") MySQL的基本知識(shí)點(diǎn)梳理和常用操作總結(jié)
MySQL的基本知識(shí)點(diǎn)梳理和常用操作總結(jié)
本文主要是總結(jié)了工作中一些常用的操作,以及不合理的操作,在對(duì)慢查詢(xún)進(jìn)行優(yōu)化時(shí)收集的一些有用的資料和信息,本文適合有mysql基礎(chǔ)的開(kāi)發(fā)人員。
一、索引相關(guān)
1、索引基數(shù):基數(shù)是數(shù)據(jù)列所包含的不同值的數(shù)量。例如,某個(gè)數(shù)據(jù)列包含值1、3、7、4、7、3,那么它的基數(shù)就是4。索引的基數(shù)相對(duì)于數(shù)據(jù)表行數(shù)較高(也就是說(shuō),列中包含很多不同的值,重復(fù)的值很少)的時(shí)候,它的工作效果最好。如果某數(shù)據(jù)列含有很多不同的年齡,索引會(huì)很快地分辨數(shù)據(jù)行。如果某個(gè)數(shù)據(jù)列用于記錄性別(只有“M”和“F”兩種值),那么索引的用處就不大。如果值出現(xiàn)的幾率幾乎相等,那么無(wú)論搜索哪個(gè)值都可能得到一半的數(shù)據(jù)行。在這些情況下,最好根本不要使用索引,因?yàn)椴樵?xún)優(yōu)化器發(fā)現(xiàn)某個(gè)值出現(xiàn)在表的數(shù)據(jù)行中的百分比很高的時(shí)候,它一般會(huì)忽略索引,進(jìn)行全表掃描。慣用的百分比界線(xiàn)是“30%”。
2、索引失效原因:
1、對(duì)索引列運(yùn)算,運(yùn)算包括(+、-、*、/、!、《》、%、like‘%_’(%放在前面)
2、類(lèi)型錯(cuò)誤,如字段類(lèi)型為varchar,where條件用number。
3、對(duì)索引應(yīng)用內(nèi)部函數(shù),這種情況下應(yīng)該建立基于函數(shù)的索引
如select * from template t where ROUND(t.logicdb_id) = 1
此時(shí)應(yīng)該建ROUND(t.logicdb_id)為索引,mysql8.0開(kāi)始支持函數(shù)索引,5.7可以通過(guò)虛擬列的方式來(lái)支持,之前只能新建一個(gè)ROUND(t.logicdb_id)列然后去維護(hù)
4、如果條件有or,即使其中有條件帶索引也不會(huì)使用(這也是為什么建議少使用or的原因),如果想使用or,又想索引有效,只能將or條件中的每個(gè)列加上索引
5、如果列類(lèi)型是字符串,那一定要在條件中數(shù)據(jù)使用引號(hào),否則不使用索引;
6、B-tree索引 is null不會(huì)走,is not null會(huì)走,位圖索引 is null,is not null 都會(huì)走
7、組合索引遵循最左原則
索引的建立
1、最重要的肯定是根據(jù)業(yè)務(wù)經(jīng)常查詢(xún)的語(yǔ)句
2、盡量選擇區(qū)分度高的列作為索引,區(qū)分度的公式是 COUNT(DISTINCT col) / COUNT(*)。表示字段不重復(fù)的比率,比率越大我們掃描的記錄數(shù)就越少
3、如果業(yè)務(wù)中唯一特性最好建立唯一鍵,一方面可以保證數(shù)據(jù)的正確性,另一方面索引的效率能大大提高
二、EXPLIAN中有用的信息
基本用法
1、desc 或者 explain 加上你的sql
2、extended explain加上你的sql,然后通過(guò)show warnings可以查看實(shí)際執(zhí)行的語(yǔ)句,這一點(diǎn)也是非常有用的,很多時(shí)候不同的寫(xiě)法經(jīng)過(guò)sql分析之后實(shí)際執(zhí)行的代碼是一樣的
提高性能的特性
1、索引覆蓋(covering index):需要查詢(xún)的數(shù)據(jù)在索引上都可以查到不需要回表 EXTRA列顯示using index
