") 權(quán)值衰減和L2正則化傻傻分不清楚?本文來教會你如何分清
權(quán)值衰減和L2正則化傻傻分不清楚?本文來教會你如何分清
作者:Divyanshu Mishra
編譯:ronghuaiyang
導讀
權(quán)值衰減和L2正則化,到底是不是同一個東西,這篇文章給你答案。
神經(jīng)網(wǎng)絡(luò)是偉大的函數(shù)逼近器和特征提取器,但有時它們的權(quán)值變得過于特定化,導致過擬合。這就是正則化概念出現(xiàn)的地方,我們將討論兩種主要權(quán)重正則化技術(shù)之間的細微差別,它們經(jīng)常被錯誤地認為是相同的。
介紹
1943年,Warren McCulloch和Walter Pitts首先提出了神經(jīng)網(wǎng)絡(luò),但當時還不夠流行,因為神經(jīng)網(wǎng)絡(luò)需要大量數(shù)據(jù)和計算能力,這在當時是不可行的。但隨著上述約束條件和其他訓練技術(shù)的進步(如參數(shù)初始化和更好的激活函數(shù))變得可行,它們再次開始主導各種比賽,并在各種人類輔助技術(shù)中找到了它的應用。
如今,神經(jīng)網(wǎng)絡(luò)構(gòu)成了許多著名應用的最主要的部分,如自動駕駛汽車、谷歌翻譯、人臉識別系統(tǒng)等,并應用于幾乎所有人類發(fā)展所使用的技術(shù)。
神經(jīng)網(wǎng)絡(luò)非常擅長于將函數(shù)近似為線性或非線性,在從輸入數(shù)據(jù)中提取特征時也非常出色。這種能力使他們在大量的任務中表現(xiàn)出色,無論是計算機視覺領(lǐng)域還是語言建模。但我們都聽過這句名言:
“能力越大,責任越大。”
這句話也適用于全能的神經(jīng)網(wǎng)絡(luò)。它們作為強大的函數(shù)近似器的能力有時會導致它們通過逼近一個函數(shù)來過擬合數(shù)據(jù)集,這個函數(shù)在它被訓練過的數(shù)據(jù)上表現(xiàn)得非常好,但在測試它之前從未見過的數(shù)據(jù)時卻敗得很慘。更有技術(shù)意義的是,神經(jīng)網(wǎng)絡(luò)學習的權(quán)值對給定的數(shù)據(jù)更加專門化,而不能學習可以一般化的特征。為了解決過擬合的問題,應用了一類稱為正則化的技術(shù)來降低模型的復雜性和約束權(quán)值,迫使神經(jīng)網(wǎng)絡(luò)學習可泛化的特征。
正則化
正則化可以定義為我們?yōu)榱藴p少泛化誤差而不是減少訓練誤差而對訓練算法所做的任何改變。有許多正規(guī)化策略。有的對模型添加額外的約束,如對參數(shù)值添加約束,有的對目標函數(shù)添加額外的項,可以認為是對參數(shù)值添加間接或軟約束。如果我們仔細使用這些技術(shù),這可以改善測試集的性能。在深度學習的環(huán)境中,大多數(shù)正則化技術(shù)都基于正則化估計器。當正則化一個估計量時,有一個折衷,我們必須選擇一個增加偏差和減少方差的模型。一個有效的正規(guī)化是使一個有利可圖的交易,顯著減少方差,而不過度增加偏差。
在實踐中使用的主要正規(guī)化技術(shù)有:
① L2正則化
② L1正則化
③ 數(shù)據(jù)增強
④ Dropout
⑤ Early Stopping
在這篇文章中,我們主要關(guān)注L2正則化,并討論我們是否可以將L2正則化和權(quán)重衰減作為同一枚硬幣的兩面。
L2 正則化
L2正則化屬于正則化技術(shù)的一類,稱為參數(shù)范數(shù)懲罰。之所以提到這類技術(shù),是因為在這類技術(shù)中,特定參數(shù)的范數(shù)(主要是權(quán)重)被添加到被優(yōu)化的目標函數(shù)中。在L2范數(shù)中,在網(wǎng)絡(luò)的損失函數(shù)中加入一個額外的項,通常稱為正則化項。例如:
交叉熵損失函數(shù)的定義如下所示。
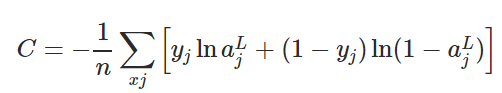

