 一種無監督下利用多模態文檔結構信息幫助圖片-句子匹配的采樣方法
一種無監督下利用多模態文檔結構信息幫助圖片-句子匹配的采樣方法
引 言
本文介紹了復旦大學數據智能與社會計算實驗室 (Fudan DISC) 在AAAI 2021上錄用的一篇關于多模態匹配的工作:An Unsupervised Sampling Approach for Image-Sentence Matching UsingDocument-Level Structural Information,提出了一種無監督設定下,更有效地利用多模態文檔的共現結構信息幫助采樣完成句子-圖片匹配的方法。本文的合作單位是杭州之江實驗室。
文章摘要
文章針對無監督的句子圖片匹配任務。現存的方法主要通過利用多模態文檔的圖片句子共現信息來無監督地采樣正負樣本對,但是其在獲得負樣本時只考慮了跨文檔的圖片句子對,在一定程度上引入了采樣的偏差,使得模型無法分辨同一文檔內語義較為近似的圖片和句子。
在本文中,我們提出了一種新的采樣的方法,通過引入同一文檔內的圖片句子對作為額外的正負樣本來減小采樣的偏差;進一步,我們提出了一個基于Transformer的模型來識別更為復雜的語義關聯,該模型為每個多模態文檔隱式地構建了一個圖的結構,構建了同一篇文檔內句子和圖片的表征學習間的橋梁。實驗的結果證明了我們提出的方法有效的減小偏差并且進一步獲得了更好的跨模態表征。
研究背景
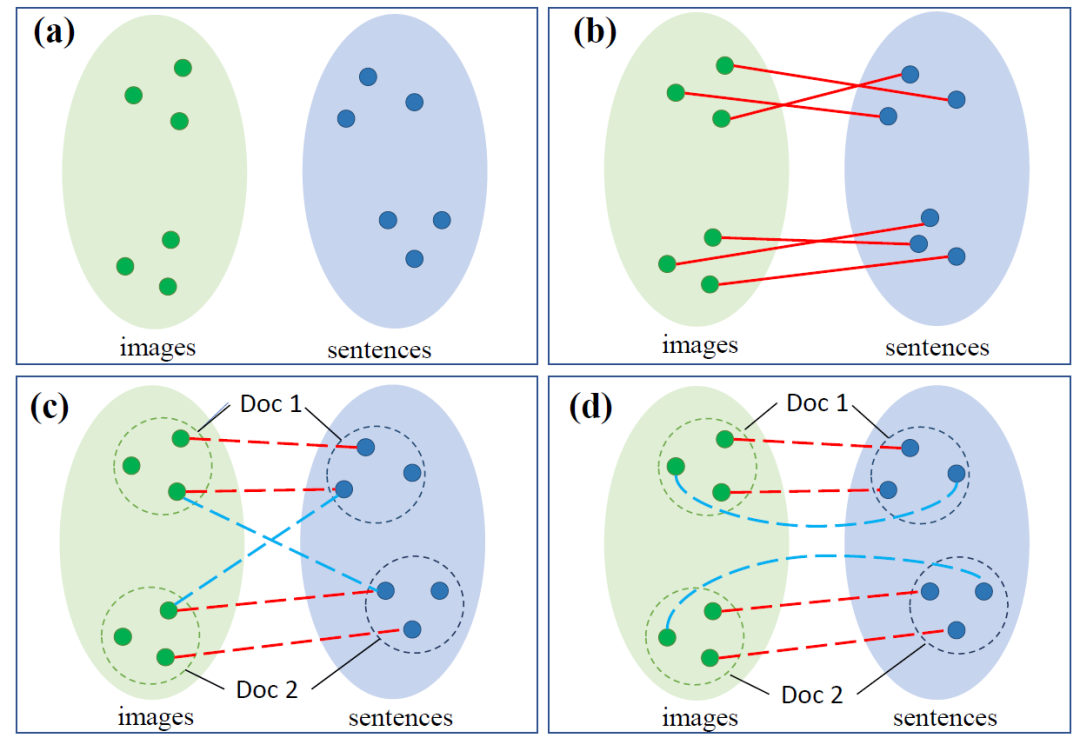
圖1. 句子-圖片匹配任務說明
(綠色/藍色點代表圖片/句子,紅色實線代表匹配關系的標簽,紅色/藍色虛線代表無監督方法選出的(偽)正/負樣本對)
圖片-句子的匹配一直是跨模態領域的基礎任務,其根本的目的是對其視覺和文本的語義空間。如(a)所示,兩個模態之間本身存在著語義空間上的差異,對其的常見方法是通過有監督的標簽拉近匹配的樣本對,如(b)所示。在無監督的環境下,最大的挑戰即為如何選擇出想要拉近的正樣本對和遠離的負樣本對。
如(c)所示,最近的無監督的方法通過文檔的圖片句子共現信息,通過拉近句子集合和圖片集合的方式來進行訓練,其中,同文檔內語義近似的句子-圖片對被看作正樣本,而跨文檔間的句子-圖片對被看作負樣本,如(c)所示,這樣的方法沒有考慮到文檔內部語義相似度更高的負樣本,其選出的負樣本與真實的負樣本分布存在著偏差。
