") 通過(guò)引入實(shí)例 scale-uniform 采樣策略與 crop-aware 邊框回歸損失實(shí)現(xiàn) SOTA 性能
通過(guò)引入實(shí)例 scale-uniform 采樣策略與 crop-aware 邊框回歸損失實(shí)現(xiàn) SOTA 性能
高分辨率圖像上的全景分割面臨著大量的挑戰(zhàn),當(dāng)處理很大或者很小的物體時(shí)可能會(huì)遇到很多困難。來(lái)自 Facebook 的研究者通過(guò)引入實(shí)例 scale-uniform 采樣策略與 crop-aware 邊框回歸損失,能夠在所有尺度上改善全景分割效果,并在多個(gè)數(shù)據(jù)集上實(shí)現(xiàn) SOTA 性能。
全景分割網(wǎng)絡(luò)可以應(yīng)對(duì)很多任務(wù)(目標(biāo)檢測(cè)、實(shí)例分割和語(yǔ)義分割),利用多批全尺寸圖像進(jìn)行訓(xùn)練。然而,隨著任務(wù)的日益復(fù)雜和網(wǎng)絡(luò)主干容量的不斷增大,盡管在訓(xùn)練過(guò)程中采用了諸如 [25,20,11,14] 這樣的節(jié)約內(nèi)存的策略,全圖像訓(xùn)練還是會(huì)被可用的 GPU 內(nèi)存所抑制。明顯的緩解策略包括減少訓(xùn)練批次大小、縮小高分辨率訓(xùn)練圖像,或者使用低容量的主干。不幸的是,這些解決方法引入了其他問(wèn)題:1) 小批次大小可能導(dǎo)致梯度出現(xiàn)較大的方差,從而降低批歸一化的有效性 [13],降低模型的性能 ;2)圖像分辨率的降低會(huì)導(dǎo)致精細(xì)結(jié)構(gòu)的丟失,這些精細(xì)結(jié)構(gòu)與標(biāo)簽分布的長(zhǎng)尾目標(biāo)密切相關(guān);3)最近的一些工作[28,5,31] 表明,與容量較低的主干相比,具有復(fù)雜策略的更大的主干可以提高全景分割的結(jié)果。
克服上述問(wèn)題的一個(gè)可能策略是從基于全圖像的訓(xùn)練轉(zhuǎn)向基于 crop 的訓(xùn)練。這被成功地用于傳統(tǒng)的語(yǔ)義分割[25,3,2]。由于任務(wù)被限定在逐像素的分類(lèi)問(wèn)題,整個(gè)問(wèn)題變得更加簡(jiǎn)單。通過(guò)固定某個(gè) crop 的大小,精細(xì)結(jié)構(gòu)的細(xì)節(jié)得以保留。而且,在給定的內(nèi)存預(yù)算下,可以將多個(gè) crop 堆疊起來(lái),形成大小合理的訓(xùn)練批次。但對(duì)于更復(fù)雜的任務(wù),如全景分割,簡(jiǎn)單的 cropping 策略也會(huì)影響目標(biāo)檢測(cè)的性能,進(jìn)而影響實(shí)例分割的性能。具體來(lái)說(shuō),在訓(xùn)練過(guò)程中,從圖像中提取固定大小的 crop 會(huì)引入對(duì)大目標(biāo)進(jìn)行截取的偏置,在對(duì)完整圖像進(jìn)行推斷時(shí)低估這些目標(biāo)的實(shí)際邊界框大小(參見(jiàn)圖 1 左)。

為了解決這一問(wèn)題,F(xiàn)acebook 的研究者進(jìn)行了以下兩方面的改進(jìn)。首先,他們提出了一種基于 crop 的訓(xùn)練策略,該策略可以利用 crop-aware 損失函數(shù)(crop-aware bounding box, CABB)來(lái)解決裁剪大型目標(biāo)的問(wèn)題;其次,他們利用 instance scale-uniform sampling(ISUS)作為數(shù)據(jù)增強(qiáng)策略來(lái)解決訓(xùn)練數(shù)據(jù)中目標(biāo)尺度不平衡的問(wèn)題。
