") 愛奇藝深度學(xué)習(xí)平臺(tái)對(duì)TF Serving毛刺問題的優(yōu)化
愛奇藝深度學(xué)習(xí)平臺(tái)對(duì)TF Serving毛刺問題的優(yōu)化
在點(diǎn)擊率 CTR(Click Through Rate)預(yù)估算法的推薦場(chǎng)景中使用 TensorFlow Serving 熱更新較大模型時(shí)會(huì)出現(xiàn)短暫的延時(shí)毛刺,導(dǎo)致業(yè)務(wù)側(cè)超時(shí),降低算法效果,為了解決這個(gè)問題,愛奇藝深度學(xué)習(xí)平臺(tái)團(tuán)隊(duì)經(jīng)過(guò)多個(gè)階段的優(yōu)化實(shí)踐,最后對(duì) TF Serving 和 TensorFlow 的源碼進(jìn)行深入優(yōu)化,將模型熱更新時(shí)的毛刺現(xiàn)象解決,本文將分享 TensorFlow Serving 的優(yōu)化細(xì)節(jié),希望對(duì)大家有幫助。
背景介紹
TensorFlow Serving是谷歌開源的用來(lái)部署機(jī)器學(xué)習(xí)模型的高性能推理系統(tǒng)。它主要具備如下特點(diǎn):
同時(shí)支持 gRPC 和 HTTP 接口
支持多模型,多版本
支持模型熱更新和版本切換
TensorFlow Serving
https://github.com/tensorflow/serving
愛奇藝深度學(xué)習(xí)平臺(tái)上大量的 CTR 推薦類業(yè)務(wù)使用 TensorFlow Serving 來(lái)部署線上推理服務(wù)。
CTR 類業(yè)務(wù)對(duì)線上服務(wù)的可持續(xù)性要求很高,如果模型升級(jí)時(shí)要中斷服務(wù)是不可接受的,因此 TF Serving 的模型熱更新功能對(duì)這樣的業(yè)務(wù)場(chǎng)景提供了很大的幫助,可以避免重啟容器來(lái)做模型升級(jí)。
但是,隨著業(yè)務(wù)對(duì)模型更新實(shí)時(shí)性的要求越來(lái)越高,我們發(fā)現(xiàn),模型熱更新時(shí)出現(xiàn)的短暫客戶端請(qǐng)求超時(shí)現(xiàn)象(稱之為毛刺現(xiàn)象)變成進(jìn)一步提升實(shí)時(shí)性的一個(gè)比較大的障礙。
模型更新時(shí)的毛刺現(xiàn)象
先來(lái)看一下,
什么是模型更新時(shí)的毛刺現(xiàn)象?
下面這張圖是我們?cè)?TF Serving 代碼中增加了 Bvar(https://github.com/apache/incubator-brpc/blob/master/docs/cn/bvar.md) 來(lái)查看內(nèi)部請(qǐng)求的延遲情況。圖中是延遲的分位比,延遲分位值分別為 [p80, p90, p99, p999],單位是微秒。
