") 如何使用Python+OpenCV+yolov5實(shí)現(xiàn)行人目標(biāo)檢測(cè)?
如何使用Python+OpenCV+yolov5實(shí)現(xiàn)行人目標(biāo)檢測(cè)?
目標(biāo)檢測(cè)支持許多視覺(jué)任務(wù),如實(shí)例分割、姿態(tài)估計(jì)、跟蹤和動(dòng)作識(shí)別,這些計(jì)算機(jī)視覺(jué)任務(wù)在監(jiān)控、自動(dòng)駕駛和視覺(jué)答疑等領(lǐng)域有著廣泛的應(yīng)用。隨著這種廣泛的實(shí)際應(yīng)用,目標(biāo)檢測(cè)自然成為一個(gè)活躍的研究領(lǐng)域。 我們?cè)贔ynd的研究團(tuán)隊(duì)一直在訓(xùn)練一個(gè)行人檢測(cè)模型來(lái)支持我們的目標(biāo)跟蹤模型。在本文中,我們將介紹如何選擇一個(gè)模型架構(gòu),創(chuàng)建一個(gè)數(shù)據(jù)集,并為我們的特定用例進(jìn)行行人檢測(cè)模型的訓(xùn)練。
什么是目標(biāo)檢測(cè)
目標(biāo)檢測(cè)是一種計(jì)算機(jī)視覺(jué)技術(shù),它允許我們識(shí)別和定位圖像或視頻中的物體。目標(biāo)檢測(cè)可以理解為兩部分,目標(biāo)定位和目標(biāo)分類(lèi)。定位可以理解為預(yù)測(cè)對(duì)象在圖像中的確切位置(邊界框),而分類(lèi)則是定義它屬于哪個(gè)類(lèi)(人/車(chē)/狗等)。
目標(biāo)檢測(cè)方法
解決目標(biāo)檢測(cè)的方法有很多種,可以分為三類(lèi)。
級(jí)聯(lián)檢測(cè)器:該模型有兩種網(wǎng)絡(luò)類(lèi)型,一種是RPN網(wǎng)絡(luò),另一種是檢測(cè)網(wǎng)絡(luò)。一些典型的例子是RCNN系列。
帶錨框的單級(jí)檢測(cè)器:這類(lèi)的檢測(cè)器沒(méi)有單獨(dú)的RPN網(wǎng)絡(luò),而是依賴于預(yù)定義的錨框。YOLO系列就是這種檢測(cè)器。
無(wú)錨框的單級(jí)檢測(cè)器:這是一種解決目標(biāo)檢測(cè)問(wèn)題的新方法,這種網(wǎng)絡(luò)是端到端可微的,不依賴于感興趣區(qū)域(ROI),塑造了新研究的思路。要了解更多,可以閱讀CornerNet或CenterNet論文。
什么是COCO數(shù)據(jù)集
為了比較這些模型,廣泛使用了一個(gè)稱為COCO(commonobjectsincontext)的公共數(shù)據(jù)集,這是一個(gè)具有挑戰(zhàn)性的數(shù)據(jù)集,有80個(gè)類(lèi)和150多萬(wàn)個(gè)對(duì)象實(shí)例,因此該數(shù)據(jù)集是初始模型選擇的一個(gè)非常好的基準(zhǔn)。