2、ICP特性(Index Condition Pushdown):本來(lái)index僅僅是data access的一種訪(fǎng)問(wèn)模式,存數(shù)引擎通過(guò)索引回表獲取的數(shù)據(jù)會(huì)傳遞到MySQL server層進(jìn)行where條件過(guò)濾,5.6版本開(kāi)始當(dāng)ICP打開(kāi)時(shí),如果部分where條件能使用索引的字段,MySQL server會(huì)把這部分下推到引擎層,可以利用index過(guò)濾的where條件在存儲(chǔ)引擎層進(jìn)行數(shù)據(jù)過(guò)濾。EXTRA顯示using index condition。需要了解mysql的架構(gòu)圖分為server和存儲(chǔ)引擎層
3、索引合并(index merge):對(duì)多個(gè)索引分別進(jìn)行條件掃描,然后將它們各自的結(jié)果進(jìn)行合并(intersect/union)。一般用OR會(huì)用到,如果是AND條件,考慮建立復(fù)合索引。EXPLAIN顯示的索引類(lèi)型會(huì)顯示index_merge,EXTRA會(huì)顯示具體的合并算法和用到的索引
extra字段
1、using filesort: 說(shuō)明MySQL會(huì)對(duì)數(shù)據(jù)使用一個(gè)外部的索引排序,而不是按照表內(nèi)的索引順序進(jìn)行讀取。MySQL中無(wú)法利用索引完成的排序操作稱(chēng)為“文件排序” ,其實(shí)不一定是文件排序,內(nèi)部使用的是快排
2、using temporary: 使用了臨時(shí)表保存中間結(jié)果,MySQL在對(duì)查詢(xún)結(jié)果排序時(shí)使用臨時(shí)表。常見(jiàn)于排序order by和分組查詢(xún)group by
3、using index: 表示相應(yīng)的SELECT操作中使用了覆蓋索引(Covering Index),避免訪(fǎng)問(wèn)了表的數(shù)據(jù)行,效率不錯(cuò)。
4、impossible where: WHERE子句的值總是false,不能用來(lái)獲取任何元組
5、select tables optimized away: 在沒(méi)有GROUP BY子句的情況下基于索引優(yōu)化MIN/MAX操作或者對(duì)于MyISAM存儲(chǔ)引擎優(yōu)化COUNT(*)操作, 不必等到執(zhí)行階段再進(jìn)行計(jì)算,查詢(xún)執(zhí)行計(jì)劃生成的階段即完成優(yōu)化
6、distinct:優(yōu)化distinct操作,在找到第一匹配的元祖后即停止找同樣值的操作
using filesort,using temporary這兩項(xiàng)出現(xiàn)時(shí)需要注意下,這兩項(xiàng)是十分耗費(fèi)性能的,在使用group by的時(shí)候,雖然沒(méi)有使用order by,如果沒(méi)有索引,是可能同時(shí)出現(xiàn)using filesort,using temporary的,因?yàn)間roup by就是先排序在分組,如果沒(méi)有排序的需要,可以加上一個(gè)order by NULL來(lái)避免排序,這樣using filesort就會(huì)去除,能提升一點(diǎn)性能。
type字段
system:表只有一行記錄(等于系統(tǒng)表),這是const類(lèi)型的特例,平時(shí)不會(huì)出現(xiàn)
const:如果通過(guò)索引依次就找到了,const用于比較主鍵索引或者unique索引。因?yàn)橹荒芷ヅ湟恍袛?shù)據(jù),所以很快。如果將主鍵置于where列表中,MySQL就能將該查詢(xún)轉(zhuǎn)換為一個(gè)常量
