") 如何去看我們的SQL是否走索引
如何去看我們的SQL是否走索引
問題發(fā)現(xiàn)
我認(rèn)為一條很簡單的 SQL 然后跑了很久,明明我已經(jīng)都建立相應(yīng)的索引,邏輯也不需要優(yōu)化。
SELECTa.custid,b.score,b.xcreditscore,b.lrscore
FROM(
SELECTDISTINCTcustid
FROMsync.`credit_apply`
WHERESUBSTR(createtime,1,10)>='2019-12-15'
ANDrejectrule='xxxx'
)a
LEFTJOIN(
SELECT*
FROMsync.`credit_creditchannel`
)b
ONa.custid=b.custid;
查看索引狀態(tài):credit_apply表
mysql>showindexfromsync.`credit_apply`;
+--------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
|Table|Non_unique|Key_name|Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|
+--------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
|credit_apply|0|PRIMARY|1|applyId|A|1468496|NULL|NULL||BTREE|||
|credit_apply|1|index2|1|custId|A|666338|NULL|NULL||BTREE|||
|credit_apply|1|index2|2|createTime|A|1518231|NULL|NULL||BTREE|||
+--------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
或者
CREATETABLE`credit_apply`(
`applyId`bigint(20)NOTNULLAUTO_INCREMENT,
`custId`varchar(128)COLLATEutf8mb4_unicode_ciNOTNULL,
`ruleVersion`int(11)NOTNULLDEFAULT'1',
`rejectRule`varchar(128)COLLATEutf8mb4_unicode_ciDEFAULT'DP0000',
`status`tinyint(4)NOTNULLDEFAULT'0',
`extra`textCOLLATEutf8mb4_unicode_ci,
`createTime`timestampNOTNULLDEFAULTCURRENT_TIMESTAMP,
`updateTime`timestampNOTNULLDEFAULTCURRENT_TIMESTAMPONUPDATECURRENT_TIMESTAMP,
`mobile`varchar(128)COLLATEutf8mb4_unicode_ciDEFAULT'',
PRIMARYKEY(`applyId`)USINGBTREE,
KEY`index2`(`custId`,`createTime`)
)ENGINE=InnoDBAUTO_INCREMENT=1567035DEFAULTCHARSET=utf8mb4COLLATE=utf8mb4_unicode_ci
sync.`credit_creditchannel`表
mysql>showindexfromsync.`credit_creditchannel`;
+----------------------+------------+-----------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
|Table|Non_unique|Key_name|Seq_in_index|Column_name|Collation|Cardinality|Sub_part|Packed|Null|Index_type|Comment|Index_comment|
+----------------------+------------+-----------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
|credit_creditchannel|0|PRIMARY|1|recId|A|450671|NULL|NULL||BTREE|||
|credit_creditchannel|1|nationalId_custid|1|nationalId|A|450770|NULL|NULL||BTREE|||
|credit_creditchannel|1|nationalId_custid|2|custId|A|450770|NULL|NULL|YES|BTREE|||
|credit_creditchannel|1|credit_creditchannel_custId|1|custId|A|450770|10|NULL|YES|BTREE|||
+----------------------+------------+-----------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
或者
