 深度學習:小樣本學習下的多標簽分類問題初探
深度學習:小樣本學習下的多標簽分類問題初探
摘要
小樣本學習(Few-shot Learning)近年來吸引了大量的關注,但是針對多標簽問題(Multi-label)的研究還相對較少。在本文中,我們以用戶意圖檢測任務為切入口,研究了的小樣本多標簽分類問題。對于多標簽分類的SOTA方法往往會先估計標簽-樣本相關性得分,然后使用閾值來選擇多個關聯的標簽。
為了在只有幾個樣本的Few-shot場景下確定合適的閾值,我們首先在數據豐富的多個領域上學習通用閾值設置經驗,然后采用一種基于非參數學習的校準(Calibration)將閾值適配到Few-shot的領域上。為了更好地計算標簽-樣本相關性得分,我們將標簽名稱嵌入作為表示(Embedding)空間中的錨點,以優化不同類別的表示,使它們在表示空間中更好的彼此分離。在兩個數據集上進行的實驗表明,所提出的模型在1-shot和5-shot實驗均明顯優于最強的基線模型(baseline)。
1.Introduction
1.1 背景一:用戶意圖識別
用戶意圖識別是任務型對話理解的關鍵組成部分,它的任務是識別用戶輸入的話語屬于哪一個領域的哪一種意圖 [1]。
當下的用戶意圖識別系統面臨著兩方面的關鍵挑戰:
頻繁變化的領域和任務需求經常導致數據不足
用戶在一輪對話中經常會同時包含多個意圖 [2,3]
圖1. 示例:意圖理解同時面領域繁多帶來數據不足和多標簽的挑戰
1.2 背景二:多標簽分類 & 小樣本學習
小樣本學習(Few-shot Learning)旨在像人一樣利用少量樣本完成學習,近年來吸引了大量的關注 [4,5]。
但是針對多標簽問題的小樣本學習研究還相對較少。
1.3 本文研究內容
本文以用戶意圖檢測任務為切入口,研究了的小樣本多標簽分類問題,并提出了Meta Calibrated Threshold (MCT) 和 Anchored Label Reps (ALR) 從兩個角度系統地為小樣本多標簽學習提供解決方案。
2. Problem Definition
2.1 多標簽意圖識別
如圖2所示,目前State-of-the-art多標簽意圖識別系統往往使用基于閾值(Threshold)的方法 [3,6,7],其工作流程可以大致分為兩步:
計算樣本-標簽類別相關性分數
然后用預設或從數據學習的閾值選擇標簽
2.2小樣本多標簽用戶意圖識別