于是本文提出了新的采樣策略,如(d)所示,我們引入了更多同一文檔內部的正負樣本對來幫助訓練。進一步,為了更好地識別同一文檔內更加復雜的句子圖片語義匹配模式,我們考慮使用更加細粒度的表征學習方法,提出了一個新的基于Transformer的模型,在其中為每個文檔的句子圖片間隱性建模了一個圖,來幫助獲得更好的跨模態表征。
方法描述
采樣方法
本文的方法基于三個部分的采樣,通過3個訓練目標實現,如圖2所示。
圖2. 三個部分的采樣和訓練目標示意
第一個部分為之前的工作提出的跨文檔訓練目標(cross-document objective)。其假設為同一文檔內的句子集合和圖片集合間的相似度要整體高于來自兩個不同文檔的句子集合和圖片集合間的相似度,背后通過一定的方式來選出幾個句子圖片對之間的相似度來代表句子集合和圖片集合間的相似度。其采樣得到的正樣本為來自同一文檔的語義較為近似的句子-圖片對;負樣本為來自不同文檔的語義較為近似的圖片句子對。
第二個部分為文檔內部的訓練目標(intra-document objective)。其假設為同一篇文檔內部的語義近似的圖片句子對之間的相似度也要高于內部語義相差較遠的圖片句子對間的相似度,高于一定的值,在此目標下采樣出的正樣本為來自同一文檔的語義較為近似的句子-圖片對;負樣本為來自同一文檔的語義相差較遠的圖片句子對。
第三個部分為次跨文檔訓練目標(dropout sub-document objective)。其假設為即使一篇文檔我們將其隨機的遮蓋住部分的句子/圖片,剩下的殘缺文檔內的句子集合和圖片集合間的相似度也要高于跨文檔間的圖片集合-句子集合間的相似度。在此目標下采樣出的正樣本為來自同一“殘次”文檔的語義較為近似的句子-圖片對;負樣本為來自不同文檔的語義近似的圖片句子對。
跨模態表征模型
圖3. 總的模型結構示意
