 激光雷達的競爭者來了,分辨率提升15倍
激光雷達的競爭者來了,分辨率提升15倍
立體視覺處理是將世界從2D平面轉換為全3D環境,不僅提供了更豐富、更密集的目標場景表示,還允許感測系統在未經訓練的情況下識別一般障礙物,使倉庫機器人、自動駕駛車輛等的導航更安全、更有效。
激光雷達(LiDAR)的競爭者來了,本不是什么顛覆性技術,但分辨率提升15倍,成本卻與便宜的固態LiDAR相仿;埃隆·馬斯克為其點贊,特斯拉也開始搭載,不過好像還沒有玩轉。要說真正量產搭載的還是傳統意義上的豪車:奔馳S級和E級、寶馬7系和5系、雷克薩斯LS、路虎Discovery Sport SUV、捷豹XFL、XE等。
從特斯拉的攝像頭說起
特斯拉的全電動汽車以攝像頭數量多而聞名,其8個攝像頭主要用于崗哨模式(Sentry Mode),還有一個TeslaCam用作行車記錄儀。通常人們沒有注意的是,特斯拉在Model 3和Model Y中配備了第九個攝像頭,就在后視鏡上方,用來監測車內情況。
前不久,美國的Model 3車主Erik Martin曾見過一輛路測的Semi原型卡車,說它配備了26個攝像頭。事實上,量產版Semi車型最多也就配備10個攝像頭。
早在2016年,在Model S上測試的特斯拉Autopilot 2.0(AP)硬件就“在駕駛員側安裝了某種雙目攝像頭,看起來像一副小望遠鏡。”
值得注意的是,特斯拉Model 3前視已搭載三個基于安森美半導體CMOS圖像傳感器的三目攝像頭(魚眼、中焦和長焦)模塊,用三個不同焦距攝像頭覆蓋不同范圍場景,以解決攝像頭無法來回切換焦距的問題,通過立體視覺技術實現3D成像。
提供各類立體視覺解決方案的北京中科慧眼銷售總監崔凱表示:“對于高級輔助駕駛系統(ADAS)單目就夠用,還便宜,而自動駕駛更需要多傳感器融合。單目有一種配置叫三目,即單種焦距的單目,可以實現近距離寬視角和遠距離的全覆蓋。但如果是三焦雙目就有很高的算力要求,開發難度很大。”
這話在特斯拉身上得到了應驗,根據國外車友測試,發現搭載Autopilot 2.5硬件的Model 3,在開啟AP后,前置三目攝像頭中只有一個主攝像頭在工作,而長焦和魚眼攝像頭都處于關閉狀態。
另外,去年年初國產特斯拉被暗中減配,混裝了HW2.5和HW3.0,后者是特斯拉自己專門為FSD打造的新計算平臺,據稱其圖像處理能力是HW2.5的21倍,計算能力提升了大約7倍。但特斯拉中國卻表示:現階段如果沒有選裝FSD功能,使用HW2.5的Model 3車型與HW3.0的Model 3車型在駕乘體驗和使用安全上“基本不存在區別”。由此可見,現在的三目攝像頭還是受制于算力。
的確有車主發現,行車記錄儀拍下來的視頻中,除了正前方的視頻較為清晰外,其他角度的視頻都比較模糊。原因就在于HW2.5(自動駕駛芯片)硬件算力不足,只有前置主攝像頭支持全分辨率輸出,剩下的5個攝像頭全部降低了分辨率輸出。這樣,想要實現對側前方、后方大量車輛的識別非常難。這也AP在面對側前方車輛加塞并線時反應沒有那么靈敏的一個原因。
如果真是那樣,特斯拉的視覺還是2D的,想象一下八個攝像頭同時處理要消耗多少GPU資源。結果可想而知,還而知了不少。
有專業人士分析說,特斯拉方案的問題在于,其方案主要依靠視覺,所以環境感知3D重建是基于2D的。2D轉換為3D,必然要丟失信息。通過看實際視頻,發現特斯拉對遠處物體有誤識別的情況,特別是有穿著黑衣服的行人在晚上突然過馬路時。毫米波雷達不是看人的,超聲波距離不夠,視覺兩眼一抹黑,這不就是視覺欺騙嗎?
