") 工業(yè)界AI項目研發(fā)中的各個環(huán)節(jié)的重要細節(jié)點
工業(yè)界AI項目研發(fā)中的各個環(huán)節(jié)的重要細節(jié)點
導(dǎo)讀
本文從作者的經(jīng)歷和經(jīng)驗教訓(xùn)展開,闡述了在AI項目研發(fā)中的各個環(huán)節(jié)的重要細節(jié)點,展現(xiàn)了一個AI項目到最終落地繁瑣的過程。
前言
AI虐我千百遍,我待AI如初戀。什么才是好的AI?答:能落地的AI才是好AI。AI項目從無到有,再到最終落地,無非不是挖坑、踩坑、填坑的過程。本文從筆者的一些經(jīng)歷、經(jīng)驗、血淚教訓(xùn)展開,說一下對AI項目研發(fā)過程中的感想。
被虐的案例
案例1:經(jīng)過N次版本修改與優(yōu)化,最終定稿。支持切換型號、云端訓(xùn)練、人工調(diào)參等。搞到最后,才發(fā)現(xiàn)別人要求準確率100%。
案例2:樣機各種燈光閃來閃去,各種運動機構(gòu)群魔亂舞。什么犄角旮旯都覆蓋到,什么劃痕、殘缺、臟污都面面俱到。但是,一個產(chǎn)品的檢測竟然要30s。到過一次現(xiàn)場才發(fā)現(xiàn),人工目檢只需要2s。
案例3:光學(xué)、算法、界面都ok了。在熱火朝天、干勁十足的準備推廣成千上百套變現(xiàn)的時候,客戶說只要一套。
案例4:同上,最終客戶說再考慮一下,當然是杳無音信。算是被耍呢?還是算是白嫖呢?
案例5:當我們正為識別準確率是99%的時候,客戶把一個識別成功的和一個識別失敗拿到一起,問:這兩個明明一模一樣,為啥這個失敗了,這個成功了?
案例6:我去生產(chǎn)現(xiàn)場培訓(xùn)客戶標注。他們非常配合,找來的也是目檢老手。我示范了幾個后,讓他試試。他就是不肯,搞到最后才知道:額,他不會用電腦!
案例7:我們的算法好牛掰,我們模型好先進。AI+傳統(tǒng)方法一起來搞,完美。不過你需要調(diào)整這20個超參數(shù)。人呢?別走啊!
案例8:已經(jīng)上線運行了,最后發(fā)現(xiàn)某一種型號的某一種缺陷打光不佳,圖像上很難判斷。最終只能推倒重來。
案例9:沒有意識到數(shù)據(jù)的重要性,每次都是幾張圖片在測試,結(jié)果是很完美,最匆匆拍板上線。最終大批量測試的時候,發(fā)現(xiàn)不work了。
為啥這么難?
工業(yè)AI,尤其是缺陷檢測這塊都是硬骨頭。雖然場景非常簡單,雖然數(shù)據(jù)都是源源不斷,雖然算法都是非常純粹。主要是其需求太分散了,不是不能做,而是值不值得去做。因為你要面臨以下問題:
說不清道不明、模棱兩可的需求標準,某些難以量化的標準。
頻繁的變更需求標準,難以做到只靠調(diào)后處理參數(shù)就快速響應(yīng)。
頻繁更換型號的場景,留給你訓(xùn)練的時間不多。甚至無法提供良好的訓(xùn)練環(huán)境。
立體的產(chǎn)品,各種吃光照,吃視角的缺陷,極其微弱的缺陷。
難以保證的樣本一致性問題。
準確率能不能到100%?
有沒有人工做的更快?
有沒有人工費用更便宜?
需要配合繁復(fù)的硬件設(shè)備,尤其是運動設(shè)備。如何才能保證整套設(shè)備的穩(wěn)定性?
后期維護成本問題?由于涉及的環(huán)節(jié)太多,需要“全才”才能搞定。
......
