 條件生成對抗模型生成數字圖片的教程
條件生成對抗模型生成數字圖片的教程
在上個數字識別的例子中,我們使用了一個簡單的3層神經網絡來識別給定圖片的中的數字。
這次我們在上次的例子中在提升一下,這次我們選用條件生成對抗模型(Conditional Generative Adversarial Networks)來生成數字圖片。
下面就讓我們開始吧!
第一步:import 我們需要的數據庫
%matplotlib inline
from __future__ import print_function, division
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import matplotlib.cm as cm
import seaborn as sns
sns.set_style('white')
from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply
from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam, SGD
第二步:數據預處理
在上個例子中,我們使用的是28*28的二值圖像,也就是說像素只有0和1,0表示黑色,1表示白色。
在上個例子中,我們使用28*28的灰度圖像,每個像素的值都是從0~255的數值,值越大,越接近白色。
2.1 數據加載函數
首先定義一個數據加載函數 load_data 用來加載數據。
不同于上一個例子,我們的數據存放在 npz 文件中,numpy 提供了 load 接口可以直接讀取。
通過函數的輸出我們就可以看到,npz文件里的內容是 x_traln , y_traln , x_test , y_ test 。
這幾個內容標簽分別對應訓練圖片數據,訓練圖片數據的 label,測試圖片數據,測試圖片數據的 label。
def load_data():
data = np.load('mnist.npz')
print(data.files)
x_train = data['x_train']
y_train = data['y_train']
x_test = data['x_test']
y_test = data['y_test']
x_train = (x_train.astype(np.float32) - 127.5) / 127.5
x_train = np.expand_dims(x_train, axis=3)
y_train = y_train.reshape(-1, 1)
return (x_train, y_train), (x_test, y_test)
(x_train, y_train), (x_test, y_test)=load_data()
2.2 數據查看
在任何模型建立之前,常規的操作是先查看數據的情況,比如數據集的大小,訓練集和測試集的數據數量,標簽的數據數量分布等等。
2.2.1 查看原始數據的緯度
訓練集有60000條數據,測試集有100000條數據,并且每一條數據有28*28的圖片像素數據。
print(x_train.shape)
print(x_test.shape)
2.2.2 查看標簽的數量
通過查看訓練標簽跟測試標簽的數量,我們可以觀察到,訓練和測試的數據集跟訓練和測試的標簽在數量上是一一對應的。這也是我么想要的結果,表示我們的數據集是完整的。
print(y_train.shape)
print(y_test.shape)
2.2.3 查看所有的標簽種類
可以看出標簽表示了從0-9的數字,沒有其他的錯誤數據。
np.unique(y_train)
np.unique(y_test)
2.3數據可視化
接下來我隨機的選取一些我們已經轉換好的圖片數據,用 matplot 來查看下,標簽和圖片是否一致。
plt.figure(figsize=(15, 9))
for i in range(50):
random_selection = np.random.randint(0, 500)
plt.subplot(5, 10, 1+i)
plt.title(y_train[random_selection])
plt.imshow(x_train[random_selection][:,:,0], cmap=cm.gray)
2.4 查看數據是否平衡
分類的設計都是基于類分布大致平衡這一假設,通常假定用于訓練的數據集是平衡的,即各類所含的樣本數大致相當。
均勻的數據分布,將會提高模型的精度。如果數據不均勻,我么就要考慮進行平衡處理,常用的處理方式包括采樣、加權、數據合成等。
我們看下標簽的分布情況,看下每個標簽種類的數據量是否分布均勻。
在 MNIST 數據集中,我們的數據是比較均勻分布的。
sns.distplot(y_train, kde=False, bins=10)
第三步:構建模型
3.1接下來讓我們定義模型:
我們選用的是條件生成對抗模型(Conditional Generative Adversarial Networks)
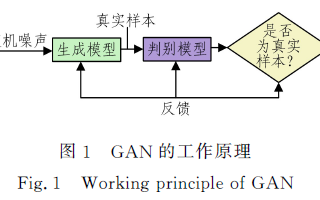
首先先讓我們來認識下基本的生成對抗模型(Generative Adversarial Networks)的架構
我們的輸入數據分成兩個,一個是真實的圖片,一個是噪聲圖片。
首先,噪聲圖片輸入到生成模型中,通過生成模型輸出一張假的圖片,然后我們同時將得到的假的圖片跟真實的圖片輸入到判別模型中,通過判別模型,我們輸出一個預測的標簽。
這個是最基本的GAN的模型流程。