論文鏈接:https://arxiv.org/abs/2012.07717
研究者表示,他們的解決方案擁有上述從基于 crop 訓(xùn)練中得到的所有益處。此外,crop-aware 損失還會(huì)鼓勵(lì)模型預(yù)測(cè)出與被裁剪目標(biāo)可視部分一致的邊界框,同時(shí)又不過(guò)分懲罰超出 crop 區(qū)域的預(yù)測(cè)。
背后的原理非常簡(jiǎn)單:雖然一個(gè)目標(biāo)邊界框的大小在裁剪后發(fā)生了變化,但實(shí)際的目標(biāo)邊界框可能比模型在訓(xùn)練過(guò)程中看到的還要大。對(duì)于超出 crop 可視范圍但仍在實(shí)際大小范圍內(nèi)的預(yù)測(cè)采取不懲罰的做法,這有助于更好地對(duì)原始訓(xùn)練數(shù)據(jù)給出的邊界框大小分布進(jìn)行建模。通過(guò) ISUS,研究者引入了一種有效的數(shù)據(jù)增強(qiáng)策略,以改進(jìn)多個(gè)尺度上用于目標(biāo)檢測(cè)的特征金字塔狀表示。該策略的目的是在訓(xùn)練過(guò)程中更均勻地在金字塔尺度上分布目標(biāo)實(shí)例監(jiān)督,從而在推理過(guò)程中提高所有尺度實(shí)例的識(shí)別準(zhǔn)確率。
實(shí)驗(yàn)結(jié)果表明,研究者提出的 crop-aware 損失函數(shù)對(duì)具有挑戰(zhàn)性的 Mapillary Vistas、Indian Driving 或 Cityscapes 數(shù)據(jù)集中的高分辨率圖像特別有效。總體來(lái)說(shuō),研究者的解決方案在這些數(shù)據(jù)集上實(shí)現(xiàn)了 SOTA 性能。其中,在 MVD 數(shù)據(jù)集上,PQ 和 mAP 分別比之前的 SOTA 結(jié)果高出 4.5% 和 5.2%。
算法介紹
實(shí)例 Scale-Uniform 采樣 (ISUS)
研究者對(duì) Samuel Rota Bulo 等人提出的 Class-Uniform 采樣(CUS)方法進(jìn)行了擴(kuò)展,創(chuàng)建了全新的 Instance Scale-Uniform 采樣(ISUS)方法。標(biāo)準(zhǔn)的 CUS 數(shù)據(jù)準(zhǔn)備過(guò)程遵循四個(gè)步驟:1)以均勻的概率對(duì)語(yǔ)義類(lèi)進(jìn)行采樣;2)加載包含該類(lèi)的圖像并重新縮放,使其最短邊與預(yù)定義大小 s_0 匹配;3)數(shù)據(jù)增強(qiáng)(例如翻轉(zhuǎn)、隨機(jī)縮放);4)從所選類(lèi)可見(jiàn)的圖像區(qū)域中生成隨機(jī) crop。
在 ISUS 方法中,研究者遵循與 CUS 相同的步驟,只是尺度增強(qiáng)過(guò)程是 instance-aware 的。具體地,當(dāng)在步驟 1 中選擇「thing」類(lèi)( 可數(shù)的 objects,如 people, animals, tools 等),并在完成步驟 2 之后,研究者還從圖像和隨機(jī)特征金字塔層級(jí)中采樣該類(lèi)的隨機(jī)實(shí)例。然后在第 3 步中,他們計(jì)算了一個(gè)縮放因子σ,這樣所選實(shí)例將根據(jù)訓(xùn)練網(wǎng)絡(luò)采用的啟發(fā)式方法分配到所選層級(jí)。