如何評(píng)估性能
評(píng)估性能我們需要評(píng)價(jià)目標(biāo)檢測(cè)任務(wù)的各種指標(biāo),包括:
PASCAL VOC挑戰(zhàn)(Everingham等人。2010年)
COCO目標(biāo)檢測(cè)挑戰(zhàn)(Lin等人。2014年)
開(kāi)放圖像挑戰(zhàn)賽(Kuznetsova 2018)。
要理解這些指標(biāo),你需要先去理解一些基本概念,如精確度、召回率和IOU。以下是公式的簡(jiǎn)要定義。
平均精度
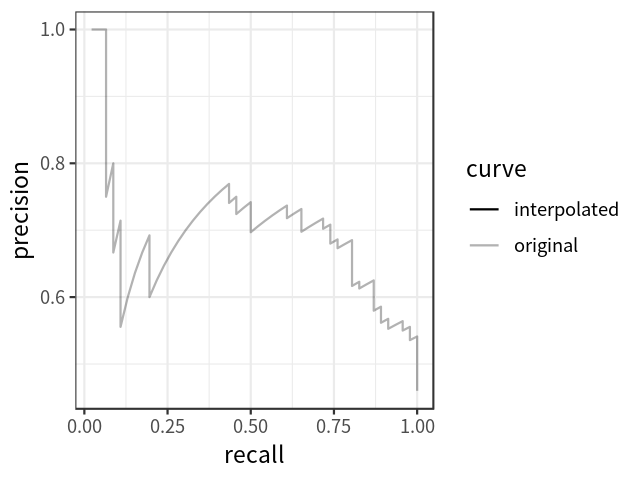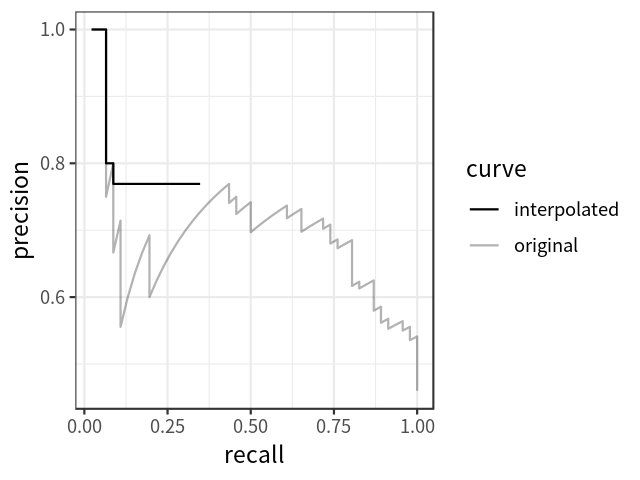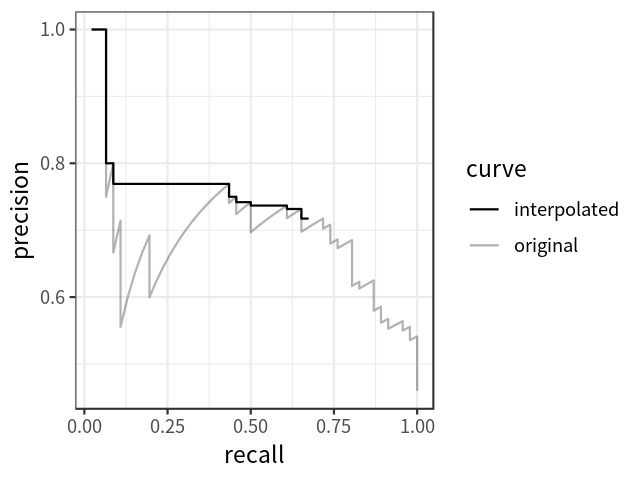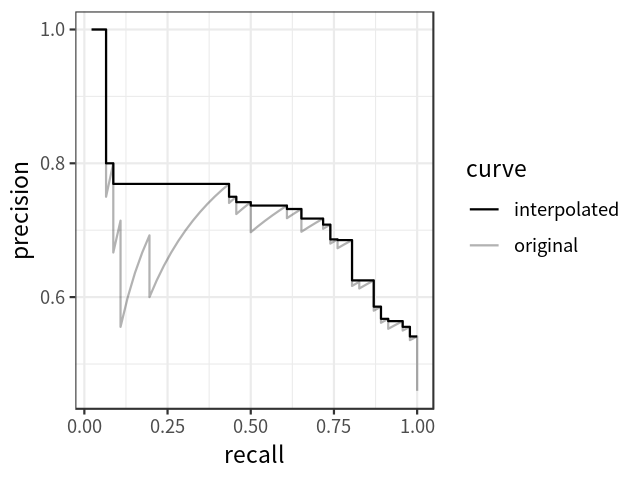
AP可定義為插值精度召回曲線下的面積,可使用以下公式計(jì)算:
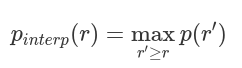
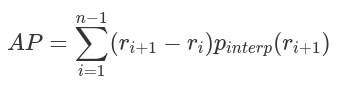
mAP
AP的計(jì)算只涉及一個(gè)類(lèi),然而,在目標(biāo)檢測(cè)中,通常存在K>1類(lèi)。平均精度(Mean average precision,mAP)定義為所有K類(lèi)中AP的平均值:
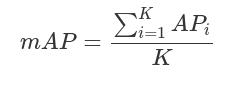
TIDE
TIDE是一個(gè)易于使用的通用工具箱,用于計(jì)算和評(píng)估對(duì)象檢測(cè)和實(shí)例分割對(duì)整體性能的影響。TIDE有助于更詳細(xì)地了解模型錯(cuò)誤,僅使用mAP值是不可能找出哪個(gè)錯(cuò)誤段導(dǎo)致的。TIDE可以繪制簡(jiǎn)單的圖表,使分析變得輕松。https://youtu.be/McYFYU3PXcU
實(shí)際問(wèn)題陳述
我們的任務(wù)是檢測(cè)零售店閉路電視視頻源中的人體邊界框,這是跟蹤模型的一個(gè)基礎(chǔ)模型,且其檢測(cè)所產(chǎn)生的所有誤差都會(huì)傳遞到跟蹤模型中。以下是在這類(lèi)視頻中檢測(cè)的一些主要挑戰(zhàn)。
挑戰(zhàn)
視角:CCTV是頂裝式的,與普通照片的前視圖不同,它有一個(gè)角度
人群:商店/商店有時(shí)會(huì)有非常擁擠的場(chǎng)景
背景雜亂:零售店有更多的分散注意力或雜亂的東西(對(duì)于我們的模特來(lái)說(shuō)),比如衣服、架子、人體模型等等,這些都會(huì)導(dǎo)致誤報(bào)。