CREATETABLE`credit_creditchannel`(
`recId`bigint(20)NOTNULLAUTO_INCREMENT,
`nationalId`varchar(128)NOTNULLDEFAULT'',
`identityType`varchar(3)NOTNULLDEFAULT'',
`brief`mediumtext,
`score`decimal(10,4)NOTNULLDEFAULT'0.0000',
`npaCode`varchar(128)NOTNULLDEFAULT'',
`basic`mediumtext,
`createTime`timestampNOTNULLDEFAULTCURRENT_TIMESTAMP,
`updateTime`timestampNOTNULLDEFAULTCURRENT_TIMESTAMPONUPDATECURRENT_TIMESTAMP,
`request`mediumtext,
`custId`varchar(128)DEFAULT'',
`xcreditScore`decimal(10,4)DEFAULT'0.0000',
`queryTime`varchar(24)DEFAULT'',
`lrScore`decimal(10,4)DEFAULT'0.0000',
PRIMARYKEY(`recId`)USINGBTREE,
KEY`nationalId_custid`(`nationalId`,`custId`),
KEY`credit_creditchannel_custId`(`custId`(10))
)ENGINE=InnoDBAUTO_INCREMENT=586557DEFAULTCHARSET=utf8
我們都可以看到相應(yīng)的索引。以現(xiàn)在簡單的sql邏輯理論上走custid這個(gè)索引就好了
解釋函數(shù)explain
mysql>explainSELECTa.custid,b.score,b.xcreditscore,b.lrscoreFROM(
SELECTDISTINCTcustidFROMsync.`credit_apply`WHERESUBSTR(createtime,1,10)>='2019-12-15'ANDrejectrule='xxx')a
LEFTJOIN
(select*fromsync.`credit_creditchannel`)b
ONa.custid=b.custid;
+----+-------------+----------------------+------------+-------+---------------+--------+---------+------+---------+----------+----------------------------------------------------+
|id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows|filtered|Extra|
+----+-------------+----------------------+------------+-------+---------------+--------+---------+------+---------+----------+----------------------------------------------------+
|1|PRIMARY||NULL|ALL|NULL|NULL|NULL|NULL|158107|100.00|NULL|
|1|PRIMARY|credit_creditchannel|NULL|ALL|NULL|NULL|NULL|NULL|450770|100.00|Usingwhere;Usingjoinbuffer(BlockNestedLoop)|
|2|DERIVED|credit_apply|NULL|index|index2|index2|518|NULL|1581075|10.00|Usingwhere|
+----+-------------+----------------------+------------+-------+---------------+--------+---------+------+---------+----------+----------------------------------------------------+
3rowsinset(0.06sec)
如何去看我們的SQL是否走索引?我們只需要注意一個(gè)最重要的type 的信息很明顯的提現(xiàn)是否用到索引:
type結(jié)果type結(jié)果值從好到壞依次是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL一般來說,得保證查詢至少達(dá)到range級(jí)別,最好能達(dá)到ref,否則就可能會(huì)出現(xiàn)性能問題。possible_keys:sql所用到的索引key:顯示MySQL實(shí)際決定使用的鍵(索引)。如果沒有選擇索引,鍵是NULLrows: 顯示MySQL認(rèn)為它執(zhí)行查詢時(shí)必須檢查的行數(shù)。
分析:我們的credit_creditchannel是ALL,而possible_keys是NULL索引在查詢?cè)摫淼臅r(shí)候并沒有用到索引怪不得這么慢!!!!!!!!!
