 Redis是什么
Redis是什么
今天,“我”不自量力的面試了某大廠的 Java 開發崗位,迎面走來一位風塵仆仆的中年男子,手里拿著屏幕還亮著的 Mac。他沖著我禮貌的笑了笑,然后說了句“不好意思,讓你久等了”,然后示意我坐下,說:“我們開始吧,看了你的簡歷,覺得你對 Redis 應該掌握的不錯,我們今天就來討論下 Redis……”。我想:“來就來,兵來將擋水來土掩”。
Redis 是什么
面試官:你先來說下 Redis 是什么吧!
我:(這不就是總結下 Redis 的定義和特點嘛)Redis 是 C 語言開發的一個開源的(遵從 BSD 協議)高性能鍵值對(key-value)的內存數據庫,可以用作數據庫、緩存、消息中間件等。
它是一種 NoSQL(not-only sql,泛指非關系型數據庫)的數據庫。
我頓了一下,接著說,Redis 作為一個內存數據庫:
性能優秀,數據在內存中,讀寫速度非常快,支持并發 10W QPS。
單進程單線程,是線程安全的,采用 IO 多路復用機制。
豐富的數據類型,支持字符串(strings)、散列(hashes)、列表(lists)、集合(sets)、有序集合(sorted sets)等。
支持數據持久化。
可以將內存中數據保存在磁盤中,重啟時加載。
主從復制,哨兵,高可用。
可以用作分布式鎖。
可以作為消息中間件使用,支持發布訂閱。
五種數據類型
面試官:總結的不錯,看來是早有準備啊。剛來聽你提到 Redis 支持五種數據類型,那你能簡單說下這五種數據類型嗎?
我:當然可以,但是在說之前,我覺得有必要先來了解下 Redis 內部內存管理是如何描述這 5 種數據類型的。
說著,我拿著筆給面試官畫了一張圖:
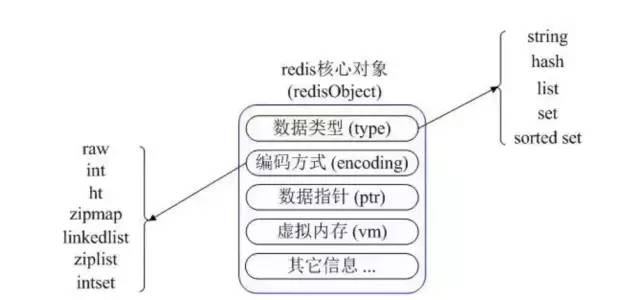
我:首先 Redis 內部使用一個 redisObject 對象來表示所有的 key 和 value。 redisObject 最主要的信息如上圖所示:type 表示一個 value 對象具體是何種數據類型,encoding 是不同數據類型在 Redis 內部的存儲方式。 比如:type=string 表示 value 存儲的是一個普通字符串,那么 encoding 可以是 raw 或者 int。
我頓了一下,接著說,下面我簡單說下 5 種數據類型:
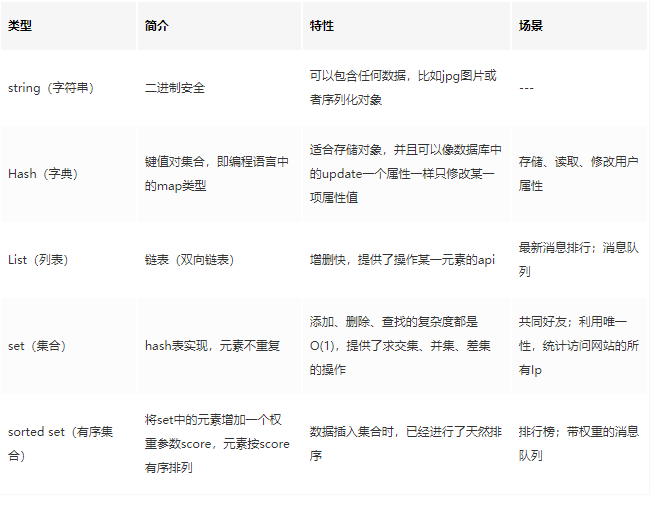
①String 是 Redis 最基本的類型,可以理解成與 Memcached一模一樣的類型,一個 Key 對應一個 Value。Value 不僅是 String,也可以是數字。
String 類型是二進制安全的,意思是 Redis 的 String 類型可以包含任何數據,比如 jpg 圖片或者序列化的對象。String 類型的值最大能存儲 512M。
②Hash是一個鍵值(key-value)的集合。Redis 的 Hash 是一個 String 的 Key 和 Value 的映射表,Hash 特別適合存儲對象。常用命令:hget,hset,hgetall 等。
③List 列表是簡單的字符串列表,按照插入順序排序。可以添加一個元素到列表的頭部(左邊)或者尾部(右邊) 常用命令:lpush、rpush、lpop、rpop、lrange(獲取列表片段)等。 應用場景:List 應用場景非常多,也是 Redis 最重要的數據結構之一,比如 Twitter 的關注列表,粉絲列表都可以用 List 結構來實現。
數據結構:List 就是鏈表,可以用來當消息隊列用。Redis 提供了 List 的 Push 和 Pop 操作,還提供了操作某一段的 API,可以直接查詢或者刪除某一段的元素。
實現方式:Redis List 的是實現是一個雙向鏈表,既可以支持反向查找和遍歷,更方便操作,不過帶來了額外的內存開銷。 ④Set 是 String 類型的無序集合。集合是通過 hashtable 實現的。Set 中的元素是沒有順序的,而且是沒有重復的。常用命令:sdd、spop、smembers、sunion 等。
應用場景:Redis Set 對外提供的功能和 List 一樣是一個列表,特殊之處在于 Set 是自動去重的,而且 Set 提供了判斷某個成員是否在一個 Set 集合中。
⑤Zset 和 Set 一樣是 String 類型元素的集合,且不允許重復的元素。常用命令:zadd、zrange、zrem、zcard 等。
