 模型訓練擬合的分類和表現
模型訓練擬合的分類和表現
在進行數據挖掘或者機器學習模型建立的時候,因為在統計學習中,假設數據滿足獨立同分布(i.i.d,independently and identically distributed),即當前已產生的數據可以對未來的數據進行推測與模擬,因此都是使用歷史數據建立模型,即使用已經產生的數據去訓練,然后使用該模型去擬合未來的數據。 在我們機器學習和深度學習的訓練過程中,經常會出現過擬合和欠擬合的現象。訓練一開始,模型通常會欠擬合,所以會對模型進行優化,然而等到訓練到一定程度的時候,就需要解決過擬合的問題了。
一、模型訓練擬合的分類和表現
如何判斷過擬合呢?我們在訓練過程中會定義訓練誤差,驗證集誤差,測試集誤差(泛化誤差)。訓練誤差總是減少的,而泛化誤差一開始會減少,但到一定程序后不減反而增加,這時候便出現了過擬合的現象。
如下圖所示,從直觀上理解,欠擬合就是還沒有學習到數據的特征,還有待繼續學習,而過擬合則是學習進行的太徹底,以至于把數據的一些局部特征或者噪聲帶來的特征都給學到了,所以在進行測試的時候泛化誤差也不佳。
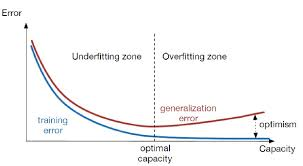
從方差和偏差的角度來說,欠擬合就是在訓練集上高方差、高偏差,過擬合也就是訓練集上高方差、低偏差。為了更加生動形象的表示,我們看一些經典的圖:
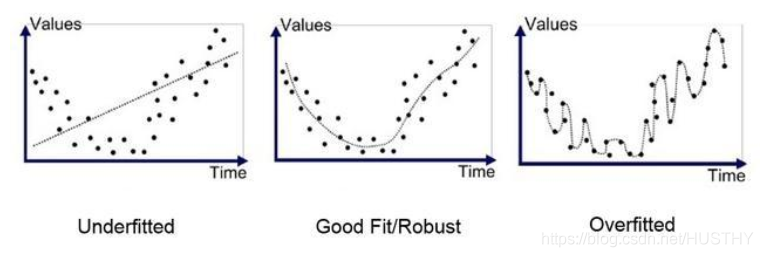
對比這幾個圖,發現圖一的擬合并沒有把大體的規律給擬合出來,這個就是欠擬合。圖三則是擬合的太細致了,用的擬合函數太復雜了,在這些數據集上的效果很好,但是換到另外的一個數據集效果肯定可預見的不好。只有圖二是最好的,把數據的規律擬合出來了,同時在更換數據集后,效果也不會很差。
仔細想想圖片三中的模型,擬合函數肯定是一個高次函數,其參數個數肯定肯定比圖二的要多,可以說圖三的擬合函數比圖二的要大,模型更加復雜。這也是過擬合的一個判斷經驗,模型是否太復雜。另外,針對圖三,我們把一些高次變量對應的參數值變小,也就相當于把模型變簡單了。這個角度上看,可以減小參數值,也就是一般模型過擬合,參數值整體比較大。從模型復雜性來講,可以是:1、模型的參數個數;2、模型的參數值的大小。個數越多,參數值越大,模型就越復雜。
二、欠擬合
1、欠擬合的表現
針對模型過擬合這個問題,有沒有什么方法來判定模型是否過擬合呢?其實一般都是依靠模型在訓練集和驗證集上的表現有一個大體的判斷就行了。如果要有一個具體的方法,可以參考機器學中,學習曲線來判斷模型是否過擬合。如下圖:
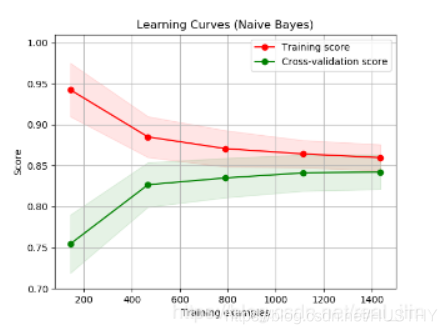
也就是看訓練集合驗證集隨著樣本數量的增加,他們之間的差值變化。如果訓練集和測試集的準確率都很低,那么說明模型欠擬合。
2、欠擬合的解決方案
欠擬合是由于學習不足,可以考慮添加特征,從數據中挖掘出更多的特征,有時候還需要對特征進行變換,使用組合特征和高次特征。
模型簡單也會導致欠擬合,例如線性模型只能擬合一次函數的數據。嘗試使用更高級的模型有助于解決欠擬合,如使用SVM,神經網絡等。
正則化參數是用來防止過擬合的,出現欠擬合的情況就要考慮減少正則化參數。
三、過擬合
1、過擬合的定義
模型在訓練集上的表現很好,但在測試集和新數據上的表現很差。
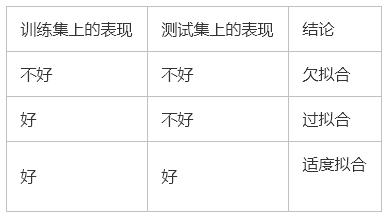
2、過擬合的原因