由于引入了更多的同一文檔內的圖片句子對,我們需要得到包含更細粒度信息的多模態表征,所以我們將圖片分割為區域,將句子分割為token,Transformer可以看作是帶有attention機制的圖網絡,我們通過兩個視覺/文本的Transformer對各模態內的(區域/token)節點進行編碼,與此同時我們引入了視覺的概念,這里我們將圖片區域預測出的標簽作為圖片包括的概念,將它們作為中間的橋梁將兩個模態的圖橋接起來。概念會直接加入到視覺的圖中,作為節點存在,而概念和文本端的關系通過共享的embedding層來實現。這樣的模型里,當句子里直接提到了區域里對應的概念時,我們的模型就能很快地捕捉到這樣的匹配關系。
實驗
我們在無監督的多句子多圖片文檔內的跨模態鏈接預測任務上進行了實驗,其中包括了基于MSCOCO, VIST構建出的三個文檔數據集。對于每一個文檔,其內部有多個句子和多個圖片,需要去預測其中句子和圖片間是否存在著鏈接的邊(匹配關系),使用AUC/P@1/P@5進行評估。相較于之前只使用cross-document objective的方法(表內MulLink),我們的方法有了明顯的提高。
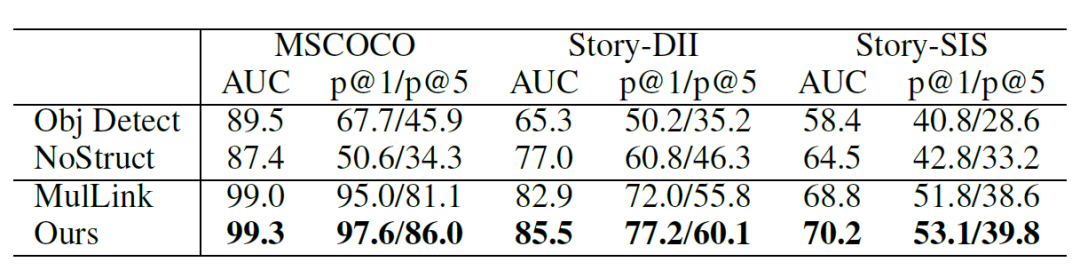
表1. 總的實驗結果
同時我們對我們提出的模型的結構,和三個部分的訓練目標進行了消融實驗:
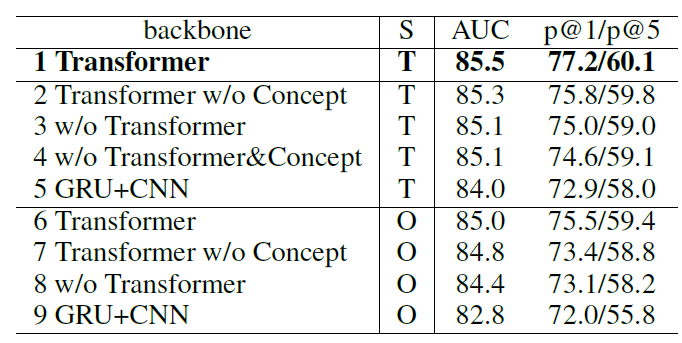
表2. 部分消融實驗的結果
(S列代表采樣方法,T代表同時使用三種目標訓練,O代表只使用跨文檔訓練目標,w/o代表without,w/o Transformer的方法里我們使用GRU對句子進行表征,對圖片的各個區域進行softmax pooling進行表征。)
可以看到整體上同時使用三種目標可以采樣到更多的信息,幫助訓練,我們也對三個目標進行了更加細致的消融實驗,詳情可以參考原文。同時我們提出的模型更好地利用了細粒度的信息,也獲得了更好地跨模態表征。
同時,我們進行了有監督、無監督和遷移學習的比較。有監督的方法直接使用文檔內的匹配的圖片句子對作為訓練,如圖4,遷移學習則嘗試遷移從MSCOCO上進行有監督訓練的信息到DII測試集上,如表3。
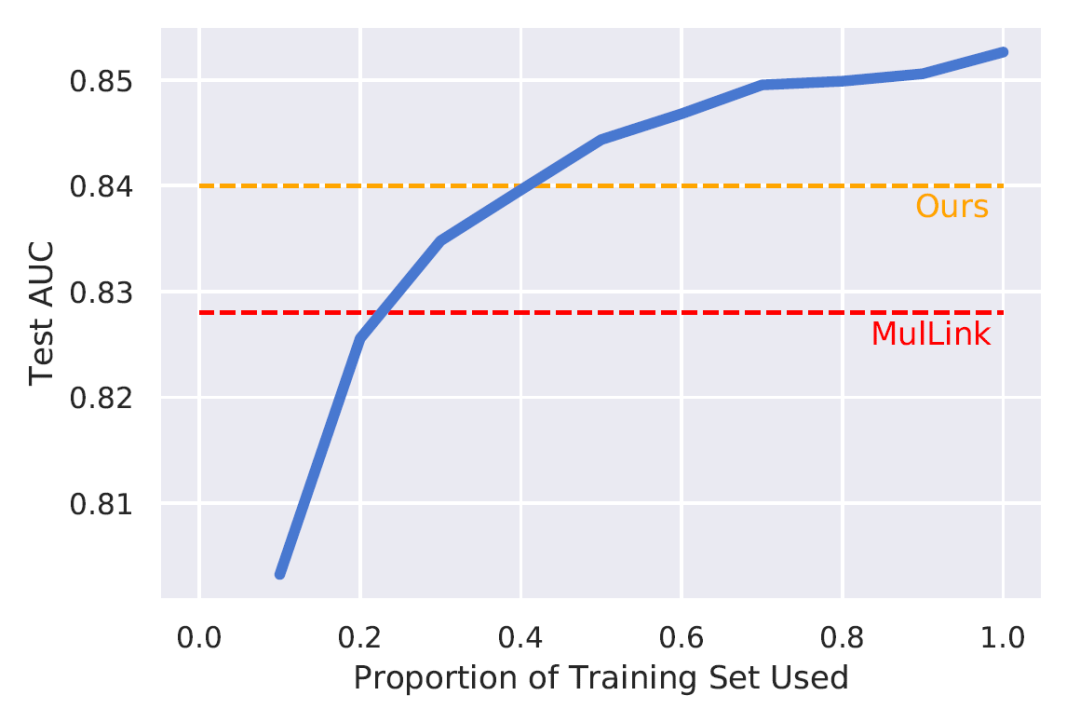
圖4. 有監督-無監督比較
藍色代表有監督學習下,隨著使用的數據增加在測試集上的表現