照明條件:店內(nèi)照明條件與室外攝影不同
圖像質(zhì)量:來(lái)自CCTVs的視頻幀有時(shí)會(huì)非常差,并且可能會(huì)出現(xiàn)運(yùn)動(dòng)模糊
測(cè)試集創(chuàng)建
我們創(chuàng)建了一個(gè)驗(yàn)證集,其中包含來(lái)自零售閉路電視視頻的視頻幀。我們使用行人邊界框?qū)蚣苓M(jìn)行注釋,并使用mAP@0.50 iou閾值在整個(gè)訓(xùn)練迭代中測(cè)試模型。
第一個(gè)人體檢測(cè)模型
我們的第一個(gè)模型是一個(gè)COCO預(yù)訓(xùn)練的模型,它將“person”作為其中的一個(gè)類(lèi)。我們?cè)诿糠N方法中列出了2個(gè)模型,并基于COCO-mAP-val和推理時(shí)間對(duì)它們進(jìn)行了評(píng)估。
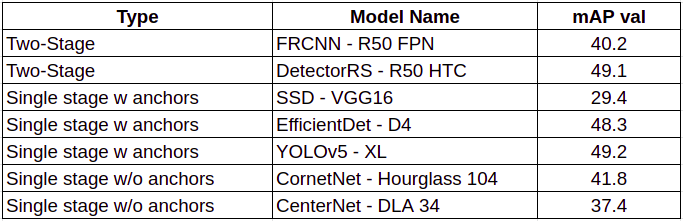
我們選擇YOLOv5是因?yàn)樗膯渭?jí)特性(快速推理)和在COCO mAP val上的良好性能,它還有YOLOv5m和YOLOv5s等更快的版本。
YOLOv5
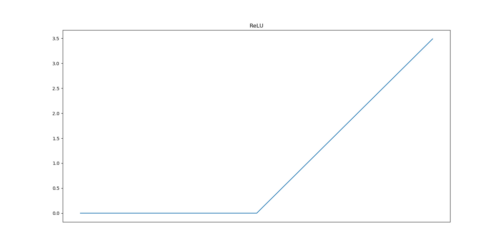
YOLO系列屬于單階段目標(biāo)探測(cè)器,與RCNN不同,它沒(méi)有單獨(dú)的區(qū)域建議網(wǎng)絡(luò)(RPN),并且依賴于不同尺度的錨框。架構(gòu)可分為三個(gè)部分:骨架、頸部和頭部。利用CSP(Cross-Stage Partial Networks)作為主干,從輸入圖像中提取特征。PANet被用作收集特征金字塔的主干,頭部是最終的檢測(cè)層,它使用特征上的錨框來(lái)檢測(cè)對(duì)象。 YOLO架構(gòu)使用的激活函數(shù)是Google Brains在2017年提出的Swish的變體,它看起來(lái)與ReLU非常相同,但與ReLU不同,它在x=0附近是平滑的。
損失函數(shù)是具有Logits損失的二元交叉熵
性能
0.48 mAP@0.50 IOU(在我們的測(cè)試集上)
分析
這個(gè)現(xiàn)成的模型不能很好地執(zhí)行,因?yàn)槟P褪窃贑OCO數(shù)據(jù)集上訓(xùn)練的,而COCO數(shù)據(jù)集包含一些不必要的類(lèi),包含人體實(shí)例的圖像數(shù)量較少,人群密度也較小。此外,包含人體實(shí)例的圖像分布與閉路電視視頻幀中的圖像分布有很大不同。
結(jié)論
我們需要更多的數(shù)據(jù)來(lái)訓(xùn)練包含更多擁擠場(chǎng)景和攝像機(jī)視角介于45?-60?(類(lèi)似于CCTV)的模型。
收集公共數(shù)據(jù)
