 ElasticSearch的原理是什么?
ElasticSearch的原理是什么?
Elasticsearch 是一款功能強大的開源分布式搜索與數據分析引擎,目前國內諸多互聯網大廠都在使用,包括攜程、滴滴、今日頭條、餓了么、360 安全、小米、vivo 等。
除了搜索之外,結合 Kibana、Logstash、Beats,Elastic Stack 還被廣泛運用在大數據近實時分析領域,包括日志分析、指標監控、信息安全等多個領域。
它可以幫助你探索海量結構化、非結構化數據,按需創建可視化報表,對監控數據設置報警閾值,甚至通過使用機器學習技術,自動識別異常狀況。
今天,我們先自上而下,后自底向上的介紹ElasticSearch的底層工作原理,并試圖回答以下問題:
為什么我的搜索*foo-bar*無法匹配 foo-bar ?
為什么增加更多的文件會壓縮索引(Index)?
為什么 ElasticSearch 占用很多內存?
圖解 ElasticSearch
elasticsearch 版本:elasticsearch-2.2.0。
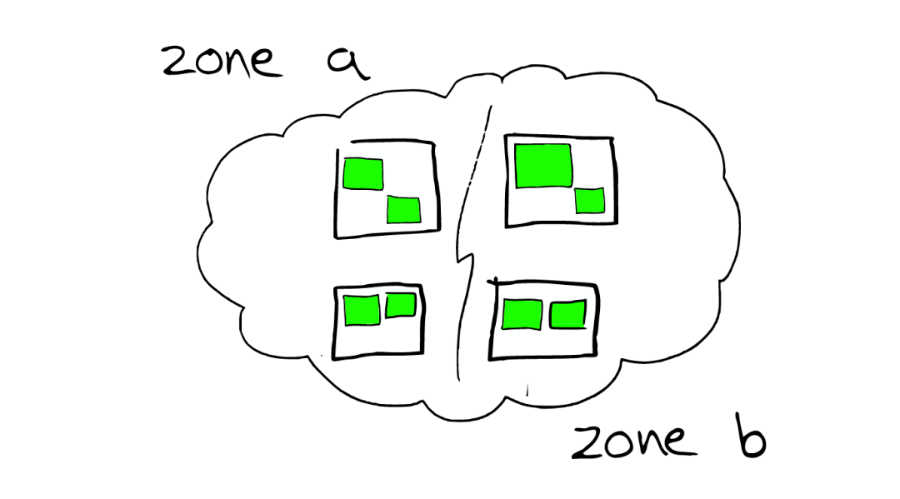
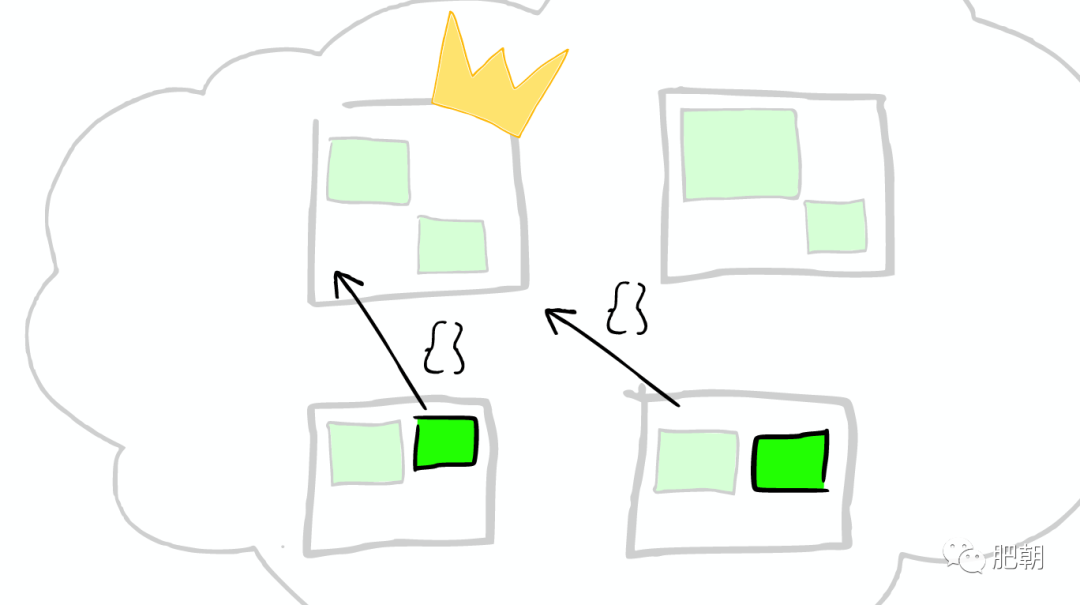
①云上的集群
如下圖:
②集群里的盒子
云里面的每個白色正方形的盒子代表一個節點——Node。
③節點之間
在一個或者多個節點直接,多個綠色小方塊組合在一起形成一個 ElasticSearch 的索引。
④索引里的小方塊
在一個索引下,分布在多個節點里的綠色小方塊稱為分片——Shard。
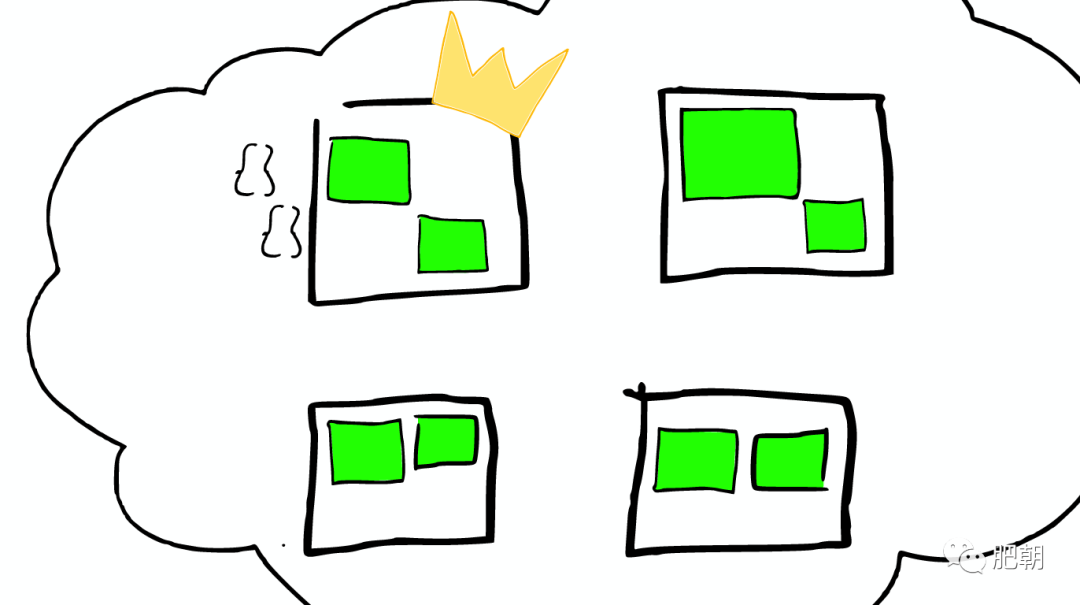
⑤Shard=Lucene Index
一個 ElasticSearch 的 Shard 本質上是一個 Lucene Index。

