 目標檢測是計算機視覺領域中一個新興的應用方向
目標檢測是計算機視覺領域中一個新興的應用方向
目標定位
圖像分類是對圖像進行分類,比如判斷圖像中是否是車。定位分類不僅要圖片分類,而且需要確定目標在圖像中的哪個位置。目標檢測中要識別的對象不僅僅只有一個,目標檢測要識別圖像中多個對象。
自動駕駛需要用到目標檢測技術。給出一張汽車行駛中的圖片
我們需要判斷圖中1-是否有行人,2-是否有車,3-是否有摩托車,4-圖片是否只是背景圖,還需要判斷圖中汽車的位置。設圖片左上角的坐標是(0,0),右下角坐標為(1,1)。圖中汽車的中心點位置大概為(bx=0.5,by=0.7),汽車的長和高分別是bw=0.3和bh=0.4。我們訓練的神經網絡就要有兩種類型的輸出,一種是4種對象的檢測,另外一種是車的位置信息。
我們定義這張圖片的標簽y要包含下面幾個元素
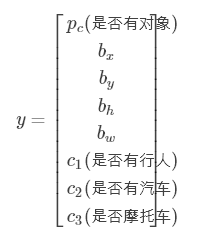
如果圖片中有任意的對象,比如上圖,那么
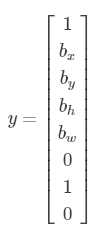
如果圖片中什么都沒有,那么
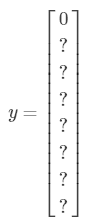
其中第一個元素置為0,其它元素可以不用設置,因為都沒有任何對象了,我們不關心其它的信息了。
目標定位的損失函數是
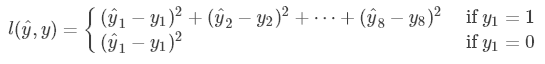
這里簡單地使用了平方損失函數。
特征點檢測
除了可以使用矩形框標出目標在圖片中的位置,還可以使用特征點來表示目標的位置。
在人臉檢測中,可以使用特征點來表示人臉的位置,或者具體的部位,比如眼睛,鼻子,嘴巴。
樣本的標簽y是一個坐標點的集合,第1個點表示左眼左側眼角,第2個點表示左眼右側眼角,第3個點表示右眼左側眼角,以此類推。
特征點檢測有許多應用場景。比如說AR,在人的頭上顯示一個皇冠,需要得到人臉的特征點位置,然后判斷人臉的傾斜度,最后把皇冠“戴”到頭上。
滑動窗體檢測
為了從一幅大圖中找出圖中汽車的位置,需要用到活動窗體檢測。首先使用汽車圖片訓練一個卷積神經網絡,用于汽車分類。接著設置一個窗體,該窗體在大圖上從上往下從左往右慢慢移動,每移動一步,把窗體截取的內容使用汽車分類器進行分類,如果檢測到有汽車,說明圖中的汽車位置在窗體的位置上。接著使用一個更大的窗體,重復上述步驟。
滑動窗體的移動步長設置大一些,可以減少汽車分類器的分類次數,但是可能會出現這種情況,窗體中的汽車只有車身的一部分,分類器不能識別,這樣導致整個系統的性能降低。
把圖片分成一塊塊區域,然后分別使用分類器分類,這樣的滑動窗體的效率非常低。我們需要一個高效率的滑動窗體的方法。
首先要介紹把全連接層轉成卷積層。
把上圖的第一個全連接層,改成用5×5×16的過濾器來卷積,一次卷積的操作數是所有輸入值,這相當于一次全連接,然后設置過濾器的數量為400,相當于計算全連接層的400個輸出值。同理,把第二個全連接層改成用400個1×1×400的過濾器來卷積,得到的1×1×400輸出就是第二個全連接層的輸出。如此類推,最后得到1×1×4的輸出就是softmax層的輸出。