觀察一個給定的有少量樣例的支持集(Support Set)
預測未見樣本(Query Instance)的意圖標簽
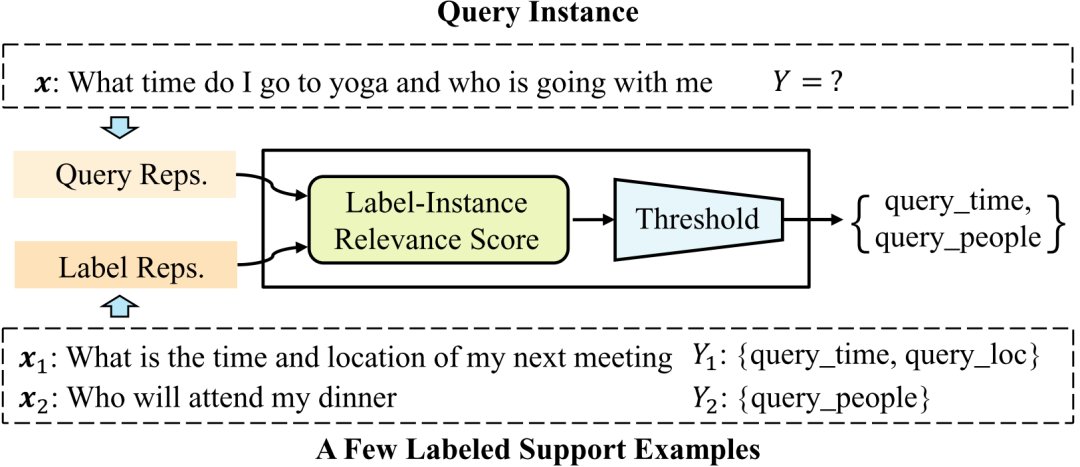
圖2. 小樣本多標簽意圖識別框架概覽
3. 方法
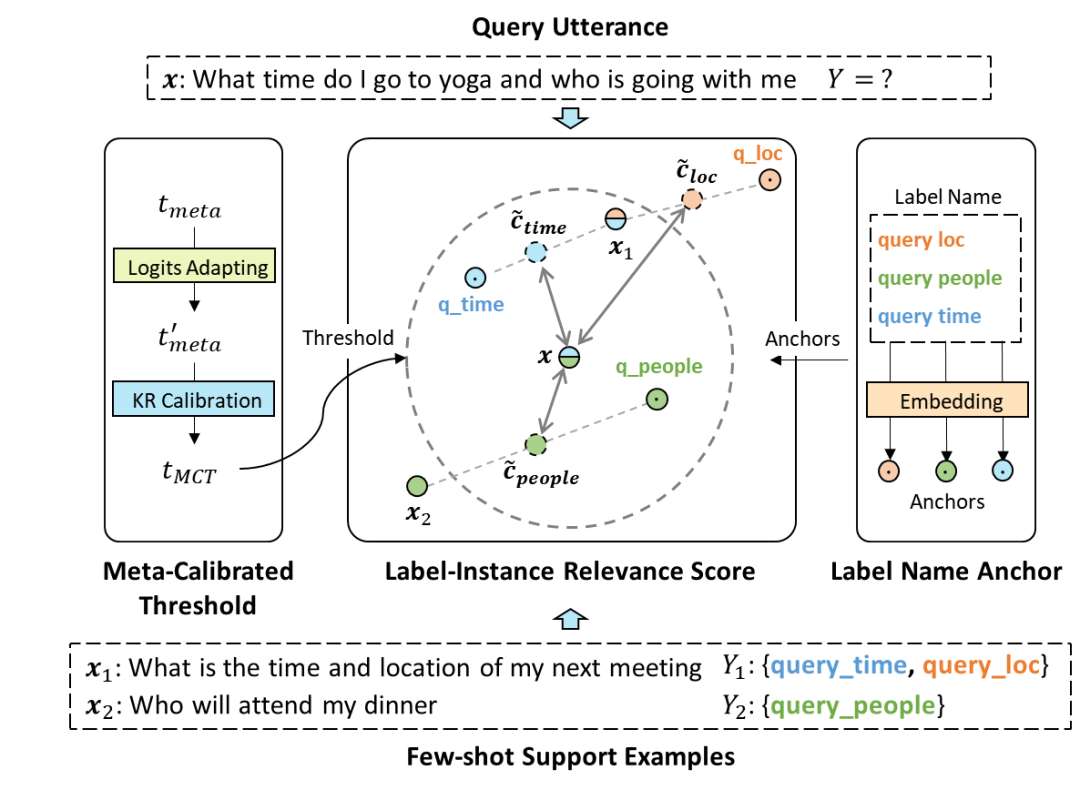
圖3. 我們提出的小樣本多標簽識別模型
3.1 閾值計算
(1)挑戰:
多標簽分類任務在小樣本情景下主要面臨如下挑戰:
a. 因為要從數據中學習閾值,現有方法只適用于數據充足情況。小樣本情景下,模型很難從幾個樣本中歸納出閾值;
b. 此外,不同領域間閾值無法直接遷移,難以利用先驗知識。
(2)解決方案:
為了解決上述挑戰,我們提出Meta Calibrated Threshold (MCT),具體可以分為兩步(如圖3左邊所示):
a. 首先在富數據領域,學習通用的thresholding經驗
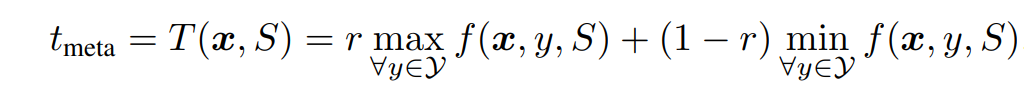
b. 然后在Few-shot領域上,用Kernel Regression 來用領域內的知識矯正閾值 (Calibration)
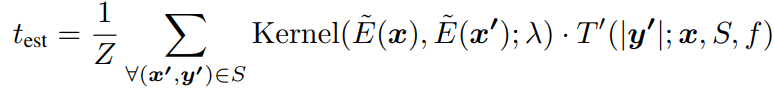
這樣,我們在估計閾值時,既能遷移先驗知識,又能利用領域特有的知識:
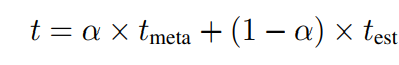
3.2 樣本-標簽類別相關度計算
(1)挑戰:
如圖4所示,經典的小樣本方法利用相似度計算樣本-標簽類別相關性,這在多標簽場景下會失效。
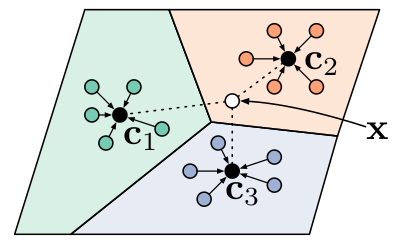
圖4. 經典的基于相似度的小樣本學習模型:原型網絡
如圖3所示,例子中,time和location兩個標簽因為support example相同,導致這兩個類別由樣本得到的表示相同不可分,進而無法進行基于相似度的樣本-類別標簽相關度計算。
(2)解決方案:
為了解決上述挑戰,我們提出了Anchored Label Reps (ALR)。具體的,如圖三右邊所示,我們
a. 利用標簽名作為錨點來優化Embedding空間學習
b. 利用標簽名語義來分開多標簽下的類別表示
4. 實驗
4.1 主實驗結果
實驗結果顯示,我們的方法在兩個數據集上顯著的優于最強baseline。同時可以看到,我們的方法很多時候只用小的預訓練模型就超過了所有使用大預訓練模型的baseline,這在計算資源受限的情景下格外有意義。