eq_ref:唯一性索引掃描,對(duì)于每個(gè)索引鍵,表中只有一條記錄與之匹配。常見(jiàn)于主鍵或唯一索引掃描
ref:非唯一性索引掃描,返回匹配某個(gè)單獨(dú)值的所有行。本質(zhì)上也是一種索引訪(fǎng)問(wèn),它返回所有匹配 某個(gè)單獨(dú)值的行,然而它可能會(huì)找到多個(gè)符合條件的行,所以它應(yīng)該屬于查找和掃描的混合體
range:只檢索給定范圍的行,使用一個(gè)索引來(lái)選擇行。key列顯示使用了哪個(gè)索引,一般就是在你的where語(yǔ)句中出現(xiàn)between、《、》、in等的查詢(xún),這種范圍掃描索引比全表掃描要好,因?yàn)橹恍枰_(kāi)始于縮印的某一點(diǎn),而結(jié)束于另一點(diǎn),不用掃描全部索引
index:Full Index Scan ,index與ALL的區(qū)別為index類(lèi)型只遍歷索引樹(shù),這通常比ALL快,因?yàn)樗饕募ǔ1葦?shù)據(jù)文件小。(也就是說(shuō)雖然ALL和index都是讀全表, 但index是從索引中讀取的,而ALL是從硬盤(pán)讀取的)
all:Full Table Scan,遍歷全表獲得匹配的行
三、字段類(lèi)型和編碼
1、mysql返回字符串長(zhǎng)度:CHARACTER_LENGTH方法(CHAR_LENGTH一樣的)返回的是字符數(shù),LENGTH函數(shù)返回的是字節(jié)數(shù),一個(gè)漢字三個(gè)字節(jié)
2、varvhar等字段建立索引長(zhǎng)度計(jì)算語(yǔ)句:select count(distinct left(test,5))/count(*) from table; 越趨近1越好
3、mysql的utf8最大是3個(gè)字節(jié)不支持emoji表情符號(hào),必須只用utf8mb4。需要在mysql配置文件中配置客戶(hù)端字符集為utf8mb4。jdbc的連接串不支持配置characterEncoding=utf8mb4,最好的辦法是在連接池中指定初始化sql,例如:hikari連接池,其他連接池類(lèi)似spring.datasource.hikari.connection-init-sql=set names utf8mb4。否則需要每次執(zhí)行sql前都先執(zhí)行set names utf8mb4。
4、msyql排序規(guī)則(一般使用_bin和_genera_ci):
utf8_genera_ci不區(qū)分大小寫(xiě),ci為case insensitive的縮寫(xiě),即大小寫(xiě)不敏感,
utf8_general_cs區(qū)分大小寫(xiě),cs為case sensitive的縮寫(xiě),即大小寫(xiě)敏感,但是目前MySQL版本中已經(jīng)不支持類(lèi)似于***_genera_cs的排序規(guī)則,直接使用utf8_bin替代。
utf8_bin將字符串中的每一個(gè)字符用二進(jìn)制數(shù)據(jù)存儲(chǔ),區(qū)分大小寫(xiě)。
那么,同樣是區(qū)分大小寫(xiě),utf8_general_cs和utf8_bin有什么區(qū)別?
cs為case sensitive的縮寫(xiě),即大小寫(xiě)敏感;bin的意思是二進(jìn)制,也就是二進(jìn)制編碼比較。
utf8_general_cs排序規(guī)則下,即便是區(qū)分了大小寫(xiě),但是某些西歐的字符和拉丁字符是不區(qū)分的,比如?=a,但是有時(shí)并不需要?=a,所以才有utf8_bin
utf8_bin的特點(diǎn)在于使用字符的二進(jìn)制的編碼進(jìn)行運(yùn)算,任何不同的二進(jìn)制編碼都是不同的,因此在utf8_bin排序規(guī)則下:?《》a
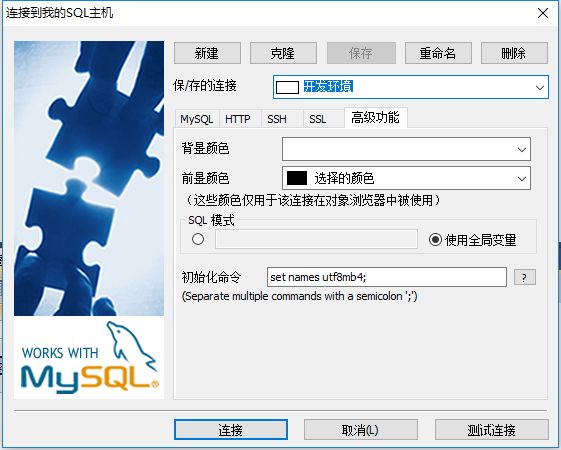
5、sql yog中初始連接指定編碼類(lèi)型使用連接配置的初始化命令