為了避免出現(xiàn)過(guò)大或過(guò)小的縮放因子,研究者將σ限制在有限范圍 r_th 中。當(dāng)在步驟 1 中選擇「stuff」類(lèi)(相同或相似紋理或材料的不規(guī)則區(qū)域,如 grass、sky、road 等)時(shí),他們遵循標(biāo)準(zhǔn)的尺度增強(qiáng)過(guò)程,即從一個(gè)范圍 r_st 均勻采樣 σ。從長(zhǎng)遠(yuǎn)來(lái)看,ISUS 具有平滑目標(biāo)尺度分布的效果,在所有尺度上提供更統(tǒng)一的監(jiān)督。
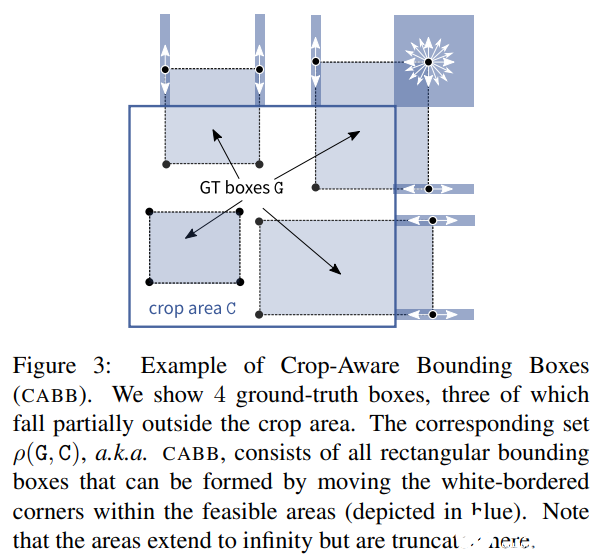
Crop-Aware 邊界框 (CABB)
在 crop 操作之后,研究者將真值邊界框 G 的概念放寬為一組與 G|_C 一致的真值框。用ρ(G,C)函數(shù)計(jì)算給定真值框 G 和 cropping 面積 C,公式如下
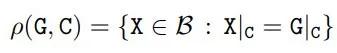
其中 X 覆蓋所有可能的邊界框Β。研究者將 ρ(G, C) 作為 Crop-Aware 邊框(CABB),它實(shí)際上是一組邊框(參見(jiàn)下圖 3)。如果真值邊框 G 嚴(yán)格地包含在 crop 區(qū)域中,那么 CABB 歸結(jié)為原始真值,在這種情況下 ρ(G, C) = {G}。
Crop-aware 邊框損失:該研究對(duì)給定的真值框 G、anchor 框 A 和 crop 區(qū)域 C 引入了以下新的損失函數(shù):
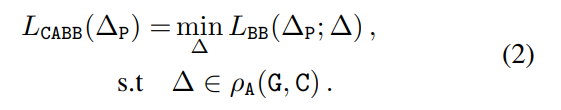
實(shí)驗(yàn)
研究者在以下三個(gè)公開(kāi)高分辨率全景分割數(shù)據(jù)集上評(píng)估了 CABB 損失:它們分別是 Mapillary Vistas(MVD)、Indian Driving Dataset(IDD)和 Cityscapes(CS)。
網(wǎng)絡(luò)與訓(xùn)練細(xì)節(jié)
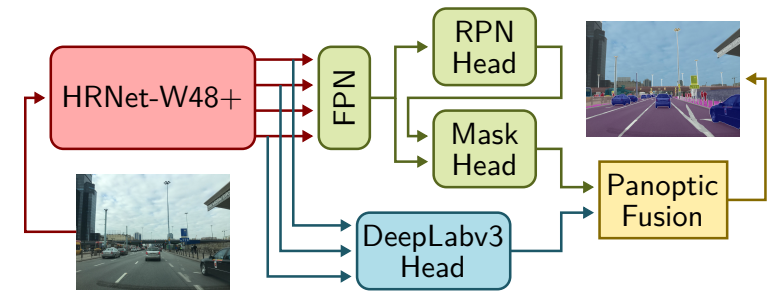
該研究遵循無(wú)縫場(chǎng)景分割(Seamless-Scene-Segmentation)[23]框架,并進(jìn)行了修改。首先,研究者用 HRNetV2-W48+[28,6]替換 ResNet-50 主體,前者是一種專(zhuān)門(mén)的骨干網(wǎng)絡(luò),它保存從圖像到網(wǎng)絡(luò)最后階段的高分辨率信息;其次,研究者將 [23] 中的 Mini-DL 分割頭替換為 DeepLabV3+[4]模塊,該模塊連接到 HRNetV2-W48 + 主干。最后將同步的 InPlace-ABN [25]應(yīng)用于整個(gè)網(wǎng)絡(luò),并在候選區(qū)域和目標(biāo)檢測(cè)模塊中使用 CABB 損失替換標(biāo)準(zhǔn)邊界框回歸損失。
具體流程如下圖所示:
與 SOTA 結(jié)果進(jìn)行比較
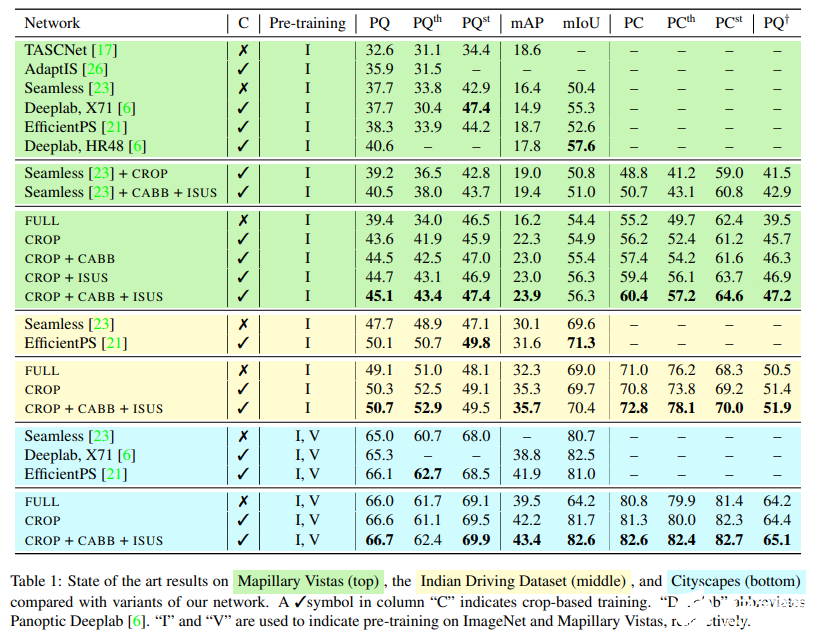
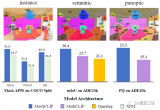
下表 1 頂部的 MVD 結(jié)果表明,CROP 在所有指標(biāo)上均優(yōu)于 FULL,這證明了基于 crop 訓(xùn)練的優(yōu)勢(shì)。除此以外,即使是該網(wǎng)絡(luò)變體中最弱的,也超過(guò)了所有的 PQ 基準(zhǔn),唯一的例外是基于 HRNet-W48 的 Panooptic Deeplab 版本。
表 1 中間的 IDD 實(shí)驗(yàn)得到了類(lèi)似的結(jié)果:CROP 在大多數(shù)指標(biāo)上優(yōu)于 FULL,而 CABB+ISUS 帶來(lái)了進(jìn)一步改進(jìn),在 PC 中最為顯著。與之前的工作相比,該研究觀察到 mAP 分?jǐn)?shù)和 SOTA PQ 都有了很大的提高,而分割指標(biāo)有點(diǎn)落后。
