 關于pipeline 以及 unroll 指令的介紹
關于pipeline 以及 unroll 指令的介紹
本文轉載自: XILINX開發者社區微信公眾號
HLS 優化設計的最關鍵指令有兩個:一個是流水線 (pipeline) 指令,一個是數據流(dataflow) 指令。正確地使用好這兩個指令能夠增強算法地并行性,提升吞吐量,降低延遲但是需要遵循一定的代碼風格。展開 (unroll) 指令是只針對 for 循環的展開指令,和流水線指令關系密切,所以我們放在一起首先我們來看一下這三個指令在 Xilinx 官方指南中的定義:
Unroll: Unroll for-loops to create multiple instances of the loop body and its instructions that can then be scheduled independently.
Pipeline:Reduces the initiation interval by allowing the overlapped execution of operations within a loop or function.
Dataflow:Enables task level pipelining, allowing functions and loops to execute concurrently. Used to optimize through output and/or latency.
Unroll 指令在 for 循環的代碼區域進行優化,這個指令不包含流水線執行的概念,單純地將循環體展開使用更多地硬件資源實現,保證并行循環體在調度地過程中是彼此獨立的。
Pipeline 指令在循環和函數兩個層級都可以使用,通過增加重復的操作指令(如增加資源使用量等等)來減小初始化間隔。
Dataflow 指令是一個任務級別的流水線指令,從更高的任務層次使得循環或函數可以并行執行,目的在于減小延遲增加吞吐量。
Unroll 和 Pipeline 指令相互重合的關系在于,當對函數進行流水線處理時,以下層次結構中的所有循環都會自動展開,而使用展開指令的循環并沒有給定對II的約束。在最新版本的 Vitis HLS 工具中,工具會自動分析數據之間的流水線操作關系,以II=1為目標優化,但是還是會受限于設計本身的算法和代碼風格。下圖非常清晰地闡明了Unroll 和 Pipeline 指令的關系,Pipeline 指令放置的循環層次越高,循環展開的層次也越高,最終會導致使用更大面積的資源去實現,同時并行性也更高。

這里如果循環的邊界是變量的話,則無法展開。這將組織函數被流水線化,可以通過添加tripcount 等指令,指定循環在綜合時大概的最大最小邊界。
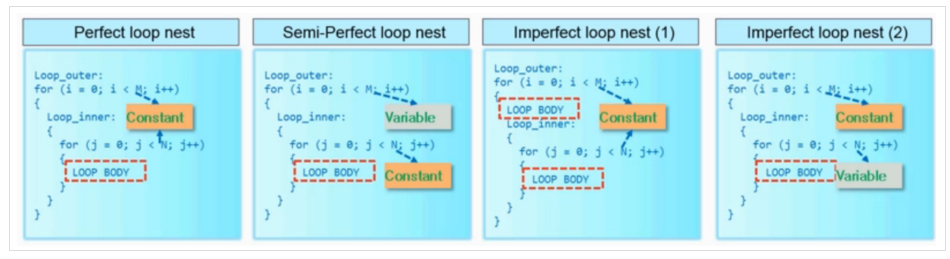
在循環流水線優化的過程中,有一個完美循環,半完美循環和非完美循環的代碼風格概念,只有當流水線循環完美或半完美時,才可以將嵌套循環徹底并行展開。
完美循環:只有最里面的循環才具有主體內容,在循環語句之間沒有指定邏輯,循環界限是恒定的。
半完美循環:只有最里面的循環才具有主體 (內容), 在循環語句之間沒有指定邏輯,只有最外面的循環邊界可以是可變的。
非完美循環:循環的主體內容分布在循環的各個層次或內層循環的邊界是變量。
當我們要爭去最大流水線循環的成功執行,就需要將非完美循環手動修改成完美或半完美循環。 以下代碼例子給出了完美循環(左邊)和非完美循環(右邊)在Vitis HLS 中的執行結果。

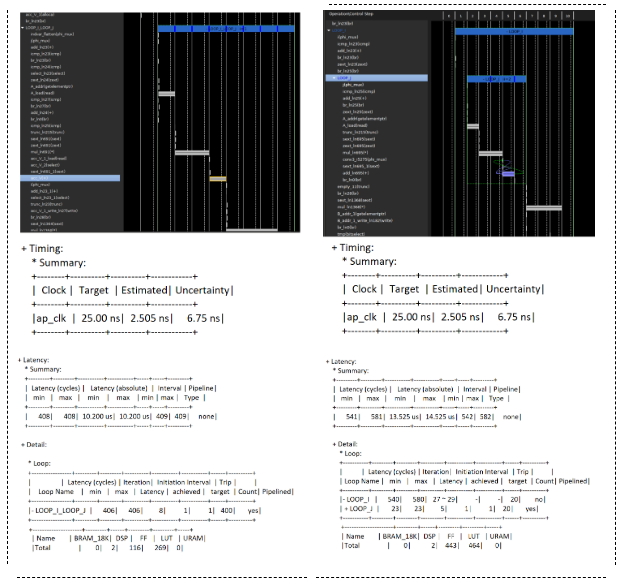
綜合完畢后,我們可以在分析窗口和綜合報告中都很清晰的看出,完美循環在執行的時候,工具自動將內層循環LOOP_J和外層循環LOOP_I合并為一整個大循環,并實現了整個大循環的流水線操作,延遲的周期數為: (400-1) *1+8-1 =406個周期數,延遲大約為 408*2.5 = 1,020 ns
非完美循環中,內層和外層循環沒有合并,只有內層循環LOOP_J 實現了流水線執行,進出內循環的浪費的時鐘周期增加了整個循環的時鐘周期,同時還有一些命令行沒有辦法跨越循環的層級實現調度上的優化,這些因素都導致了設計的延遲的增加。
本文關于pipeline 以及 unroll 指令的介紹到此結束,下篇文章我們將著重介紹 daraflow 指令。
審核編輯:何安
-
指令
+關注
關注
1文章
606瀏覽量
35651
發布評論請先 登錄
相關推薦
plc基本指令的應用有哪些
微處理器的指令集架構介紹
lyrat-mini-v1.2使用例程pipeline_wav_amr_sdcard錄音沒有聲音怎么解決?
三菱plc trd指令詳解介紹
西門子S7-1200 PLC的指令介紹
plc控制伺服電機的指令有哪些
藍牙雙模音頻模塊支持串口AT指令控制介紹

淺析SpinalHDL中Pipeline中的復位定制
什么是pipeline?Go中構建流數據pipeline的技術
AMD-Xilinx的Vitis-HLS編譯指示小結
如何在zcu102板卡上創建pipeline呢?
【愛芯派 Pro 開發板試用體驗】ax650使用ax-pipeline進行推理
PLC常見的傳送指令介紹





 工商網監
工商網監
評論