我們的下一步是收集包含行人/行人邊界框的公共可用數(shù)據(jù)集。有很多數(shù)據(jù)集可用于人體檢測(cè),但我們需要一些關(guān)于數(shù)據(jù)集的附加信息,如視角、圖像質(zhì)量、人體密度和背景等,以獲取數(shù)據(jù)集的分布信息。 我們可以看到,滿足我們確切需求的數(shù)據(jù)集并不多,但我們?nèi)匀豢梢允褂眠@些數(shù)據(jù)集,因?yàn)槿梭w邊界框的基本要求已經(jīng)得到滿足。在下載了所有的數(shù)據(jù)集之后,我們把它轉(zhuǎn)換成一個(gè)通用的COCO格式進(jìn)行檢測(cè)。
第二個(gè)人體檢測(cè)模型
我們用收集到的所有公共數(shù)據(jù)集訓(xùn)練模型。
訓(xùn)練迭代2:
主干網(wǎng)絡(luò):YOLOv5x
模型初始化:COCO預(yù)訓(xùn)練的權(quán)重
epoch:10個(gè)epoch
性能
0.65 mAP @ 0.50 IOU
分析
隨著數(shù)據(jù)集的增加,模型性能急劇提高。有些數(shù)據(jù)集具有滿足我們的一個(gè)要求的高擁擠場(chǎng)景,有些包含滿足另一個(gè)需求的頂角攝影機(jī)視圖。
結(jié)論
雖然模型的性能有所提高,但有些數(shù)據(jù)集是視頻序列,而且在某些情況下背景仍然是靜態(tài)的,可能會(huì)導(dǎo)致過(guò)擬合。很少有數(shù)據(jù)集有非常小的人體,這使得任務(wù)很難學(xué)習(xí)。
清理數(shù)據(jù)
下一步是清理數(shù)據(jù)。我們從訓(xùn)練和驗(yàn)證集中篩選出損失最大的圖像,或者我們可以說(shuō)這些圖像具有非常少的mAP度量。我們選擇了一個(gè)0.3的閾值并將圖像可視化。我們從數(shù)據(jù)集中篩選出三種類(lèi)型的錯(cuò)誤。
錯(cuò)誤標(biāo)記的邊界框
包含非常小的邊界框或太多人群的圖像
重復(fù)幀的附近
為了去除重復(fù)幀,我們只從視頻序列中選擇稀疏幀。
第三個(gè)人體檢測(cè)模型
有了經(jīng)過(guò)清理和整理的數(shù)據(jù)集,我們就可以進(jìn)行第三次迭代了 訓(xùn)練迭代3:
主干網(wǎng)絡(luò):YOLOv5x
模型初始化:COCO預(yù)訓(xùn)練的權(quán)重
epoch:~100個(gè)epoch
性能
0.69 mAP @ 0.50 IOU
分析
當(dāng)未清理的數(shù)據(jù)從訓(xùn)練和驗(yàn)證集中移除時(shí),模型性能略有改善。
結(jié)論
數(shù)據(jù)集被清理,性能得到改善。我們可以得出結(jié)論,進(jìn)一步改進(jìn)數(shù)據(jù)集可以提高模型性能。為了提高性能,我們需要確保數(shù)據(jù)集包含與測(cè)試用例相似的圖像。我們處理了人群情況和一些視角的情況,但大多數(shù)數(shù)據(jù)仍然有一個(gè)前視角。