分析和搜索解決辦法
換著法的改sql也沒用;換著群問大神也沒用;各種搜索引擎搜才總算有點(diǎn)思路。**索引用不上的原因可能是字符集和排序規(guī)則不相同。于是看了了兩張表的字符集和兩張表這個(gè)字段的字符集以及排序規(guī)則:
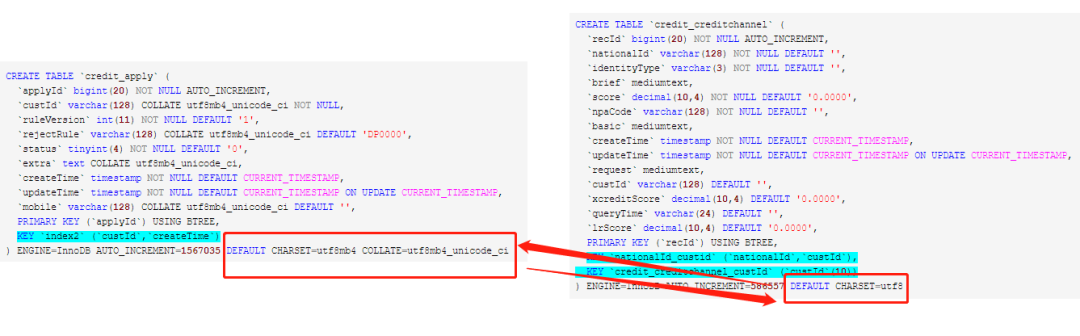
**修改數(shù)據(jù)庫和表的字符集
alterdatabasesyncdefaultcharactersetutf8mb4;//修改數(shù)據(jù)庫的字符集
altertablesync.credit_creditchanneldefaultcharactersetutf8mb4;//修改表的字符集
****修改表排序規(guī)則
altertablesync.`credit_creditchannel`converttocharactersetutf8mb4COLLATEutf8mb4_unicode_ci;
由于數(shù)據(jù)庫中的數(shù)據(jù)表和表字段的字符集和排序規(guī)則不統(tǒng)一,批量修改腳本如下:1. 修改指定數(shù)據(jù)庫中所有varchar類型的表字段的字符集為ut8mb4,并將排序規(guī)則修改為utf8_unicode_ci
SELECTCONCAT('ALTERTABLE`',table_name,'`MODIFY`',column_name,'`',DATA_TYPE,'(',CHARACTER_MAXIMUM_LENGTH,')CHARACTERSETutf8mb4COLLATEutf8mb4_unicode_ci',CASE
WHENIS_NULLABLE='NO'THEN'NOTNULL'
ELSE''
END,';')
FROMinformation_schema.COLUMNS
WHERE(TABLE_SCHEMA='databaseName'
ANDDATA_TYPE='varchar'
AND(CHARACTER_SET_NAME!='utf8mb4'
ORCOLLATION_NAME!='utf8mb4_unicode_ci'));
**2.修改指定數(shù)據(jù)庫中所有數(shù)據(jù)表的字符集為UTF8,并將排序規(guī)則修改為utf8_general_ci**
SELECTCONCAT('ALTERTABLE',table_name,'CONVERTTOCHARACTERSETutf8mb4COLLATEutf8mb4_unicode_ci;')
FROMinformation_schema.TABLES
WHERETABLE_SCHEMA='sync_rs'
explain 查看是否用到了索引
mysql>explainSELECTa.custid,b.score,b.xcreditscore,b.lrscoreFROM(
SELECTDISTINCTcustidFROMsync.`credit_apply`WHERESUBSTR(createtime,1,10)>='2019-12-15'ANDrejectrule='xxx')a
LEFTJOIN
(select*fromsync.`credit_creditchannel`)b
ONa.custid=b.custid;
+----+-------------+----------------------+------------+-------+-----------------------------+-----------------------------+---------+----------+---------+----------+-------------+
|id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows|filtered|Extra|
+----+-------------+----------------------+------------+-------+-----------------------------+-----------------------------+---------+----------+---------+----------+-------------+
|1|PRIMARY||NULL|ALL|NULL|NULL|NULL|NULL|146864|100.00|NULL|
|1|PRIMARY|credit_creditchannel|NULL|ref|credit_creditchannel_custId|credit_creditchannel_custId|43|a.custid|1|100.00|Usingwhere|
|2|DERIVED|credit_apply|NULL|index|index2|index2|518|NULL|1468644|10.00|Usingwhere|
+----+-------------+----------------------+------------+-------+-----------------------------+-----------------------------+---------+----------+---------+----------+-------------+
就是這樣!!!!