1)數據量太小
這個是很容易產生過擬合的一個原因。設想,我們有一組數據很好的吻合3次函數的規律,現在我們局部的拿出了很小一部分數據,用機器學習或者深度學習擬合出來的模型很大的可能性就是一個線性函數,在把這個線性函數用在測試集上,效果可想而知肯定很差了。
2)訓練集和驗證集分布不一致
訓練集訓練出一個適合訓練集那樣分布的數據集,當你把模型運用到一個不一樣分布的數據集上,效果肯定大打折扣。這個是顯而易見的。
3)模型復雜度太大
在選擇模型算法的時候,首先就選定了一個復雜度很高的模型,然后數據的規律是很簡單的,復雜的模型反而就不適用了。
4)數據質量很差
數據還有很多噪聲,模型在學習的時候,肯定也會把噪聲規律學習到,從而減小了具有一般性的規律。這個時候模型用來預測肯定效果也不好。
5)過度訓練
這個是同第4個是相聯系的,只要訓練時間足夠長,那么模型肯定就會吧一些噪聲隱含的規律學習到,這個時候降低模型的性能是顯而易見的。
3、解決方案
1)降低模型復雜度
處理過擬合的第一步就是降低模型復雜度。為了降低復雜度,我們可以簡單地移除層或者減少神經元的數量使得網絡規模變小。與此同時,計算神經網絡中不同層的輸入和輸出維度也十分重要。雖然移除層的數量或神經網絡的規模并無通用的規定,但如果你的神經網絡發生了過擬合,就嘗試縮小它的規模。
2)數據集擴增
在數據挖掘領域流行著這樣的一句話,“有時候往往擁有更多的數據勝過一個好的模型”。因為我們在使用訓練數據訓練模型,通過這個模型對將來的數據進行擬合,而在這之間又一個假設便是,訓練數據與將來的數據是獨立同分布的。即使用當前的訓練數據來對將來的數據進行估計與模擬,而更多的數據往往估計與模擬地更準確。因此,更多的數據有時候更優秀。但是往往條件有限,如人力物力財力的不足,而不能收集到更多的數據,如在進行分類的任務中,需要對數據進行打標,并且很多情況下都是人工得進行打標,因此一旦需要打標的數據量過多,就會導致效率低下以及可能出錯的情況。所以,往往在這時候,需要采取一些計算的方式與策略在已有的數據集上進行手腳,以得到更多的數據。
通俗得講,數據機擴增即需要得到更多的符合要求的數據,即和已有的數據是獨立同分布的,或者近似獨立同分布的。
一般有以下方法:
從數據源頭采集更多數據
復制原有數據并加上隨機噪聲
重采樣
根據當前數據集估計數據分布參數,使用該分布產生更多數據等
3)數據增強
使用數據增強可以生成多幅相似圖像。這可以幫助我們增加數據集規模從而減少過擬合。因為隨著數據量的增加,模型無法過擬合所有樣本,因此不得不進行泛化。計算機視覺領域通常的做法有:翻轉、平移、旋轉、縮放、改變亮度、添加噪聲等等
4)正則化
正則化方法是指在進行目標函數或代價函數優化時,在目標函數或代價函數后面加上一個正則項,一般有L1正則與L2正則等。
L1懲罰項的目的是使權重絕對值最小化。公式如下:
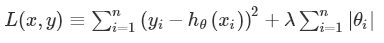
L2懲罰項的目的是使權重的平方最小化。公式如下:
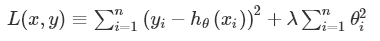
以下表格對兩種正則化方法進行了對比:
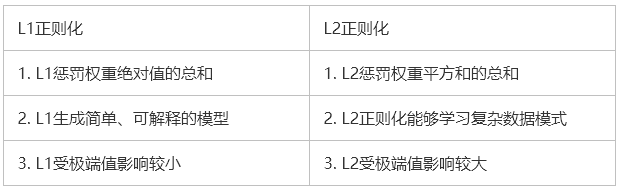
如果數據過于復雜以至于無法準確地建模,那么L2是更好的選擇,因為它能夠學習數據中呈現的內在模式。而當數據足夠簡單,可以精確建模的話,L1更合適。對于我遇到的大多數計算機視覺問題,L2正則化幾乎總是可以給出更好的結果。然而L1不容易受到離群值的影響。所以正確的正則化選項取決于我們想要解決的問題。