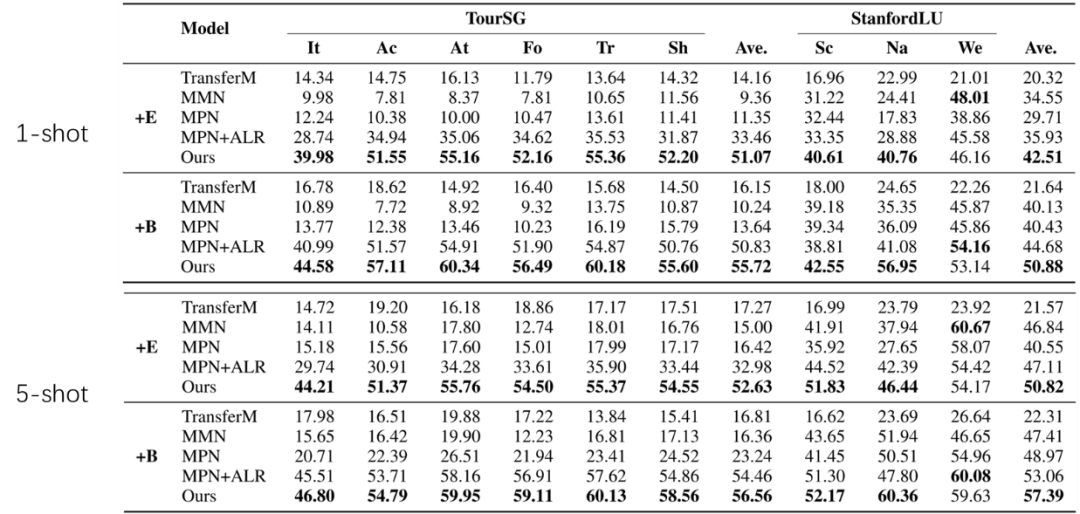
表1. 主實驗結果。+E 代表使用 Electra-small (14M);+B為 BERT-base (110M)
4.2 實驗分析
圖5的消融實驗顯示所提出的ALR和MCT都對最終的效果產生了較大的貢獻。

圖5. 消融實驗
在圖6中,我們對Meta Calibrated Threshold中各步驟對最終標簽個數準確率的影響進行了探索。結果顯示Meta學習和基于Kernel Regression的Calibration過程都會極大地提升最終模型的準確率。
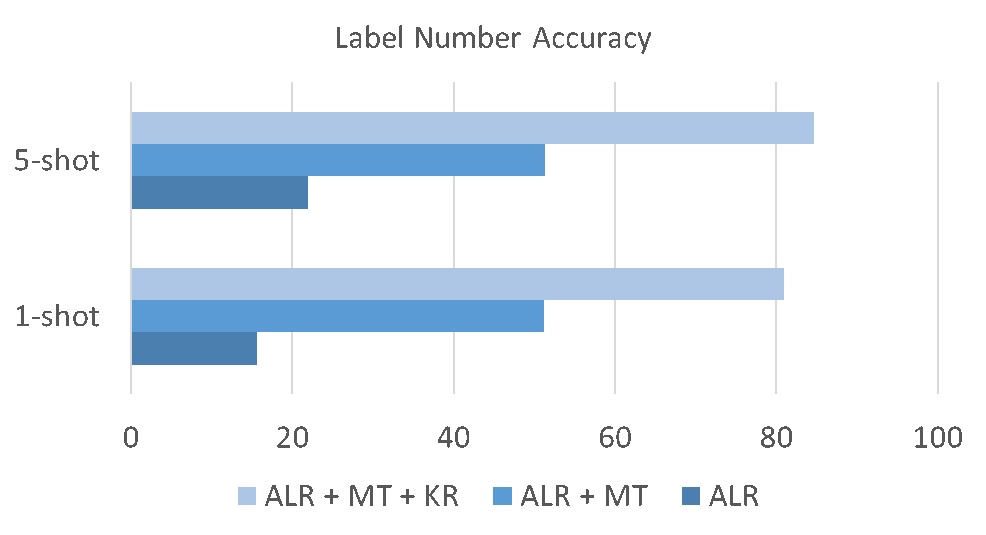
圖6. 標簽個數準確率結果
參考文獻
[1] Young, S.; Gasiˇ c, M.; Thomson, B.; and Williams, J. D. ′ 2013. Pomdp-based statistical spoken dialog systems: A review. In Proc. of the IEEE, volume 101, 1160–1179. IEEE.
[2] Xu, P.; and Sarikaya, R. 2013. Exploiting shared information for multi-intent natural language sentence classification. In Proc. of Interspeech, 3785–3789.
[3]Qin, L.; Xu, X.; Che, W.; and Liu, T. 2020. TD-GIN: Token-level Dynamic Graph-Interactive Network for Joint Multiple Intent Detection and Slot Filling. arXiv preprint arXiv:2004.10087 .
[4] Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; and Wierstra, D. 2016. Matching networks for one shot learning. In Proc. of NeurIPS, 3630–3638.