使用場景:Sorted Set 可以通過用戶額外提供一個優先級(score)的參數來為成員排序,并且是插入有序的,即自動排序。
當你需要一個有序的并且不重復的集合列表,那么可以選擇 Sorted Set 結構。
和 Set 相比,Sorted Set關聯了一個 Double 類型權重的參數 Score,使得集合中的元素能夠按照 Score 進行有序排列,Redis 正是通過分數來為集合中的成員進行從小到大的排序。
實現方式:Redis Sorted Set 的內部使用 HashMap 和跳躍表(skipList)來保證數據的存儲和有序,HashMap 里放的是成員到 Score 的映射。
而跳躍表里存放的是所有的成員,排序依據是 HashMap 里存的 Score,使用跳躍表的結構可以獲得比較高的查找效率,并且在實現上比較簡單。
數據類型應用場景總結:
面試官:想不到你平時也下了不少工夫,那 Redis 緩存你一定用過的吧? 我:用過的。
面試官:那你跟我說下你是怎么用的?
我是結合 Spring Boot 使用的。一般有兩種方式,一種是直接通過 RedisTemplate 來使用,另一種是使用 Spring Cache 集成 Redis(也就是注解的方式)。
Redis 緩存
直接通過 RedisTemplate 來使用,使用 Spring Cache 集成 Redis pom.xml 中加入以下依賴:
spring-boot-starter-data-redis:在 Spring Boot 2.x 以后底層不再使用 Jedis,而是換成了 Lettuce。
commons-pool2:用作 Redis 連接池,如不引入啟動會報錯。
spring-session-data-redis:Spring Session 引入,用作共享 Session。
配置文件 application.yml 的配置:
server: port:8082 servlet: session: timeout:30ms spring: cache: type:redis redis: host:127.0.0.1 port:6379 password: #redis默認情況下有16個分片,這里配置具體使用的分片,默認為0 database:0 lettuce: pool: #連接池最大連接數(使用負數表示沒有限制),默認8 max-active:100
創建實體類 User.java:
publicclassUserimplementsSerializable{ privatestaticfinallongserialVersionUID=662692455422902539L; privateIntegerid; privateStringname; privateIntegerage; publicUser(){ } publicUser(Integerid,Stringname,Integerage){ this.id=id; this.name=name; this.age=age; } publicIntegergetId(){ returnid; } publicvoidsetId(Integerid){ this.id=id; } publicStringgetName(){ returnname; } publicvoidsetName(Stringname){ this.name=name; } publicIntegergetAge(){ returnage; } publicvoidsetAge(Integerage){ this.age=age; } @Override publicStringtoString(){ return"User{"+ "id="+id+ ",name='"+name+'''+ ",age="+age+ '}'; } }
RedisTemplate 的使用方式
默認情況下的模板只能支持 RedisTemplate
添加配置類 RedisCacheConfig.java:
@Configuration @AutoConfigureAfter(RedisAutoConfiguration.class) publicclassRedisCacheConfig{ @Bean publicRedisTemplate
測試類:
@RestController @RequestMapping("/user") publicclassUserController{ publicstaticLoggerlogger=LogManager.getLogger(UserController.class); @Autowired privateStringRedisTemplatestringRedisTemplate; @Autowired privateRedisTemplate
然后在瀏覽器訪問,觀察后臺日志 http://localhost:8082/user/test

使用 Spring Cache 集成 Redis
Spring Cache 具備很好的靈活性,不僅能夠使用 SPEL(spring expression language)來定義緩存的 Key 和各種 Condition,還提供了開箱即用的緩存臨時存儲方案,也支持和主流的專業緩存如 EhCache、Redis、Guava 的集成。 定義接口 UserService.java:
publicinterfaceUserService{ Usersave(Useruser); voiddelete(intid); Userget(Integerid); }
接口實現類 UserServiceImpl.java:
@Service publicclassUserServiceImplimplementsUserService{ publicstaticLoggerlogger=LogManager.getLogger(UserServiceImpl.class); privatestaticMap
為了方便演示數據庫的操作,這里直接定義了一個 Map
@Cachable
@CachePut
@CacheEvict
測試類:UserController
@RestController @RequestMapping("/user") publicclassUserController{ publicstaticLoggerlogger=LogManager.getLogger(UserController.class); @Autowired privateStringRedisTemplatestringRedisTemplate; @Autowired privateRedisTemplate
用緩存要注意,啟動類要加上一個注解開啟緩存:
@SpringBootApplication(exclude=DataSourceAutoConfiguration.class) @EnableCaching publicclassApplication{ publicstaticvoidmain(String[]args){ SpringApplication.run(Application.class,args); } }
①先調用添加接口:http://localhost:8082/user/add

②再調用查詢接口,查詢 id=4 的用戶信息:

可以看出,這里已經從緩存中獲取數據了,因為上一步 add 方法已經把 id=4 的用戶數據放入了 Redis 緩存 3、調用刪除方法,刪除 id=4 的用戶信息,同時清除緩存:

④再次調用查詢接口,查詢 id=4 的用戶信息:

沒有了緩存,所以進入了 get 方法,從 userMap 中獲取。
緩存注解
①@Cacheable
根據方法的請求參數對其結果進行緩存:
Key:緩存的 Key,可以為空,如果指定要按照 SPEL 表達式編寫,如果不指定,則按照方法的所有參數進行組合。
Value:緩存的名稱,必須指定至少一個(如 @Cacheable (value='user')或者 @Cacheable(value={'user1','user2'}))
Condition:緩存的條件,可以為空,使用 SPEL 編寫,返回 true 或者 false,只有為 true 才進行緩存。
②@CachePut
根據方法的請求參數對其結果進行緩存,和 @Cacheable 不同的是,它每次都會觸發真實方法的調用。參數描述見上。
③@CacheEvict
根據條件對緩存進行清空:
Key:同上。
Value:同上。
Condition:同上。
allEntries:是否清空所有緩存內容,缺省為 false,如果指定為 true,則方法調用后將立即清空所有緩存。
beforeInvocation:是否在方法執行前就清空,缺省為 false,如果指定為 true,則在方法還沒有執行的時候就清空緩存。缺省情況下,如果方法執行拋出異常,則不會清空緩存。
緩存問題
面試官:看了一下你的 Demo,簡單易懂。那你在實際項目中使用緩存有遇到什么問題或者會遇到什么問題你知道嗎?