剛剛的國產Model Y試駕所見,其內后視鏡背面空空如也,并沒有搭載之前Model 3曾有的三目攝像頭。
我們還是先看看什么是立體視覺(StereoVision)技術吧。
原理并不復雜
早在1838年,物理學家惠斯登(Wheaston)發明了實體鏡,讓人們第一次知曉了立體視覺這一全新的深度知覺現象。1861年,美國人史高維(Scoville)利用兩個鏡頭仿照人體兩眼前的距離同時拍攝,發明了早期的立體攝影。其仿生的就是人眼三角測距。
立體視覺是計算機視覺的一個重要模塊。人類之所以能看到各種物體,得益于我們的視覺系統。在發現了單目系統的缺陷之后,從一個攝像頭增加到兩個攝像頭,就構成了一個立體系統。如果可以在兩幅圖像中找到對應點,就可以通過三角測量的方法來求得深度。
基于此,人們發明了用來測量距離的雙目攝像頭。近年來,伴隨計算機和自動駕駛(AD)技術的發展,立體視覺已用于車輛的目標感測和識別應用。
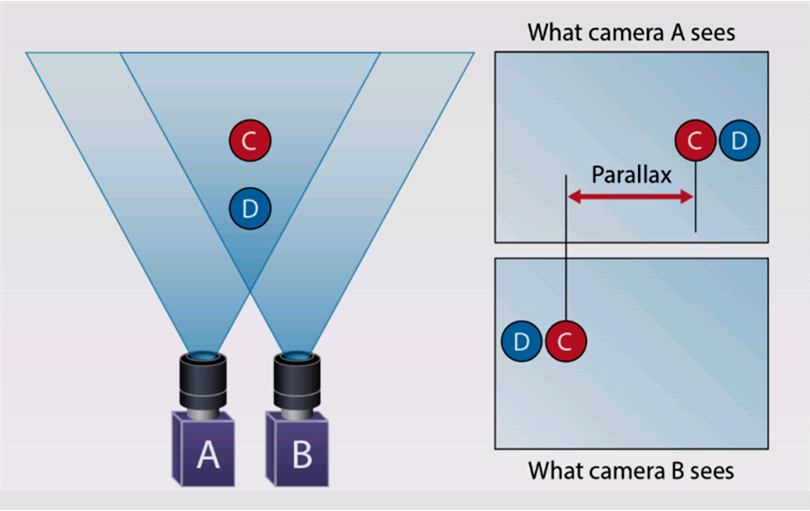
立體視覺原理
立體視覺處理是將世界從2D平面轉換為全3D環境,不僅提供了更豐富、更密集的目標場景表示,還允許感測系統在未經訓練的情況下識別一般障礙物,使倉庫機器人、自動駕駛車輛等的導航更安全、更有效。
早在1996年,德州儀器(TI)就在《用多個DSP實現快速3D視覺》的應用報告中描述了一個具有移動機器人引導和自動車輛導航的立體視覺過程。
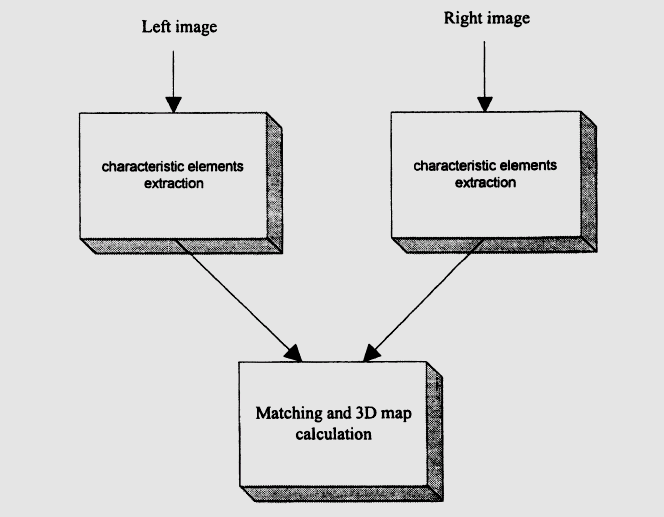
3D信息任務分配和數據傳輸
報告指出:“立體視覺過程通過在不同位置獲取兩幅圖像,并研究相應立體點位置的差異來確定物體的距離。各種技術已經發展到從一組亮度圖像推斷3D信息的階段。立體視覺的技術,特別是它能夠在各種照明條件下和大深度范圍內工作更適合測距應用。”
自動駕駛應該百密而無一疏
