 機器人定位及建圖的準確性和魯棒性
機器人定位及建圖的準確性和魯棒性
將一個機器人隨機放入未知環境中,是否有辦法讓機器人一邊移動一邊確定自己的位置并構建該環境的地圖?近日,由重慶大學王科副教授帶領的團隊的論文 SBAS:Salient Bundle Adjustment for Visual SLAM,將顯著性預測模型應用于 SLAM 框架中去,模擬人類執行這一任務的過程,有效提升了機器人定位及建圖的準確性和魯棒性。
1. 什么是 SLAM?
SLAM 的全稱是 Simultaneous Localization And Mapping,即同時定位與建圖。
通俗來說,該技術希望搭載特定傳感器的機器人在未知的環境中,通過不斷的運動提取環境中的特征如墻角、柱子等來估計自身的位置,并同時根據傳感器觀測到的數據建立環境的地圖,從而達到同時定位和地圖構建的目的。
通常情況下,基于幾何的方法的 SLAM 技術可以分為兩類:特征法和直接法。
特征法通過提取和匹配圖像中的關鍵點通過最小化重投影誤差來估計相機的姿態,而直接法則直接利用圖像中的像素強度通過最小化光度誤差來估計相機的姿態。目前,該領域已經有了一些較為出色的算法模型。
MonoSLAM 是第一個使用擴展卡爾曼濾波(EKF)和 Shi-Tomasi 角點的實時視覺 SLAM 系統。該方法簡化了 SLAM 對硬件的要求,并可以被應用于仿人機器人實時 3D 定位和建圖以及手持相機的在線增強現實。

PTAM 是最早提出將 Track 和 Map 分開作為兩個線程的一種 SLAM 算法,也是一種基于關鍵幀的單目視覺 SLAM 算法。采用非線性優化方法代替基于濾波器的方法作為后端優化方法,PTAM 提出并實現了跟蹤映射過程的并行化。