表 1 底部的 Cityscapes 結(jié)果呈現(xiàn)相同趨勢(shì),盡管邊際損失(margin)有所下降。需要注意,Cityscapes 是比 IDD 和 MVD 都小的數(shù)據(jù)集,在某些度量標(biāo)準(zhǔn)中,SOTA 結(jié)果接近 90%,因此預(yù)計(jì)會(huì)有較小的改進(jìn)。盡管如此,與以前最佳方法相比,CROP+CABB+ISUS 在 mAP 上實(shí)現(xiàn)了 1.5%以上的顯著提升。
實(shí)驗(yàn)細(xì)節(jié)
上表 1 為均在 1024×1024 crop 上訓(xùn)練的兩種設(shè)置的結(jié)果:從其原始代碼中復(fù)制(Seamless + CROP)的未修改網(wǎng)絡(luò) [23],以及結(jié)合 CABB 損失和 ISUS 網(wǎng)絡(luò)(Seamless+CABB+ISUS)的同一網(wǎng)絡(luò)。
與該研究的其他結(jié)果一致,基于 crop 訓(xùn)練的引入相較基準(zhǔn)實(shí)現(xiàn)了一致改進(jìn),特別是在檢測(cè)指標(biāo)方面,同時(shí) CABB 損失和 ISUS 進(jìn)一步提高了分?jǐn)?shù),在 PQ w.r.t.Seamelss 上提升了 2.8% 以上。
下圖 6 展示了在具有大型目標(biāo)的 12Mpixels Mapillary Vistas 驗(yàn)證圖像上,CROP 與 CROP+CABB+ISUS 的輸出之間的對(duì)比情況:

責(zé)任編輯:PSY
-
算法
+關(guān)注
關(guān)注
23文章
4601瀏覽量
92651 -
圖像分割
+關(guān)注
關(guān)注
4文章
182瀏覽量
17980 -
分割
+關(guān)注
關(guān)注
0文章
17瀏覽量
11892
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
使用PWM實(shí)現(xiàn)電源管理的策略
什么是回歸測(cè)試_回歸測(cè)試的測(cè)試策略
PCM1864采樣音頻數(shù)據(jù)的諧波及底噪可能會(huì)是由什么引入的呢?
基于ArkTS語(yǔ)言的OpenHarmony APP應(yīng)用開(kāi)發(fā):圖片處理

電流采樣電阻的采樣原理
性能高達(dá) 6 倍,F(xiàn)lexus X 實(shí)例用實(shí)力闡述什么是新一代柔性算力
請(qǐng)問(wèn)如何才能實(shí)現(xiàn)ESP32的2MSPS采樣?
NB81是否支持OneNet SOTA功能?應(yīng)該如何激活SOTA?
旋變位置不變的情況下,當(dāng)使能SOTA功能與關(guān)閉SOTA功能時(shí),APP中DSADC采樣得到的旋變sin和cos兩者值不一樣,為什么?
Scale out成高性能計(jì)算更優(yōu)解,通用互聯(lián)技術(shù)大有可為

如何通過(guò)GD32 MCU內(nèi)部ADC參考電壓通道提高采樣精度?
對(duì)象檢測(cè)邊界框損失函數(shù)–從IOU到ProbIOU介紹
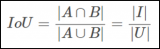
foc單電阻采樣時(shí)序的軟件實(shí)現(xiàn)
深入解讀OTA,了解兩大子系統(tǒng)FOTA與SOTA的升級(jí)優(yōu)勢(shì)

三項(xiàng)SOTA!MasQCLIP:開(kāi)放詞匯通用圖像分割新網(wǎng)絡(luò)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論