為了將L2正則化應用于任何有交叉熵損失的網(wǎng)絡(luò),我們將正則化項添加到損失函數(shù)中,其中正則化項如下所示:

在上式中,λ是正則化參數(shù),與應用的正則化量成正比。如果λ=0,則不應用正則化,當λ= 1時,對網(wǎng)絡(luò)應用最大正則化。λ是一個超參數(shù),這意味著它不是在訓練期間學習的,而是由用戶手動調(diào)整或使用一些超參數(shù)調(diào)整技術(shù),如隨機搜索。
現(xiàn)在讓我們把這些放在一起,形成L2正則化的最終方程,應用于下式所給出的交叉熵損失函數(shù)。

上面的例子展示了L2正則化應用于交叉熵損失函數(shù),但這一概念可以推廣到所有可用的損失函數(shù)。下式給出了L2正則化更一般的公式,其中C0為非正則化損失函數(shù),C為加入正則化項的正則化損失函數(shù)。

注:我們在對網(wǎng)絡(luò)進行正則化時不考慮網(wǎng)絡(luò)的bias,原因如下:
1、與權(quán)重相比,bias通常需要更少的數(shù)據(jù)來精確擬合。每個權(quán)重指定了兩個變量如何相互作用(w和x),因此要想很好地擬合權(quán)重,就需要在各種條件下觀察兩個變量,而每個bias只控制一個單一變量(b)。因此,我們對bias不使用正則化,以免引入太多的方差。2、對bias進行正則化可能引入大量的欠擬合。
為什么L2 正則化有用?
實踐推理:
讓我們試著理解L2正則化基于損失函數(shù)的梯度的工作原理。如果我們對網(wǎng)絡(luò)中所有權(quán)重和偏差取上面式子中所示方程的偏導數(shù)或梯度,即?C/?w和?C/?b。求偏導數(shù),我們得到:

我們可以使用backpropagation算法計算上述方程中提到的?C0/?w和?C0/?b項。由于沒有應用正則化項,偏置參數(shù)的偏導將不變,而權(quán)重參數(shù)將包含額外的(λ/n)*w)正則化項。
偏置和權(quán)重的學習規(guī)則由此變?yōu)椋?/p>
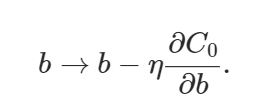
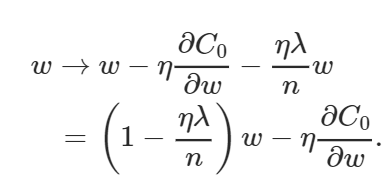
上面的權(quán)值方程類似于通常的梯度下降學習規(guī)則,除了現(xiàn)在我們首先通過 (1?(η*λ)/n)重新調(diào)整權(quán)值w。這就是L2正則化經(jīng)常被稱為權(quán)重衰減的原因,因為它使權(quán)重變小。因此,你可以看到為什么正則化工作的時候,它使網(wǎng)絡(luò)的權(quán)值更小。權(quán)值變小意味著,如果我們在這里或那里改變一些隨機輸入,網(wǎng)絡(luò)的行為不會有太大的變化,這反過來使正則化的網(wǎng)絡(luò)很難學習數(shù)據(jù)中的局部噪聲。這迫使網(wǎng)絡(luò)只學習那些在訓練集中經(jīng)常看到的特征。
個人的直覺:
簡單地從優(yōu)化損失函數(shù)的角度來考慮L2正則化,當我們把正則化項添加到損失函數(shù)中我們實際上增加了損失函數(shù)的值。因此,如果權(quán)值越大,損失也就越高,訓練算法會試圖通過懲罰權(quán)值來降低損失函數(shù),迫使它們?nèi)「〉闹担瑥亩咕W(wǎng)絡(luò)正則化。
L2 正則化和權(quán)值衰減是一樣的嗎?
L2正則化和權(quán)值衰減并不是一回事,但是可以根據(jù)學習率對權(quán)值衰減因子進行重新參數(shù)化,從而使SGD等價。不明白?讓我給你詳細解釋一下。
以λ為衰減因子,給出了權(quán)值衰減方程。

