 CPU是如何調度任務的?
CPU是如何調度任務的?
前言
你清楚下面這幾個問題嗎?
有了內存,為什么還需要 CPU Cache?
CPU 是怎么讀寫數據的?
如何讓 CPU 能讀取數據更快一些?
CPU 偽共享是如何發生的?又該如何避免?
CPU 是如何調度任務的?如果你的任務對響應要求很高,你希望它總是能被先調度,這該怎么辦?
…
這篇,我們就來回答這些問題。
正文
CPU 如何讀寫數據的?
先來認識 CPU 的架構,只有理解了 CPU 的 架構,才能更好地理解 CPU 是如何讀寫數據的,對于現代 CPU 的架構圖如下:
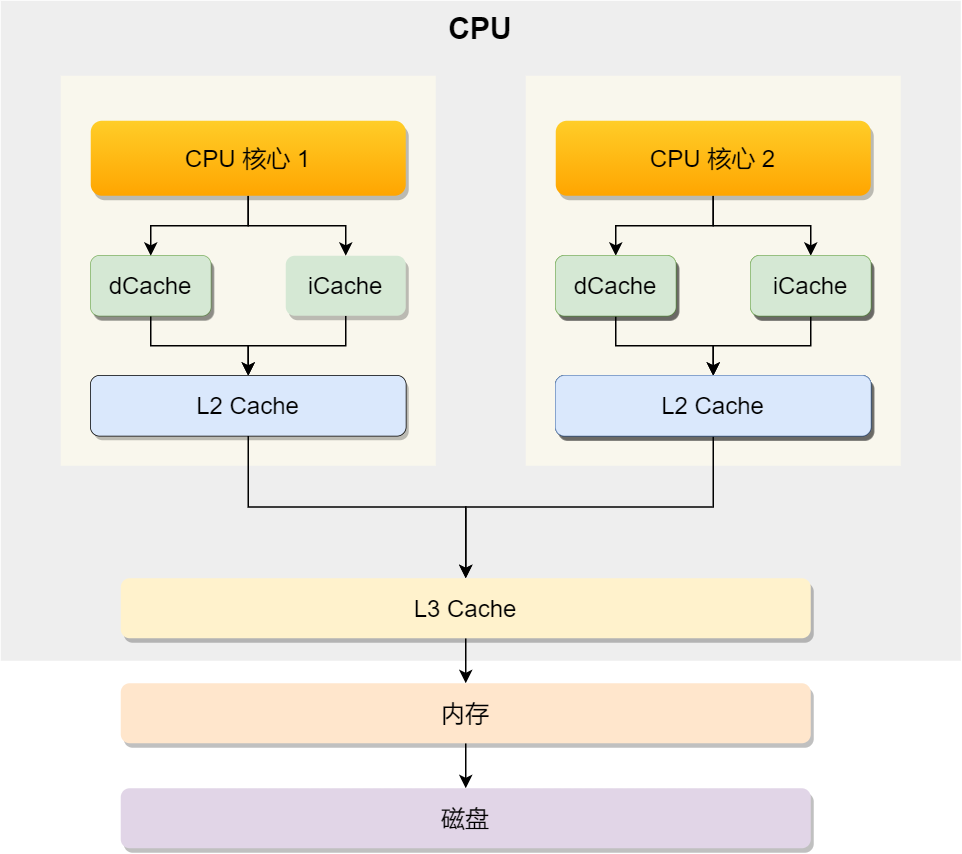
可以看到,一個 CPU 里通常會有多個 CPU 核心,比如上圖中的 1 號和 2 號 CPU 核心,并且每個 CPU 核心都有自己的 L1 Cache 和 L2 Cache,而 L1 Cache 通常分為 dCache(數據緩存) 和 iCache(指令緩存),L3 Cache 則是多個核心共享的,這就是 CPU 典型的緩存層次。
上面提到的都是 CPU 內部的 Cache,放眼外部的話,還會有內存和硬盤,這些存儲設備共同構成了金字塔存儲層次。如下圖所示:
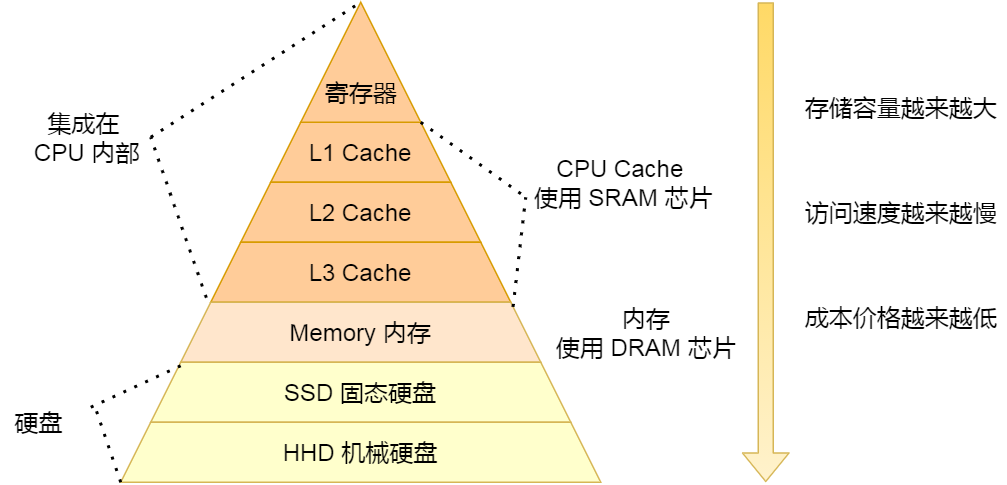
從上圖也可以看到,從上往下,存儲設備的容量會越大,而訪問速度會越慢。至于每個存儲設備的訪問延時,你可以看下圖的表格:
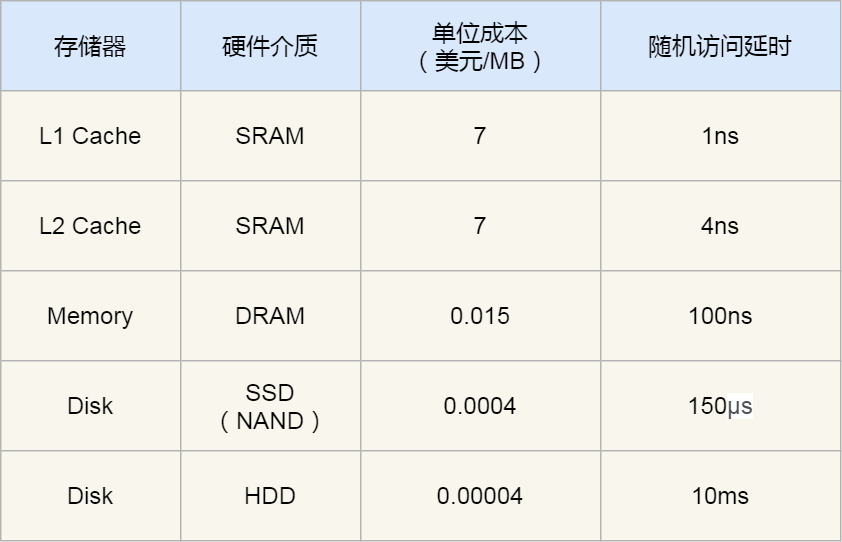
你可以看到, CPU 訪問 L1 Cache 速度比訪問內存快 100 倍,這就是為什么 CPU 里會有 L1~L3 Cache 的原因,目的就是把 Cache 作為 CPU 與內存之間的緩存層,以減少對內存的訪問頻率。
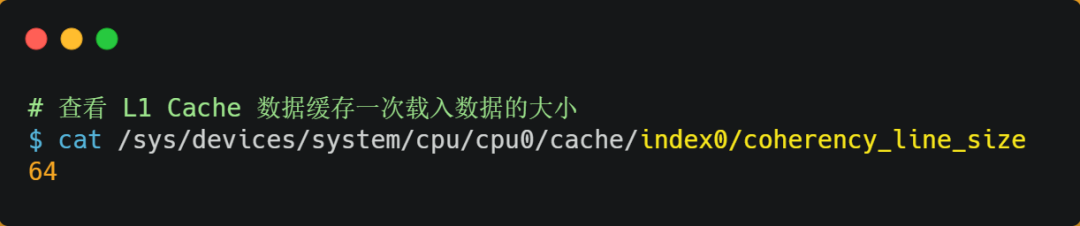