我:緩存和數據庫數據一致性問題:分布式環境下非常容易出現緩存和數據庫間數據一致性問題,針對這一點,如果項目對緩存的要求是強一致性的,那么就不要使用緩存。
我們只能采取合適的策略來降低緩存和數據庫間數據不一致的概率,而無法保證兩者間的強一致性。
合適的策略包括合適的緩存更新策略,更新數據庫后及時更新緩存、緩存失敗時增加重試機制。 面試官:Redis 雪崩了解嗎?
我:我了解的,目前電商首頁以及熱點數據都會去做緩存,一般緩存都是定時任務去刷新,或者查不到之后去更新緩存的,定時任務刷新就有一個問題。
舉個栗子:如果首頁所有 Key 的失效時間都是 12 小時,中午 12 點刷新的,我零點有個大促活動大量用戶涌入,假設每秒 6000 個請求,本來緩存可以抗住每秒 5000 個請求,但是緩存中所有 Key 都失效了。
此時 6000 個/秒的請求全部落在了數據庫上,數據庫必然扛不住,真實情況可能 DBA 都沒反應過來直接掛了。
此時,如果沒什么特別的方案來處理,DBA 很著急,重啟數據庫,但是數據庫立馬又被新流量給打死了。這就是我理解的緩存雪崩。
我心想:同一時間大面積失效,瞬間 Redis 跟沒有一樣,那這個數量級別的請求直接打到數據庫幾乎是災難性的。
你想想如果掛的是一個用戶服務的庫,那其他依賴他的庫所有接口幾乎都會報錯。
如果沒做熔斷等策略基本上就是瞬間掛一片的節奏,你怎么重啟用戶都會把你打掛,等你重啟好的時候,用戶早睡覺去了,臨睡之前,罵罵咧咧“什么垃圾產品”。 面試官摸摸了自己的頭發:嗯,還不錯,那這種情況你都是怎么應對的?
我:處理緩存雪崩簡單,在批量往 Redis 存數據的時候,把每個 Key 的失效時間都加個隨機值就好了,這樣可以保證數據不會再同一時間大面積失效。
setRedis(key,value,time+Math.random()*10000);
如果 Redis 是集群部署,將熱點數據均勻分布在不同的 Redis 庫中也能避免全部失效。
或者設置熱點數據永不過期,有更新操作就更新緩存就好了(比如運維更新了首頁商品,那你刷下緩存就好了,不要設置過期時間),電商首頁的數據也可以用這個操作,保險。
面試官:那你了解緩存穿透和擊穿么,可以說說他們跟雪崩的區別嗎?
我:嗯,了解,先說下緩存穿透吧,緩存穿透是指緩存和數據庫中都沒有的數據,而用戶(黑客)不斷發起請求。
舉個栗子:我們數據庫的 id 都是從 1 自增的,如果發起 id=-1 的數據或者 id 特別大不存在的數據,這樣的不斷攻擊導致數據庫壓力很大,嚴重會擊垮數據庫。
我又接著說:至于緩存擊穿嘛,這個跟緩存雪崩有點像,但是又有一點不一樣,緩存雪崩是因為大面積的緩存失效,打崩了 DB。
而緩存擊穿不同的是緩存擊穿是指一個 Key 非常熱點,在不停地扛著大量的請求,大并發集中對這一個點進行訪問,當這個 Key 在失效的瞬間,持續的大并發直接落到了數據庫上,就在這個 Key 的點上擊穿了緩存。 面試官露出欣慰的眼光:那他們分別怎么解決?
我:緩存穿透我會在接口層增加校驗,比如用戶鑒權,參數做校驗,不合法的校驗直接 return,比如 id 做基礎校驗,id<=0 直接攔截。 ?面試官:那你還有別的方法嗎?
我:我記得 Redis 里還有一個高級用法布隆過濾器(Bloom Filter)這個也能很好的預防緩存穿透的發生。
它的原理也很簡單,就是利用高效的數據結構和算法快速判斷出你這個 Key 是否在數據庫中存在,不存在你 return 就好了,存在你就去查 DB 刷新 KV 再 return。
緩存擊穿的話,設置熱點數據永不過期,或者加上互斥鎖就搞定了。作為暖男,代碼給你準備好了,拿走不謝。
publicstaticStringgetData(Stringkey)throwsInterruptedException{ //從Redis查詢數據 Stringresult=getDataByKV(key); //參數校驗 if(StringUtils.isBlank(result)){ try{ //獲得鎖 if(reenLock.tryLock()){ //去數據庫查詢 result=getDataByDB(key); //校驗 if(StringUtils.isNotBlank(result)){ //插進緩存 setDataToKV(key,result); } }else{ //睡一會再拿 Thread.sleep(100L); result=getData(key); } }finally{ //釋放鎖 reenLock.unlock(); } } returnresult; }
面試官:嗯嗯,還不錯。
Redis 為何這么快
面試官:Redis 作為緩存大家都在用,那 Redis 一定很快咯?