自動駕駛的一項基本任務是環境感知,即在行進中解釋不斷變化的3D世界。車輛要使用一些方法來了解和響應周圍環境,尤其是在運動中實現深度感知。如果路上的物體是陌生的怎么辦?也就是說,如果系統沒有被訓練就去識別路上的特定障礙物就會出現偏差。
實現自動駕駛的傳統方法是結合使用深度傳感技術:LiDAR和雷達是最常見的(與全球定位系統(GPS)配合使用,再加上極其精確的地形圖)方法。對攝像頭數據進行深度估計在業界也很流行,但是,顧名思義,這種技術提供的是距離估計,而不是精確的測量。而立體攝像頭能夠精確地測量距離,為自動駕駛應用提供顯著的優勢。
再看看特斯拉是怎么做的?去年,特斯拉收購了研究高效DNN(深層神經網絡)的計算機視覺初創公司DeepScale,希望能夠沿著視覺算法這一技術路線圖,繼續推進自動駕駛技術的落地。之后,特斯拉Autopilot 2.0實現了利用攝像頭訓練數據改進的限速識別算法,以提高高速公路限速數據的準確性。特斯拉一直在用神經網絡計算機來加強算力,也一直在用幾個攝像頭觀測場景的數據來訓練神經網絡。訓練者,難免百密而無一疏。
護欄屬于“未知物體”,失誤在所難免
致力于汽車智能化和輕量化產品的研發和制造保隆科技視覺產品總監孫路認為,特斯拉將增強型自動駕駛輔助系統提供給用戶后,本地用戶便“心甘情愿”地通過眾包形式無限訓練車輛,通過采集大量數據進行大量訓練,其方案結合幾何與網絡測距方法,適用于網絡調參,來增強模型的擬合能力,方案價格略高一些。
他指出:“但單目自身存在的問題不能完全杜絕,窮舉法不可能完全覆蓋,特斯拉仍然會出現一些場景的操控失誤風險;而雙目具有一定技術門檻,不易實現高性能指標,行業還沒有專用芯片,目前普遍采用FPGA,工藝難度高。此外,結構精度要求高,耐久性、一致性、溫度適應性要求也高。需要自動校準(AA)算法、靜態標定算法保存內參等,投入很大。”
車用傳感器孰優孰劣?