數(shù)據(jù)增強(qiáng)
我們列出了在實(shí)際情況下檢測(cè)時(shí)將面臨的一些挑戰(zhàn),但是收集到的數(shù)據(jù)集分布不同,因此,我們采用了一些數(shù)據(jù)擴(kuò)充技術(shù),使訓(xùn)練分布更接近實(shí)際用例或測(cè)試分布。 下面是我們對(duì)數(shù)據(jù)集進(jìn)行的擴(kuò)展。
視角
視角改變
照明條件
亮度
對(duì)比度
圖像質(zhì)量
噪音
圖像壓縮
運(yùn)動(dòng)模糊
通過(guò)將所有這些擴(kuò)展匯總,我們可以將公共數(shù)據(jù)分布更接近實(shí)際分布,我們將原始圖像和轉(zhuǎn)換后的圖像進(jìn)行比較,可以從下面的圖像中看到。
所有這些擴(kuò)展都是通過(guò)使用“albumentation”來(lái)應(yīng)用的,這是一個(gè)易于與PyTorch數(shù)據(jù)轉(zhuǎn)換集成的python庫(kù),他們還有一個(gè)演示應(yīng)用程序,我們用來(lái)設(shè)置不同方法的增強(qiáng)參數(shù)。庫(kù)中還有很多可以與其他用例一起使用的擴(kuò)展包。 我們使用albumentation方法來(lái)實(shí)現(xiàn)這一點(diǎn)。
第四個(gè)人體檢測(cè)模型
現(xiàn)在有了轉(zhuǎn)換后的數(shù)據(jù)集,我們就可以進(jìn)行第四次迭代了 訓(xùn)練迭代4: 主干網(wǎng)絡(luò):YOLOv5x 模型初始化:迭代3中的模型 epoch:~100個(gè)epoch
性能
0.77 mAP @ 0.50 IOU
分析
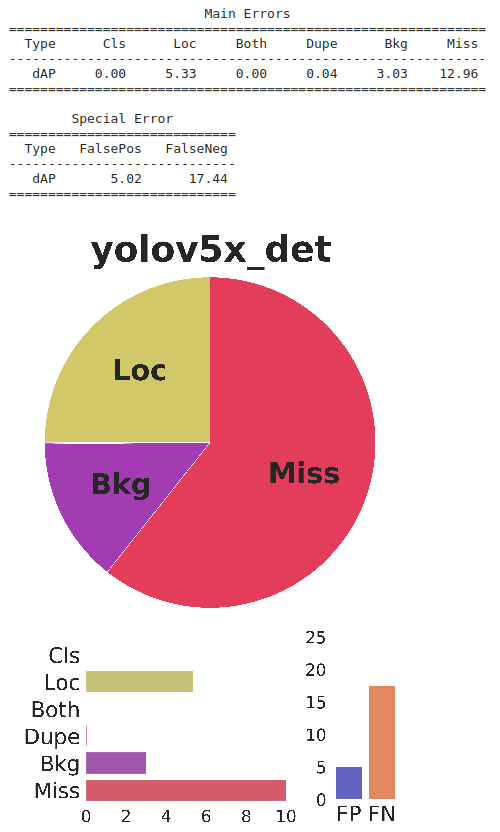
性能提高了近8%,該模型能夠預(yù)測(cè)大多數(shù)情況,并在攝像機(jī)視角下進(jìn)行了泛化。由于視頻序列中的背景雜波和遮擋,仍有一些誤報(bào)和漏報(bào)。
結(jié)論
我們?cè)噲D收集數(shù)據(jù)集并覆蓋任務(wù)中幾乎所有的挑戰(zhàn),但是仍然有一個(gè)問(wèn)題仍然存在,并阻礙了我們的模型性能,我們需要收集包含此類(lèi)場(chǎng)景下的數(shù)據(jù)。
創(chuàng)建自定義批注