總結
正則項是為了降低模型的復雜度,從而避免模型區過分擬合訓練數據,包括噪聲與異常點(outliers)。從另一個角度上來講,正則化即是假設模型參數服從先驗概率,即為模型參數添加先驗,只是不同的正則化方式的先驗分布是不一樣的。這樣就規定了參數的分布,使得模型的復雜度降低(試想一下,限定條件多了,是不是模型的復雜度降低了呢),這樣模型對于噪聲與異常點的抗干擾性的能力增強,從而提高模型的泛化能力。還有個解釋便是,從貝葉斯學派來看:加了先驗,在數據少的時候,先驗知識可以防止過擬合;從頻率學派來看:正則項限定了參數的取值,從而提高了模型的穩定性,而穩定性強的模型不會過擬合,即控制模型空間。
另外一個角度,過擬合從直觀上理解便是,在對訓練數據進行擬合時,需要照顧到每個點,從而使得擬合函數波動性非常大,即方差大。在某些小區間里,函數值的變化性很劇烈,意味著函數在某些小區間里的導數值的絕對值非常大,由于自變量的值在給定的訓練數據集中的一定的,因此只有系數足夠大,才能保證導數的絕對值足夠大。
如下圖(引用知乎):
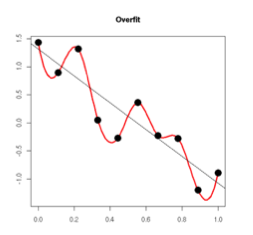
另外一個解釋,規則化項的引入,在訓練(最小化cost)的過程中,當某一維的特征所對應的權重過大時,而此時模型的預測和真實數據之間距離很小,通過規則化項就可以使整體的cost取較大的值,從而,在訓練的過程中避免了去選擇那些某一維(或幾維)特征的權重過大的情況,即過分依賴某一維(或幾維)的特征(引用知乎)。
L2與L1的區別在于,L1正則是拉普拉斯先驗,而L2正則則是高斯先驗。它們都是服從均值為0,協方差為1λ。當λ=0時,即沒有先驗)沒有正則項,則相當于先驗分布具有無窮大的協方差,那么這個先驗約束則會非常弱,模型為了擬合所有的訓練集數據,參數可以變得任意大從而使得模型不穩定,即方差大而偏差小。λ越大,標明先驗分布協方差越小,偏差越大,模型越穩定。即,加入正則項是在偏差bias與方差variance之間做平衡tradeoff(來自知乎)。
下圖即為L2與L1正則的區別:
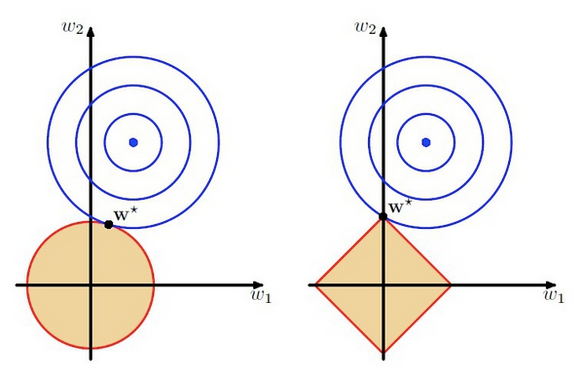
上圖中的模型是線性回歸,有兩個特征,要優化的參數分別是w1和w2,左圖的正則化是L2,右圖是L1。藍色線就是優化過程中遇到的等高線,一圈代表一個目標函數值,圓心就是樣本觀測值(假設一個樣本),半徑就是誤差值,受限條件就是紅色邊界(就是正則化那部分),二者相交處,才是最優參數。可見右邊的最優參數只可能在坐標軸上,所以就會出現0權重參數,使得模型稀疏。
其實拉普拉斯分布與高斯分布是數學家從實驗中誤差服從什么分布研究中得來的。一般直觀上的認識是服從應該服從均值為0的對稱分布,并且誤差大的頻率低,誤差小的頻率高,因此拉普拉斯使用拉普拉斯分布對誤差的分布進行擬合,如下圖:
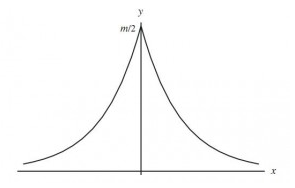
而拉普拉斯在最高點,即自變量為0處不可導,因為不便于計算,于是高斯在這基礎上使用高斯分布對其進行擬合,如下圖:
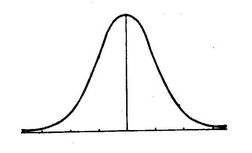
5)dropout
正則是通過在代價函數后面加上正則項來防止模型過擬合的。而在神經網絡中,有一種方法是通過修改神經網絡本身結構來實現的,其名為Dropout。該方法是在對網絡進行訓練時用一種技巧(trick),對于如下所示的三層人工神經網絡:
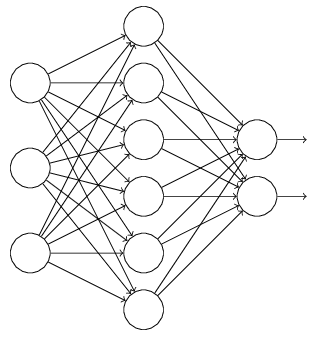
對于上圖所示的網絡,在訓練開始時,隨機得刪除一些(可以設定為一半,也可以為1/3,1/4等)隱藏層神經元,即認為這些神經元不存在,同時保持輸入層與輸出層神經元的個數不變,這樣便得到如下的ANN:
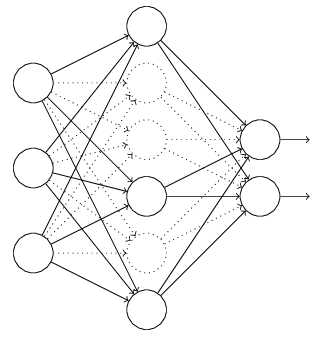
然后按照BP學習算法對ANN中的參數進行學習更新(虛線連接的單元不更新,因為認為這些神經元被臨時刪除了)。這樣一次迭代更新便完成了。下一次迭代中,同樣隨機刪除一些神經元,與上次不一樣,做隨機選擇。這樣一直進行瑕疵,直至訓練結束。
這種技術被證明可以減少很多問題的過擬合,這些問題包括圖像分類、圖像切割、詞嵌入、語義匹配等問題。
6)早停
對模型進行訓練的過程即是對模型的參數進行學習更新的過程,這個參數學習的過程往往會用到一些迭代方法,如梯度下降(Gradient descent)學習算法。Early stopping便是一種迭代次數截斷的方法來防止過擬合的方法,即在模型對訓練數據集迭代收斂之前停止迭代來防止過擬合。
Early stopping方法的具體做法是,在每一個Epoch結束時(一個Epoch集為對所有的訓練數據的一輪遍歷)計算validation data的accuracy,當accuracy不再提高時,就停止訓練。這種做法很符合直觀感受,因為accurary都不再提高了,在繼續訓練也是無益的,只會提高訓練的時間。如下圖所示,在幾次迭代后,即使訓練誤差仍然在減少,但測驗誤差已經開始增加了。
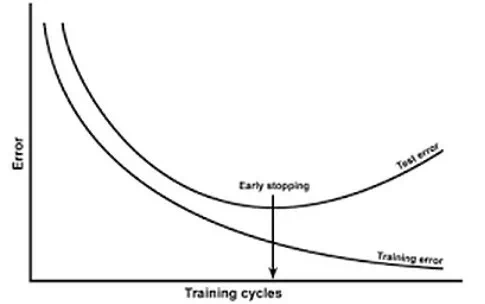
那么該做法的一個重點便是怎樣才認為validation accurary不再提高了呢?并不是說validation accuracy一降下來便認為不再提高了,因為可能經過這個Epoch后,accuracy降低了,但是隨后的Epoch又讓accuracy又上去了,所以不能根據一兩次的連續降低就判斷不再提高。一般的做法是,在訓練的過程中,記錄到目前為止最好的validation accuracy,當連續10次Epoch(或者更多次)沒達到最佳accuracy時,則可以認為accuracy不再提高了。此時便可以停止迭代了(Early Stopping)。這種策略也稱為“No-improvement-in-n”,n即Epoch的次數,可以根據實際情況取,如10、20、30……
7)重新清洗數據
把明顯異常的數據剔除
8)使用集成學習方法
把多個模型集成在一起,降低單個模型的過擬合風險
本文轉自:博客園 - 早起的小蟲子,轉載此文目的在于傳遞更多信息,版權歸原作者所有。
審核編輯:何安
-
深度學習
+關注
關注
73文章
5493瀏覽量
120979
發布評論請先 登錄
相關推薦

如何訓練自己的LLM模型
大語言模型的預訓練
深度學習模型中的過擬合與正則化
人臉識別模型訓練失敗原因有哪些
預訓練模型的基本原理和應用
神經網絡擬合的誤差怎么分析
深度學習模型訓練過程詳解
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
深度學習如何訓練出好的模型

超分畫質大模型!華為和清華聯合提出CoSeR:基于認知的萬物超分大模型






 工商網監
工商網監
評論