我:當然了,官方提供的數據可以達到 100000+ 的 QPS(每秒內的查詢次數),這個數據不比 Memcached 差!
面試官:Redis 這么快,它的“多線程模型”你了解嗎?(露出邪魅一笑)
我:您是想問 Redis 這么快,為什么還是單線程的吧。Redis 確實是單進程單線程的模型,因為 Redis 完全是基于內存的操作,CPU 不是 Redis 的瓶頸,Redis 的瓶頸最有可能是機器內存的大小或者網絡帶寬。
既然單線程容易實現,而且 CPU 不會成為瓶頸,那就順理成章的采用單線程的方案了(畢竟采用多線程會有很多麻煩)。
面試官:嗯,是的。那你能說說 Redis 是單線程的,為什么還能這么快嗎?
我:可以這么說吧,總結一下有如下四點:
Redis 完全基于內存,絕大部分請求是純粹的內存操作,非常迅速,數據存在內存中,類似于 HashMap,HashMap 的優勢就是查找和操作的時間復雜度是 O(1)。
數據結構簡單,對數據操作也簡單。
采用單線程,避免了不必要的上下文切換和競爭條件,不存在多線程導致的 CPU 切換,不用去考慮各種鎖的問題,不存在加鎖釋放鎖操作,沒有死鎖問題導致的性能消耗。
使用多路復用 IO 模型,非阻塞 IO。
Redis 和 Memcached 的區別
面試官:嗯嗯,說的很詳細。那你為什么選擇 Redis 的緩存方案而不用 Memcached 呢? 我:原因有如下四點:
存儲方式上:Memcache 會把數據全部存在內存之中,斷電后會掛掉,數據不能超過內存大小。Redis 有部分數據存在硬盤上,這樣能保證數據的持久性。
數據支持類型上:Memcache 對數據類型的支持簡單,只支持簡單的 key-value,,而 Redis 支持五種數據類型。
使用底層模型不同:它們之間底層實現方式以及與客戶端之間通信的應用協議不一樣。Redis 直接自己構建了 VM 機制,因為一般的系統調用系統函數的話,會浪費一定的時間去移動和請求。
Value 的大小:Redis 可以達到 1GB,而 Memcache 只有 1MB。
淘汰策略
面試官:那你說說你知道的 Redis 的淘汰策略有哪些?
我:Redis 有六種淘汰策略,如下圖:

補充一下:Redis 4.0 加入了 LFU(least frequency use)淘汰策略,包括 volatile-lfu 和 allkeys-lfu,通過統計訪問頻率,將訪問頻率最少,即最不經常使用的 KV 淘汰。
持久化
面試官:你對 Redis 的持久化機制了解嗎?能講一下嗎?
我:Redis 為了保證效率,數據緩存在了內存中,但是會周期性的把更新的數據寫入磁盤或者把修改操作寫入追加的記錄文件中,以保證數據的持久化。
Redis 的持久化策略有兩種:
RDB:快照形式是直接把內存中的數據保存到一個 dump 的文件中,定時保存,保存策略。
AOF:把所有的對 Redis 的服務器進行修改的命令都存到一個文件里,命令的集合。Redis 默認是快照 RDB 的持久化方式。
當 Redis 重啟的時候,它會優先使用 AOF 文件來還原數據集,因為 AOF 文件保存的數據集通常比 RDB 文件所保存的數據集更完整。你甚至可以關閉持久化功能,讓數據只在服務器運行時存。
面試官:那你再說下 RDB 是怎么工作的? 我:默認 Redis 是會以快照"RDB"的形式將數據持久化到磁盤的一個二進制文件 dump.rdb。 工作原理簡單說一下:當 Redis 需要做持久化時,Redis 會 fork 一個子進程,子進程將數據寫到磁盤上一個臨時 RDB 文件中。
當子進程完成寫臨時文件后,將原來的 RDB 替換掉,這樣的好處是可以 copy-on-write。
我:RDB 的優點是:這種文件非常適合用于備份:比如,你可以在最近的 24 小時內,每小時備份一次,并且在每個月的每一天也備份一個 RDB 文件。
這樣的話,即使遇上問題,也可以隨時將數據集還原到不同的版本。RDB 非常適合災難恢復。
RDB 的缺點是:如果你需要盡量避免在服務器故障時丟失數據,那么RDB不合適你。
面試官:那你要不再說下 AOF?