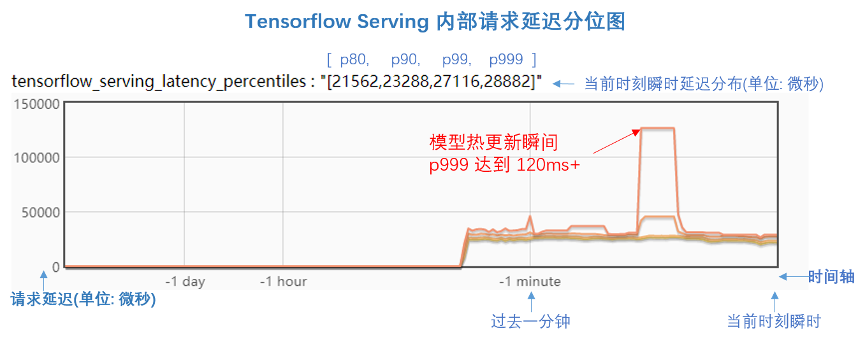
從圖中可以看到,在模型更新前后,p999的延遲都在 30ms以下。但是,在模型更新的瞬間,p999延遲突然抖動(dòng)到 120ms+,持續(xù)了大概 10 秒時(shí)間,這就是毛刺現(xiàn)象,反應(yīng)到客戶端就是會(huì)產(chǎn)生請(qǐng)求超時(shí)失敗。
為了完全解決這個(gè)問題,愛奇藝深度學(xué)習(xí)平臺(tái)經(jīng)過(guò)多個(gè)階段的深入優(yōu)化,最后將模型更新時(shí)的毛刺現(xiàn)象解決。
TF Serving 的模型更新過(guò)程
工欲善其事必先利其器,我們先來(lái)看看 TF Serving 內(nèi)部的模型更新過(guò)程。
如上圖,Source會(huì)啟動(dòng)一個(gè)線程來(lái)不斷查看模型文件,然后將發(fā)現(xiàn)的新模型構(gòu)建相應(yīng)的 Servable 數(shù)據(jù)結(jié)構(gòu)放到 Aspired Versions 的隊(duì)列中去。
DynamicManager也會(huì)啟動(dòng)一個(gè)線程,來(lái)不斷查看 Aspired Versions隊(duì)列是否有需要處理的請(qǐng)求,根據(jù)配置的 Version Policy 來(lái)執(zhí)行模型更新策略,最后通過(guò) SessionBundle來(lái)執(zhí)行模型的加載和卸載。
Version Policy 默認(rèn)為 AvailabilityPreservingPolicy,該 policy 的特點(diǎn)是當(dāng)有新的模型加入時(shí),會(huì)保證至少有一個(gè)可服務(wù)的模型版本,當(dāng)新版本加載完成后,再卸載舊版本,這樣可以最大程度的保證模型的可服務(wù)性。
舉例子來(lái)講,如果只支持一個(gè)模型版本,當(dāng)前版本是 2,如果有新的版本 3 加入,那么會(huì)先加載版本 3,然后再卸載版本 2。
接下來(lái),詳細(xì)看一下 TF Serving 的模型加載過(guò)程,主要分成以下幾個(gè)步驟:
創(chuàng)建一個(gè) DirectSession
將模型的 Graph 加載到 Session 中
執(zhí)行 Graph 中的 Restore Op 來(lái)將變量從模型中讀取到內(nèi)存
執(zhí)行 Graph 中的 Init Op 做相關(guān)的模型初始化
如果配置了 Warmup,執(zhí)行 Warmup 操作,通過(guò)定義好的樣本來(lái)預(yù)熱模型