目前汽車中使用的傳感器主要是雷達、LiDAR和攝像頭,各有長短,用處不同。這些傳感器協同工作,提供外部世界車輛、行人、騎自行車的人、標志等原始數據,其重疊功能會產生冗余(圖中顏色重疊部分),確保一個系統出現故障時,另一個系統繼續運行。
ADAS完整愿景將融合多種RF技術和立體視覺等傳感器,形成一個完整的360°數字處理環境
比較一下特斯拉的車載傳感器配置,距未來愿景主要是少了LiDAR,冗余也不夠,當然未來數量還會不斷增加。
雷達:只是一種成本較低而可靠的技術,能夠在一定距離內探測較大的物體,在弱光和惡劣天氣下表現良好,但它只適用于倒車或泊車時的安全輔助裝置,是主要感測方式的重要補充。由于使用無線電波而不是光來探測物體,所以雷達在雨、霧、雪和煙中都能“看”得很清楚。
LiDAR:通過測量激光信號從物體上返回到本地傳感器所需的時間來確定車輛與環境或物體之間的距離
立體視覺:它基于從相鄰的兩個視角(雙目或多目攝像頭)獲取同一環境的兩幅獨立圖像來估計距離,即視覺信息的三角測量。它是使用算法處理器對現實環境進行密集的3D數字表示。
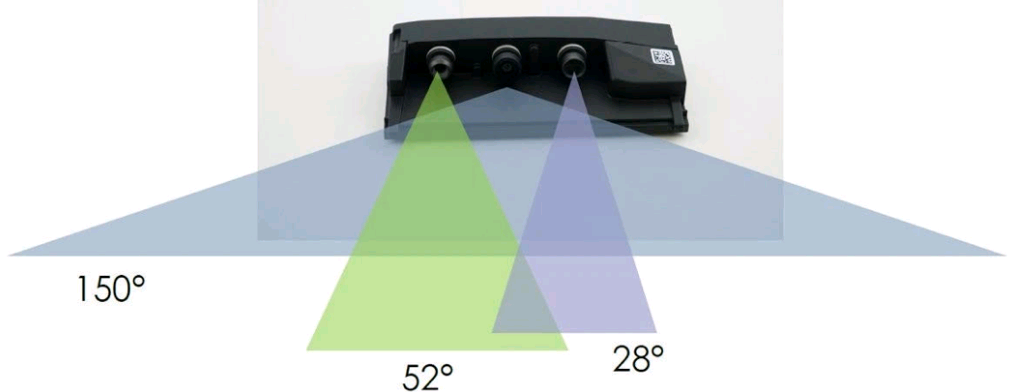
三目攝像頭示意圖
立體視覺和LiDAR都能進行距離測量、深度估計和密集點云生成(即3D環境地圖)。兩者都可產生豐富的數據集,不僅可以用來感測物體,而且可以在高速、各種環境、長距離和短距離下識別物體。作為車輛自動駕駛的主要傳感器系統,兩者也都可以同時部署以產生冗余。
因為這兩種感知方式都是光學技術,所以與人眼一樣容易受到同樣的挑戰:要“看到”道路,就要求有良好的視線,并且遠離污垢和其他污染物。那么,兩者的利弊如何呢?
早期LiDAR優勢明顯
不可否認,信號的數量越多,可能實現的距離測量數量就越多。LiDAR是通過多個旋轉(物理或通過邏輯)的激光器來實現的,以360度視野掃描車輛周圍環境。在自動駕駛發展史上,LiDAR一直是一項重要的傳感技術。開創性的自動駕駛原型依靠LiDAR實現了精確的距離測量、可靠性和易用性。例如,2004年開始的由美國國防部高級研究計劃局(DARPA)贊助的自動駕駛挑戰賽中,大多數參賽者都依賴LiDAR技術。
LiDAR沒有辜負人們的期望,優勢顯而易見,包括:
高精度(測量精度達到厘米級)
高數據速率(機械式旋轉LiDAR每秒旋轉20轉以上)
經驗證穩定可靠
感測效果不受溫度和光照的影響
盡管LiDAR有諸多優點,但也確實有一定的技術局限性:
在雨、霧和灰塵等惡劣天氣條件下會因反射造成誤報。專用算法處理可能解決這些問題,但比較復雜
眼睛安全條例對LiDAR的信號強度有所限制,使分辨率限制了視場和視場之間的距離
LiDAR測量的有效性與物體的反射率有關。如果信號遇到反射性差的障礙物,如黑色車輛,信號的能量只返回很小一部分,因此感測的可靠性會降低。幸運的是,大多數交通參與者都有足夠的反射能力,所以LiDAR在的應用相當廣泛