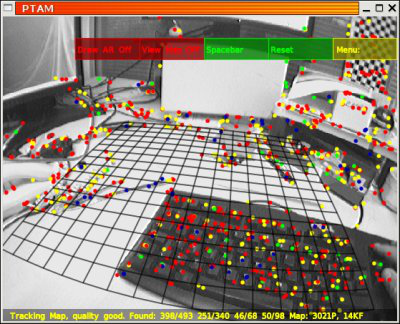
直接法不提取特征點,而是利用像素強度通過最小化光度誤差來估計攝像機的姿態。基于直接法的 SLAM 模型如下:
DTAM 是第一個使用直接方法生成密集三維地圖的系統。然而,它需要商用 GPU 來執行復雜的計算。為了提高效率,SVO 提取 FAST 特征,然后利用直接法的方式來估計攝像機的姿態和三維結構。

LSD-SLAM 擴展了這項工作,并且可以在大比例尺環境下生成半密集地圖。同時能夠將三維環境地圖實時重構為關鍵幀的姿態圖和對應的半稠密的深度圖。
除了基于幾何的方法的 SLAM 外,基于深度學習的 SLAM 憑借神經網絡強大的學習能力也取得了很大的進步。PoseNet 是最早使用 CNN 端到端估計相機姿態的方法之一。Deep VO 使用 RNN 來建模運動動力學和圖像序列之間的關系,ESP-VO 在此基礎上增加了位姿估計的不確定性估計。
2. 基于顯著性模型的 SLAM 框架
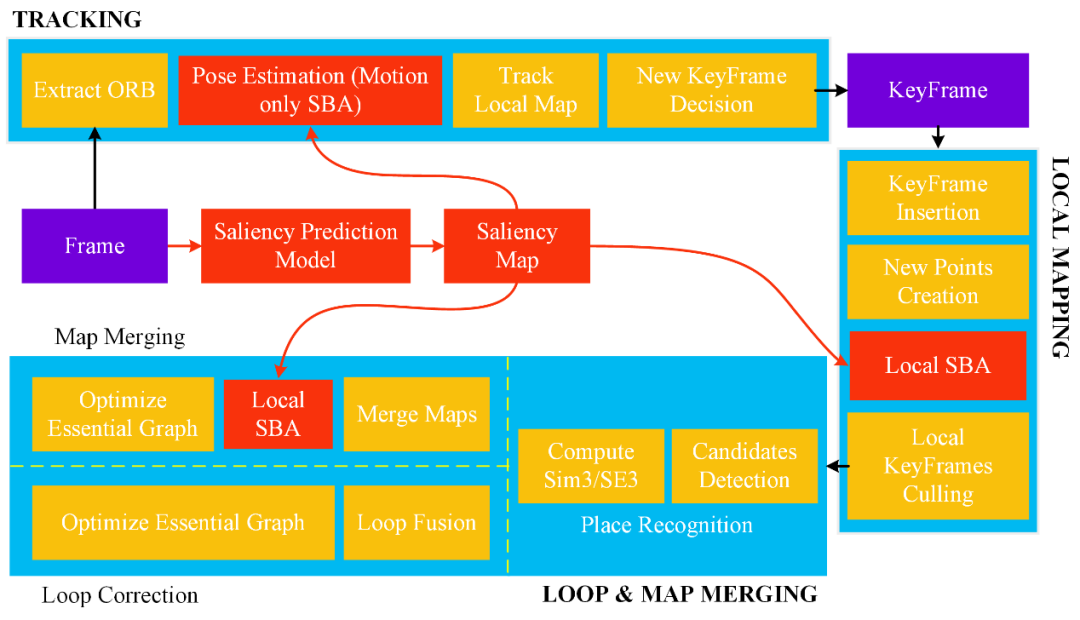
圖 | 框架總覽
為更好地解決現有 SLAM 框架的問題,作者提出了一個適用于室內和室外環境的 SLAM 框架,它可以應用于各種場景,具有較好的魯棒性和準確性。
上圖為整體框架的簡化說明,它包括兩個組件:基于幾何法的 SLAM 管道和基于深度學習的顯著性預測模塊。顯著性預測模塊生成與 SLAM 數據集相對應的顯著性圖。然后,將顯著性圖作為輸入,幫助 SLAM 選擇顯著的特征點,以提高定位的準確性和魯棒性。