TensorFlow 的模型執(zhí)行有個(gè)非常顯著的特點(diǎn)是 lazy initialization,也就是如果沒有 Warmup,當(dāng) TF Serving 加載完模型,其實(shí)只是加載了 Graph 和變量,Graph 中的 OP 其實(shí)并沒有做初始化,只有當(dāng)客戶端第一次發(fā)請(qǐng)求過(guò)來(lái)時(shí),才會(huì)開始初始化 OP。
問題的初步優(yōu)化
從上面的分析來(lái)看,可以看到初步的解決方案,那就是做模型的 Warmup,具體方案如下:
配置模型 Warmup,在模型目錄中增加 tf_serving_warmup_requests 文件
使用獨(dú)立線程來(lái)做模型的加載和卸載操作,配置 num_unload_threads和 num_load_threads
模型如何做 Warmup 詳細(xì)請(qǐng)參考 TF 的文檔 SavedModel Warmup。
https://tensorflow.google.cn/tfx/serving/saved_model_warmup
第二項(xiàng)優(yōu)化主要是參考美團(tuán)的文章基于 TensorFlow Serving 的深度學(xué)習(xí)在線預(yù)估。
https://tech.meituan.com/2018/10/11/tfserving-improve.html
我們來(lái)對(duì)比一下優(yōu)化前后的區(qū)別:
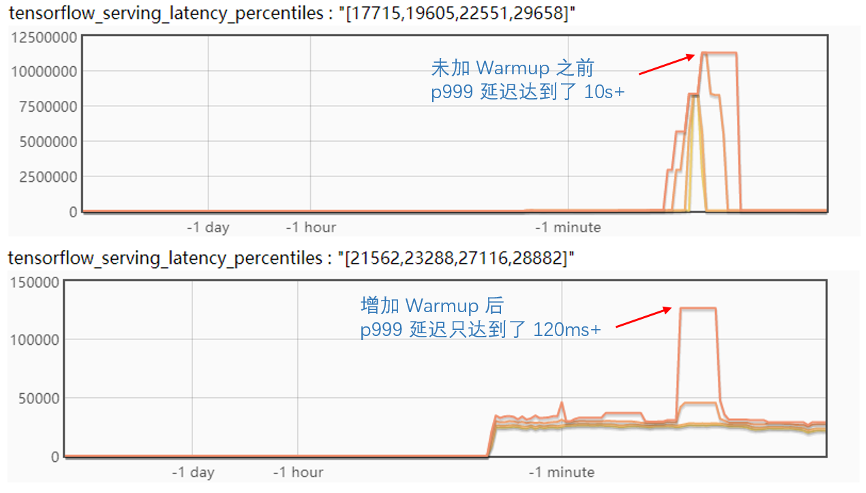
可以看到,使用上面的優(yōu)化,抖動(dòng)的延遲減少了幾個(gè)數(shù)量級(jí),效果很明顯。
問題的進(jìn)一步優(yōu)化
雖然上面的優(yōu)化將模型更新時(shí)的毛刺降低到只有 120ms+,但是這個(gè)仍然會(huì)對(duì)客戶端的請(qǐng)求產(chǎn)生超時(shí)現(xiàn)象,如果模型更新的頻率不高,比如一天更新一次,那么基本上是可以接受的。
但是,如果業(yè)務(wù)對(duì)模型更新的實(shí)時(shí)性到一個(gè)小時(shí)以內(nèi),甚至更高,那么就必須進(jìn)一步解決毛刺問題。我們不得不繼續(xù)思考,剩下的這個(gè)毛刺是由于什么原因產(chǎn)生的?
TF Serving 是一個(gè)計(jì)算密集型的服務(wù),對(duì)可能產(chǎn)生影響的因素,我們做了如下猜測(cè):
計(jì)算原因:是不是新模型的初始化,包括 Warmup 的計(jì)算,影響了推理請(qǐng)求?
內(nèi)存原因:是不是模型更新過(guò)程中的內(nèi)存分配或釋放產(chǎn)生鎖而導(dǎo)致的?
或者兩者都有?
計(jì)算原因分析
先來(lái)分析一下計(jì)算方面的原因,如果模型加載會(huì)影響到推理請(qǐng)求,那么能不能將模型的加載也用獨(dú)立的線程來(lái)做?