立體視覺后來居上
在車輛自動駕駛的早期(90年代末到21世紀初),計算機視覺科學還處于起步階段,加上半導體技術等因素造成的許多問題,阻礙了立體視覺作為自動駕駛主要感測模式的采用。
這段時間,立體視覺最受詬病的問題是:
攝像頭分辨率低,遠距離圖像質量差
弱光環境下性能差
計算資源要求高(計算機視覺處理需要多臺PC機)
駕駛過程中未經校準的攝像頭需要手動調整
當時,這些問題的嚴重性足以阻礙立體視覺作為一種可行的自動駕駛感知替代品的部署。在沒有競爭者的情況下,LiDAR得以蓬勃發展。
不過,從那時起,立體視覺慢慢走上了更具吸引力的發展之路,出現了大逆轉,目前已具備了和LiDAR競爭的能力:
低成本、高分辨率攝像頭(目前為800萬像素攝像頭)
適用于夜間駕駛的具有HDR(高動態范圍圖像)和微光圖像處理功能的高級ISP(圖像信號處理
專門為實時計算機視覺處理而設計的嵌入式SoC(系統級芯片
自動動態攝像頭校準
正是這些發展將立體視覺從一種小眾自動駕駛技術變成了一種強有力的競爭者,成為車輛自動駕駛的主要感測方式。
為什么自動駕駛更需要對象類型?
克魯日(Cluj-Napoca)技術大學的研究人員稱,密集立體視覺系統的一般處理流程是圖像采集、立體處理、視差到3D映射,最后是感測算法的應用。
立體視覺硬件使用兩個攝像頭,以24fps的最大幀速率獲取一系列優化的圖像。通過產生輸出函數的專用硬件板對被跟蹤圖像的進行3D重建——可以是兩個處理后的圖像之間的視差圖或用于生成基于左攝像頭的X-Y坐標系的Z-map。
立體視覺系統能夠生成兩種類型的環境數據:一是基于高程(elevation)測量的復雜駕駛環境密度圖,二是由參數化車道、跟蹤長方體和行人組成的一系列幾何元素。過去,傳統雙目攝像頭不區分對象類型,僅僅是將前方障礙物檢測或測量出來。這使其在實際應用中存在一些問題。因為計算元素既耗時又密集,為了根據接收到的環境數據進行實時決策,系統需要大量的數據帶寬和處理能力,因此必須使用并行計算。
雖然LiDAR也是一種常用的測距技術,也能夠精確地進行3D物體感測,而單目攝像頭也可以用來推斷或預測與深度相關的信息,但立體視覺在提供對3D環境的高度詳細和準確的360度理解方面具有獨特優勢。立體視覺利用兩個同步自動校準的攝像頭信息生成3D深度圖,是自動駕駛系統中視覺感知、運動預測和路徑規劃的重要組成部分。
在一個城市交叉口的圖像中可以看到,包括車輛、行人、自行車和路標、護欄等障礙物。
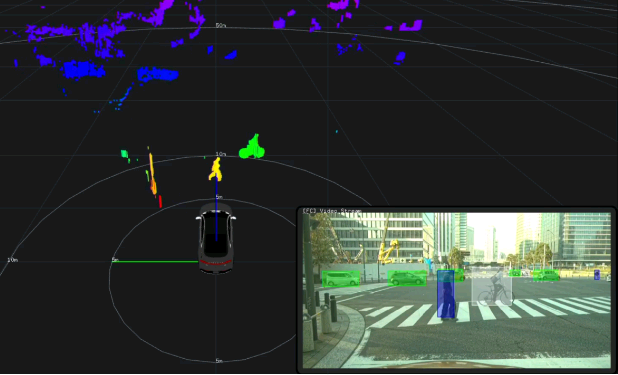
立體視覺視圖和嵌入圖像
將上圖中較大的立體視覺視圖與右下角的嵌入圖像進行比較,可以清楚地區分左側的路標、人行橫道上的行人、附近的騎車人、從左側進入交叉口的最近的兩輛車,以及道路兩側的背景元素。立體視覺視圖中的顏色表示距離,較暖的顏色(如橙色)表示距離車輛較近,較冷的顏色(如紫色)表示距離較遠。另外,小圖中3D邊界框顏色表示對象類型:車輛輪廓為綠色,行人輪廓為藍色,自行車輪廓為白色。