表3. 遷移學習和無監督學習的比較
可以看到相較于只使用跨文檔訓練目標,同時使用三種目標得到的更多樣本對里包括了更多的信息,我們無監督的方法可以利用訓練集內更多的信息(~40%),相較于遷移自其他數據集的信息,也更加有效。
除此之外,我們通過錯誤分析的方法驗證我們的方法對于偏差的修正效果。該偏差的表現為同一文檔內的句子和圖片更加近似,跨文檔內的圖片和句子差異更大,所以我們使用文檔內的句子/圖片表征的發散程度來代表這個差異,同一文檔內越發散,訓練和測試之間的差異越小。在DII上,我們使用每個文檔內句子/圖片的發散程度來擬合該文檔鏈接預測的AUC,原來的方法得到的線性模型的R方為42%,也就是說差異能很大程度解釋錯誤的原因,而我們的方法得到的R方為23%,這意味著該差異對于結果的作用減弱了,加上我們模型整體上更好地表現,我們可以認為我們減弱了采樣的偏差,使得偏差引起的錯誤減少了。
結論
在本文里,我們對于無監督的句子-圖片匹配任務,針對之前方法存在的采樣偏差問題提出了新的采樣策略,希望更高效地利用多模態文檔內句子和圖片共現的結構信息,引入了更多的來自同一文檔內的正/負圖片-句子對。同時提出了可以利用更細粒度信息的模型,建立了跨模態表征學習的關系橋梁。最終的實驗證明了我們方法的有效性。
責任編輯:xj
原文標題:【Fudan DISC】一種無監督下利用多模態文檔結構信息幫助圖片-句子匹配的采樣方法
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
語義
+關注
關注
0文章
21瀏覽量
8658 -
自然語言
+關注
關注
1文章
287瀏覽量
13332
原文標題:【Fudan DISC】一種無監督下利用多模態文檔結構信息幫助圖片-句子匹配的采樣方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種簡單高效配置FPGA的方法
利用OpenVINO部署Qwen2多模態模型

一種無透鏡成像的新方法

神經網絡如何用無監督算法訓練
深度學習中的無監督學習方法綜述
谷歌推出多模態VLOGGER AI
Meta發布新型無監督視頻預測模型“V-JEPA”
什么是多模態?多模態的難題是什么?

OCR終結了?曠視提出可以文檔級OCR的多模態大模型框架Vary,支持中英文,已開源!

ADC架構的無采樣保持(SHA-less)結構分析
大模型+多模態的3種實現方法

基于transformer和自監督學習的路面異常檢測方法分享






 工商網監
工商網監
評論