經(jīng)過(guò)調(diào)研 TF Serving 的源碼,我們發(fā)現(xiàn)了這樣的參數(shù),原來(lái) TF 已經(jīng)考慮到這樣的因素。
// If set, session run calls use a separate threadpool for restore and init // ops as part of loading the session-bundle. The value of this field should // correspond to the index of the tensorflow::ThreadPoolOptionProto defined as // part of session_config.session_inter_op_thread_pool. google.protobuf.Int32Value session_run_load_threadpool_index = 4;
通過(guò)配置 session_inter_op_thread_pool并設(shè)置 session_run_load_threadpool_index可以將模型的初始化放在獨(dú)立的線程。
修改配置后,并做了相關(guān)驗(yàn)證,如下圖。
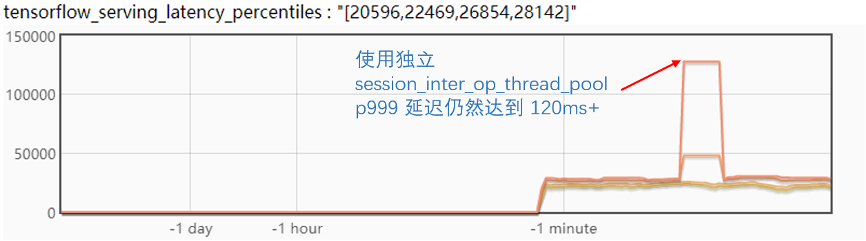
驗(yàn)證的結(jié)論很遺憾,使用獨(dú)立的線程來(lái)處理模型初始化并不能緩解毛刺問題。
從而,進(jìn)一步分析了 TF Serving 的線程機(jī)制,發(fā)現(xiàn)計(jì)算部分主要集中在 TF 的 Inter 和 Intra Op 線程,在模型初始化線程獨(dú)立出來(lái)后,原來(lái)的推理請(qǐng)求基本不會(huì)被影響到。
另外,經(jīng)過(guò)分析還發(fā)現(xiàn),TF 在執(zhí)行 Restore Op 的時(shí)候會(huì)創(chuàng)建額外的線程池來(lái)恢復(fù)大的變量,于是嘗試將 Restore 時(shí)的線程池去掉,發(fā)現(xiàn)仍然沒有效果。
內(nèi)存原因分析
先來(lái)看一下 TF 內(nèi)存的分配機(jī)制,TF 的 GPU 顯存是通過(guò) BFC (best-fit with coalescing) 算法來(lái)分配的,CPU 內(nèi)存分配是直接調(diào)用底層 glibc ptmalloc2 的 memory allocation。
目前平臺(tái)上 CTR 類業(yè)務(wù)基本都是 CPU 推理,因此內(nèi)存的分配和釋放都是通過(guò) glibc ptmalloc2 來(lái)管理的。
經(jīng)過(guò)調(diào)研了解到,Linux glibc 的內(nèi)存管理也是經(jīng)過(guò)優(yōu)化的,原來(lái)的實(shí)現(xiàn)是 dlmalloc,對(duì)多線程的支持并不好,現(xiàn)在的 ptmalloc2 是優(yōu)化后支持了多線程。