視覺顯著性是指模仿人類視覺系統,從自然場景中選擇出最顯著、最感興趣的區域或點,以便在不同的任務下進行進一步的處理。近年來,有許多基于深度學習的方法來預測自然場景中的顯著性區域,并取得了很好的效果。然而,這些顯著性預測方法并不能完全描述 SLAM 系統應該關注的特征,原因是這些方法只使用原始的人類注視信息,例如,在駕駛車輛行駛的過程中,人類的注視通常停留在車輛前方的道路上,因為這是車輛行駛的地方。但是,這還不夠,因為 SLAM/VO 還需要聚焦在遠離圖像中心的區域,所以僅僅依靠人眼眼動跟蹤器獲得的凝視數據,并不能幫助 SLAM 系統捕捉所有這些重要線索。
為解決這一問題,作者通過結合幾何信息和語義信息,在 KITTI 數據集的基礎上,構造一個顯著性數據集 Salient-KITTI 來訓練顯著性模型,用語義注視代替人類注視。具體來說,作者首先提取圖像幾何信息如特征點、線和平面等。然后使用語義分割網絡 SDC Net 在感興趣對象周圍生成分割掩碼。
然后,作者選取了 13 個類別作為 SLAM 應該重點關注的對象(紅綠燈、交通標志、道路、建筑物、人行道、停車場、軌道、圍欄、橋梁、電線桿、桿群、植被、地形)來過濾幾何信息,因為這些類別中的區域通常包含顯著的、穩定和魯棒的特征。如下圖,其顯示了語義注視和人類注視地面真值的比較。

最后,基于該顯著性數據集,作者使用 DI-Net 獲得顯著性模型,并用它來預測初始顯著性圖,隨后根據圖像的深度信息得到最終的顯著性圖。