CPU 從內存中讀取數據到 Cache 的時候,并不是一個字節一個字節讀取,而是一塊一塊的方式來讀取數據的,這一塊一塊的數據被稱為 CPU Line(緩存行),所以CPU Line 是 CPU 從內存讀取數據到 Cache 的單位。
至于 CPU Line 大小,在 Linux 系統可以用下面的方式查看到,你可以看我服務器的 L1 Cache Line 大小是 64 字節,也就意味著L1 Cache 一次載入數據的大小是 64 字節。
那么對數組的加載, CPU 就會加載數組里面連續的多個數據到 Cache 里,因此我們應該按照物理內存地址分布的順序去訪問元素,這樣訪問數組元素的時候,Cache 命中率就會很高,于是就能減少從內存讀取數據的頻率, 從而可提高程序的性能。
但是,在我們不使用數組,而是使用單獨的變量的時候,則會有 Cache 偽共享的問題,Cache 偽共享問題上是一個性能殺手,我們應該要規避它。
接下來,就來看看 Cache 偽共享是什么?又如何避免這個問題?
現在假設有一個雙核心的 CPU,這兩個 CPU 核心并行運行著兩個不同的線程,它們同時從內存中讀取兩個不同的數據,分別是類型為long的變量 A 和 B,這個兩個數據的地址在物理內存上是連續的,如果 Cahce Line 的大小是 64 字節,并且變量 A 在 Cahce Line 的開頭位置,那么這兩個數據是位于同一個 Cache Line 中,又因為 CPU Line 是 CPU 從內存讀取數據到 Cache 的單位,所以這兩個數據會被同時讀入到了兩個 CPU 核心中各自 Cache 中。
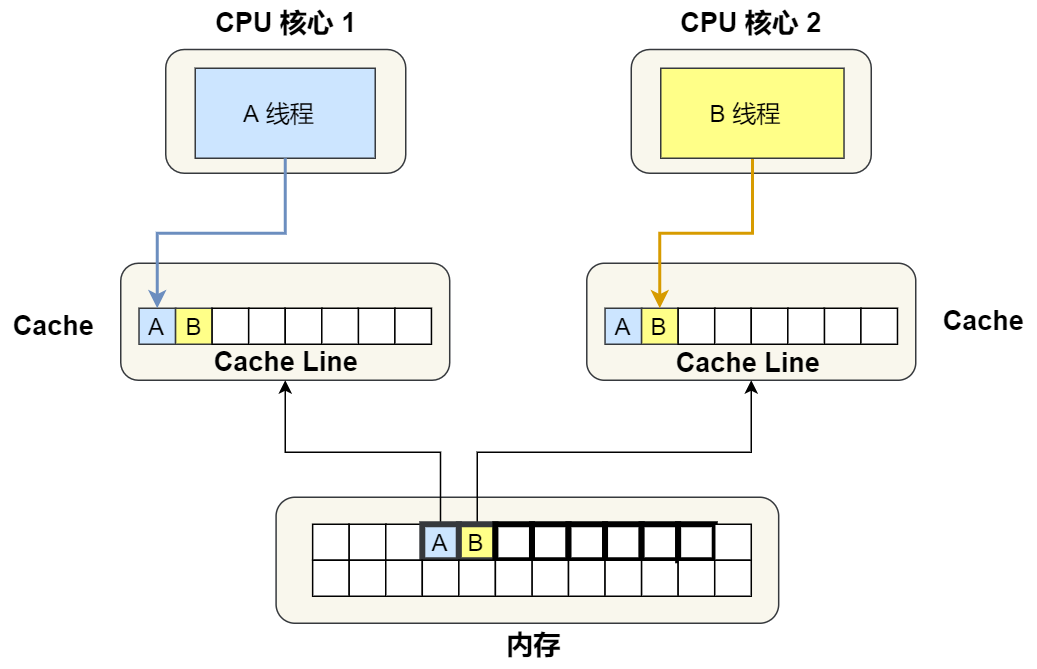
我們來思考一個問題,如果這兩個不同核心的線程分別修改不同的數據,比如 1 號 CPU 核心的線程只修改了 變量 A,或 2 號 CPU 核心的線程的線程只修改了變量 B,會發生什么呢?