如果要深入到 ptmalloc2 優(yōu)化內(nèi)存管理就比較麻煩,不過(guò)調(diào)研發(fā)現(xiàn)已經(jīng)有了開源的優(yōu)化方案,那就是谷歌的 Tcmalloc和 Facebook 的 Jemalloc。
Tcmalloc
http://goog-perftools.sourceforge.net/doc/tcmalloc.html)
Jemalloc
http://jemalloc.net/
Ptmalloc,Tcmalloc 和 Jemalloc 的優(yōu)缺點(diǎn)網(wǎng)上有很多分析的文章,都指出 Tcmalloc 和 Jemalloc 在多線程環(huán)境下有比較好的性能,大體從原理上來(lái)講是區(qū)分大小內(nèi)存塊的分配,各個(gè)線程有自己內(nèi)存分配區(qū)域,減少鎖競(jìng)爭(zhēng)。
對(duì)比試驗(yàn)了三個(gè)內(nèi)存分配器,實(shí)驗(yàn)結(jié)果如下圖:
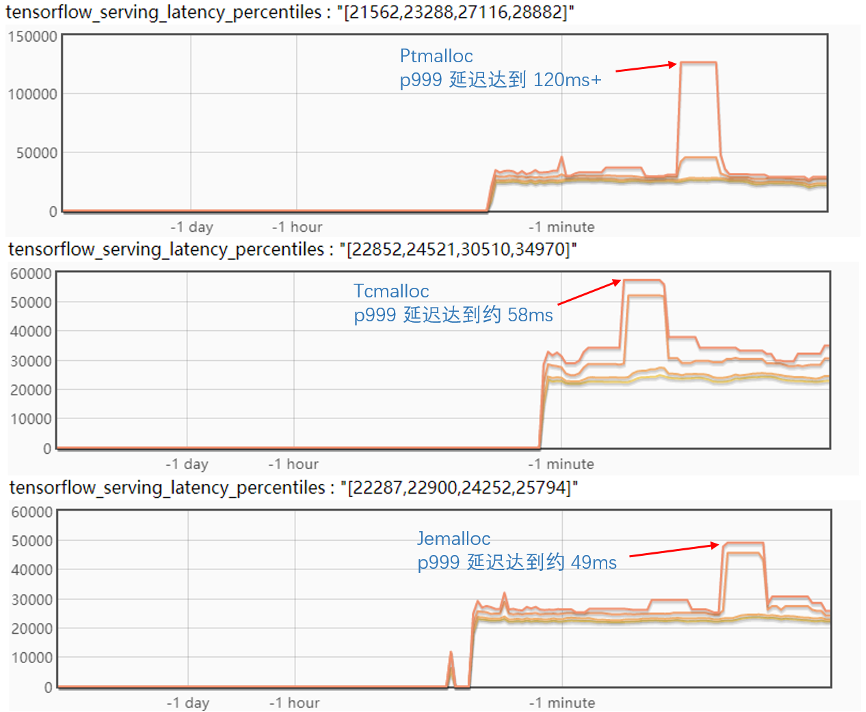
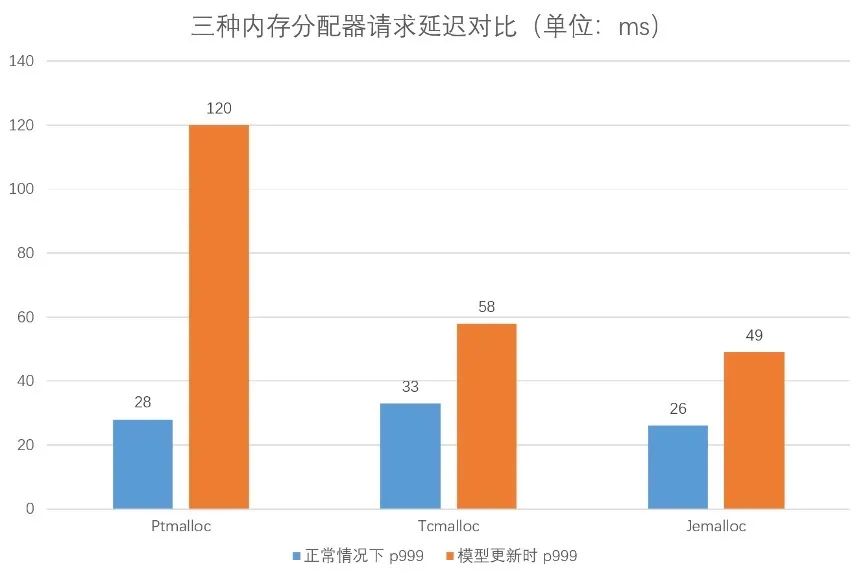
從實(shí)驗(yàn)結(jié)果來(lái)看,Tcmalloc 和 Jemalloc 對(duì)毛刺都有比較好的緩解,但是 Tcmalloc 會(huì)增加正常情況下的 p999 延遲;而反觀 Jemalloc 的毛刺 p999 降到了 50ms 以下,正常情況下的 p999 比 Ptmalloc也有所優(yōu)化。
看起來(lái) Jemalloc 是一個(gè)相對(duì)比較理想的方案,不過(guò)在進(jìn)一步的試驗(yàn)中發(fā)現(xiàn),如果同時(shí)更新兩個(gè)版本,Jemalloc 的 p999 毛刺會(huì)達(dá)到近 60ms,并且更新后會(huì)有一個(gè)比較長(zhǎng)的延遲抖動(dòng)期,會(huì)持續(xù)近一分鐘時(shí)間,如下圖:
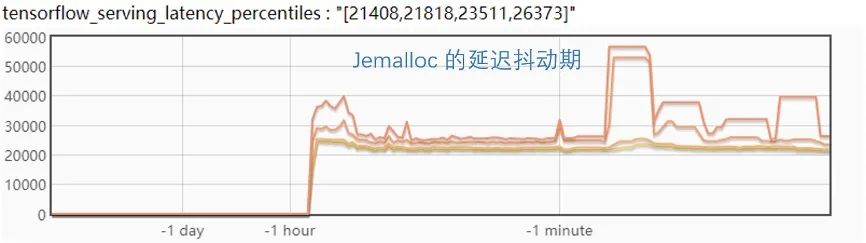
優(yōu)化到這一步,如果對(duì)這樣的延遲變化不敏感的話,基本就可以用 Jemalloc 來(lái)做為方案上線了,但對(duì)這樣的效果仍覺得不是非常理想,因此進(jìn)行了更深入的優(yōu)化。
問題的最終深入優(yōu)化
上面內(nèi)存方案的優(yōu)化效果提供了一個(gè)很好的啟示和方向,毛刺的根本原因應(yīng)該在內(nèi)存的分配和釋放競(jìng)爭(zhēng)上,所以來(lái)進(jìn)一步分析 TF 的內(nèi)存分配。
TF 內(nèi)存分配和釋放的使用場(chǎng)景主要分成兩個(gè)部分:
一部分是模型 Restore 時(shí)變量本身 Tensor 的分配,這個(gè)是在加載模型時(shí)分配的,內(nèi)存的釋放是在模型被卸載的時(shí)候
一部分是 RPC 請(qǐng)求時(shí)網(wǎng)絡(luò)前向計(jì)算時(shí)的中間輸出Tensor 內(nèi)存分配,在請(qǐng)求處理結(jié)束后就被釋放
模型更新時(shí),新模型加載時(shí)的 Restore OP 有大量的內(nèi)存被分配,舊模型被卸載時(shí)的有很多對(duì)象被析構(gòu),大量?jī)?nèi)存被釋放。
而這個(gè)過(guò)程中,RPC 請(qǐng)求沒有中斷,這個(gè)時(shí)候兩者的內(nèi)存分配和釋放會(huì)產(chǎn)生沖突和競(jìng)爭(zhēng)關(guān)系。
因此設(shè)計(jì)了內(nèi)存分配隔離方案:
將模型本身參數(shù)的內(nèi)存分配和 RPC 請(qǐng)求過(guò)程中的內(nèi)存分配隔離開來(lái),讓它們的分配和釋放在不同的內(nèi)存空間。
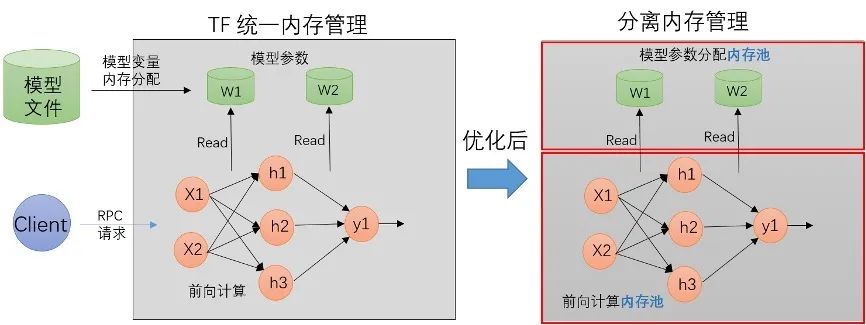
結(jié)合模型的更新,線上模型一個(gè)容器里面最多就兩個(gè)版本的模型文件,給每個(gè)模型版本各自分配了獨(dú)立的內(nèi)存池,用來(lái)做 AB 切換。
在代碼的編寫上,TF 剛好有一個(gè)現(xiàn)成的 BFC 內(nèi)存分配器,利用 BFC 做模型參數(shù)的內(nèi)存分配器,RPC 請(qǐng)求的內(nèi)存分配仍然使用 glibc ptmalloc2 來(lái)統(tǒng)一分配,因此最后的設(shè)計(jì)是這樣:
代碼改動(dòng)主要在 TF 的源碼,主要是對(duì) ProcessState,ThreadPoolDevice和 Allocator做了一些改動(dòng)。
最后來(lái)看一下試驗(yàn)效果:
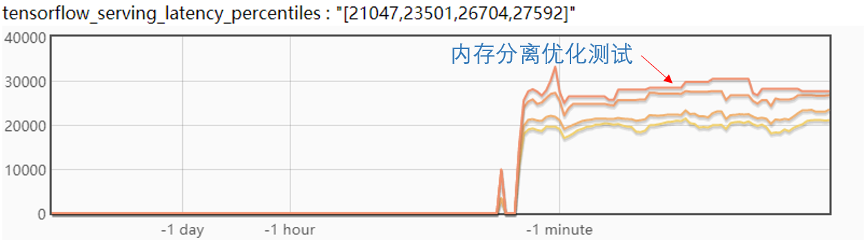
從圖中,可以看到模型更新后,延遲抖動(dòng)很少,大約在 2ms,在實(shí)際的線上測(cè)試高峰期大概有 5ms 的抖動(dòng),滿足業(yè)務(wù)需求。
總結(jié)
本文介紹了愛奇藝深度學(xué)習(xí)平臺(tái)對(duì) TF Serving 毛刺問題的優(yōu)化,主要?dú)w納如下:
配置模型 Warmup 文件來(lái)初預(yù)熱模型
使用 Jemalloc 做內(nèi)存分配優(yōu)化
TF 模型參數(shù)分配和 RPC 請(qǐng)求內(nèi)存分配分離
經(jīng)過(guò)實(shí)踐,每個(gè)方法都有進(jìn)一步的優(yōu)化,最后基本解決了模型熱更新過(guò)程中的毛刺問題。