為了驗證顯著性模型的可行性,作者做了三個實驗:
a) 1、顯著性模型的有效性驗證。使用分別在 Saleint-KITTI 數據集和 SALICON 數據集上訓練的顯著性模型,驗證所提出的顯著性模型相對于其它顯著性模型的有效性。
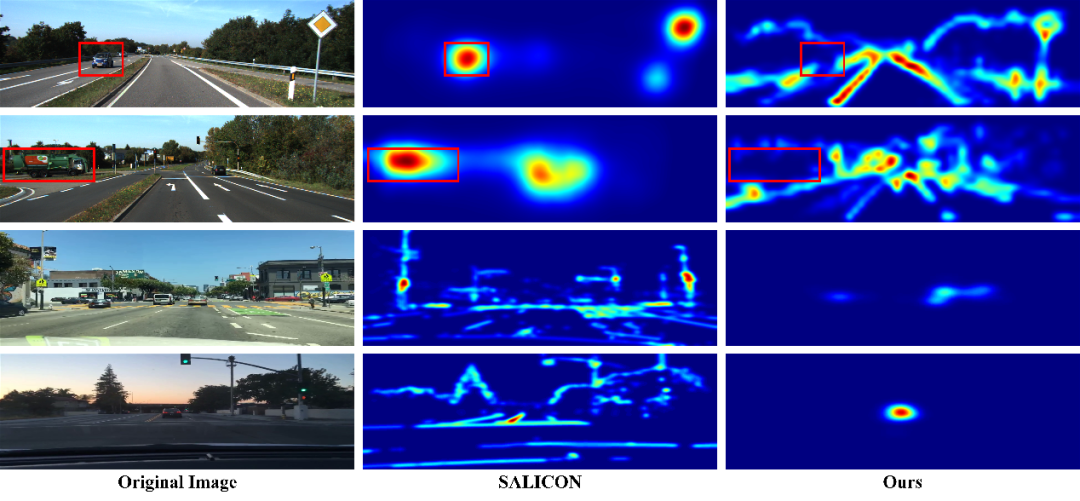
圖 | SALICON 和 KITTI 數據集訓練的顯著性模型的比較
結果顯示,對于基于 SALICON 數據集訓練的模型,當圖像中沒有顯著對象時,注意力集中在圖像的中心,從而忽略了其他重要信息,即我們所說的存在中心偏差。相反,在 Salient-KITTI 數據集上訓練的模型可成功地捕捉到這些重要信息。此外,該模型還可以減少動態對象的影響,因此具有顯著性值高的點通常是更穩定和魯棒的點。
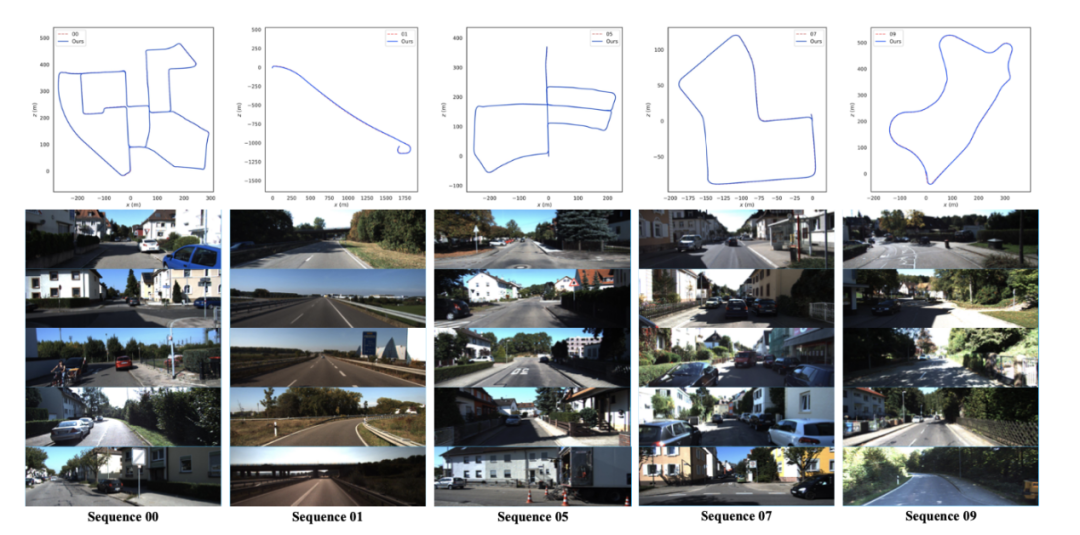
2、基于 KITTI 數據集的室外場景驗證。在單目和立體視覺配置中,作者提出的系統比 ORB-SLAM3 更精確,因為 SBA 使顯著特征點充分發揮其作用。同時,本實驗也證明利用顯著圖可以使算法在姿態估計方面有更多的優勢,具體效果如下圖所示。
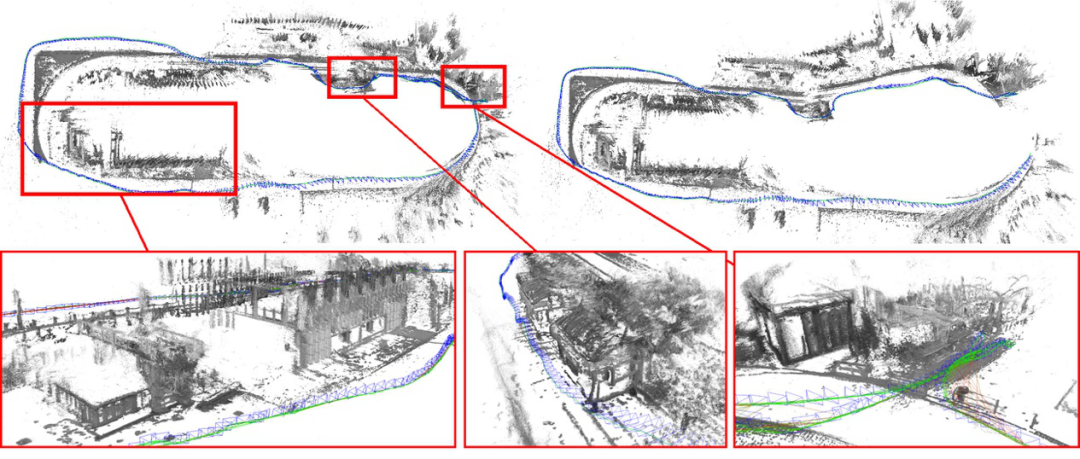
3、基于 EuRoc 數據集的室內場景驗證。在第三個實驗中,作者將算法與其他最先進的算法進行了比較,如 ORB-SLAM、DSM、DSO、突出 DSO 和 ORB-SLAM3。
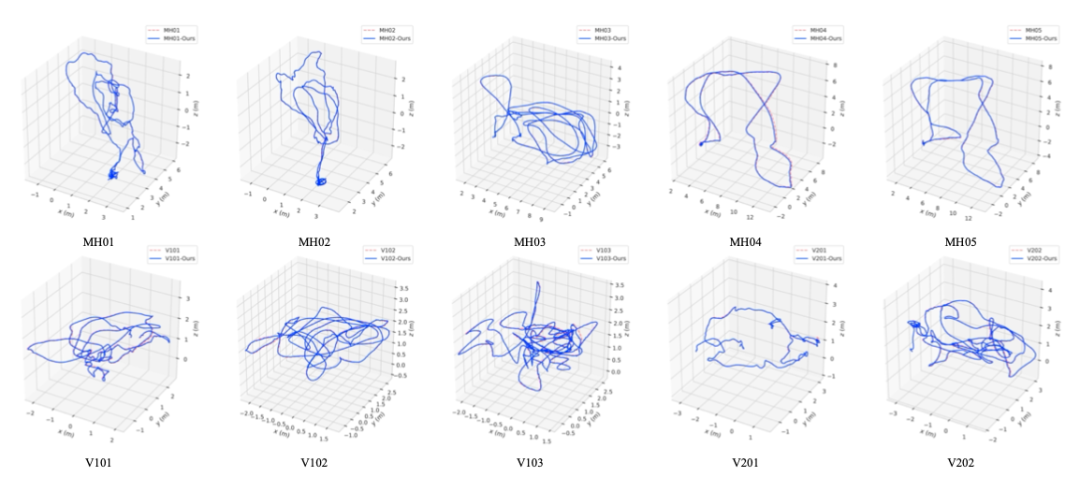