3.2 條件生成對抗模型(Conditional Generative Adversarial Networks)
從基本的生成對抗模型(Generative Adversarial Networks)模型中我們看到,輸入的只是一張隨機的噪聲圖片,并沒有指定這個噪聲圖片對應的標簽的任何信息。
那么在我們的這個例子里,我們希望輸入的噪聲圖片,是指定的一個數字的標簽,并且在通過GAN模型以后,能夠輸出對于我們輸入標簽的數字圖片。
因此我們需要在他的基礎上做些修改,這個模型就是我們這次使用的模型,叫做條件生成對抗模型(Conditional Generative Adversarial Networks)。
模型示意圖
可以看到我們做了如下修改:
我們在生成網絡的輸入數據中加入了我們的隨機噪聲圖片所對應的標簽,
我們在判別網絡中加入了,真實圖片所對應的標簽。
3.3 定義網絡
下面讓我們來定義我們需要的模型
3.3.1先定義一些常量
# 輸入圖片數據的維度
img_shape = (28, 28, 1)
# 圖片通道數
channels = 1
# 標簽數目
num_classes = 10
# 噪聲圖片的輸入維度
latent_dim = 100
3.3.2 定義優化器
這里我們使用的優化器是Adam(Adaptive Moment Estimation)
Adam 是一種可以替代傳統隨機梯度下降(SGD)過程的一階優化算法,它能基于訓練數據迭代地更新神經網絡權重。
Adam最開始是由OpenAI的Diederik Kingma和多倫多大學的Jimmy Ba在提交到2015年ICLR論文(Adam: A Method for Stochastic Optimization)中提出的。
Adam優化器有以下特點:
1.實現簡單,計算高效,對內存需求少
2.參數的更新不受梯度的伸縮變換影響
3.超參數具有很好的解釋性,且通常無需調整或僅需很少的微調
4.更新的步長能夠被限制在大致的范圍內(初始學習率)
5.能自然地實現步長退火過程(自動調整學習率)
6.很適合應用于大規模的數據及參數的場景
7.適用于不穩定目標函數
8.適用于梯度稀疏或梯度存在很大噪聲的問題
optimizer = Adam(0.0002, 0.5)
3.3.3 定義生成模型
def build_generator():
model = Sequential()
model.add(Dense(256, input_dim=latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(img_shape), activation='tanh'))
model.add(Reshape(img_shape))
model.summary()
noise = Input(shape=(latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(num_classes, latent_dim)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
return Model([noise, label], img)
3.3.4 定義判別模型
def build_discriminator():
model = Sequential()
model.add(Dense(512, input_dim=np.prod(img_shape)))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.4))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.4))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=img_shape)
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(num_classes, np.prod(img_shape))(label))
flat_img = Flatten()(img)
model_input = multiply([flat_img, label_embedding])
validity = model(model_input)
return Model([img, label], validity)
在上面的生成模型跟判別模型中,我們使用了幾個新的網絡, LeakyReLU, Dropout, BatchNormalization。
下面我們對這些層次進行一些簡單的說明跟介紹。
3.4 帶泄露修正線性單元(Leaky ReLU)
在上一個數字識別的例子中, 我們使用了線性整流函數(Rectified Linear Unit)就是我們常說的 ReLU 來作為激活函數。
我們也同時介紹了它的優缺點,其中一個重要的缺點就是前向傳播過程中,在x<0時,神經元保持非激活狀態。
這樣會導致權重無法得到更新,也就是網絡無法學習,為了解決 Relu 函數這個缺點,在 Relu 函數的負半區間引入一個泄露(Leaky)值, 使得ReLU在這個區間不為零。因此 Leaky ReLU 的圖像如下, 通過參數a來控制函數負半區的值。
3.5 Dropout
在機器學習的模型中,如果模型的參數太多,而訓練樣本又太少,訓練出來的模型很容易產生過擬合的現象, 具體表現在模型在訓練數據上損失函數較小,預測準確率較高。