通過(guò)數(shù)據(jù)增強(qiáng),我們創(chuàng)建了一些真實(shí)世界的樣本,但是我們的數(shù)據(jù)在圖像背景上仍然缺乏多樣性。對(duì)于零售商店來(lái)說(shuō),框架背景充滿了雜亂的東西,人體模型或衣服架子會(huì)導(dǎo)致假正例,而大面積的遮擋則會(huì)導(dǎo)致假反例。為了增加這種多樣性,我們?nèi)∠斯雀杷阉鳎瑥纳痰晔占]路電視視頻,并對(duì)圖片進(jìn)行了手工注釋。 首先,我們通過(guò)迭代4中的模型傳遞所有的圖像并創(chuàng)建自動(dòng)標(biāo)簽,然后使用開(kāi)源注釋工具CVAT(computervision and annotation tool)進(jìn)一步修正注釋。
最終人體檢測(cè)模型
我們將定制存儲(chǔ)圖像添加到之前的數(shù)據(jù)集中,并為最終迭代訓(xùn)練模型。我們的最終數(shù)據(jù)集分布如下所示。
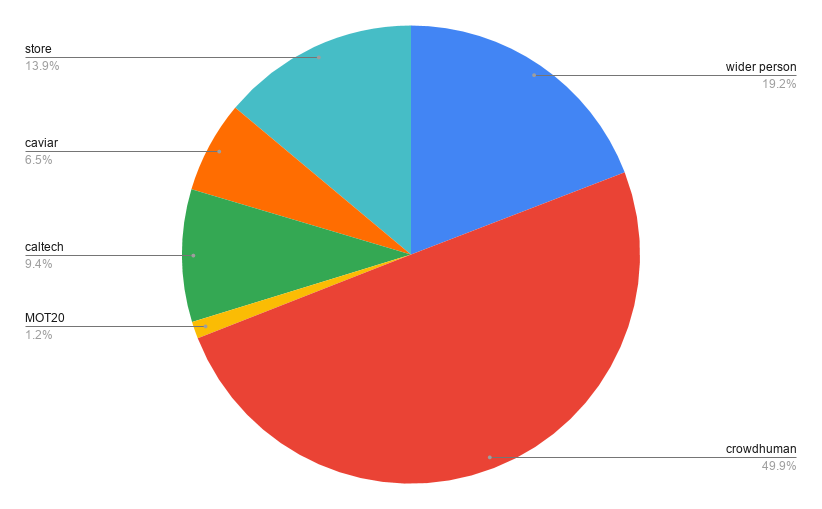
訓(xùn)練迭代5: 主干網(wǎng)絡(luò):YOLOv5x 模型初始化:迭代4中的模型 epoch:~100個(gè)epoch
性能
0.79 mAP @ 0.50 IOU
分析
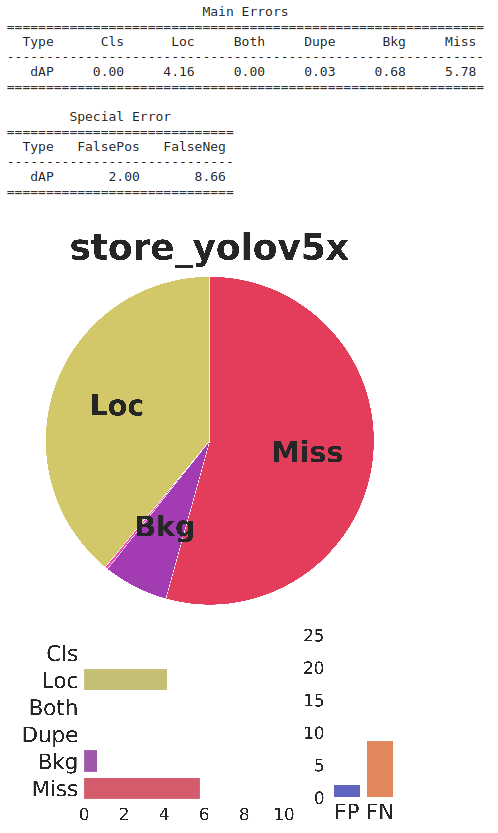
我們的模型的性能顯示了大約0.2%的正增長(zhǎng),同時(shí),從TIDE分析可以看出,假正例在誤差中的貢獻(xiàn)也有所降低。
結(jié)論
額外的數(shù)據(jù)有助于使模型對(duì)背景干擾更加穩(wěn)健,但是收集到的數(shù)據(jù)量與總體數(shù)據(jù)集大小相比仍然非常少,并且模型仍然存在一些誤報(bào)。當(dāng)在隨機(jī)圖像上進(jìn)行測(cè)試時(shí),該模型能夠很好地泛化。
總結(jié)
我們從模型選擇開(kāi)始,以COCO作為基準(zhǔn),我們實(shí)現(xiàn)一系列的模型。此外,我們考慮了推理時(shí)間和模型架構(gòu),并選擇了yolov5。我們收集并清理了各種公開(kāi)可用的數(shù)據(jù)集,并使用各種數(shù)據(jù)擴(kuò)充技術(shù)來(lái)轉(zhuǎn)換這些數(shù)據(jù)集,以適應(yīng)我們的用例。最后,我們收集存儲(chǔ)圖像,并在手工注釋后將其添加到數(shù)據(jù)集中。我們的最終模型是在這個(gè)精心設(shè)計(jì)的數(shù)據(jù)集上訓(xùn)練的,能夠從0.46map@IOU0.5提高到0.79map@IOU0.5。
結(jié)論
通過(guò)根據(jù)用例對(duì)數(shù)據(jù)集進(jìn)行處理,我們改進(jìn)了大約20%的對(duì)象檢測(cè)模型,該模型在映射和延遲方面仍有改進(jìn)的余地,所選的超參數(shù)是yolov5默認(rèn)給出的,我們可以使用optuna等超參數(shù)搜索庫(kù)對(duì)它們進(jìn)行優(yōu)化。當(dāng)訓(xùn)練分布和測(cè)試分布之間存在差異時(shí),域適應(yīng)是另一種可以使用的技術(shù),同樣,這種情況可能需要一個(gè)持續(xù)的訓(xùn)練循環(huán),其中包含額外的數(shù)據(jù)集,以確保模型的持續(xù)改進(jìn)。