分析偽共享的問題
現在我們結合保證多核緩存一致的 MESI 協議,來說明這一整個的過程,如果你還不知道 MESI 協議,你可以看我這篇文章「10 張圖打開 CPU 緩存一致性的大門」。
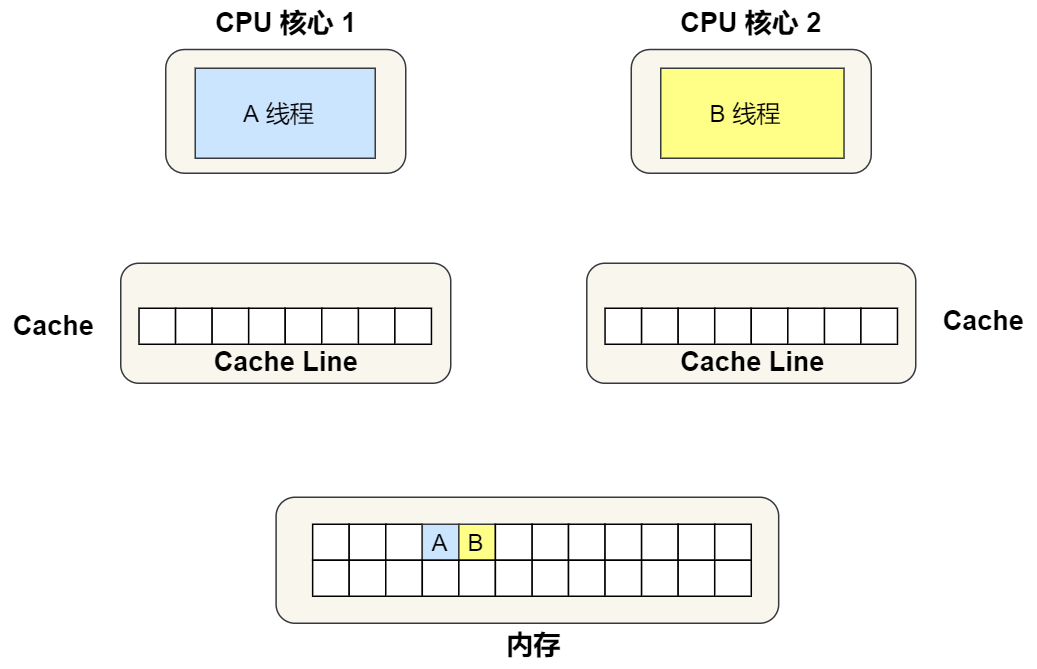
①. 最開始變量 A 和 B 都還不在 Cache 里面,假設 1 號核心綁定了線程 A,2 號核心綁定了線程 B,線程 A 只會讀寫變量 A,線程 B 只會讀寫變量 B。
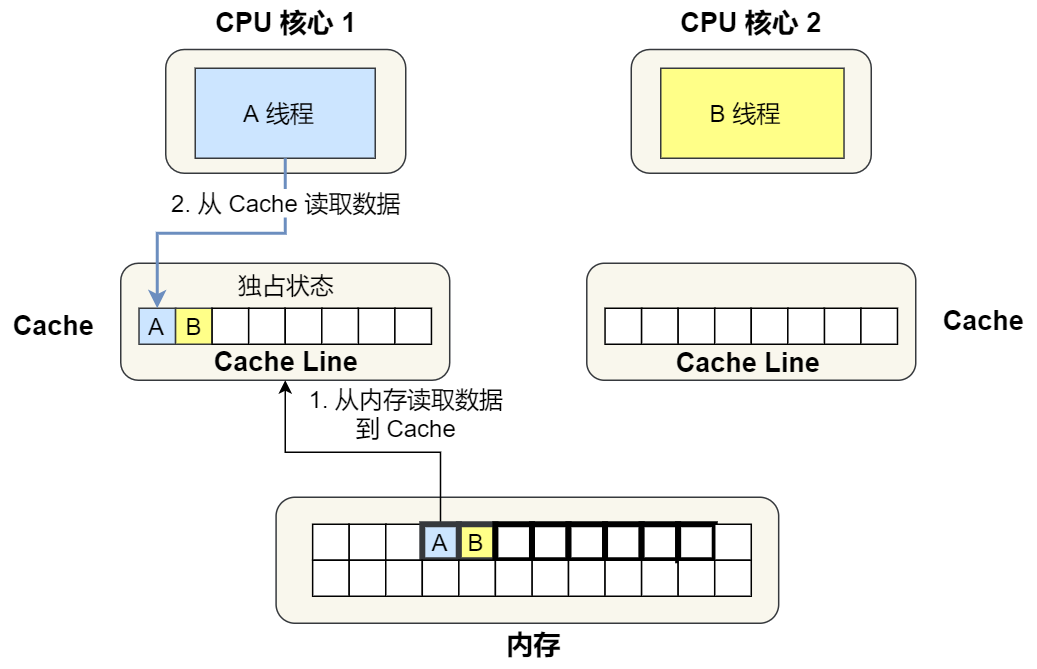
②. 1 號核心讀取變量 A,由于 CPU 從內存讀取數據到 Cache 的單位是 Cache Line,也正好變量 A 和 變量 B 的數據歸屬于同一個 Cache Line,所以 A 和 B 的數據都會被加載到 Cache,并將此 Cache Line 標記為「獨占」狀態。
③. 接著,2 號核心開始從內存里讀取變量 B,同樣的也是讀取 Cache Line 大小的數據到 Cache 中,此 Cache Line 中的數據也包含了變量 A 和 變量 B,此時 1 號和 2 號核心的 Cache Line 狀態變為「共享」狀態。
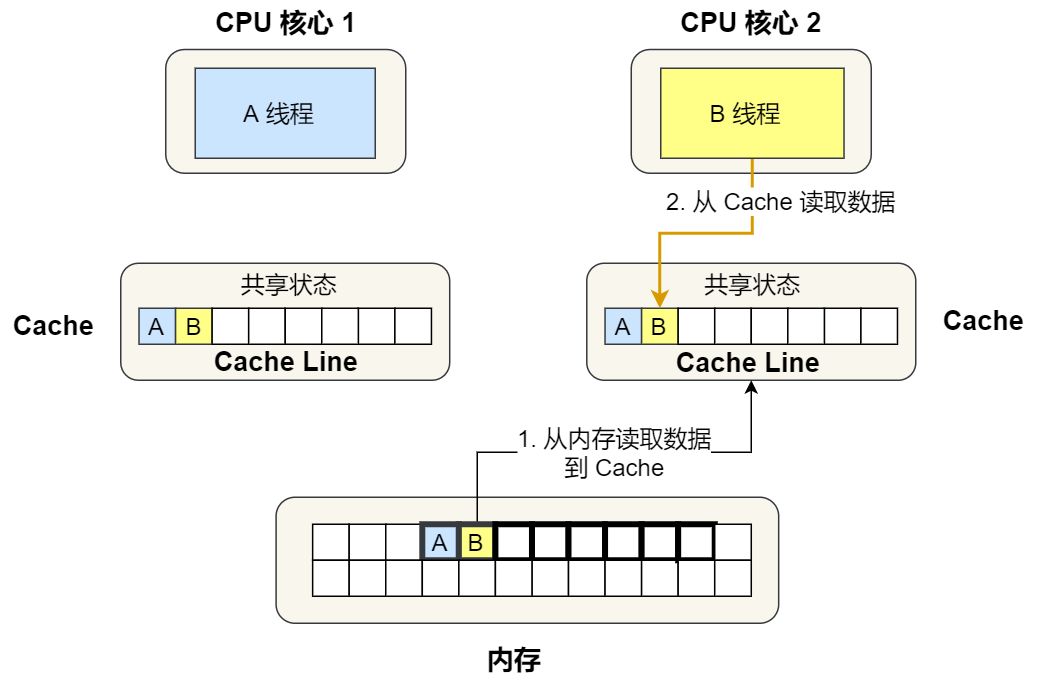
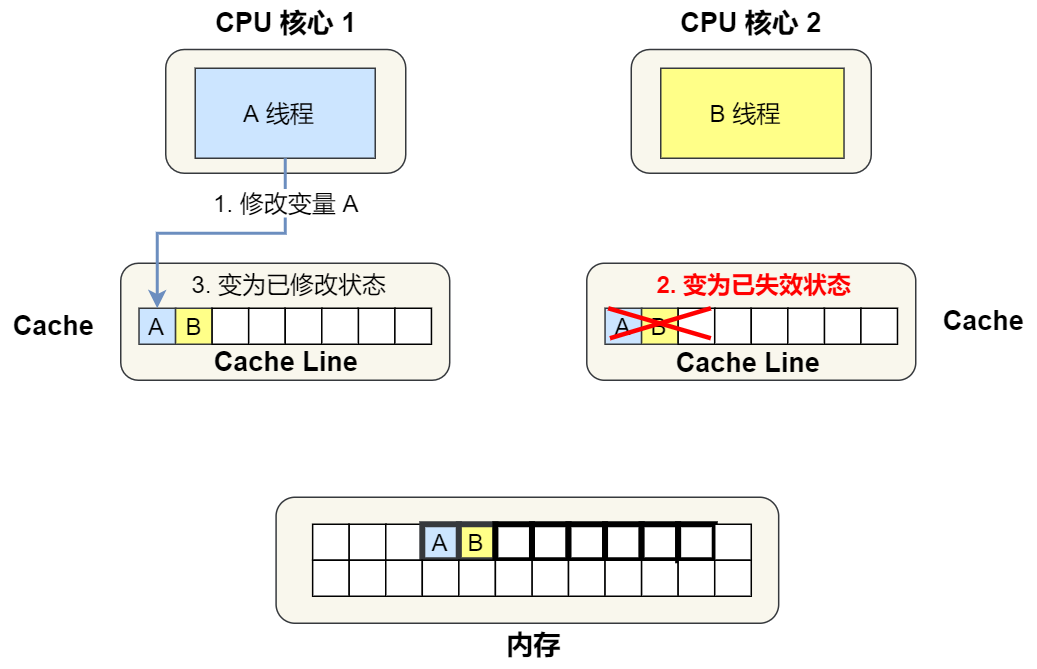
④. 1 號核心需要修改變量 A,發現此 Cache Line 的狀態是「共享」狀態,所以先需要通過總線發送消息給 2 號核心,通知 2 號核心把 Cache 中對應的 Cache Line 標記為「已失效」狀態,然后 1 號核心對應的 Cache Line 狀態變成「已修改」狀態,并且修改變量 A。
⑤. 之后,2 號核心需要修改變量 B,此時 2 號核心的 Cache 中對應的 Cache Line 是已失效狀態,另外由于 1 號核心的 Cache 也有此相同的數據,且狀態為「已修改」狀態,所以要先把 1 號核心的 Cache 對應的 Cache Line 寫回到內存,然后 2 號核心再從內存讀取 Cache Line 大小的數據到 Cache 中,最后把變量 B 修改到 2 號核心的 Cache 中,并將狀態標記為「已修改」狀態。
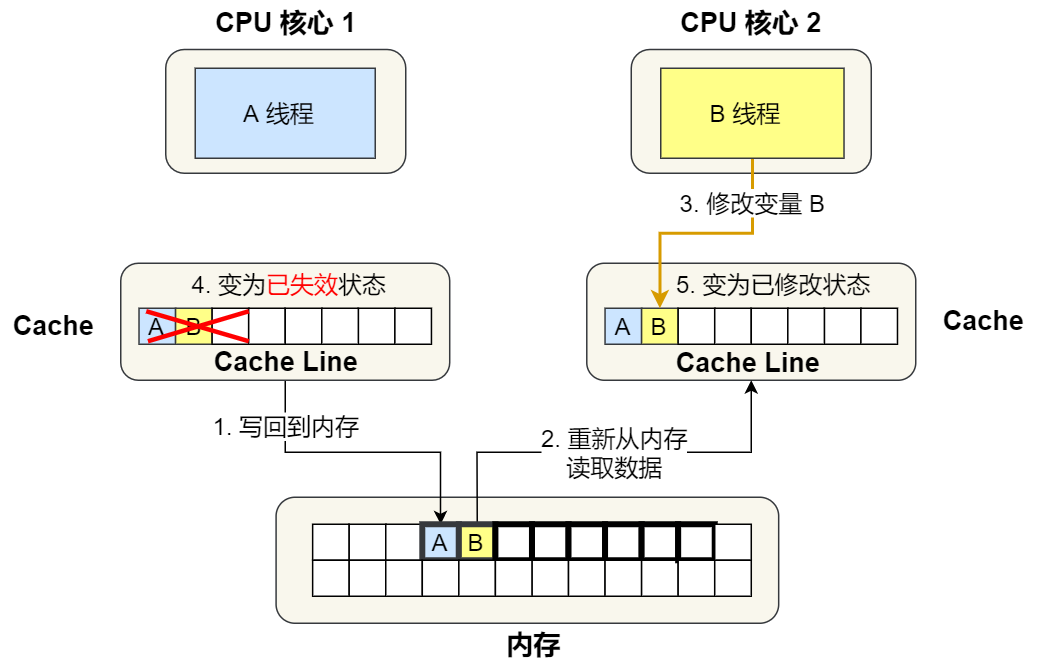
所以,可以發現如果 1 號和 2 號 CPU 核心這樣持續交替的分別修改變量 A 和 B,就會重復 ④ 和 ⑤ 這兩個步驟,Cache 并沒有起到緩存的效果,雖然變量 A 和 B 之間其實并沒有任何的關系,但是因為同時歸屬于一個 Cache Line ,這個 Cache Line 中的任意數據被修改后,都會相互影響,從而出現 ④ 和 ⑤ 這兩個步驟。