高效率的滑動窗體的方法是使用卷積來實現滑動窗體。
上圖第一行表示一幅14×14×3的圖片使用卷積網絡進行分類的過程。其中全連接層使用卷積層實現。上圖的下一行表示在一幅大圖中實現滑動窗體的計算。首先只觀察藍色方塊,這是一個滑動窗體,這個藍色方塊的大小滿足上一行卷積網絡的規格,把藍色方塊帶入卷積網絡,注意黃色區域也代入卷積網絡中。最后2×2×4的藍色塊表示藍色方塊的分類結果。然后觀察綠色框的區域,這是另外一個滑動窗體,你會發現卷積網絡中綠色框的值就是綠色框區域在上一行卷積網絡中的結果。把大圖輸入到卷積網絡,卷積網絡會同時計算大圖的所有的相同大小滑動窗體的分類結果,這就加快了滑動窗體的分類效率。
Bounding Box 預測
滑動窗體檢測對象的位置不是很精確,例如
黑色框是滑動窗體分割的區域,在綠色框和黃色框中有汽車。直接把綠色框和黃色框作為圖片中汽車的位置太粗略了,我們需要更加精確的汽車位置。這時可以使用到前面所說的目標定位的知識。
我們訓練的分類器不僅僅要輸出圖片是否有汽車,還要輸出汽車在圖片中的位置(Bounding Box),所以可以使用目標定位使用的y,

把這張大圖輸入進卷積網絡,最后得到的輸出為3×3×8的矩陣,其中3×3代表滑動窗體,8表示每個滑動窗體的目標定位的8個預測結果。根據預測結果中的汽車位置信息,可以精確到汽車的具體位置。
這些方法來自YOLO算法。
交并比
交并比函數用于判斷算法的定位預測是否正確。
紅色框是正確的汽車位置,紫色框是預測的位置,交并比函數是指兩者交集和并集的比。圖中黃色區域指的是二者的交集,綠色區域指的是二者的并集,交并比函數公式是
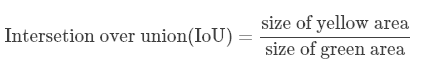
然后設置一個閾值,比如說0.5,如果IoU>0.5,則算法的定位預測沒有問題。如果需要算法預測效果更加精確,閾值可以設置得更高。
非極大值抑制
滑動窗體檢測有一個問題,就是一個對象可能會多次被檢測到。例如
滑動窗體把圖片分成19×19個區域,算法檢測到綠色區域和黃色區域都有汽車。這幾個區域都是汽車的一部分,它們組合起來,擴充更大的區域,才是完整的汽車。
上圖是一個物體被多次檢測到的情況。非極大值抑制會清除多余的檢測結果,比如,保留上圖中pc值最高的兩個(0.8和0.9)檢測結果。
非極大值抑制算法的具體過程如下。
每個滑動窗體輸出的預測值的形式是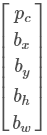 。
。
首先設置一個IoU閾值,比如0.5和一個概率閾值(置信度),比如0.6,清除所有 pc<0.6 的窗體。
如果還有剩下的窗體,執行下面的循環:
選擇pc值最大的輸出作為預測結果。
清除所有剩下的與前一步選擇的窗體IoU>0.5的窗體。
Anchor boxes
上述所說的都是一個窗體檢測一個對象,現在了解一下一個窗體同時檢測多個對象的情況。如果兩個物體對象同時出現在一個窗體中,它們的中心點位置相同,需要算法能夠同時識別這兩個物體對象。
上圖中行人和車的中心點都在同一個位置,之前所說的算法只能檢測到一個對象,因此需要修改算法。