Lucene 是一個 Full Text 搜索庫(也有很多其他形式的搜索庫),ElasticSearch 是建立在 Lucene 之上的。
接下來的故事要說的大部分內容實際上是 ElasticSearch 如何基于 Lucene 工作的。
圖解 Lucene
Mini 索引:Segment
在 Lucene 里面有很多小的 Segment,我們可以把它們看成 Lucene 內部的 mini-index。
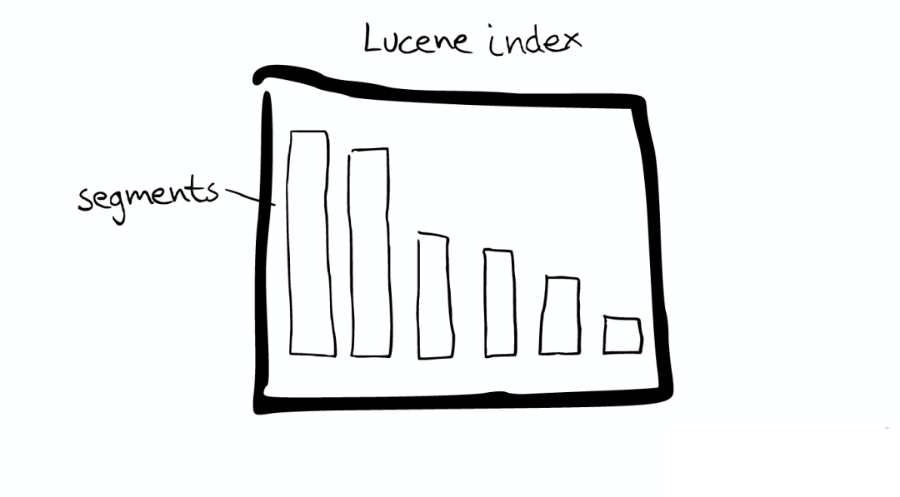
Segment 內部
Segment 內部有著許多數據結構,如上圖:
Inverted Index
Stored Fields
Document Values
Cache
最最重要的 Inverted Index
如下圖:
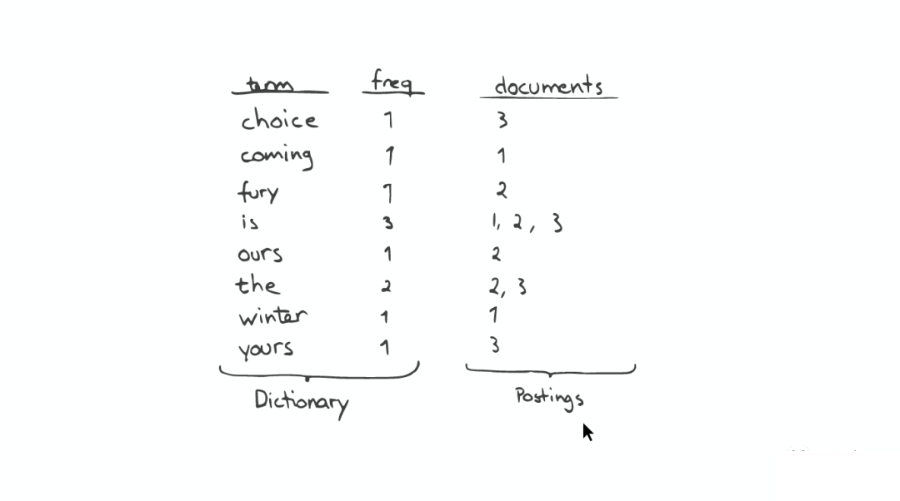
Inverted Index 主要包括兩部分:
一個有序的數據字典 Dictionary(包括單詞 Term 和它出現的頻率)。
與單詞 Term 對應的 Postings(即存在這個單詞的文件)。
當我們搜索的時候,首先將搜索的內容分解,然后在字典里找到對應 Term,從而查找到與搜索相關的文件內容。

①查詢“the fury”
如下圖:

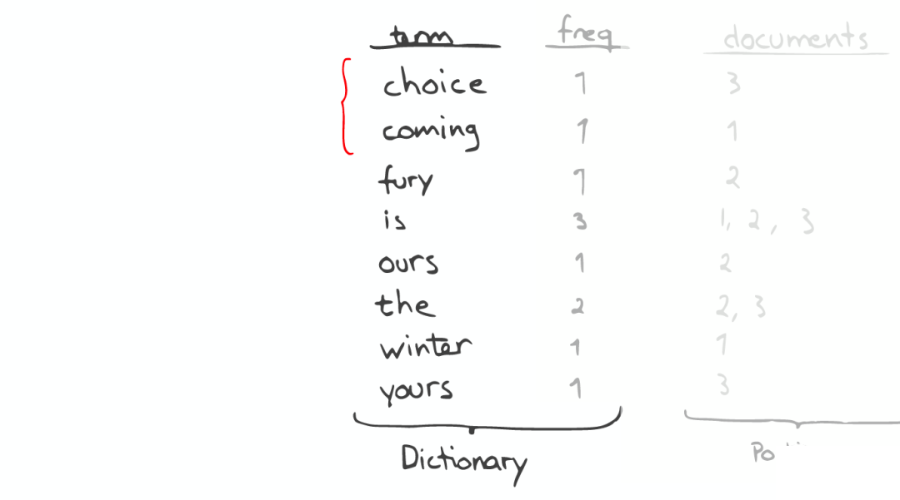
②自動補全(AutoCompletion-Prefix)
如果想要查找以字母“c”開頭的字母,可以簡單的通過二分查找(Binary Search)在 Inverted Index 表中找到例如“choice”、“coming”這樣的詞(Term)。
③昂貴的查找
如果想要查找所有包含“our”字母的單詞,那么系統會掃描整個 Inverted Index,這是非常昂貴的。
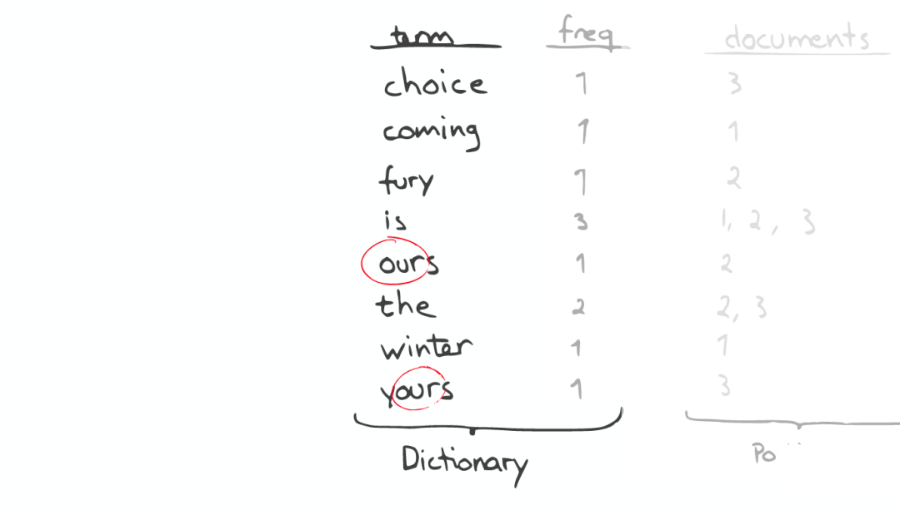
在此種情況下,如果想要做優化,那么我們面對的問題是如何生成合適的 Term。
④問題的轉化
如下圖:

對于以上諸如此類的問題,我們可能會有幾種可行的解決方案:
* suffix→xiffus *,如果我們想以后綴作為搜索條件,可以為 Term 做反向處理。
(60.6384, 6.5017)→ u4u8gyykk,對于 GEO 位置信息,可以將它轉換為 GEO Hash。
123→{1-hundreds, 12-tens, 123},對于簡單的數字,可以為它生成多重形式的 Term。
⑤解決拼寫錯誤
一個 Python 庫為單詞生成了一個包含錯誤拼寫信息的樹形狀態機,解決拼寫錯誤的問題。
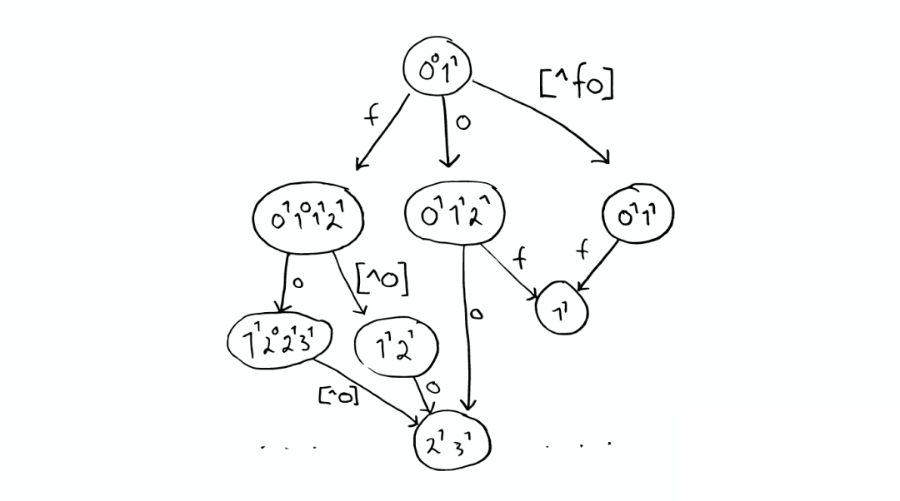
⑥Stored Field 字段查找
當我們想要查找包含某個特定標題內容的文件時,Inverted Index 就不能很好的解決這個問題,所以 Lucene 提供了另外一種數據結構 Stored Fields 來解決這個問題。
本質上,Stored Fields 是一個簡單的鍵值對 key-value。默認情況下,ElasticSearch 會存儲整個文件的 JSON source。

⑦Document Values 為了排序,聚合
即使這樣,我們發現以上結構仍然無法解決諸如:排序、聚合、facet,因為我們可能會要讀取大量不需要的信息。
所以,另一種數據結構解決了此種問題:Document Values。這種結構本質上就是一個列式的存儲,它高度優化了具有相同類型的數據的存儲結構。