因此,這種因為多個線程同時讀寫同一個 Cache Line 的不同變量時,而導致 CPU Cache 失效的現象稱為偽共享(False Sharing)。
避免偽共享的方法
因此,對于多個線程共享的熱點數據,即經常會修改的數據,應該避免這些數據剛好在同一個 Cache Line 中,否則就會出現為偽共享的問題。
接下來,看看在實際項目中是用什么方式來避免偽共享的問題的。
在 Linux 內核中存在__cacheline_aligned_in_smp宏定義,是用于解決偽共享的問題。
從上面的宏定義,我們可以看到:
如果在多核(MP)系統里,該宏定義是__cacheline_aligned,也就是 Cache Line 的大小;
而如果在單核系統里,該宏定義是空的;
因此,針對在同一個 Cache Line 中的共享的數據,如果在多核之間競爭比較嚴重,為了防止偽共享現象的發生,可以采用上面的宏定義使得變量在 Cache Line 里是對齊的。
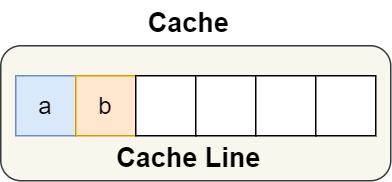
舉個例子,有下面這個結構體:
結構體里的兩個成員變量 a 和 b 在物理內存地址上是連續的,于是它們可能會位于同一個 Cache Line 中,如下圖:
所以,為了防止前面提到的 Cache 偽共享問題,我們可以使用上面介紹的宏定義,將 b 的地址設置為 Cache Line 對齊地址,如下:
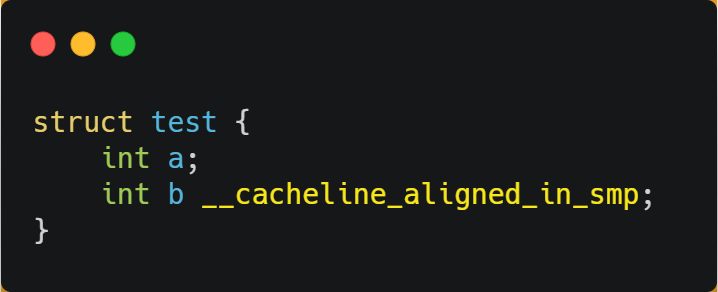
這樣 a 和 b 變量就不會在同一個 Cache Line 中了,如下圖:
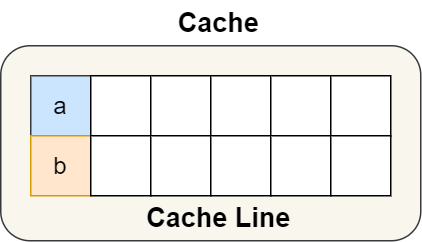
所以,避免 Cache 偽共享實際上是用空間換時間的思想,浪費一部分 Cache 空間,從而換來性能的提升。
我們再來看一個應用層面的規避方案,有一個 Java 并發框架 Disruptor 使用「字節填充 + 繼承」的方式,來避免偽共享的問題。
Disruptor 中有一個 RingBuffer 類會經常被多個線程使用,代碼如下:
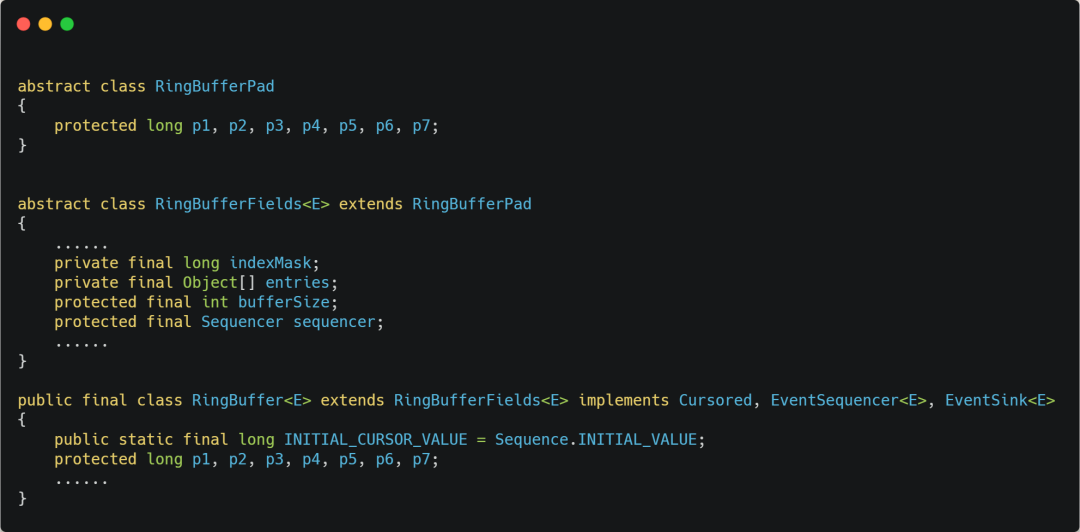
你可能會覺得 RingBufferPad 類里 7 個 long 類型的名字很奇怪,但事實上,它們雖然看起來毫無作用,但卻對性能的提升起到了至關重要的作用。
我們都知道,CPU Cache 從內存讀取數據的單位是 CPU Line,一般 64 位 CPU 的 CPU Line 的大小是 64 個字節,一個 long 類型的數據是 8 個字節,所以 CPU 一下會加載 8 個 long 類型的數據。
