,則接下來會(huì)從視頻流中讀取下一個(gè)視頻幀,并將其放到隊(duì)列中去。否則輸入隊(duì)列中沒有視頻幀是不會(huì)進(jìn)行任何處理的。
為了解決視頻幀順序的問題,我使用優(yōu)先級(jí)隊(duì)列作為第二輸出隊(duì)列:
1. 讀取視頻幀,并將視頻幀及其對(duì)應(yīng)的編號(hào)一并放到輸入隊(duì)列中(實(shí)際上是將 Python 列表對(duì)象放到隊(duì)列中)。
2.然后,worker 從輸入隊(duì)列中取出視頻幀,對(duì)其進(jìn)行處理后再將其放入第一個(gè)輸出隊(duì)列(仍帶有相關(guān)的視頻幀編號(hào))。
while True: frame = input_q.get() frame_rgb = cv2.cvtColor(frame[1], cv2.COLOR_BGR2RGB) output_q.put((frame[0], detect_objects(frame_rgb, sess, detection_graph)))
3. 如果輸出隊(duì)列不為空,則提取視頻幀,并將視頻幀及其對(duì)應(yīng)編號(hào)一起放入優(yōu)先級(jí)隊(duì)列,視頻編號(hào)即為優(yōu)先級(jí)編號(hào)。優(yōu)先級(jí)隊(duì)列的規(guī)模被設(shè)置為其他隊(duì)列的三倍。
# Check output queue is not empty if not output_q.empty(): # Recover treated frame in output queue and feed priority queue output_pq.put(output_q.get())
4. 最后,如果輸出優(yōu)先級(jí)隊(duì)列不為空,則取出優(yōu)先級(jí)最高(優(yōu)先級(jí)編號(hào)最小)的視頻(這是標(biāo)準(zhǔn)優(yōu)先級(jí)隊(duì)列的運(yùn)作)。如果優(yōu)先級(jí)編號(hào)與預(yù)期視頻幀編號(hào)一致,則將這一幀添加到輸出視頻流中(如果有需要的話將這一幀寫入視頻流),不一致的話則將這一幀放回優(yōu)先級(jí)隊(duì)列中。
# Check output priority queue is not empty if not output_pq.empty(): prior, output_frame = output_pq.get() if prior > countWriteFrame: output_pq.put((prior, output_frame)) else: countWriteFrame = countWriteFrame + 1 # Do something with your frame
要停止該進(jìn)程,需要檢查所有的隊(duì)列是否為空,以及是否從該視頻流中提取出所有的視頻了。
if((not ret) & input_q.empty() & output_q.empty() & output_pq.empty()): break
總結(jié)
本文介紹了如何使用 docker 和 TensorFlow 實(shí)現(xiàn)實(shí)時(shí)目標(biāo)檢測(cè)項(xiàng)項(xiàng)目。如上文所述,docker 是測(cè)試新數(shù)據(jù)科學(xué)工具最安全的方式,也是我們提供給客戶打包解決方案最安全的方式。本文還展示了如何使用《Building a Real-Time Object Recognition App with Tensorflow and OpenCV》中的原始 Python 腳本執(zhí)行多進(jìn)程視頻處理。
原文鏈接:https://towardsdatascience.com/real-time-and-video-processing-object-detection-using-tensorflow-opencv-and-docker-2be1694726e5
責(zé)任編輯:xj
原文標(biāo)題:教程 | 如何使用Docker、TensorFlow目標(biāo)檢測(cè)API和OpenCV實(shí)現(xiàn)實(shí)時(shí)目標(biāo)檢測(cè)和視頻處理
文章出處:【微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
OpenCV
+關(guān)注
關(guān)注
30文章
628瀏覽量
41264 -
python
+關(guān)注
關(guān)注
56文章
4782瀏覽量
84453 -
tensorflow
+關(guān)注
關(guān)注
13文章
328瀏覽量
60499 -
Docker
+關(guān)注
關(guān)注
0文章
454瀏覽量
11814
原文標(biāo)題:教程 | 如何使用Docker、TensorFlow目標(biāo)檢測(cè)API和OpenCV實(shí)現(xiàn)實(shí)時(shí)目標(biāo)檢測(cè)和視頻處理
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
ARM平臺(tái)實(shí)現(xiàn)Docker容器技術(shù)
ARM平臺(tái)實(shí)現(xiàn)Docker容器技術(shù)
Jtti:Docker會(huì)替代調(diào)虛機(jī)嗎

keras模型轉(zhuǎn)tensorflow session
關(guān)于Docker 的清理命令集錦
基于全志T113-i的Docker容器實(shí)現(xiàn)方案
Docker容器技術(shù)的安裝和使用
OpenVINO? Java API應(yīng)用RT-DETR做目標(biāo)檢測(cè)器實(shí)戰(zhàn)
Docker容器實(shí)現(xiàn)開機(jī)自動(dòng)啟動(dòng)策略
ARM平臺(tái)實(shí)現(xiàn)Docker容器技術(shù)

【飛騰派4G版免費(fèi)試用】第二章:在PC端使用 TensorFlow2 訓(xùn)練目標(biāo)檢測(cè)模型
【飛騰派4G版免費(fèi)試用】 第二章:在PC端使用 TensorFlow2 訓(xùn)練目標(biāo)檢測(cè)模型
Windows Docker部署Redis的流程






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論