為了提高效率,ElasticSearch 可以將索引下某一個 Document Value 全部讀取到內存中進行操作,這大大提升訪問速度,但是也同時會消耗掉大量的內存空間。
總之,這些數據結構 Inverted Index、Stored Fields、Document Values 及其緩存,都在 segment 內部。
搜索發生時
搜索時,Lucene 會搜索所有的 Segment 然后將每個 Segment 的搜索結果返回,最后合并呈現給客戶。
Lucene 的一些特性使得這個過程非常重要:
Segments 是不可變的(immutable):Delete?當刪除發生時,Lucene 做的只是將其標志位置為刪除,但是文件還是會在它原來的地方,不會發生改變。
Update?所以對于更新來說,本質上它做的工作是:先刪除,然后重新索引(Re-index)。
隨處可見的壓縮:Lucene 非常擅長壓縮數據,基本上所有教科書上的壓縮方式,都能在 Lucene 中找到。
緩存所有的所有:Lucene 也會將所有的信息做緩存,這大大提高了它的查詢效率。
緩存的故事
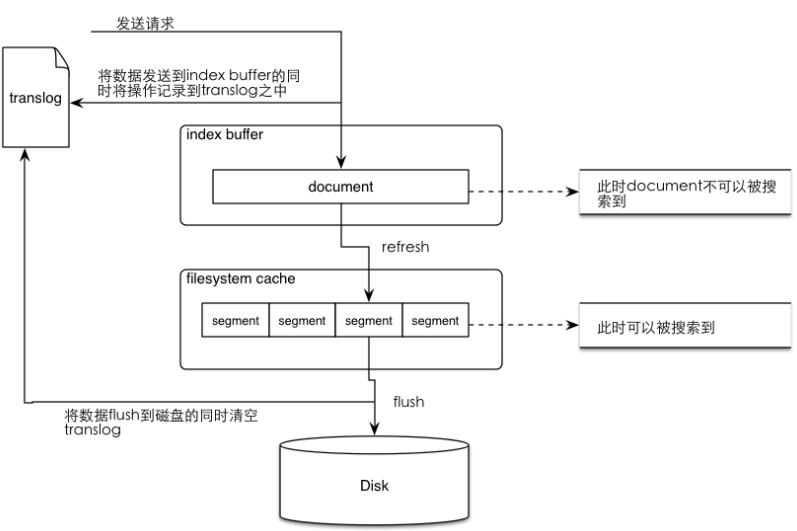
當 ElasticSearch 索引一個文件的時候,會為文件建立相應的緩存,并且會定期(每秒)刷新這些數據,然后這些文件就可以被搜索到。
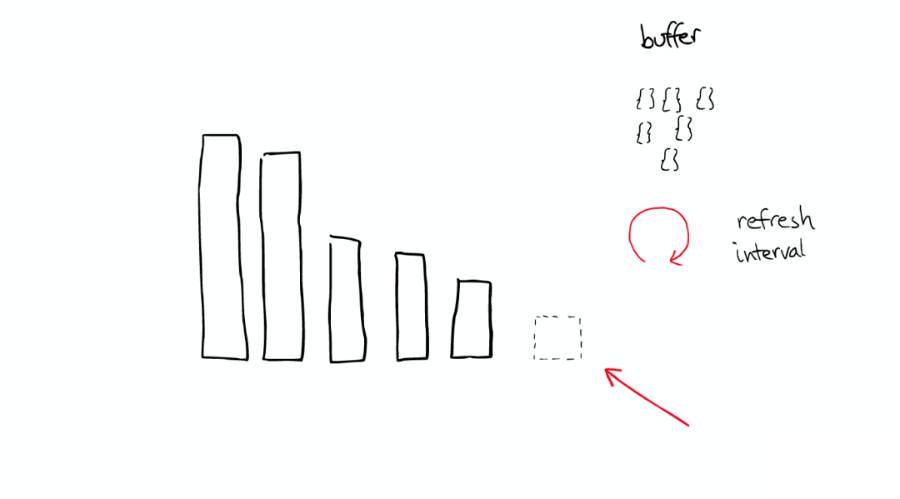
隨著時間的增加,我們會有很多 Segments,如下圖:
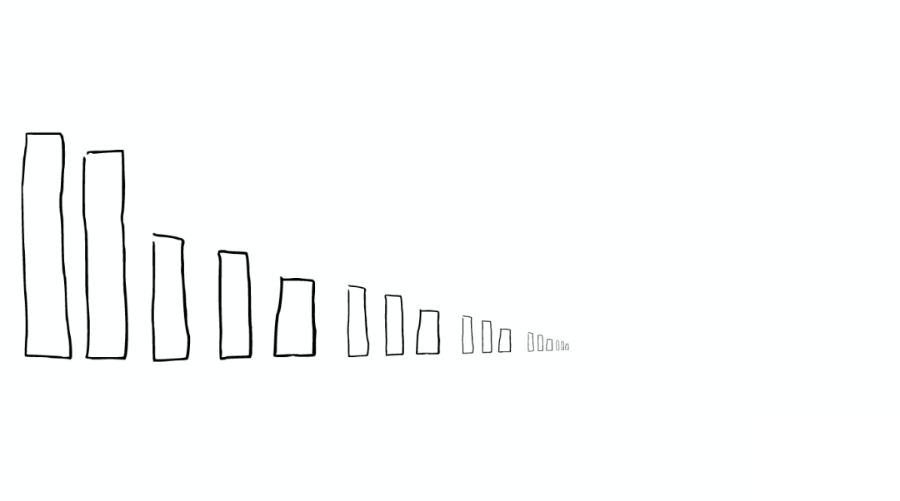
所以 ElasticSearch 會將這些 Segment 合并,在這個過程中,Segment 會最終被刪除掉。
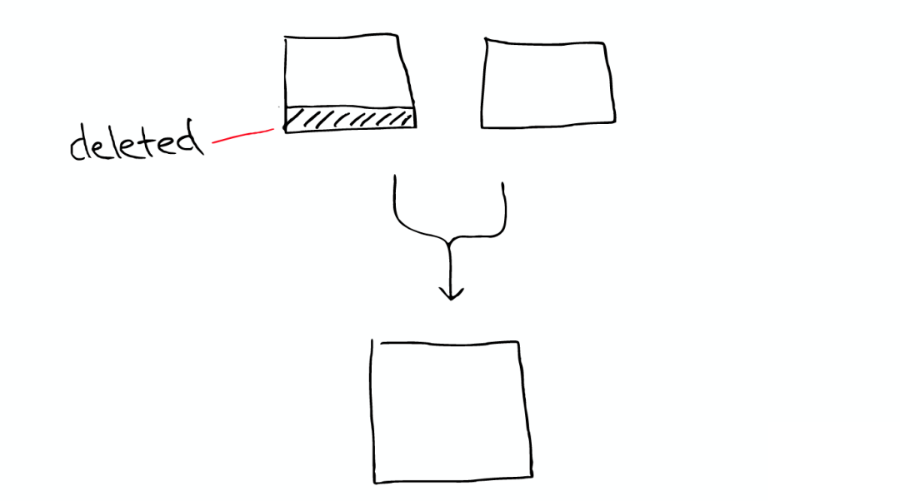
這就是為什么增加文件可能會使索引所占空間變小,它會引起 Merge,從而可能會有更多的壓縮。
舉個栗子
有兩個 Segment 將會 Merge:

這兩個 Segment 最終會被刪除,然后合并成一個新的 Segment,如下圖:
這時這個新的 Segment 在緩存中處于 Cold 狀態,但是大多數 Segment 仍然保持不變,處于 Warm 狀態。
以上場景經常在 Lucene Index 內部發生的,如下圖:
在 Shard 中搜索
ElasticSearch 從 Shard 中搜索的過程與 Lucene Segment 中搜索的過程類似。
與在 Lucene Segment 中搜索不同的是,Shard 可能是分布在不同 Node 上的,所以在搜索與返回結果時,所有的信息都會通過網絡傳輸。
需要注意的是:1 次搜索查找 2 個 Shard=2 次分別搜索 Shard。
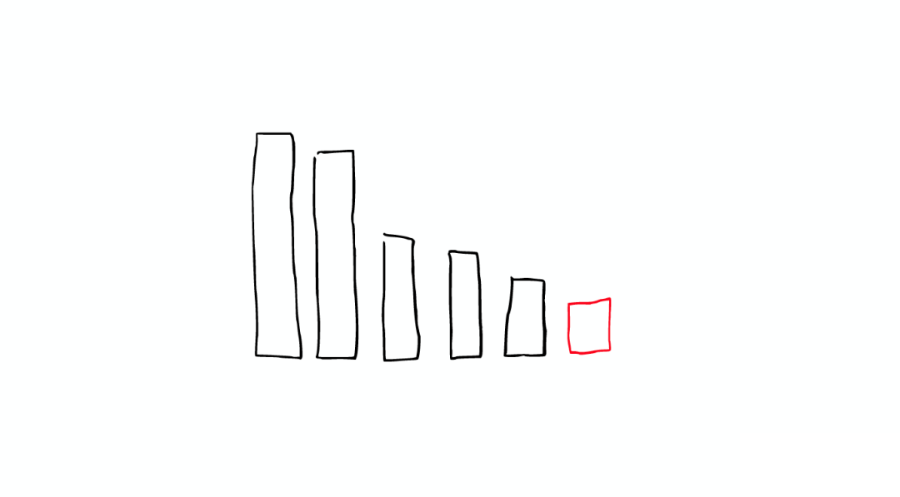
對于日志文件的處理:當我們想搜索特定日期產生的日志時,通過根據時間戳對日志文件進行分塊與索引,會極大提高搜索效率。
當我們想要刪除舊的數據時也非常方便,只需刪除老的索引即可。
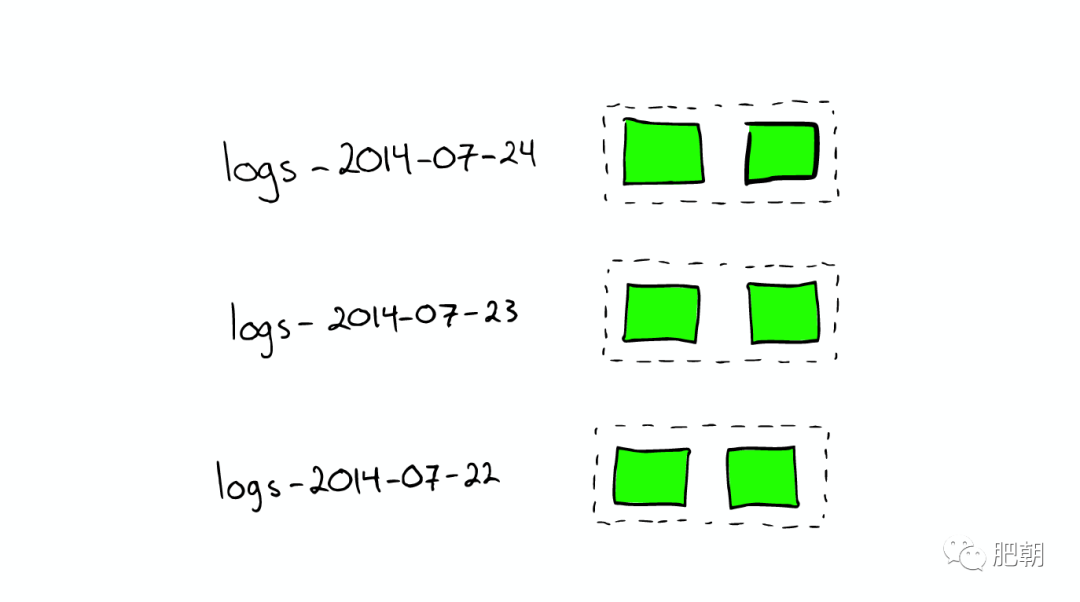