圖 | EuRoc 數據集的一些軌跡結果和地面真實情況
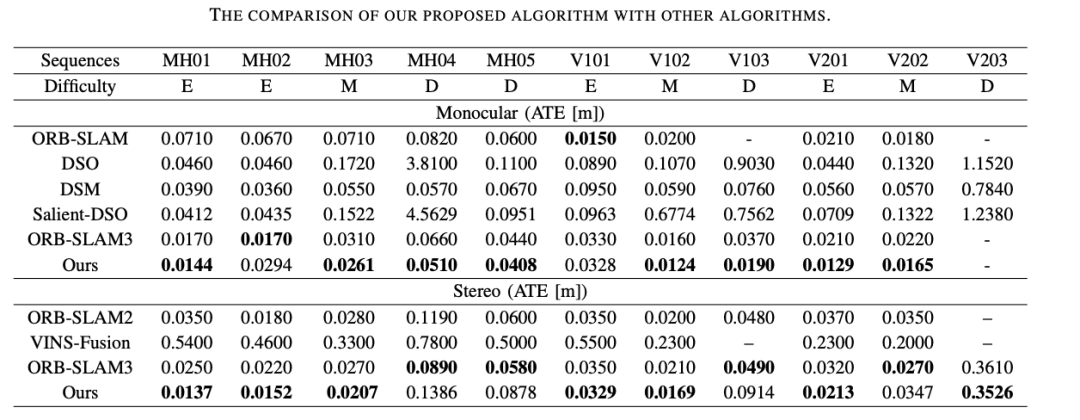
結果顯示,在大多數序列中,作者提出的模型在室內和室外環境下都能很好地工作,同時也比文獻中的最新技術獲得更精確的結果。
王科表示,該研究不僅僅針對自動駕駛,基于圖像處理的都可以用,它是一個基礎的算法,而非純應用的提升,只不過最初是在自動駕駛平臺做起來的。
而隨著 SLAM 技術的不斷發展,它們將被應用到越來越多的領域中,小到掃地機器人,大到無人駕駛技術、AR、VR 等,未來將為人類生活帶來極大的便利。
責任編輯:lq
-
算法
+關注
關注
23文章
4599瀏覽量
92639 -
SLAM
+關注
關注
23文章
419瀏覽量
31786 -
機器人視覺
+關注
關注
0文章
48瀏覽量
10016
原文標題:重慶大學研發定位與建圖技術,可讓機器人視覺更智能
文章出處:【微信號:deeptechchina,微信公眾號:deeptechchina】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何提升ASR模型的準確性
深度學習模型的魯棒性優化
魯棒性在機器學習中的重要性
如何提高系統的魯棒性
如何維護電流互感器的準確性
如何評估 ChatGPT 輸出內容的準確性
如何保證測長機測量的準確性?

傾斜光柵的魯棒性優化
影響電源紋波測試準確性的因素

基于計算設計的超魯棒性應變傳感器,實現軟體機器人的感知和自主性

怎樣測試電流探頭的準確性以及保證其精準性






 工商網監
工商網監
評論