根據 JVM 對象繼承關系中父類成員和子類成員,內存地址是連續排列布局的,因此 RingBufferPad 中的 7 個 long 類型數據作為 Cache Line前置填充,而 RingBuffer 中的 7 個 long 類型數據則作為 Cache Line后置填充,這 14 個 long 變量沒有任何實際用途,更不會對它們進行讀寫操作。
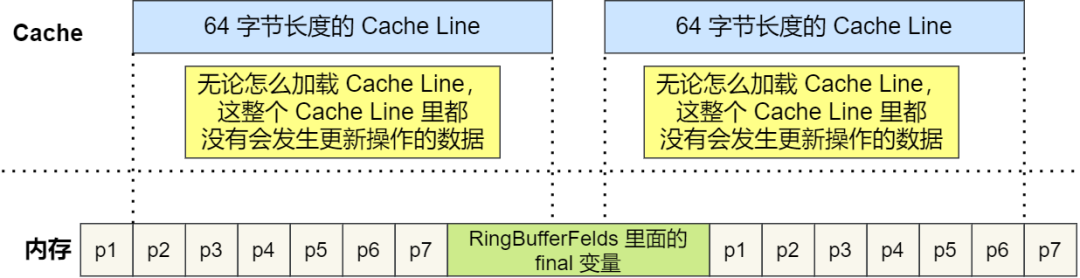
另外,RingBufferFelds 里面定義的這些變量都是final修飾的,意味著第一次加載之后不會再修改, 又由于「前后」各填充了 7 個不會被讀寫的 long 類型變量,所以無論怎么加載 Cache Line,這整個 Cache Line 里都沒有會發生更新操作的數據,于是只要數據被頻繁地讀取訪問,就自然沒有數據被換出 Cache 的可能,也因此不會產生偽共享的問題。
CPU 如何選擇線程的?
了解完 CPU 讀取數據的過程后,我們再來看看 CPU 是根據什么來選擇當前要執行的線程。
在 Linux 內核中,進程和線程都是用tark_struct結構體表示的,區別在于線程的 tark_struct 結構體里部分資源是共享了進程已創建的資源,比如內存地址空間、代碼段、文件描述符等,所以 Linux 中的線程也被稱為輕量級進程,因為線程的 tark_struct 相比進程的 tark_struct 承載的 資源比較少,因此以「輕」得名。
一般來說,沒有創建線程的進程,是只有單個執行流,它被稱為是主線程。如果想讓進程處理更多的事情,可以創建多個線程分別去處理,但不管怎么樣,它們對應到內核里都是tark_struct。
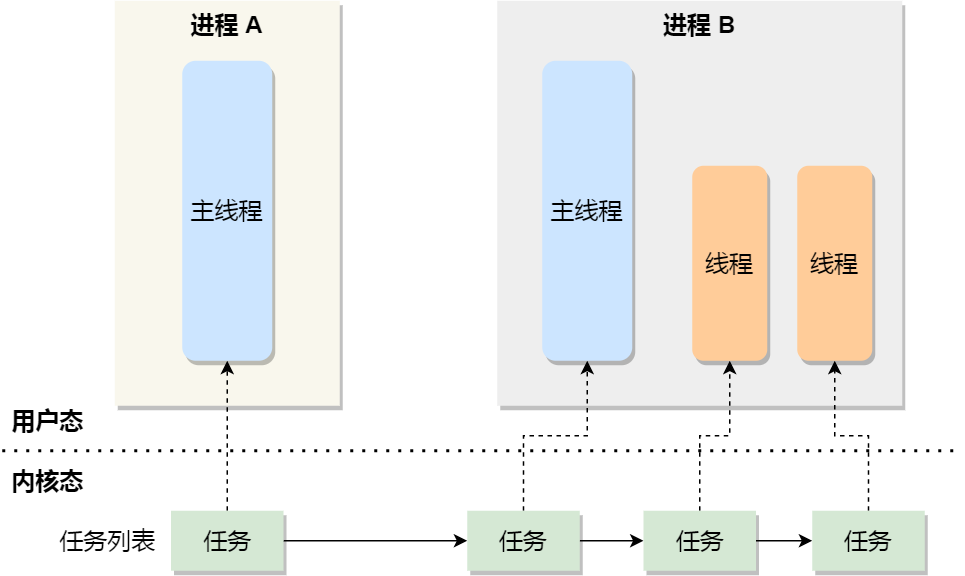
所以,Linux 內核里的調度器,調度的對象就是tark_struct,接下來我們就把這個數據結構統稱為任務。
在 Linux 系統中,根據任務的優先級以及響應要求,主要分為兩種,其中優先級的數值越小,優先級越高:
實時任務,對系統的響應時間要求很高,也就是要盡可能快的執行實時任務,優先級在0~99范圍內的就算實時任務;
普通任務,響應時間沒有很高的要求,優先級在100~139范圍內都是普通任務級別;
調度類
由于任務有優先級之分,Linux 系統為了保障高優先級的任務能夠盡可能早的被執行,于是分為了這幾種調度類,如下圖:
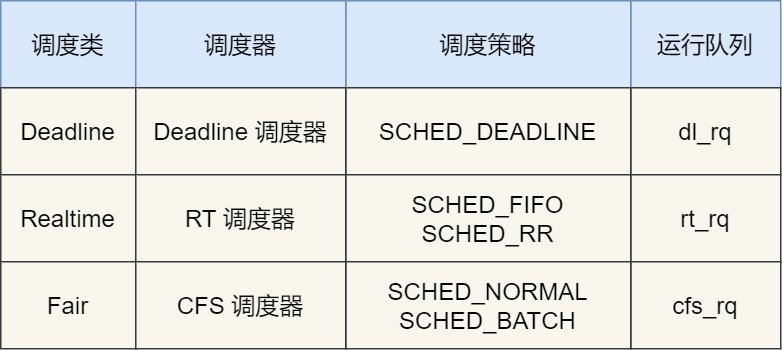