雖然道路場景很具有挑戰性,照明條件可能會發生很大變化,車輛、行人、自行車、碎片和其他障礙物是常態,但立體視覺解決方案也能有效地在復雜環境中實現。以夜間駕駛為例,在黑暗中基于立體的障礙物感測(同時感測正面和負面障礙物,如坑洞)需要魯棒的深度估計,包括視差有效性度量才能成功。
比如,計算機視覺芯片開發商Ambarella將短距離和長距離立體攝像頭模塊的多個輸出組合在一起,通過生成密集點云以驚人的細節對環境可視化。其立體攝像頭生成的數據進行了以下一些處理:
深度映射:創建深度映射可以感測場景中的一般對象(從車輛和行人到電線桿、垃圾箱、坑洞和碎片,包括其準確大小、位置和距離,而無需對系統進行明確訓練
道路建模:對不同道路形狀精確建模,有助于下坡和上坡運動
數據融合:由于顏色相關信息與深度數據一起由同一傳感器提供,因此可以同時運行單目算法(例如,通過卷積神經網絡(CNN)進行車道標記或交通標志感測),然后將此數據與深度圖融合
360度可視化:立體攝像頭可用于魚眼鏡頭的短程感知,在低速移動時可360度查看場景
自動駕駛,分辨率定輸贏
Ambarella總經理、帕爾馬大學計算機工程教授Alberto Broggi認為:“在當今的自動駕駛障礙物識別技術中,最重要的性能指標就是分辨率,也就是圖像密度,即每秒可以提供距離測量數的多少。數值越高,汽車周圍的3D表現就越精確。”
一般來說,使用當今攝像頭的立體視覺可以提供大約2000個垂直樣本/秒。LiDAR呢?才128個垂直樣本/秒,分辨率低了15倍以上。

立體(上)和LiDAR(下)圖像密度比較
Broggi解釋道:“在兩幅圖像中,彩色像素表示傳感器的測量值,顏色表示每個傳感器標度上的測量距離。我們可以看到,左側的立體解決方案提供了更大的環境覆蓋范圍,而右側的LiDAR輸出的區域覆蓋非常稀疏。”
由此可見兩者的明顯差異:立體視覺生成的數據更為豐富,從而使障礙物感測更容易。通過對上面兩張圖像的特寫對比,可以看到立體密度(左)和LiDAR密度(右)的區別。

立體和LiDAR的密度天壤之別
他指出,雖然這兩種技術都可用于自動駕駛車輛的目標感測,但效果差異很大。上述演示發生在白天,而在弱光情況下,立體的分辨率也很高。下圖顯示了夜間駕駛時的密度對比。
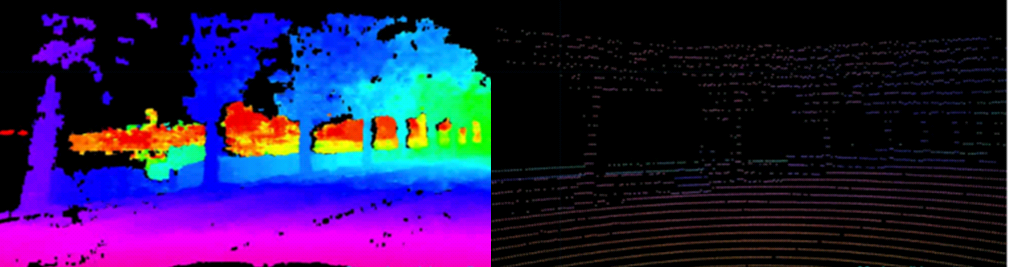
夜間立體(左)和LiDAR(右)密度比較
Broggi解釋說,精度是另一個重要的衡量標準,它提供的不是直接的距離測量,而是立體視覺。對于立體,距離是一個導出量,是通過處理兩個亮度圖像獲得的間接測量。不管怎樣,立體視覺在遠距離(不強制要求精確測量距離)和短程(要求高精度執行精確移動)方面都能提供自動駕駛應用所需的精度水平。例如,在短距離內,立體可以提供毫米級距離的感測。
除了分辨率和精度,現代立體視覺還有以下優點:
立體的一對攝像頭都可以作為獨立的單目攝像頭使用,提供內置冗余
立體攝像頭提供的雙圖像可以在一個芯片上并行執行單目CNN算法,如目標分類
立體視覺提供了感測一般3D形狀的能力,即使那些沒有被歸類為已知障礙物的形狀,例如,從另一輛車上掉落的石頭、各種碎片或隨機物體(如梯子或床墊)會被立體系統感測到;即使是負面障礙,如坑洞,也可以準確感測到
立體攝像頭相對便宜,是大容量應用的重要考慮因素;也沒有移動部件,可以自動認證,并消耗最少的電力
立體視覺以幀速率運行(每秒30幀超高清圖像),因為立體引擎是硬連線到立體功能芯片,可以實現極高的數據率
立體攝像頭可以自動校準,使兩個攝像頭的位置保持相對固定,否則測量數據將不正確
在典型駕駛條件下,振動和沖擊是一種常態,這對立體系統來說是一個挑戰。一些公司開發的實時自動校準程序可以補償通常在正常車輛運行期間發生的攝像頭移動,確保立體視覺處理的精確度。
立體視覺是ADAS和AD的未來
如今,視覺感知已進入深水區,算法將決定誰是贏家。雙目的算法要求比普通單目要高,而且在車輛生命周期內必須保持感測的穩定性能,使兩個鏡頭保持位置相對不變才能感知準確,或者采用自校準能力很強的算法。Ambarella高級算法工程師Francesca Ghidini博士認為,立體視覺可能是全自動駕駛汽車的關鍵,它是互聯技術網格(mesh)的一部分,將為全自動車輛鋪平道路。
崔凱認為:“全球范圍能夠量產雙目的廠家也就是個位數,預計L3級別以上自動駕駛車輛采用雙目攝像頭會成為主流,而主機廠選擇雙目沒啥難度。”
孫路認為:“感知的準確性首先要提高算法的性能,同時要依賴結構設計、產線設計多年積累的豐富經驗。主機廠采用雙目沒有難度,但由于尺寸較單目大,所以需要內飾布置,一般不會集成到域控制器中。”
Cadence電氣工程技術專家Adrian Gibbons則表示:“過去幾年,ADAS一直在不斷發展,在現階段,立體視覺處理技術的下一步進展將有助于ADAS的普及。”
責任編輯:xj
-
立體視覺
+關注
關注
0文章
36瀏覽量
9772 -
激光雷達
+關注
關注
967文章
3940瀏覽量
189601 -
LIDAR
+關注
關注
10文章
323瀏覽量
29358
發布評論請先 登錄
相關推薦
激光雷達技術的基于深度學習的進步
如何提升激光雷達數據的精度
激光雷達在地形測繪中的作用
物聯網系統中的自動駕駛的“眼睛”_純固態激光雷達

愛普生IMU產品在激光雷達測繪中的應用

晶振在激光雷達系統中的作用有哪些
機載單光子激光雷達系統用于實現高分辨率3D成像
全固態激光雷達SPAD芯片量產落地!阜時科技芯片上車應用
激光雷達分辨率對比方法與技巧詳解

Stellantis宣布投資高性能激光雷達傳感技術開發商SteerLight

激光雷達的應用場景
汽車激光雷達:競爭格局和技術演進
512線激光雷達還不是盡頭,1024線激光雷達早在兩年前已經推出?






 工商網監
工商網監
評論