四、SQL語(yǔ)句總結(jié)
常用的但容易忘的:
1、如果有主鍵或者唯一鍵沖突則不插入:insert ignore into
2、如果有主鍵或者唯一鍵沖突則更新,注意這個(gè)會(huì)影響自增的增量:INSERT INTO room_remarks(room_id,room_remarks) VALUE(1,“sdf”) ON DUPLICATE KEY UPDATE room_remarks=“234”
3、如果有就用新的替代,values如果不包含自增列,自增列的值會(huì)變化:REPLACE INTO room_remarks(room_id,room_remarks) VALUE(1,“sdf”)
4、備份表:CREATE TABLE user_info SELECT * FROM user_info
5、復(fù)制表結(jié)構(gòu):CREATE TABLE user_v2 LIKE user
6、從查詢(xún)語(yǔ)句中導(dǎo)入:INSERT INTO user_v2 SELECT * FROM user或者INSERT INTO user_v2(id,num) SELECT id,num FROM user
7、連表更新:UPDATE user a, room b SET a.num=a.num+1 WHERE a.room_id=b.id
8、連表刪除:DELETE user FROM user,black WHERE user.id=black.id
鎖相關(guān)(作為了解,很少用)
1、共享鎖: select id from tb_test where id = 1 lock in share mode;
2、排它鎖: select id from tb_test where id = 1 for update
優(yōu)化時(shí)用到:
1、強(qiáng)制使用某個(gè)索引: select * from table force index(idx_user) limit 2;
2、禁止使用某個(gè)索引:select * from table ignore index(idx_user) limit 2;
3、禁用緩存(在測(cè)試時(shí)去除緩存的影響): select SQL_NO_CACHE from table limit 2;
查看狀態(tài)
1、查看字符集 SHOW VARIABLES LIKE ‘character_set%’;
2、查看排序規(guī)則 SHOW VARIABLES LIKE ‘collation%’;
SQL編寫(xiě)注意
1、where語(yǔ)句的解析順序是從右到左,條件盡量放where不要放having
2、采用延遲關(guān)聯(lián)(deferred join)技術(shù)優(yōu)化超多分頁(yè)場(chǎng)景,比如limit 10000,10,延遲關(guān)聯(lián)可以避免回表
3、distinct語(yǔ)句非常損耗性能,可以通過(guò)group by來(lái)優(yōu)化
4、連表盡量不要超過(guò)三個(gè)表
五、踩坑
1、如果有自增列,truncate語(yǔ)句會(huì)把自增列的基數(shù)重置為0,有些場(chǎng)景用自增列作為業(yè)務(wù)上的id需要十分重視
2、聚合函數(shù)會(huì)自動(dòng)濾空,比如a列的類(lèi)型是int且全部是NULL,則SUM(a)返回的是NULL而不是0
3、mysql判斷null相等不能用“a=null”,這個(gè)結(jié)果永遠(yuǎn)為UnKnown,where和having中,UnKnown永遠(yuǎn)被視為false,check約束中,UnKnown就會(huì)視為true來(lái)處理。所以要用“a is null”處理
六、千萬(wàn)大表在線(xiàn)修改