補(bǔ)充大全:
可以看到結(jié)果中包含10列信息,分別為
id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra
對(duì)應(yīng)的簡單描述如下:
-
id: select查詢的序列號(hào),包含一組數(shù)字,表示查詢中執(zhí)行select子句或操作表的順序===id如果相同,可以認(rèn)為是一組,從上往下順序執(zhí)行;在所有組中,id值越大,優(yōu)先級(jí)越高,越先執(zhí)行
-
select_type: 表示查詢的類型。用于區(qū)別普通查詢、聯(lián)合查詢、子查詢等的復(fù)雜查詢。
-
table: 輸出結(jié)果集的表 顯示這一步所訪問數(shù)據(jù)庫中表名稱(顯示這一行的數(shù)據(jù)是關(guān)于哪張表的),有時(shí)不是真實(shí)的表名字,可能是簡稱,例如上面的e,d,也可能是第幾步執(zhí)行的結(jié)果的簡稱
-
partitions:匹配的分區(qū)
-
type:對(duì)表訪問方式,表示MySQL在表中找到所需行的方式,又稱“訪問類型”。
-
possible_keys:表示查詢時(shí),可能使用的索引
-
key:表示實(shí)際使用的索引
-
key_len:索引字段的長度
-
ref:列與索引的比較
-
rows:掃描出的行數(shù)(估算的行數(shù))
-
filtered:按表?xiàng)l件過濾的行百分比
-
Extra:執(zhí)行情況的描述和說明
挑選一些重要信息詳細(xì)說明:
-
select_type
-
SIMPLE 簡單的select查詢,查詢中不包含子查詢或者UNION
-
PRIMARY 查詢中若包含任何復(fù)雜的子部分,最外層查詢則被標(biāo)記為PRIMARY
-
SUBQUERY 在SELECT或WHERE列表中包含了子查詢
-
DERIVED 在FROM列表中包含的子查詢被標(biāo)記為DERIVED(衍生),MySQL會(huì)遞歸執(zhí)行這些子查詢,把結(jié)果放在臨時(shí)表中
-
UNION 若第二個(gè)SELECT出現(xiàn)在UNION之后,則被標(biāo)記為UNION:若UNION包含在FROM子句的子查詢中,外層SELECT將被標(biāo)記為:DERIVED
-
UNION RESULT 從UNION表獲取結(jié)果的SELECT
-
-
type
-
mysql找到數(shù)據(jù)行的方式,效率排名
-
NULL > system > const > eq_ref > ref > range > index > all
-
***一般來說,得保證查詢至少達(dá)到range級(jí)別,最好能達(dá)到ref。
-
system 表只有一行記錄(等于系統(tǒng)表),這是const類型的特列,平時(shí)不會(huì)出現(xiàn),這個(gè)也可以忽略不計(jì)
-
const 通過索引一次就找到了,const用于比較primary key 和 unique key,因?yàn)橹黄ヅ湟恍袛?shù)據(jù),所以很快。如果將主鍵置于where列表中,mysql就能將該查詢轉(zhuǎn)換為一個(gè)常量
-
eq_ref 唯一性索引掃描,對(duì)于每個(gè)索引鍵,表中只有一條記錄與之匹配。常見于主鍵索引和唯一索引 區(qū)別于const eq_ref用于聯(lián)表查詢的情況
-
ref 非唯一索引掃描,返回匹配某個(gè)單獨(dú)值的所有行,本質(zhì)上也是一種索引訪問,它返回所有匹配某個(gè)單獨(dú)值的行,然而,他可能會(huì)找到多個(gè)符合條件的行,所以他應(yīng)該屬于查找和掃描的混合體
-
range 只檢索給定范圍的行,使用一個(gè)索引來選擇行,一般是在where中出現(xiàn)between、<、>、in等查詢,范圍掃描好于全表掃描,因?yàn)樗恍枰_始于索引的某一點(diǎn),而結(jié)束于另一點(diǎn),不用掃描全部索引
-
index Full Index Scan,Index與All區(qū)別為index類型只遍歷索引樹。通常比All快,因?yàn)樗饕募ǔ1葦?shù)據(jù)文件小。也就是說,雖然all和index都是讀全表,但是index是從索引中讀取的,而all是從硬盤讀取的
-
ALL Full Table Scan,將遍歷全表以找到匹配的行
- possible_keys
指出mysql能使用哪個(gè)索引在表中找到記錄,查詢涉及到的字段若存在索引,則該索引被列出,但不一定被查詢使用(該查詢可以利用的索引,如果沒有任何索引顯示null)
實(shí)際使用的索引,如果為NULL,則沒有使用索引。(可能原因包括沒有建立索引或索引失效)
查詢中若使用了覆蓋索引(select 后要查詢的字段剛好和創(chuàng)建的索引字段完全相同),則該索引僅出現(xiàn)在key列表中 possible_keys為null
