 基于深度學習YOLO系列算法的圖像檢測
基于深度學習YOLO系列算法的圖像檢測
目前,基于深度學習算法的一系列目標檢測算法大致可以分為兩大流派:
兩步走(two-stage)算法:先產生候選區域然后再進行CNN分類(RCNN系列)
一步走(one-stage)算法:直接對輸入圖像應用算法并輸出類別和相應的定位(YOLO系列)
1YOLO算法的提出
在圖像的識別與定位中,輸入一張圖片,要求輸出其中所包含的對象,以及每個對象的位置(包含該對象的矩形框)。
對象的識別和定位,可以看成兩個任務:找到圖片中某個存在對象的區域,然后識別出該區域中具體是哪個對象。對象識別這件事(一張圖片僅包含一個對象,且基本占據圖片的整個范圍),最近幾年基于CNN卷積神經網絡的各種方法已經能達到不錯的效果了。所以主要需要解決的問題是,對象在哪里。最簡單的想法,就是遍歷圖片中所有可能的位置,地毯式搜索不同大小,不同寬高比,不同位置的每個區域,逐一檢測其中是否存在某個對象,挑選其中概率最大的結果作為輸出。
顯然這種方法效率太低。RCNN開創性的提出了候選區(Region Proposals)的方法,先從圖片中搜索出一些可能存在對象的候選區(Selective Search),大概2000個左右,然后對每個候選區進行對象識別,總體來說,RCNN系列依然是兩階段處理模式:先提出候選區,再識別候選區中的對象,大幅提升了對象識別和定位的效率。不過RCNN的速度依然很慢,其處理一張圖片大概需要49秒。因此又有了后續的Fast RCNN 和 Faster RCNN,針對 RCNN的神經網絡結構和候選區的算法不斷改進,Faster RCNN已經可以達到一張圖片約0.2秒的處理速度。
R-CNN系列雖然準確率比較高,但是即使是發展到Faster R-CNN,檢測一張圖片如下圖所示也要7fps(原文為5fps),為了使得檢測的工作能夠用到實時的場景中,提出了YOLO。
2 算法的簡介
YOLO意思是You Only Look Once,創造性的將候選區和對象識別這兩個階段合二為一,看一眼圖片(不用看兩眼哦)就能知道有哪些對象以及它們的位置。
實際上,YOLO并沒有真正去掉候選區,而是采用了預定義的候選區(準確點說應該是預測區,因為并不是Faster RCNN所采用的Anchor)。也就是將圖片劃分為 7*7=49 個網格(grid),每個網格允許預測出2個邊框(bounding box,包含某個對象的矩形框),總共 49*2=98 個bounding box。可以理解為98個候選區,它們很粗略的覆蓋了圖片的整個區域。
RCNN雖然會找到一些候選區,但畢竟只是候選,等真正識別出其中的對象以后,還要對候選區進行微調,使之更接近真實的bounding box。這個過程就是邊框回歸:將候選區bounding box調整到更接近真實的bounding box。既然反正最后都是要調整的,干嘛還要先費勁去尋找候選區呢,大致有個區域范圍就行了,所以YOLO就這么干了。
邊框回歸為什么能起作用,本質上是因為分類信息中已經包含了位置信息。就像你看到一只貓的臉和身體,就能推測出耳朵和屁股的位置。
3 算法的結構
去掉候選區這個步驟以后,YOLO的結構非常簡單,就是單純的卷積、池化最后加了兩層全連接。單看網絡結構的話,和普通的CNN對象分類網絡幾乎沒有本質的區別,最大的差異是最后輸出層用線性函數做激活函數,因為需要預測bounding box的位置(數值型),而不僅僅是對象的概率。所以粗略來說,YOLO的整個結構就是輸入圖片經過神經網絡的變換得到一個輸出的張量,如下圖所示。
4 輸入輸出映射關系
因為只是一些常規的神經網絡結構,所以,理解YOLO的設計的時候,重要的是理解輸入和輸出的映射關系。
參考圖5,輸入就是原始圖像,唯一的要求是縮放到448*448的大小。主要是因為YOLO的網絡中,卷積層最后接了兩個全連接層,全連接層是要求固定大小的向量作為輸入,所以倒推回去也就要求原始圖像有固定的尺寸。那么YOLO設計的尺寸就是448*448。輸出是一個 7*7*30 的張量(tensor)。根據YOLO的設計,輸入圖像被劃分為 7*7 的網格(grid),輸出張量中的 7*7 就對應著輸入圖像的 7*7 網格。或者我們把 7*7*30 的張量看作 7*7=49個30維的向量,也就是輸入圖像中的每個網格對應輸出一個30維的向量。參考上面圖5,比如輸入圖像左上角的網格對應到輸出張量中左上角的向量。