在上種情況下,每個 Index 有兩個 Shards。
如何 Scale
如下圖:
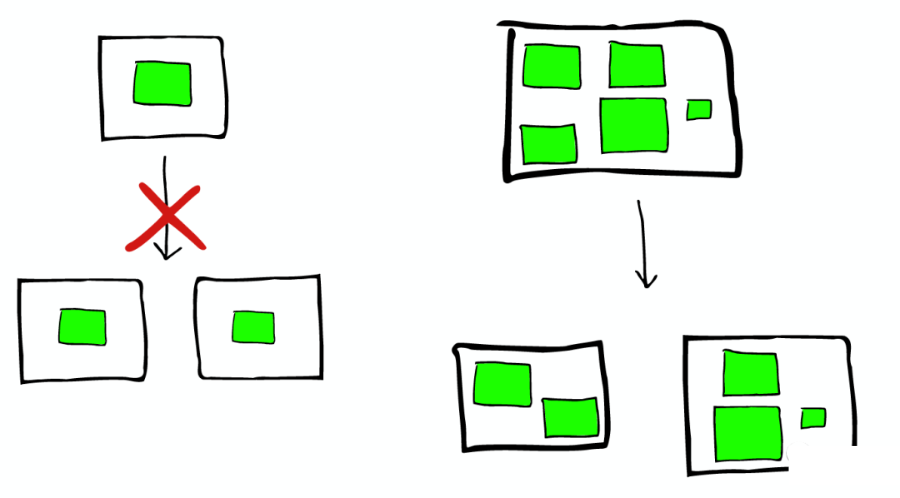
Shard 不會進行更進一步的拆分,但是 Shard 可能會被轉移到不同節點上。
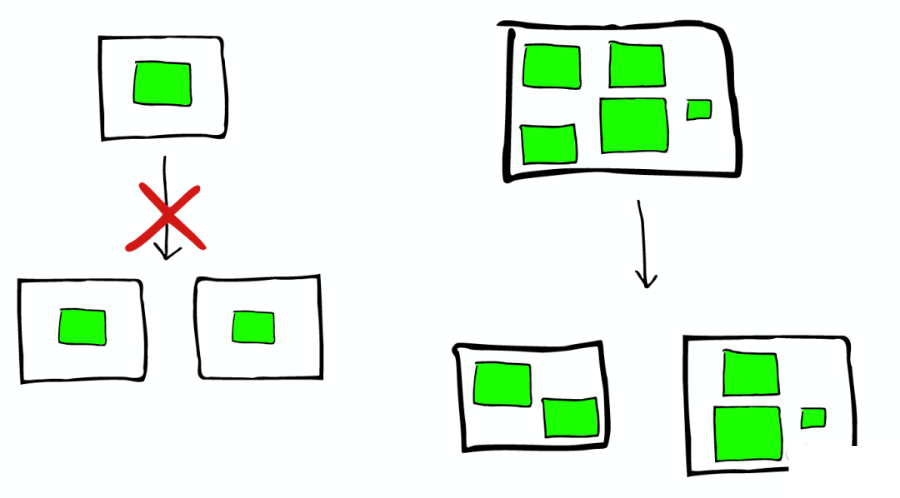
所以,如果當集群節點壓力增長到一定的程度,我們可能會考慮增加新的節點,這就會要求我們對所有數據進行重新索引,這是我們不太希望看到的。 所以我們需要在規劃的時候就考慮清楚,如何去平衡足夠多的節點與不足節點之間的關系。
節點分配與 Shard 優化:
為更重要的數據索引節點,分配性能更好的機器。
確保每個 Shard 都有副本信息 Replica。
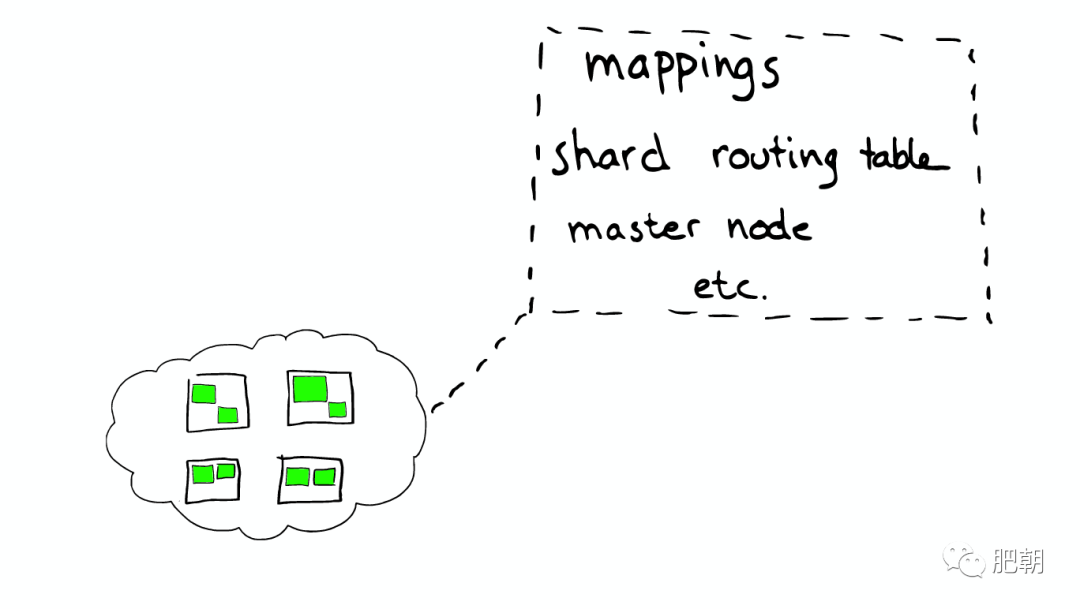
路由 Routing:每個節點,每個都存留一份路由表,所以當請求到任何一個節點時,ElasticSearch 都有能力將請求轉發到期望節點的 Shard 進一步處理。
一個真實的請求
如下圖:

①Query
如下圖:

Query 有一個類型 filtered,以及一個 multi_match 的查詢。
②Aggregation
如下圖:

根據作者進行聚合,得到 top10 的 hits 的 top10 作者的信息。
③請求分發
這個請求可能被分發到集群里的任意一個節點,如下圖:
④上帝節點
如下圖:
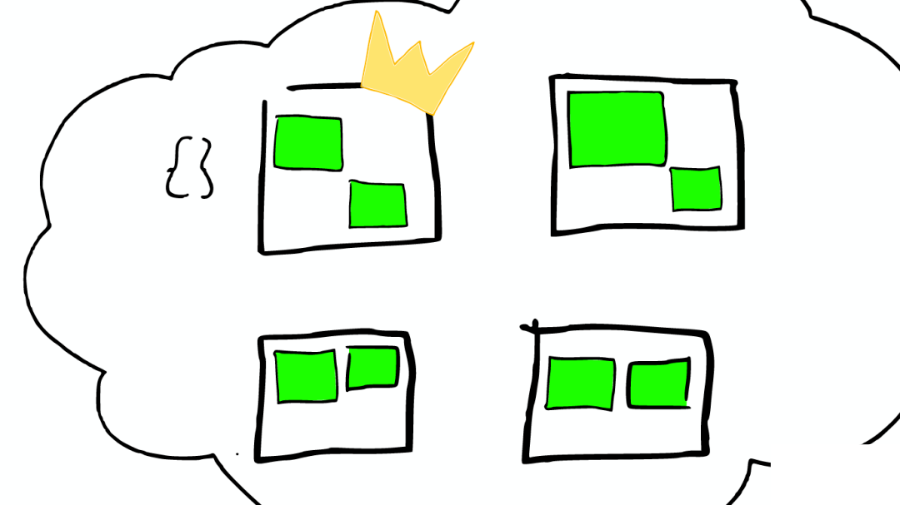
這時這個節點就成為當前請求的協調者(Coordinator),它決定:
根據索引信息,判斷請求會被路由到哪個核心節點。
以及哪個副本是可用的。
等等。
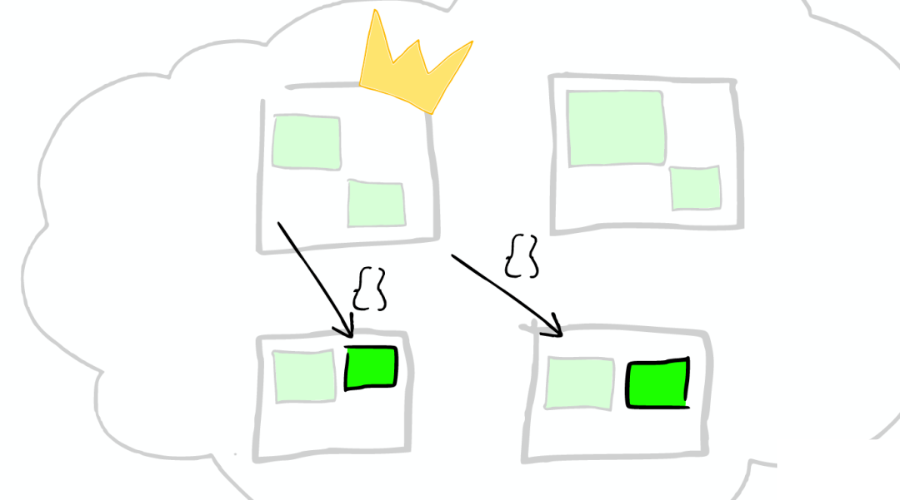
⑤路由
如下圖:
⑥在真實搜索之前
ElasticSearch 會將 Query 轉換成 Lucene Query,如下圖:
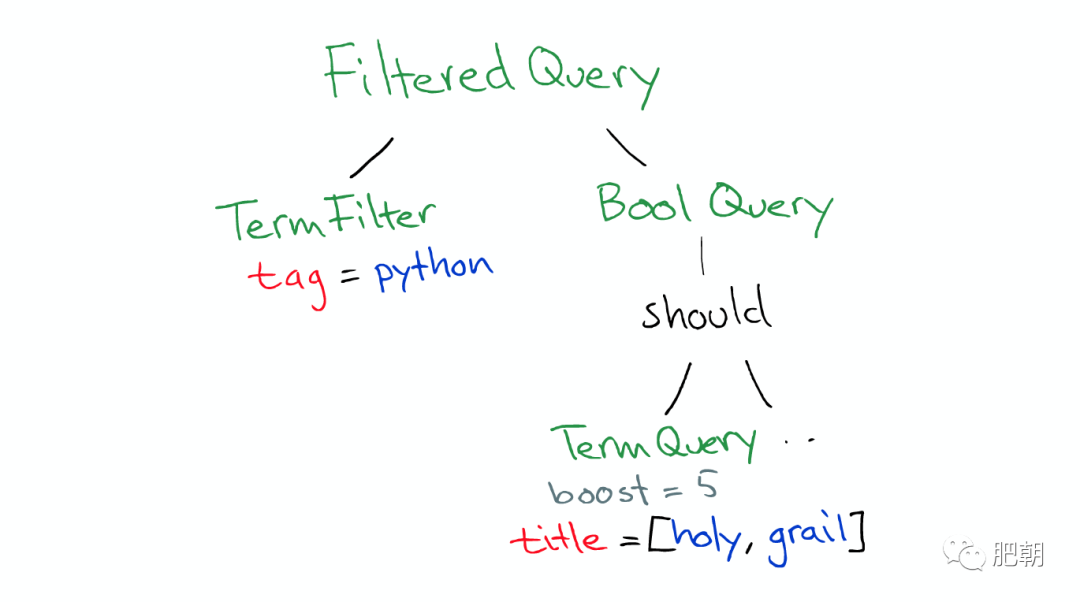
然后在所有的 Segment 中執行計算,如下圖:
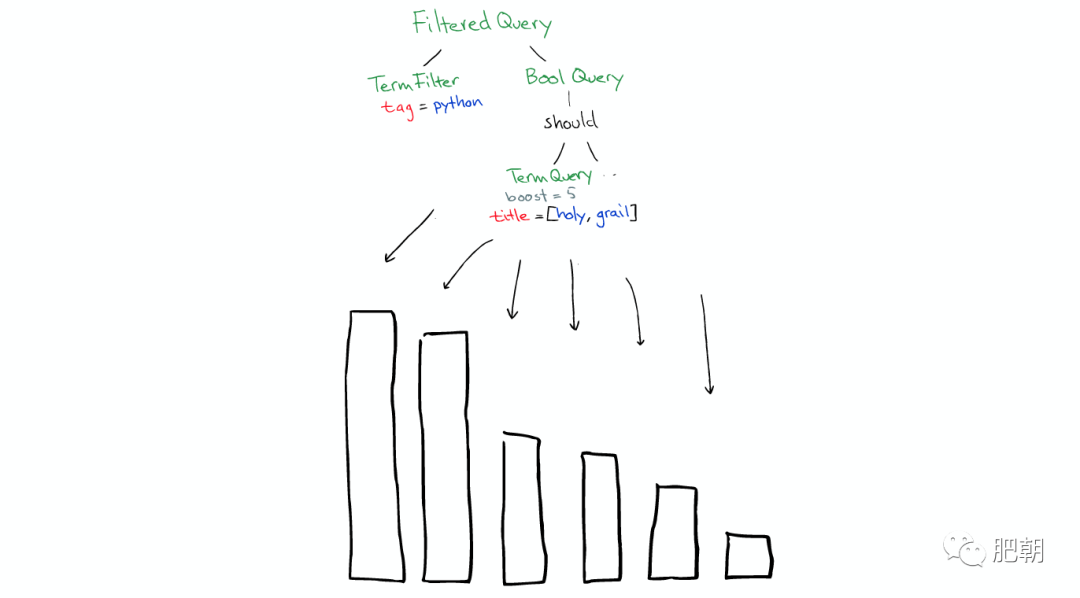
對于 Filter 條件本身也會有緩存,如下圖:
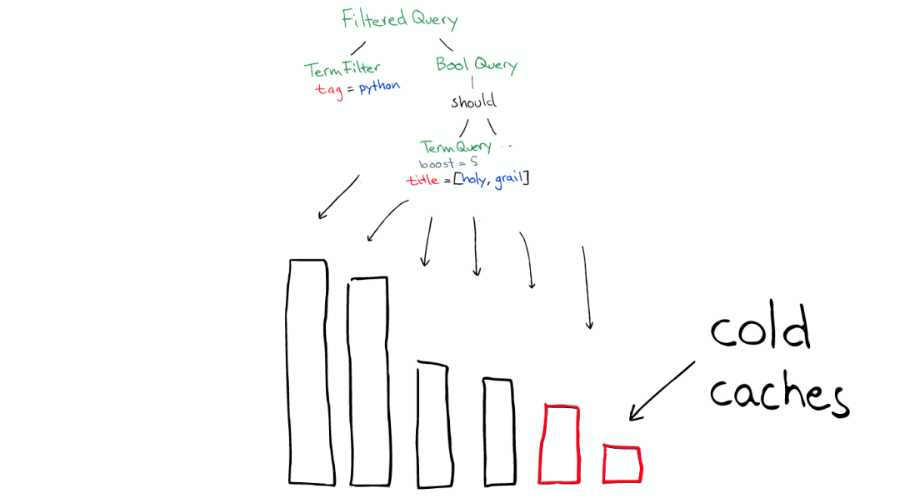
但 Queries 不會被緩存,所以如果相同的 Query 重復執行,應用程序自己需要做緩存。