一般流程
AI要敏捷開發(fā),更要方法論,更更要穩(wěn)定成熟的流程。
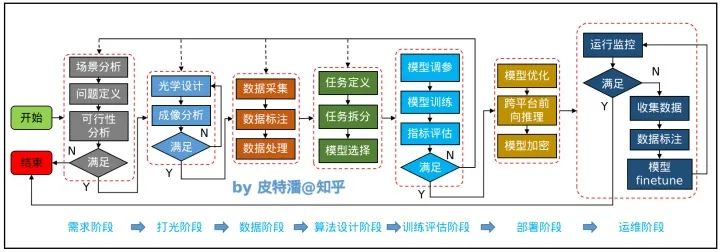
這里要提的是,工業(yè)場景的AI不過是整套系統(tǒng)中的一個小小組件,你一定不會靠單純的AI去make money。即便如此,AI從無到有,依然經(jīng)過以下幾個環(huán)節(jié):
需求階段
包括場景分析,問題定義,可行性分析。很多任務(wù)都是從該階段直接進入end。這個是好事,一定不要盲目自信和盲目樂觀。所謂一葉障目不見泰山,只看到算法容易實現(xiàn)就忽略以上的問題,最后只能慘淡收場。最怕投入太多沉沒成本之后,想收場卻不甘心。
什么是需求,什么是真正需求,什么是隱藏等待發(fā)掘的真正需求。很多時候,和客戶一起聊需求的時候,他們給不出明確的需求。最簡單直接的辦法就是,深入?yún)⒂^他們的生產(chǎn)現(xiàn)場。和工人融到一起,學(xué)會他們的判斷標準。為他們發(fā)掘需求,尤其是下面幾點必須提前明確清楚:
什么是絕對不能容忍的錯誤,一旦出現(xiàn)就是質(zhì)量事故。我們要知道算法的下限在哪里。
涉不涉及更換型號,能否提供符合模型訓(xùn)練的場景要求,比如至少得有GPU吧,或者可以上網(wǎng)進行云端訓(xùn)練。
對時間上的要求,很多替換人工工位都要要求比人更快。我們要知道系統(tǒng)的物理極限,例如運動設(shè)備。
對于算法難以界定的灰色地帶,接不接受人工二次復(fù)檢。對于不work的個例,我們要有backup。
其他都比較直白,對于第二點說明一下。大家想必都知道,我們做算法復(fù)現(xiàn)的時候,推理部分比訓(xùn)練部分要容易好幾個等級。同理,上線部署的時候,如果涉及用戶自己訓(xùn)練,那么難度就上來了。要把標注、數(shù)據(jù)處理、訓(xùn)練參數(shù)、測試評估等都打包在一起,還要實現(xiàn)全自動化。甚至?xí)龅街T如用戶電腦不能上網(wǎng)&沒有GPU,沒有錯,即便是你提訓(xùn)練必須條件,他也不一定會給你配到。
以上這幾點,一定要仔細論證,全局論證,反復(fù)論證。論證不是內(nèi)卷,不是效率不高,不是執(zhí)行力不高。沒有詳細論證而匆匆上馬的項目,一般后期有無數(shù)個坑在等著你。
打光階段
包括光學(xué)設(shè)計,成像分析,當然還包括不是那么AI的結(jié)構(gòu)設(shè)計等。俗話說:七分靠打光,三分靠調(diào)參。打光非常重要,因為后續(xù)算法只能為圖片負責(zé)。一般我會用“明顯”和“明確”來進行可行性分析,“明顯”就是來自光學(xué)。最直觀的判斷就是,人肉眼能否通過圖片進行精準判斷。如果存在模棱兩可的部分,那么它也將成為算法模棱兩可的地方。
數(shù)據(jù)階段
包括數(shù)據(jù)采集,數(shù)據(jù)標注,數(shù)據(jù)處理。數(shù)據(jù)的重要性不言而喻,正所謂:七分靠數(shù)據(jù),三分靠trick。數(shù)據(jù)到位了,一切都好說。數(shù)據(jù)的重要性,想必是任何一個從業(yè)人員都深有體會的。我們要數(shù)據(jù),要有效的數(shù)據(jù)。沒有數(shù)據(jù)的場景,抱歉請用傳統(tǒng)方法。要記住,模型泛化,沒那么重要,當然模型也沒有那么強的泛化能力。它之所以能夠識別,那是因為它見過。將模型理解成一個存儲器,而不是泛化器。之前的你,需要建立數(shù)據(jù)庫來存儲數(shù)據(jù)用以測試時的比對,現(xiàn)在的你,模型就是你的數(shù)據(jù)庫。
數(shù)據(jù)標注就會涉及標準的定義,很多時候很難拿到清晰的標準。或者說無法量化為清晰的標準。往往會存在灰色地帶,這就要提前有一個清晰的認識。對于灰色地帶的處理,或者說客戶的容忍,要提前想好策略。這里比較困難的是,灰色地帶可能很難量化出來,我們只是知道這個樣本是灰色地帶,到底有多灰,have no idea。
另外,比較重要的是盡快建立穩(wěn)定的、有代表性的數(shù)據(jù)集合,尤其是測試集,這點非常重要。可以幫助非常敏捷進行后續(xù)的benchmark實驗。如果你不知道你對什么樣的最終結(jié)果負責(zé),那么你將永無止境的做下去。
算法設(shè)計階段
包括任務(wù)定義,任務(wù)拆分,模型選擇。尤其是任務(wù)拆分,你不肯定把所有的大象都裝到一個冰箱里面,你也不可能把所有的雞蛋放到一個籃子里面。
杜絕唯模型論 & SOTA 論。我們需要的是在特定場景下解決特定的問題。這里涉及學(xué)院派思維轉(zhuǎn)變,學(xué)院派的高手為imageNet和COCO等數(shù)據(jù)集負責(zé),而我為我自己的場景和自己數(shù)據(jù)集負責(zé)。SOTA看中的是模型的上限,而實際的場景,看中的是模型的下限。
杜絕唯AI論。不管傳統(tǒng)方法還是AI方法,能work的就是好算法。如果傳統(tǒng)方法沒有明顯的缺陷,那么請選擇傳統(tǒng)方案。或者你可以這么認為,當前看似高大上的AI并不是真正的AI,或許30年后一天,你會說:先用傳統(tǒng)方法YOLO V28 來試一下吧!