[5] Bao, Y.; Wu, M.; Chang, S.; and Barzilay, R. 2020. Few-shot Text Classification with Distributional Signatures. In Proc. of the ICLR.
[6] Xu, G.; Lee, H.; Koo, M.-W.; and Seo, J. 2017. Convolutional neural network using a threshold predictor for multilabel speech act classification. In IEEE international conference on big data and smart computing (BigComp), 126–130.
[7]Gangadharaiah, R.; and Narayanaswamy, B. 2019. Joint Multiple Intent Detection and Slot Labeling for GoalOriented Dialog. In Proc. of the ACL, 564–569.
責任編輯:xj
原文標題:【賽爾AAAI2021】小樣本學習下的多標簽分類問題初探
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
AI
+關注
關注
87文章
30239瀏覽量
268482 -
機器學習
+關注
關注
66文章
8382瀏覽量
132444 -
深度學習
+關注
關注
73文章
5493瀏覽量
121001
原文標題:【賽爾AAAI2021】小樣本學習下的多標簽分類問題初探
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用
AI大模型與深度學習的關系
利用Matlab函數實現深度學習算法
深度學習中的時間序列分類方法
深度學習中的無監督學習方法綜述
深度學習與nlp的區別在哪
深度學習模型訓練過程詳解
深度學習與傳統機器學習的對比
深度解析深度學習下的語義SLAM


為什么深度學習的效果更好?

【技術科普】主流的深度學習模型有哪些?AI開發工程師必備!


異構信號驅動下小樣本跨域軸承故障診斷的GMAML算法





 工商網監
工商網監
評論