原文標(biāo)題:使用Python+OpenCV+yolov5實(shí)現(xiàn)行人目標(biāo)檢測(cè)
文章出處:【微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
機(jī)器視覺(jué)
+關(guān)注
關(guān)注
161文章
4345瀏覽量
120111 -
OpenCV
+關(guān)注
關(guān)注
30文章
628瀏覽量
41264 -
python
+關(guān)注
關(guān)注
56文章
4782瀏覽量
84453
原文標(biāo)題:使用Python+OpenCV+yolov5實(shí)現(xiàn)行人目標(biāo)檢測(cè)
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
YOLOv10自定義目標(biāo)檢測(cè)之理論+實(shí)踐
如何用OpenCV的相機(jī)捕捉視頻進(jìn)行人臉檢測(cè)--基于米爾NXP i.MX93開(kāi)發(fā)板
在樹(shù)莓派上部署YOLOv5進(jìn)行動(dòng)物目標(biāo)檢測(cè)的完整流程
YOLOv6在LabVIEW中的推理部署(含源碼)

【飛凌嵌入式OK3576-C開(kāi)發(fā)板體驗(yàn)】rknn實(shí)現(xiàn)yolo5目標(biāo)檢測(cè)
RK3588 技術(shù)分享 | 在Android系統(tǒng)中使用NPU實(shí)現(xiàn)Yolov5分類(lèi)檢測(cè)-迅為電子

opencv-python和opencv一樣嗎
DongshanPI-AICT全志V853開(kāi)發(fā)板搭建YOLOV5-V6.0環(huán)境
YOLOv5的原理、結(jié)構(gòu)、特點(diǎn)和應(yīng)用
用yolov5的best.pt導(dǎo)出成onnx轉(zhuǎn)化成fp32 bmodel后在Airbox上跑,報(bào)維度不匹配怎么處理?
OpenVINO? C# API部署YOLOv9目標(biāo)檢測(cè)和實(shí)例分割模型
基于OpenCV DNN實(shí)現(xiàn)YOLOv8的模型部署與推理演示
OpenCV4.8 C++實(shí)現(xiàn)YOLOv8 OBB旋轉(zhuǎn)對(duì)象檢測(cè)
深入淺出Yolov3和Yolov4
在C++中使用OpenVINO工具包部署YOLOv5-Seg模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論