訓(xùn)練評估階段
包括模型調(diào)參,模型訓(xùn)練,指標評估。所謂的“煉丹”。前幾步做好了,一般不會有太大問題,如果有,請向前追溯。這里要說一句,“提前優(yōu)化是萬惡之源“。在保證精度的時候,再去考慮速度,再去做優(yōu)化。當然你靠58個模型聯(lián)合起來獲取的精度不在該討論范圍。
部署階段
這個階段坑比較多,基本上都是技術(shù)方面。也是所謂的“臟活”。包括模型優(yōu)化,跨平臺前向推理,模型加密。終于到部署階段了,也看到了落地的曙光。關(guān)于深度學(xué)習(xí)人工智能落地,已經(jīng)有有很多的解決方案,不論是電腦端、手機端還是嵌入式端,將已經(jīng)訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)權(quán)重在各個平臺跑起來,應(yīng)用起來才是最實在的。不過依然存在這么多工作需要做:
跨平臺:可跑目標硬件上,包括各類cpu/gpu/npu/fpga等等。
高效能:速度快、占用內(nèi)存少等。
精度沒有丟失:經(jīng)過一通量化、剪枝、蒸餾、圖優(yōu)化等操作后,終于滿足時間要求了,卻突然發(fā)現(xiàn)部署測試精度掉了一半,WTF。
加密需求:你一定不希望自己辛辛苦苦搞出來的成果被別人白嫖吧!
閉環(huán)生態(tài):當然你不能一勞永逸,怎么在應(yīng)用中收集樣本,更新系統(tǒng)。你需要作成實用、好用的閉環(huán)工具鏈。
運維階段
包括運行監(jiān)控,模型更新等。你以為可以所以口氣了,并沒有。能不能經(jīng)受海量產(chǎn)能和時間的考驗,請瑟瑟發(fā)抖地注視著吧!運維的核心就是保證業(yè)務(wù)安全穩(wěn)定運行。上面提到,AI泛化能力還是比較欠缺的,所以很可能會在實際運行的過程中遇到不work的情況。當然最最直接的辦法就是持續(xù)不斷擴充數(shù)據(jù)。當然要保證你的模型有足夠的capacity,如果沒有,那么就是算法設(shè)計環(huán)節(jié)沒有做好。收集數(shù)據(jù)利用上面部署階段所說的閉環(huán)生態(tài)工具鏈來持續(xù)完成這個事情。至此,你的AI項目已經(jīng)落地。
結(jié)語:多謝各位。
責(zé)任編輯:xj
原文標題:工業(yè)界AI項目落地的繁瑣過程
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
工業(yè)
+關(guān)注
關(guān)注
3文章
1783瀏覽量
46411 -
AI
+關(guān)注
關(guān)注
87文章
30155瀏覽量
268426 -
人工智能
+關(guān)注
關(guān)注
1791文章
46863瀏覽量
237587
原文標題:工業(yè)界AI項目落地的繁瑣過程
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
AI干貨補給站03 | 工業(yè)AI視覺檢測項目實施第二步:數(shù)據(jù)收集

人工智能工業(yè)領(lǐng)域應(yīng)用有哪些
邏輯組件中的流程塊節(jié)點通常出于什么用途
固定式工業(yè)條碼掃描器在mes系統(tǒng)中的各個環(huán)節(jié)應(yīng)用

基于AI深度學(xué)習(xí)的缺陷檢測系統(tǒng)
Pegatron通過AI賦能的數(shù)字孿生來模擬并優(yōu)化工廠運營
字節(jié)跳動否認AI手機研發(fā)項目
什么是工業(yè)控制網(wǎng)絡(luò)節(jié)點?常用的節(jié)點有哪些
Arm預(yù)計未來五年將有1000億臺設(shè)備用于AI
信號的預(yù)處理包括哪些環(huán)節(jié)
IMEC推出針對N2節(jié)點的設(shè)計探路PDK

未來已來:AI 助力智能制造
Imec推出首款針對N2節(jié)點的設(shè)計探路工藝設(shè)計套件
場內(nèi)物流智慧調(diào)度系統(tǒng)在工業(yè)園區(qū)中的作用、應(yīng)用與發(fā)展趨勢






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論