我:(說就一起說下吧)使用 AOF 做持久化,每一個寫命令都通過 write 函數追加到 appendonly.aof 中,配置方式如下:
appendfsyncyes appendfsyncalways#每次有數據修改發生時都會寫入AOF文件。 appendfsynceverysec#每秒鐘同步一次,該策略為AOF的缺省策略。
AOF 可以做到全程持久化,只需要在配置中開啟 appendonly yes。這樣 Redis 每執行一個修改數據的命令,都會把它添加到 AOF 文件中,當 Redis 重啟時,將會讀取 AOF 文件進行重放,恢復到 Redis 關閉前的最后時刻。
我頓了一下,繼續說:使用 AOF 的優點是會讓 Redis 變得非常耐久。可以設置不同的 Fsync 策略,AOF的默認策略是每秒鐘 Fsync 一次,在這種配置下,就算發生故障停機,也最多丟失一秒鐘的數據。
缺點是對于相同的數據集來說,AOF 的文件體積通常要大于 RDB 文件的體積。根據所使用的 Fsync 策略,AOF 的速度可能會慢于 RDB。
面試官又問:你說了這么多,那我該用哪一個呢?
我:如果你非常關心你的數據,但仍然可以承受數分鐘內的數據丟失,那么可以額只使用 RDB 持久。
AOF 將 Redis 執行的每一條命令追加到磁盤中,處理巨大的寫入會降低Redis的性能,不知道你是否可以接受。
數據庫備份和災難恢復:定時生成 RDB 快照非常便于進行數據庫備份,并且 RDB 恢復數據集的速度也要比 AOF 恢復的速度快。
當然了,Redis 支持同時開啟 RDB 和 AOF,系統重啟后,Redis 會優先使用 AOF 來恢復數據,這樣丟失的數據會最少。
主從復制
面試官:Redis 單節點存在單點故障問題,為了解決單點問題,一般都需要對 Redis 配置從節點,然后使用哨兵來監聽主節點的存活狀態,如果主節點掛掉,從節點能繼續提供緩存功能,你能說說 Redis 主從復制的過程和原理嗎? 我有點懵,這個說來就話長了。但幸好提前準備了:主從配置結合哨兵模式能解決單點故障問題,提高 Redis 可用性。
從節點僅提供讀操作,主節點提供寫操作。對于讀多寫少的狀況,可給主節點配置多個從節點,從而提高響應效率。
我頓了一下,接著說:關于復制過程,是這樣的:
從節點執行 slaveof[masterIP][masterPort],保存主節點信息。
從節點中的定時任務發現主節點信息,建立和主節點的 Socket 連接。
從節點發送 Ping 信號,主節點返回 Pong,兩邊能互相通信。
連接建立后,主節點將所有數據發送給從節點(數據同步)。
主節點把當前的數據同步給從節點后,便完成了復制的建立過程。接下來,主節點就會持續的把寫命令發送給從節點,保證主從數據一致性。
面試官:那你能詳細說下數據同步的過程嗎?