所以:
Filters 可以在任何時候使用。
Query 只有在需要 Score 的時候才使用。
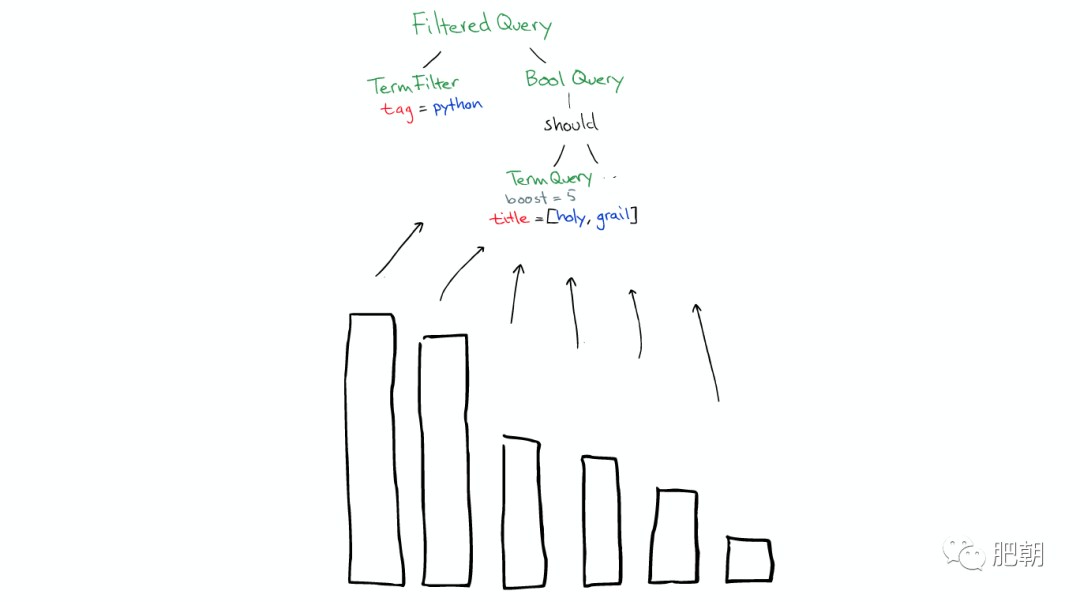
⑦返回
搜索結束之后,結果會沿著下行的路徑向上逐層返回,如下圖:

原文標題:圖解 ElasticSearch 原理,你可收好了!
文章出處:【微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
數據
+關注
關注
8文章
6909瀏覽量
88849 -
互聯網
+關注
關注
54文章
11115瀏覽量
103033
原文標題:圖解 ElasticSearch 原理,你可收好了!
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
手機直連衛星市場崛起!華為首發三網衛星通信手機,四大芯片廠商跟進

儲能系統的“指揮官”——功率驅動芯片
江波龍:LPDDR5量產,LPDDR5X在研,AI端側落地促消費電子回彈
智能底盤持續發展,底盤域MCU的國產機會
聯發科技推出Genio 130智能插座解決方案
MHMF082L41N-MINAS A6 系列 Block動作應用說明資料 -I/F啟動- 松下

MHMF082L41N-MINAS A6S 系列 技術資料 -基本功能規格篇- 松下
MHMF082L41N-MINAS A6S 系列 技術資料 -Modbus通信規格?Block 動作功能篇- 松下
Elasticsearch 再次開源

啟明信息完成國產化Doris數據庫升級替代任務
軟件系統的數據檢索設計
統一日志數據流圖
Elasticsearch Mapping類型修改
Rust編寫的首個Postgres基礎Elasticsearch開源替代品問世

號稱取代 Elasticsearch,太猛了!





 工商網監
工商網監
評論