Deadline 和 Realtime 這兩個調度類,都是應用于實時任務的,這兩個調度類的調度策略合起來共有這三種,它們的作用如下:
SCHED_DEADLINE:是按照 deadline 進行調度的,距離當前時間點最近的 deadline 的任務會被優先調度;
SCHED_FIFO:對于相同優先級的任務,按先來先服務的原則,但是優先級更高的任務,可以搶占低優先級的任務,也就是優先級高的可以「插隊」;
SCHED_RR:對于相同優先級的任務,輪流著運行,每個任務都有一定的時間片,當用完時間片的任務會被放到隊列尾部,以保證相同優先級任務的公平性,但是高優先級的任務依然可以搶占低優先級的任務;
而 Fair 調度類是應用于普通任務,都是由 CFS 調度器管理的,分為兩種調度策略:
SCHED_NORMAL:普通任務使用的調度策略;
SCHED_BATCH:后臺任務的調度策略,不和終端進行交互,因此在不影響其他需要交互的任務,可以適當降低它的優先級。
完全公平調度
我們平日里遇到的基本都是普通任務,對于普通任務來說,公平性最重要,在 Linux 里面,實現了一個基于 CFS 的調度算法,也就是完全公平調度(Completely Fair Scheduling)。
這個算法的理念是想讓分配給每個任務的 CPU 時間是一樣,于是它為每個任務安排一個虛擬運行時間 vruntime,如果一個任務在運行,其運行的越久,該任務的 vruntime 自然就會越大,而沒有被運行的任務,vruntime 是不會變化的。
那么,在 CFS 算法調度的時候,會優先選擇 vruntime 少的任務,以保證每個任務的公平性。
這就好比,讓你把一桶的奶茶平均分到 10 杯奶茶杯里,你看著哪杯奶茶少,就多倒一些;哪個多了,就先不倒,這樣經過多輪操作,雖然不能保證每杯奶茶完全一樣多,但至少是公平的。
當然,上面提到的例子沒有考慮到優先級的問題,雖然是普通任務,但是普通任務之間還是有優先級區分的,所以在計算虛擬運行時間 vruntime 還要考慮普通任務的權重值,注意權重值并不是優先級的值,內核中會有一個 nice 級別與權重值的轉換表,nice 級別越低的權重值就越大,至于 nice 值是什么,我們后面會提到。
于是就有了以下這個公式:

你可以不用管 NICE_0_LOAD 是什么,你就認為它是一個常量,那么在「同樣的實際運行時間」里,高權重任務的 vruntime 比低權重任務的 vruntime少,你可能會奇怪為什么是少的?你還記得 CFS 調度嗎,它是會優先選擇 vruntime 少的任務進行調度,所以高權重的任務就會被優先調度了,于是高權重的獲得的實際運行時間自然就多了。
CPU 運行隊列
一個系統通常都會運行著很多任務,多任務的數量基本都是遠超 CPU 核心數量,因此這時候就需要排隊。