mysql在表數(shù)據(jù)量很大的時(shí)候,如果修改表結(jié)構(gòu)會(huì)導(dǎo)致鎖表,業(yè)務(wù)請(qǐng)求被阻塞。mysql在5.6之后引入了在線(xiàn)更新,但是在某些情況下還是會(huì)鎖表,所以一般都采用pt工具( Percona Toolkit)
如對(duì)表添加索引:
如下:
pt-online-schema-change --user=‘root’ --host=‘localhost’ --ask-pass --alter “add index idx_user_id(room_id,create_time)”
D=fission_show_room_v2,t=room_favorite_info --execute
七、慢查詢(xún)?nèi)罩?/p>
有時(shí)候如果線(xiàn)上請(qǐng)求超時(shí),應(yīng)該去關(guān)注下慢查詢(xún)?nèi)罩荆樵?xún)的分析很簡(jiǎn)單,先找到慢查詢(xún)?nèi)罩疚募奈恢茫缓罄胢ysqldumpslow去分析。查詢(xún)慢查詢(xún)?nèi)罩拘畔⒖梢灾苯油ㄟ^(guò)執(zhí)行sql命令查看相關(guān)變量,常用的sql如下:
-- 查看慢查詢(xún)配置
-- slow_query_log 慢查詢(xún)?nèi)罩臼欠耖_(kāi)啟
-- slow_query_log_file 的值是記錄的慢查詢(xún)?nèi)罩镜轿募?/p>
-- long_query_time 指定了慢查詢(xún)的閾值
-- log_queries_not_using_indexes 是否記錄所有沒(méi)有利用索引的查詢(xún)
SHOW VARIABLES LIKE ‘%quer%’;
-- 查看慢查詢(xún)是日志還是表的形式
SHOW VARIABLES LIKE ‘log_output’
-- 查看慢查詢(xún)的數(shù)量
mysqldumpslow的工具十分簡(jiǎn)單,我主要用到的是參數(shù)如下:
-t:限制輸出的行數(shù),我一般取前十條就夠了
-s:根據(jù)什么來(lái)排序默認(rèn)是平均查詢(xún)時(shí)間at,我還經(jīng)常用到c查詢(xún)次數(shù),因?yàn)椴樵?xún)次數(shù)很頻繁但是時(shí)間不高也是有必要優(yōu)化的,還有t查詢(xún)時(shí)間,查看那個(gè)語(yǔ)句特別卡。
-v:輸出詳細(xì)信息
例子:mysqldumpslow -v -s t -t 10 mysql_slow.log.2018-11-20-0500
八、查看sql進(jìn)程和殺死進(jìn)程
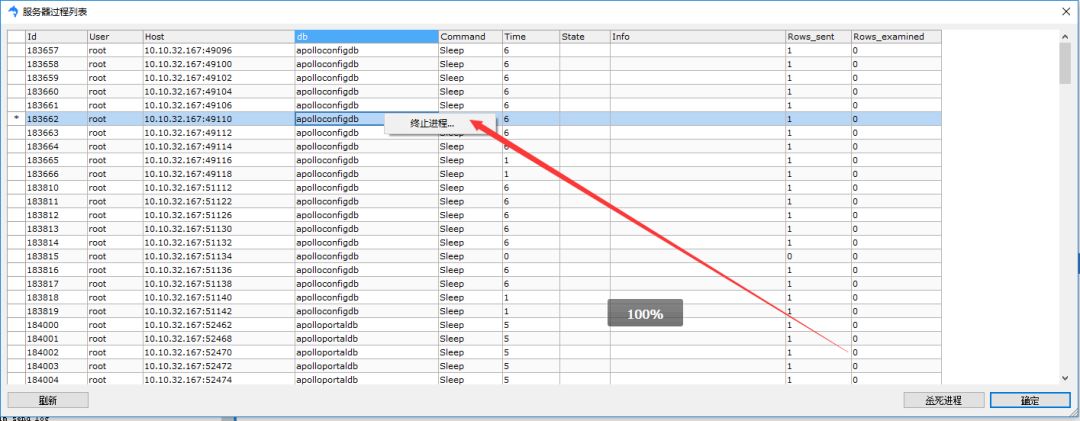
如果你執(zhí)行了一個(gè)sql的操作,但是遲遲沒(méi)有返回,你可以通過(guò)查詢(xún)進(jìn)程列表看看他的實(shí)際執(zhí)行狀況,如果該sql十分耗時(shí),為了避免影響線(xiàn)上可以用kill命令殺死進(jìn)程,通過(guò)查看進(jìn)程列表也能直觀的看下當(dāng)前sql的執(zhí)行狀態(tài),如果當(dāng)前數(shù)據(jù)庫(kù)負(fù)載很高,在進(jìn)程列表可能會(huì)出現(xiàn),大量的進(jìn)程夯住,執(zhí)行時(shí)間很長(zhǎng)。命令如下:
--查看進(jìn)程列表
SHOW PROCESSLIST;
--殺死某個(gè)進(jìn)程
kill 183665
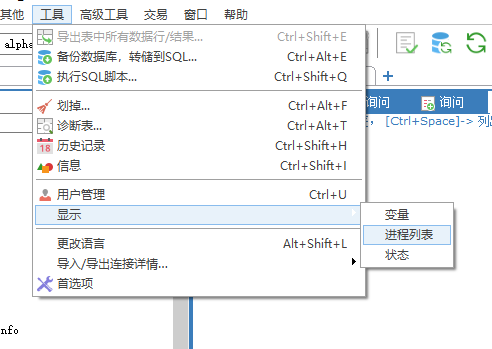
如果你使用的sqlyog,那么也有圖形化的頁(yè)面,在菜單欄-工具-顯示-進(jìn)程列表。在進(jìn)程列表頁(yè)面可以右鍵殺死進(jìn)程。如下所示:
九、一些數(shù)據(jù)庫(kù)性能的思考
在對(duì)公司慢查詢(xún)?nèi)罩咀鰞?yōu)化的時(shí)候,很多時(shí)候可能是忘了建索引,像這種問(wèn)題很容易解決,加個(gè)索引就行了。但是有兩種情況就不是簡(jiǎn)單能加索引能解決了:
1、業(yè)務(wù)代碼循環(huán)讀數(shù)據(jù)庫(kù): 考慮這樣一個(gè)場(chǎng)景,獲取用戶(hù)粉絲列表信息 加入分頁(yè)是十個(gè) 其實(shí)像這樣的sql是十分簡(jiǎn)單的,通過(guò)連表查詢(xún)性能也很高,但是有時(shí)候,很多開(kāi)發(fā)采用了取出一串id,然后循環(huán)讀每個(gè)id的信息,這樣如果id很多對(duì)數(shù)據(jù)庫(kù)的壓力是很大的,而且性能也很低
2、統(tǒng)計(jì)sql:很多時(shí)候,業(yè)務(wù)上都會(huì)有排行榜這種,發(fā)現(xiàn)公司有很多地方直接采用數(shù)據(jù)庫(kù)做計(jì)算,在對(duì)一些大表的做聚合運(yùn)算的時(shí)候,經(jīng)常超過(guò)五秒,這些sql一般很長(zhǎng)而且很難優(yōu)化, 像這種場(chǎng)景,如果業(yè)務(wù)允許(比如一致性要求不高或者是隔一段時(shí)間才統(tǒng)計(jì)的),可以專(zhuān)門(mén)在從庫(kù)里面做統(tǒng)計(jì)。另外我建議還是采用redis緩存來(lái)處理這種業(yè)務(wù)
3、超大分頁(yè):在慢查詢(xún)?nèi)罩局邪l(fā)現(xiàn)了一些超大分頁(yè)的慢查詢(xún)?nèi)鏻imit 40000,1000,因?yàn)閙ysql的分頁(yè)是在server層做的,可以采用延遲關(guān)聯(lián)在減少回表。但是看了相關(guān)的業(yè)務(wù)代碼正常的業(yè)務(wù)邏輯是不會(huì)出現(xiàn)這樣的請(qǐng)求的,所以很有可能是有惡意用戶(hù)在刷接口,所以最好在開(kāi)發(fā)的時(shí)候也對(duì)接口加上校驗(yàn)攔截這些惡意請(qǐng)求。
這篇文章就總結(jié)到這里,希望能夠?qū)δ阌兴鶐椭?/p>
原文標(biāo)題:MySQL 基本知識(shí)點(diǎn)梳理和查詢(xún)優(yōu)化
文章出處:【微信公眾號(hào):數(shù)據(jù)分析與開(kāi)發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3765瀏覽量
64276 -
MySQL
+關(guān)注
關(guān)注
1文章
802瀏覽量
26444
原文標(biāo)題:MySQL 基本知識(shí)點(diǎn)梳理和查詢(xún)優(yōu)化
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開(kāi)發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
接口測(cè)試?yán)碚摗⒁蓡?wèn)收錄與擴(kuò)展相關(guān)知識(shí)點(diǎn)
堆棧和內(nèi)存的基本知識(shí)
MySQL知識(shí)點(diǎn)匯總

模擬電子技術(shù)知識(shí)點(diǎn)問(wèn)題總結(jié)概覽

基于FPGA的常見(jiàn)的圖像算法模塊總結(jié)

汽車(chē)MCU芯片知識(shí)點(diǎn)梳理

一篇搞定DCS系統(tǒng)相關(guān)知識(shí)點(diǎn)
【量子計(jì)算機(jī)重構(gòu)未來(lái) | 閱讀體驗(yàn)】第二章關(guān)鍵知識(shí)點(diǎn)
淺談初級(jí)電工必備知識(shí)點(diǎn)

TCP協(xié)議面試常問(wèn)知識(shí)點(diǎn)總結(jié)
SQL核心知識(shí)點(diǎn)總結(jié)
開(kāi)關(guān)模式下的電源電流如何檢測(cè)?這12個(gè)電路&10個(gè)知識(shí)點(diǎn)講明白了





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論