圖中的行人和汽車的形狀不同,行人的矩形框比較長,汽車的矩形框比較寬,定義這些矩形框叫Anchor box,如下圖所示
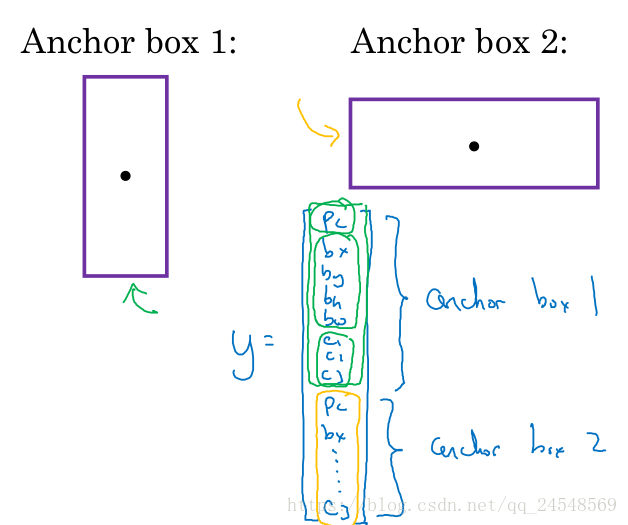
為了能夠同時檢測到Anchor box1和Anchor box2,需要修改標簽y。本來y只有8個元素,現在y有16個元素,前8個元素用來輸出Anchor box1的位置,后8個元素用來輸出Anch box2的位置。pc表示對應的對象是否存在。
上圖的標簽y是下圖的中間向量
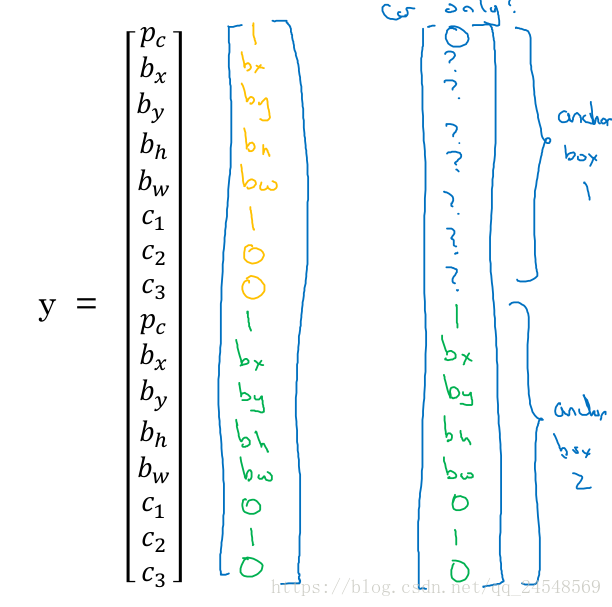
如果行人離開的圖片中,那么y值變為上圖的右邊向量。因為行人不在圖片中,Anchor box1的位置信息就沒有意義了,用?表示。
YOLO算法
現在來簡單介紹YOLO算法的整個過程。
有一個例子是檢測圖片中的行人、汽車和摩托車。我們的算法主要檢測行人和汽車,因此使用兩個Anchor box。每個窗體的標簽值y就如同下圖所示,有16個元素,一半用來記錄行人的位置信息,另一半用來記錄汽車的位置信息。
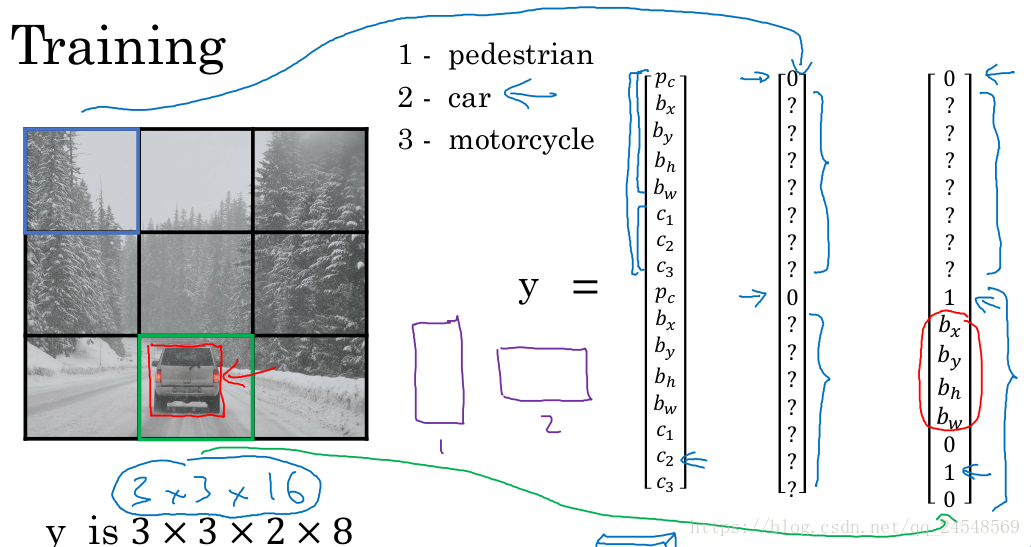
我們使用3×3的滑動窗體,不過一般使用更小的滑動窗體,比如19×19。訓練出來的卷積網絡最后輸出的預測值大小是3×3×16。
對一張圖片進行檢測,每個窗體都會檢測到兩個位置信息,如下圖。對象的邊界的方框可能會超出窗體。
先把低于概率閾值的位置信息去掉
接著,對每個類別(行人和汽車),使用非極大值抑制算法來確定最終的位置。
R-CNN
R-CNN(帶區域的CNN)提出了候選區域(Region proposal)的概念。R-CNN認為滑動窗體有時會檢測什么對象都沒有的區域,這會浪費時間,比如在下圖的兩個藍色區域,是沒有行人或汽車出現,對這兩個區域進行卷積運算會降低系統的效率。
R-CNN對圖片進行圖片分割,得到一幅圖片的區域圖
不同的顏色塊代表圖片的不同區域,這些顏色塊可以作為候選區域,R-CNN認為這些區域可能含有我們的目標對象,直接檢測這些候選區域比檢測所有的滑動窗體要快。
實際上R-CNN比YOLO要慢一些,但是R-CNN的思想值得借鑒。R-CNN自發表出來,已經有速度更快的版本。
R-CNN:最初的R-CNN算法,一次只對一個候選區域進行分類,輸出的是label和bounding box(是否有對象和對象的位置)。
Fast R-CNN:使用滑動窗體的卷積實現來對所有的候選區域進行分類。
Faster R-CNN:使用卷積網絡來獲取候選區域。
版權聲明:本文轉自CSDN(叫什么就是什么),遵循 CC 4.0 BY-SA 版權協議,轉載請附上原文出處鏈接和本聲明。
本文鏈接:https://blog.csdn.net/qq_24548569/article/details/81177007
審核編輯:何安
-
目標檢測
+關注
關注
0文章
205瀏覽量
15590 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45930
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論