— 參考文獻(xiàn) —
1. TF ServingAarchtecture
https://github.com/tensorflow/serving/blob/master/tensorflow_serving/g3doc/architecture.md
2. BVar
https://github.com/apache/incubator-brpc/blob/master/docs/cn/bvar.md
3. TF WarmUp
https://tensorflow.google.cn/tfx/serving/saved_model_warmup
4. 美團(tuán)基于 TensorFlow Serving 的深度學(xué)習(xí)在線預(yù)估
https://tech.meituan.com/2018/10/11/tfserving-improve.html
5. Google Tcmalloc
http://goog-perftools.sourceforge.net/doc/tcmalloc.html
6. Facebook Jemalloc: http://jemalloc.net/
責(zé)任編輯:xj
原文標(biāo)題:社區(qū)分享 | TensorFlow Serving 模型更新毛刺的完全優(yōu)化實(shí)踐
文章出處:【微信公眾號(hào):TensorFlow】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
毛刺
+關(guān)注
關(guān)注
0文章
29瀏覽量
15653 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120978 -
tensorflow
+關(guān)注
關(guān)注
13文章
328瀏覽量
60499
原文標(biāo)題:社區(qū)分享 | TensorFlow Serving 模型更新毛刺的完全優(yōu)化實(shí)踐
文章出處:【微信號(hào):tensorflowers,微信公眾號(hào):Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NPU在深度學(xué)習(xí)中的應(yīng)用
深度學(xué)習(xí)模型的魯棒性優(yōu)化
GPU深度學(xué)習(xí)應(yīng)用案例
FPGA做深度學(xué)習(xí)能走多遠(yuǎn)?
深度學(xué)習(xí)算法在嵌入式平臺(tái)上的部署
深度學(xué)習(xí)中的模型權(quán)重
深度學(xué)習(xí)模型訓(xùn)練過(guò)程詳解
深度學(xué)習(xí)的模型優(yōu)化與調(diào)試方法
深度學(xué)習(xí)編譯工具鏈中的核心——圖優(yōu)化





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論