事實上,每個 CPU 都有自己的運行隊列(Run Queue, rq),用于描述在此 CPU 上所運行的所有進程,其隊列包含三個運行隊列,Deadline 運行隊列 dl_rq、實時任務運行隊列 rt_rq 和 CFS 運行隊列 csf_rq,其中 csf_rq 是用紅黑樹來描述的,按 vruntime 大小來排序的,最左側的葉子節點,就是下次會被調度的任務。
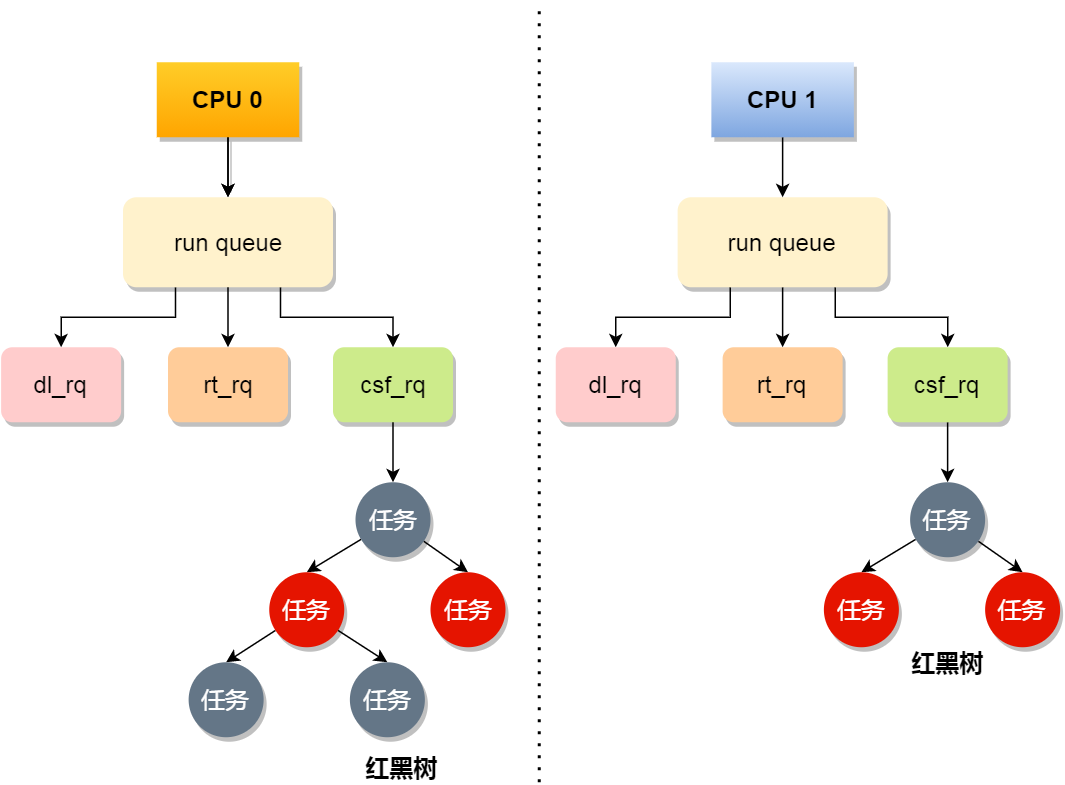
這幾種調度類是有優先級的,優先級如下:Deadline > Realtime > Fair,這意味著 Linux 選擇下一個任務執行的時候,會按照此優先級順序進行選擇,也就是說先從dl_rq里選擇任務,然后從rt_rq里選擇任務,最后從csf_rq里選擇任務。因此,實時任務總是會比普通任務優先被執行。
調整優先級
如果我們啟動任務的時候,沒有特意去指定優先級的話,默認情況下都是普通任務,普通任務的調度類是 Fail,由 CFS 調度器來進行管理。CFS 調度器的目的是實現任務運行的公平性,也就是保障每個任務的運行的時間是差不多的。
如果你想讓某個普通任務有更多的執行時間,可以調整任務的nice值,從而讓優先級高一些的任務執行更多時間。nice 的值能設置的范圍是-20~19, 值越低,表明優先級越高,因此 -20 是最高優先級,19 則是最低優先級,默認優先級是 0。
是不是覺得 nice 值的范圍很詭異?事實上,nice 值并不是表示優先級,而是表示優先級的修正數值,它與優先級(priority)的關系是這樣的:priority(new) = priority(old) + nice。內核中,priority 的范圍是 0~139,值越低,優先級越高,其中前面的 0~99 范圍是提供給實時任務使用的,而 nice 值是映射到 100~139,這個范圍是提供給普通任務用的,因此 nice 值調整的是普通任務的優先級。

在前面我們提到了,權重值與 nice 值的關系的,nice 值越低,權重值就越大,計算出來的 vruntime 就會越少,由于 CFS 算法調度的時候,就會優先選擇 vruntime 少的任務進行執行,所以 nice 值越低,任務的優先級就越高。
我們可以在啟動任務的時候,可以指定 nice 的值,比如將 mysqld 以 -3 優先級:
如果想修改已經運行中的任務的優先級,則可以使用renice來調整 nice 值:
nice 調整的是普通任務的優先級,所以不管怎么縮小 nice 值,任務永遠都是普通任務,如果某些任務要求實時性比較高,那么你可以考慮改變任務的優先級以及調度策略,使得它變成實時任務,比如:
總結
理解 CPU 是如何讀寫數據的前提,是要理解 CPU 的架構,CPU 內部的多個 Cache + 外部的內存和磁盤都就構成了金字塔的存儲器結構,在這個金字塔中,越往下,存儲器的容量就越大,但訪問速度就會小。
CPU 讀寫數據的時候,并不是按一個一個字節為單位來進行讀寫,而是以 CPU Line 大小為單位,CPU Line 大小一般是 64 個字節,也就意味著 CPU 讀寫數據的時候,每一次都是以 64 字節大小為一塊進行操作。
因此,如果我們操作的數據是數組,那么訪問數組元素的時候,按內存分布的地址順序進行訪問,這樣能充分利用到 Cache,程序的性能得到提升。但如果操作的數據不是數組,而是普通的變量,并在多核 CPU 的情況下,我們還需要避免 Cache Line 偽共享的問題。
所謂的 Cache Line 偽共享問題就是,多個線程同時讀寫同一個 Cache Line 的不同變量時,而導致 CPU Cache 失效的現象。那么對于多個線程共享的熱點數據,即經常會修改的數據,應該避免這些數據剛好在同一個 Cache Line 中,避免的方式一般有 Cache Line 大小字節對齊,以及字節填充等方法。
系統中需要運行的多線程數一般都會大于 CPU 核心,這樣就會導致線程排隊等待 CPU,這可能會產生一定的延時,如果我們的任務對延時容忍度很低,則可以通過一些人為手段干預 Linux 的默認調度策略和優先級。
責任編輯:lq
-
cpu
+關注
關注
68文章
10829瀏覽量
211198 -
數據
+關注
關注
8文章
6909瀏覽量
88850 -
存儲設備
+關注
關注
0文章
159瀏覽量
18575
原文標題:你不好奇 CPU 是如何執行任務的?
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
鴻蒙開發接口資源調度:【@ohos.workScheduler (延遲任務調度)】
編寫一個任務調度程序,在上下文切換后遇到了一些問題求解
淺析FreeRTOS任務調度器的三種調度算法和應用
STM32F103 FreeRTOS任務調度異常的原因?
鴻蒙OS開發實例:【ArkTS類庫多線程CPU密集型任務TaskPool】

FreeRTOS調度器中的三種調度算法實踐(上)

鴻蒙原生應用開發-ArkTS語言基礎類庫多線程CPU密集型任務TaskPool
HarmonyOS CPU與I/O密集型任務開發指導
鴻蒙開發【分布式任務調度】解析
鴻蒙OS 分布式任務調度
鴻蒙原生應用/元服務開發-延遲任務說明(一)
任務調度系統設計的核心邏輯





 工商網監
工商網監
評論