在以下證明中可以證明L2正則化等價于SGD情況下的權(quán)值衰減:
1、讓我們首先考慮下面圖中給出的L2正則化方程。我們的目標是對它進行重新參數(shù)化,使其等價于上式中給出的權(quán)值衰減方程。
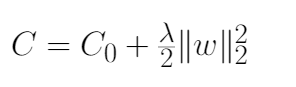
2、首先,我們找到L2正則化損失函數(shù)相對于參數(shù)w的偏導數(shù)(梯度),如下式所示。


注意:上圖中這兩種符號的意思是一樣的。
3、得到損失函數(shù)的偏導數(shù)結(jié)果后,將結(jié)果代入梯度下降學習規(guī)則中,如下式所示。代入后,打開括號,重新排列,使其等價于在一定假設(shè)下的權(quán)值衰減方程。

4、你可以注意到,最終重新排列的L2正則化方程和權(quán)值衰減方程之間的唯一區(qū)別是α(學習率)乘以λ(正則化項)。為了得到兩個方程,我們用λ來重新參數(shù)化L2正則化方程。
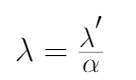
5、將λ'替換為λ,對L2正則化方程進行重新參數(shù)化,將其等價于權(quán)值衰減方程,如下式所示。

從上面的證明中,你必須理解為什么L2正則化在SGD情況下被認為等同于權(quán)值衰減,但對于其他基于自適應梯度的優(yōu)化算法,如Adam, AdaGrad等,卻不是這樣。特別是,當與自適應梯度相結(jié)合時,L2正則化導致具有較大歷史參數(shù)和/或梯度振幅的權(quán)值比使用權(quán)值衰減時正則化得更少。這導致與SGD相比,當使用L2正則化時adam表現(xiàn)不佳。另一方面,權(quán)值衰減在SGD和Adam身上表現(xiàn)得一樣好。
一個令人震驚的結(jié)果是,帶有動量的SGD優(yōu)于像Adam這樣的自適應梯度方法,因為常見的深度學習庫實現(xiàn)了L2正則化,而不是原始的權(quán)重衰減。因此,在使用L2正則化有利于SGD的任務上,Adam的結(jié)果要比使用動量的SGD差。
總結(jié)
因此,我們得出結(jié)論,盡管權(quán)值衰減和L2正則化在某些條件下可以達到等價,但概念上還是有細微的不同,應該區(qū)別對待,否則可能導致無法解釋的性能下降或其他實際問題。
本文轉(zhuǎn)自:AI公園,作者:Divyanshu Mishra,編譯:ronghuaiyang,
轉(zhuǎn)載此文目的在于傳遞更多信息,版權(quán)歸原作者所有。
審核編輯 黃昊宇
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4765瀏覽量
100568 -
正則化
+關(guān)注
關(guān)注
0文章
17瀏覽量
8123
發(fā)布評論請先 登錄
相關(guān)推薦
ADS131M03打印輸出的電壓值與實際輸入電壓值對不上是怎么回事?
模擬信號、數(shù)字信號、ADC與DAC傻傻分不清楚?一文了解,收藏再看

用adc讀取電壓值時,顯示的電壓值是亂碼怎么解決?
用adc讀取電壓值時,顯示的電壓值是亂碼,如何解決?
頻段、信道、帶寬和傳輸速率,還傻傻分不清楚?