但是在測試數據上損失函數比較大,預測準確率較低。為了解決過擬合問題,Hinton在其論文《Improving neural networks by preventing co-adaptation of feature detectors》中提出了 Dropout 。
Dropout 的工作原理是我們在前向傳播的時候,讓某個神經元的激活值以一定的概率停止工作,這樣可以使模型泛化性更強,因為它不會太依賴某些局部的特征。
它的工作的可視化表示如下圖所示:
Dropout 可以有效的防止模型過擬合。
3.6 Batch Normallzatlon
機器學習領域有個很重要的假設:IID獨立同分布假設,就是假設訓練數據和測試數據是滿足相同分布的,這是通過訓練數據獲得的模型能夠在測試集獲得好的效果的一個基本保障。
Batch Normalization就是在深度神經網絡訓練過程中使得每一層神經網絡的輸入保持相同分布。
基本思想其實相當直觀:因為深層神經網絡在做非線性變換前的激活輸入值隨著網絡深度加深或者在訓練過程中,其分布逐漸發生偏移或者變動,之所以訓練收斂慢,一般是整體分布逐漸往非線性函數的取值區間的上下限兩端靠近(參考Sigmoid函數),所以這導致反向傳播時低層神經網絡的梯度消失,這是訓練深層神經網絡收斂越來越慢的本質原因。
而 Batch Normalization 就是通過一定的規范化手段,把每層神經網絡任意神經元這個輸入值的分布強行拉回到均值為0方差為1的標準正態分布,其實就是把越來越偏的分布強制拉回比較標準的分布。
這樣使得激活輸入值落在非線性函數對輸入比較敏感的區域,這樣輸入的小變化就會導致損失函數較大的變化,意思是這樣讓梯度變大,避免梯度消失問題產生,而且梯度變大意味著學習收斂速度快,能大大加快訓練速度
Batch Normalization有如下幾個有特點:
1.使得網絡中每層輸入數據的分布相對穩定,加速模型學習速度
2.使得模型對網絡中的參數不那么敏感,簡化調參過程,使得網絡學習更加穩定
3.允許網絡使用飽和性激活函數(例如sigmoid,tanh等),緩解梯度消失問題
4.具有一定的正則化效果
3.7 定義中間結果顯示函數
這個函數主要用于在訓練的時候,顯示當前模型的預測情況,其中epoch這個參數表示當前第幾個 epoch,generator 表示生成函數模型。
我們將查看當前 epoch 時,生成模型對于0-9這個幾個數字的生成情況。
函數中,我們使用 numpy 產生一個0-9的標簽數組,并且對每個0-9的數字產生一個噪聲圖片的數組,然后我們將噪聲圖片,以及對應的標簽交給生成模型預測。將產生的結果,用 matplot 分兩行繪制在一張圖片內。
其中上面是0,1,2,3,4,下面是5,6,7,8,9, 并且將這張圖片保存在images文件夾中, 文件名為當前 epoch,然后我們用 matplot 將這個圖像顯示jupyter上,方便查看。
def sample_images(epoch, generator):
print("第%d個epoch的預測結果" % epoch)
# 2行,5列
r, c = 2, 5
# 噪聲圖片
noise = np.random.normal(0, 1, (r * c, 100))
# 噪聲圖片對應的標簽
sampled_labels = np.arange(0, 10).reshape(-1, 1)
# 用生成模型預測結果
gen_imgs = generator.predict([noise, sampled_labels])
gen_imgs = 0.5 * gen_imgs + 0.5
# 將結果繪制在一張圖片上并保存
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
# 我們繪制的時灰度圖片
axs[i,j].imshow(gen_imgs[cnt,:,:,0], cmap='gray')
# 將結果圖片的標簽頁繪制在結果圖片的上方
axs[i,j].set_title("%d" % sampled_labels[cnt])
# 關閉坐標軸
axs[i,j].axis('off')
cnt += 1
#保存圖片
fig.savefig("images/epoch_%d.png" % epoch)
plt.close()
# 讀取剛才的圖片,并顯示在jupyter上
img = mpimg.imread('images/epoch_%d.png' %epoch)
plt.imshow(img)
plt.axis('off')
plt.show()
3.8 定義條件生成對抗模型(Conditional Generative Adversarial Networks)
class ConditionalGAN():
def __init__(self):
# loss值記錄列表,用于最后顯示Loss值的趨勢,查看訓練效果
self.g_loss = []
# epoch的記錄列表
self.epoch_range = []
# ---------------------
# 判別模型部分
# ---------------------
self.discriminator = build_discriminator()
self.discriminator.compile(loss=['binary_crossentropy'],
optimizer=optimizer,
metrics=['accuracy'])
# ---------------------
# 生成模型部分
# ---------------------
self.generator = build_generator()