- key
key列顯示mysql實(shí)際決定使用的索引,必然包含在possible_keys中。如果沒有選擇索引,鍵是NULL。想要強(qiáng)制使用或者忽視possible_keys列中的索引,在查詢時(shí)指定FORCE INDEX、USE INDEX或者IGNORE index
- key_len
表示索引中使用的字節(jié)數(shù),可通過該列計(jì)算查詢中使用的索引的長度,在不損失精確性的情況下,長度越短越好。key_len顯示的值為索引字段的最大可能長度,并非實(shí)際使用長度,即key_len是根據(jù)表定義計(jì)算而得,不是通過表內(nèi)檢索出的。
- ref
顯示索引的那一列被使用了,如果可能的話,最好是一個(gè)常數(shù)。哪些列或常量被用于查找索引列上的值。
- rows
根據(jù)表統(tǒng)計(jì)信息及索引選用情況,大致估算出找到所需的記錄所需要讀取的行數(shù),也就是說,用的越少越好
- extra
包含不適合在其他列中顯式但十分重要的額外信息
-
Using Index:表示相應(yīng)的select操作中使用了覆蓋索引(Covering Index),避免訪問了表的數(shù)據(jù)行,效率不錯(cuò)。如果同時(shí)出現(xiàn)using where,表明索引被用來執(zhí)行索引鍵值的查找;如果沒有同時(shí)出現(xiàn)using where,表明索引用來讀取數(shù)據(jù)而非執(zhí)行查找動(dòng)作。
-
Using where:不用讀取表中所有信息,僅通過索引就可以獲取所需數(shù)據(jù),這發(fā)生在對(duì)表的全部的請(qǐng)求列都是同一個(gè)索引的部分的時(shí)候,表示mysql服務(wù)器將在存儲(chǔ)引擎檢索行后再進(jìn)行過濾
-
Using temporary:表示MySQL需要使用臨時(shí)表來存儲(chǔ)結(jié)果集,常見于排序和分組查詢,常見 group by ; order by
-
Using filesort:當(dāng)Query中包含 order by 操作,而且無法利用索引完成的排序操作稱為“文件排序”
-
Using join buffer:表明使用了連接緩存,比如說在查詢的時(shí)候,多表join的次數(shù)非常多,那么將配置文件中的緩沖區(qū)的join buffer調(diào)大一些。
-
Impossible where:where子句的值總是false,不能用來獲取任何元組
-
Select tables optimized away:這個(gè)值意味著僅通過使用索引,優(yōu)化器可能僅從聚合函數(shù)結(jié)果中返回一行
-
No tables used:Query語句中使用from dual 或不含任何from子句
以上兩種信息表示mysql無法使用索引
-
using filesort :表示mysql會(huì)對(duì)結(jié)果使用一個(gè)外部索引排序,而不是從表里按索引次序讀到相關(guān)內(nèi)容,可能在內(nèi)存或磁盤上排序。mysql中無法利用索引完成的操作稱為文件排序
-
using temporary: 使用了用臨時(shí)表保存中間結(jié)果,MySQL在對(duì)查詢結(jié)果排序時(shí)使用臨時(shí)表。常見于排序order by和分組查詢group by。
責(zé)任編輯:xj
原文標(biāo)題:如何查看 sql 查詢是否用到索引 ( mysql )
文章出處:【微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
SQL
+關(guān)注
關(guān)注
1文章
759瀏覽量
44069 -
MySQL
+關(guān)注
關(guān)注
1文章
801瀏覽量
26441 -
索引
+關(guān)注
關(guān)注
0文章
59瀏覽量
10462
原文標(biāo)題:如何查看 sql 查詢是否用到索引 ( mysql )
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
SQL與NoSQL的區(qū)別
MATLAB中的矩陣索引
IP 地址在 SQL 注入攻擊中的作用及防范策略
一文了解MySQL索引機(jī)制

什么是 Flink SQL 解決不了的問題?
SQL全外連接剖析
手動(dòng)檢測是否被入侵
如何用Rust過程宏魔法簡化SQL函數(shù)呢?
SQL對(duì)象名無效的解決方法
導(dǎo)致MySQL索引失效的情況以及相應(yīng)的解決方法
Mysql索引是什么東西?索引有哪些特性?索引是如何工作的?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論