一文介紹:UWB-AOA產(chǎn)品特點及其應用
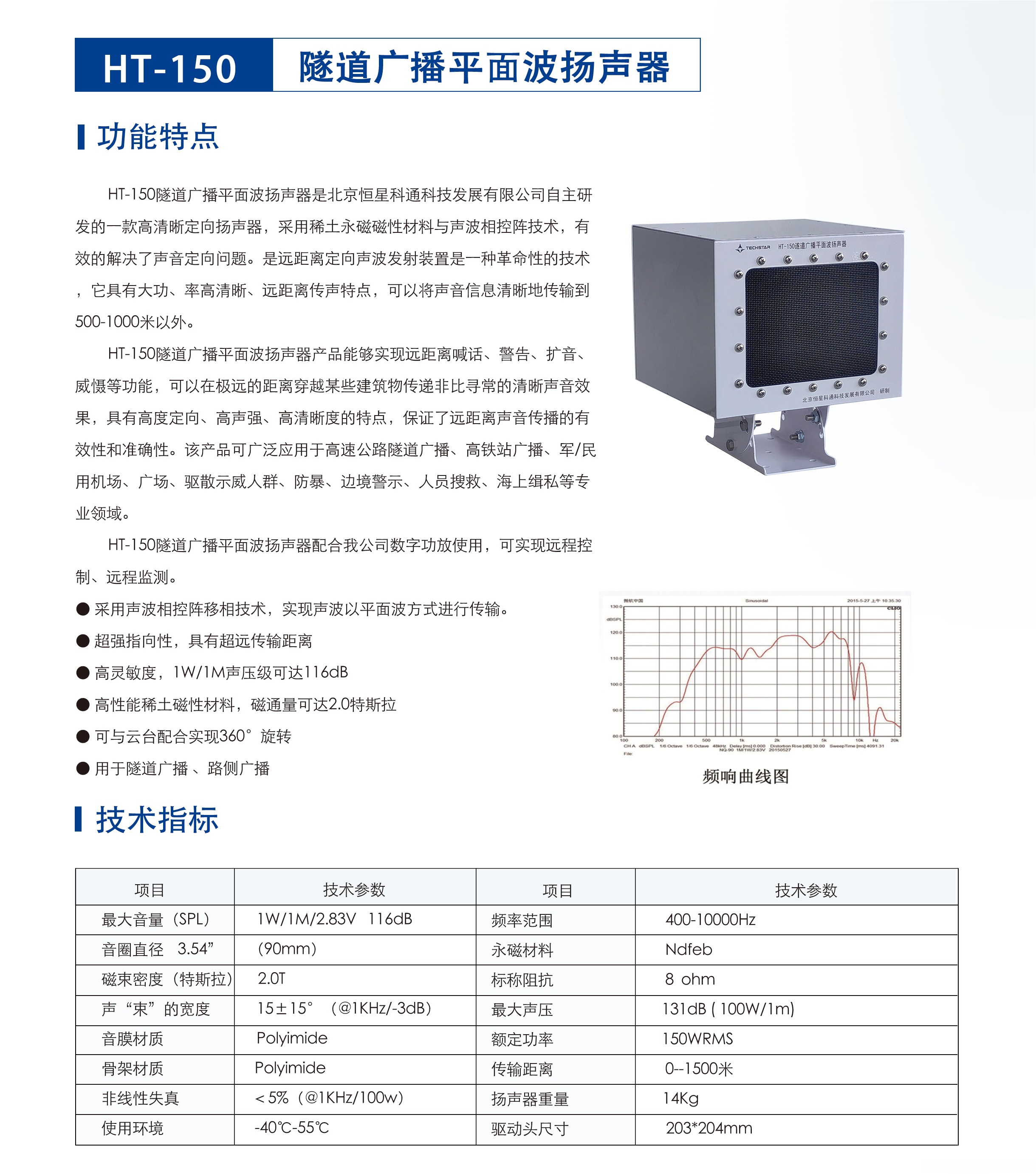
如何解決隧道廣播聽不清楚的問題
傻傻分不清?射頻模擬信號源和矢量信號源的區(qū)別
FOSB和FOUP傻傻分不清楚?
你還是分不清多進程和多線程嗎?一文搞懂!
[ElfBoard]是誰字和字節(jié)傻傻分不清楚?
[ElfBoard]康康是誰字和字節(jié)傻傻分不清楚?
4R技術(shù)(AR、VR、MR、XR)傻傻分不清,看完這篇你就懂了!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論