# ---------------------
# 合并模型部分
# ---------------------
noise = Input(shape=(latent_dim,))
label = Input(shape=(1,))
img = self.generator([noise, label])
# 在合并模型中,我們只訓練生成模型
self.discriminator.trainable = False
valid = self.discriminator([img, label])
# 結合判別模型跟生成模型
self.combined = Model([noise, label], valid)
self.combined.compile(loss=['binary_crossentropy'],
optimizer=optimizer)
# 訓練函數
def train(self, epochs, batch_size=128, sample_interval=50):
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs+1):
# ---------------------
# 訓練判別模型部分
# ---------------------
idx = np.random.randint(0, x_train.shape[0], batch_size)
imgs, labels = x_train[idx], y_train[idx]
# 生成噪聲圖片
noise = np.random.normal(0, 1, (batch_size, 100))
# 生成模型通過噪聲圖片跟標簽,生成相應的圖片
gen_imgs = self.generator.predict([noise, labels])
# 訓練判別模型
d_loss_real = self.discriminator.train_on_batch([imgs, labels], valid)
d_loss_fake = self.discriminator.train_on_batch([gen_imgs, labels], fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# 訓練生成模型部分
# ---------------------
sampled_labels = np.random.randint(0, 10, batch_size).reshape(-1, 1)
# 訓練生成模型模型
g_loss = self.combined.train_on_batch([noise, labels], valid)
# 記錄訓練結果的值
self.g_loss.append(g_loss)
self.epoch_range.append(epoch)
# 每200個epoch輸出一次結果,查看效果
if epoch % sample_interval == 0:
sample_images(epoch, self.generator)
創建條件生成對抗模型(Conditional Generative Adversarial Networks)對象
gan = ConditionalGAN()
訓練
這次我們訓練20000個epochs,設置Batch Size大小為32, 同時每200個epoch,我們輸出一次預測結果,看下0-9這幾個數字在當前模型下的生成情況。
從中間的每200個epoch的結果來看,我們的模型從最開始的隨機圖像,先慢慢的產生出黑色的背景圖,然后在每個圖像的中間慢慢的產生出內容,隨著epoch迭代的增加,中間輸出的圖像的內容也慢慢的變得更加有意義,直到迭代結束。我們輸出的結果圖像,基本可以用肉眼看到這個是什么數字。
gan.train(epochs=20000, batch_size=32, sample_interval=200)
查看訓練過程中條件生成對抗模型(Conditional Generative Adversarial Networks)的損失值(loss)情況:
圖表中顯示了生成模型跟對抗模型的損失值(loss)的趨勢,
查看圖表,我們可以看到損失值(loss)從一開始的非常大的數值,下降到了一個穩定的值。
這個表明我們的模型在不斷的迭代的過程中,產生的結果的誤差是在逐步逐步的減小,最后趨于一個穩定的值,說明我們的模型一直在收斂。
plt.plot(gan.epoch_range, gan.g_loss, '-r', label= "Generator Loss")
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
腳本地址:https://github.com/matpool/mn...
矩池云現已經把腳本鏡像以上線,有感興趣的用戶可以在矩池云中體驗。
審核編輯 黃昊宇
-
python
+關注
關注
56文章
4783瀏覽量
84473 -
強化學習
+關注
關注
4文章
266瀏覽量
11220
發布評論請先 登錄
相關推薦
圖像生成對抗生成網絡
如何使用生成對抗網絡進行信息隱藏方案資料說明
基于譜歸一化條件生成對抗網絡的圖像修復算法

基于生成器的圖像分類對抗樣本生成模型

基于自注意力機制的條件生成對抗網絡模型
梯度懲罰優化的圖像循環生成對抗網絡模型
基于密集卷積生成對抗網絡的圖像修復方法
基于條件生成式對抗網絡的面部表情遷移模型
基于結構保持生成對抗網絡的圖像去噪
生成對抗網絡GAN的七大開放性問題







 工商網監
工商網監
評論