要注意的是,并不是說僅僅網格內的信息被映射到一個30維向量。經過神經網絡對輸入圖像信息的提取和變換,網格周邊的信息也會被識別和整理,最后編碼到那個30維向量中。
具體來看每個網格對應的30維向量中包含了哪些信息。
① 20個對象分類的概率
因為YOLO支持識別20種不同的對象(人、鳥、貓、汽車、椅子等),所以這里有20個值表示該網格位置存在任一種對象的概率。也對應為20個object條件概率。
② 2個bounding box的位置
每個bounding box需要4個數值來表示其位置,(Center_x,Center_y,width,height),即(bounding box的中心點的x坐標,y坐標,bounding box的寬度,高度),2個bounding box共需要8個數值來表示其位置。
③ 2個bounding box的置信度
bounding box的置信度 = 該bounding box內存在對象的概率 * 該bounding box與該對象實際bounding box的IOU, IOU=交集部分面積/并集部分面積,2個box完全重合時IOU=1,不相交時IOU=0。
綜合來說,一個bounding box的置信度Confidence意味著它 是否包含對象且位置準確的程度。置信度高表示這里存在一個對象且位置比較準確,置信度低表示可能沒有對象 或者 即便有對象也存在較大的位置偏差。作為監督學習,我們需要先構造好訓練樣本,才能讓模型從中學習。對于一張輸入圖片,其對應輸出的7*7*30張量(也就是通常監督學習所說的標簽y或者label)應該填寫什么數據呢。
首先,輸出的 7*7維度 對應于輸入的 7*7 網格。
① 20個對象分類的概率
② 2個bounding box的位置
③ 2個bounding box的置信度
(請對照上面圖6)
5 損失函數
損失就是網絡實際輸出值與樣本標簽值之間的偏差。
YOLO給出的損失函數如下。
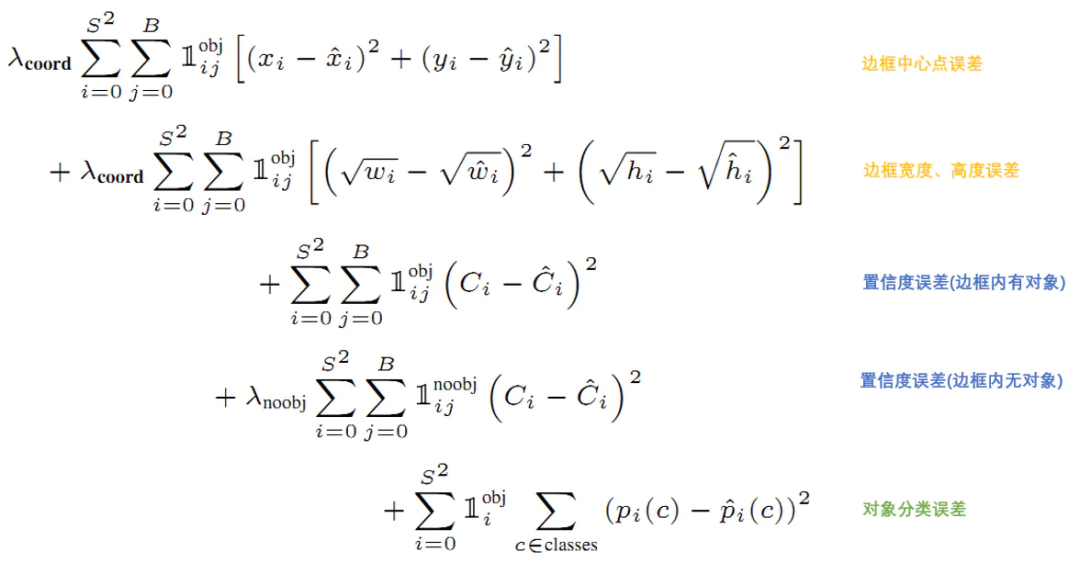
6 預測
訓練好的YOLO網絡,輸入一張圖片,將輸出一個 7*7*30 的張量(tensor)來表示圖片中所有網格包含的對象(概率)以及該對象可能的2個位置(bounding box)和可信程度(置信度)。為了從中提取出最有可能的那些對象和位置,YOLO采用NMS(Non-maximal suppression,非極大值抑制)算法。
7 總結
YOLO以速度見長,處理速度可以達到45fps,其YoloV4版本(網絡較小)甚至可以達到155fps。這得益于其識別和定位合二為一的網絡設計,而且這種統一的設計也使得訓練和預測可以端到端的進行,非常簡便。不足之處是小對象檢測效果不太好(尤其是一些聚集在一起的小對象),對邊框的預測準確度不是很高,總體預測精度略低于Fast RCNN。主要是因為網格設置比較稀疏,而且每個網格只預測兩個邊框,另外Pooling層會丟失一些細節信息,對定位存在影響。
責任編輯:xj
原文標題:基于YOLO系列算法的圖像檢測
文章出處:【微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
-
算法
+關注
關注
23文章
4599瀏覽量
92643 -
圖像檢測
+關注
關注
0文章
33瀏覽量
11866 -
深度學習
+關注
關注
73文章
5492瀏覽量
120977
原文標題:基于YOLO系列算法的圖像檢測
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
《DNK210使用指南 -CanMV版 V1.0》第四十一章 YOLO2物體檢測實驗
《DNK210使用指南 -CanMV版 V1.0》第四十章 YOLO2人手檢測實驗
深度識別算法包括哪些內容
opencv圖像識別有什么算法
利用Matlab函數實現深度學習算法
深度學習在工業機器視覺檢測中的應用
基于深度學習的小目標檢測
深度學習的基本原理與核心算法
基于深度學習的缺陷檢測方案
深度解析深度學習下的語義SLAM

基于機器視覺和深度學習的焊接質量檢測系統

基于YOLO技術的植物檢測與計數





 工商網監
工商網監
評論