(我心想:這也問的太細了吧)我:可以。Redis 2.8 之前使用 sync[runId][offset] 同步命令,Redis 2.8 之后使用 psync[runId][offset] 命令。
兩者不同在于,Sync 命令僅支持全量復制過程,Psync 支持全量和部分復制。
介紹同步之前,先介紹幾個概念:
runId:每個 Redis 節點啟動都會生成唯一的 uuid,每次 Redis 重啟后,runId 都會發生變化。
offset:主節點和從節點都各自維護自己的主從復制偏移量 offset,當主節點有寫入命令時,offset=offset+命令的字節長度。
從節點在收到主節點發送的命令后,也會增加自己的 offset,并把自己的 offset 發送給主節點。
這樣,主節點同時保存自己的 offset 和從節點的 offset,通過對比 offset 來判斷主從節點數據是否一致。
repl_backlog_size:保存在主節點上的一個固定長度的先進先出隊列,默認大小是 1MB。
主節點發送數據給從節點過程中,主節點還會進行一些寫操作,這時候的數據存儲在復制緩沖區中。
從節點同步主節點數據完成后,主節點將緩沖區的數據繼續發送給從節點,用于部分復制。
主節點響應寫命令時,不但會把命名發送給從節點,還會寫入復制積壓緩沖區,用于復制命令丟失的數據補救。
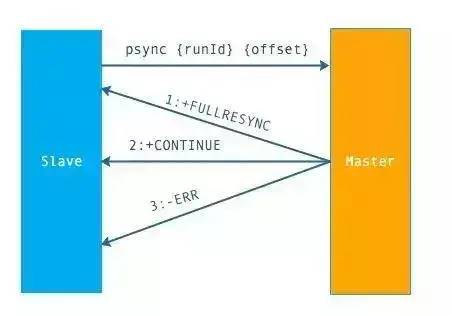
上面是 Psync 的執行流程,從節點發送 psync[runId][offset] 命令,主節點有三種響應:
FULLRESYNC:第一次連接,進行全量復制
CONTINUE:進行部分復制
ERR:不支持 psync 命令,進行全量復制
面試官:很好,那你能具體說下全量復制和部分復制的過程嗎?
我:可以!
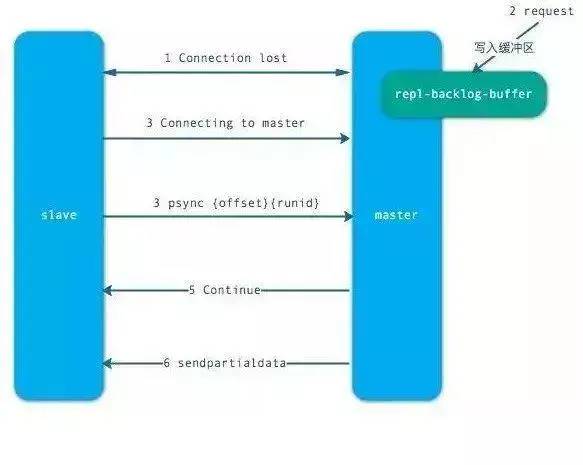
上面是全量復制的流程。主要有以下幾步:
從節點發送 psync ? -1 命令(因為第一次發送,不知道主節點的 runId,所以為?,因為是第一次復制,所以 offset=-1)。
主節點發現從節點是第一次復制,返回 FULLRESYNC {runId} {offset},runId 是主節點的 runId,offset 是主節點目前的 offset。
從節點接收主節點信息后,保存到 info 中。
主節點在發送 FULLRESYNC 后,啟動 bgsave 命令,生成 RDB 文件(數據持久化)。
主節點發送 RDB 文件給從節點。到從節點加載數據完成這段期間主節點的寫命令放入緩沖區。
從節點清理自己的數據庫數據。
從節點加載 RDB 文件,將數據保存到自己的數據庫中。如果從節點開啟了 AOF,從節點會異步重寫 AOF 文件。
關于部分復制有以下幾點說明:
①部分復制主要是 Redis 針對全量復制的過高開銷做出的一種優化措施,使用 psync[runId][offset] 命令實現。
當從節點正在復制主節點時,如果出現網絡閃斷或者命令丟失等異常情況時,從節點會向主節點要求補發丟失的命令數據,主節點的復制積壓緩沖區將這部分數據直接發送給從節點。
這樣就可以保持主從節點復制的一致性。補發的這部分數據一般遠遠小于全量數據。
②主從連接中斷期間主節點依然響應命令,但因復制連接中斷命令無法發送給從節點,不過主節點內的復制積壓緩沖區依然可以保存最近一段時間的寫命令數據。
③當主從連接恢復后,由于從節點之前保存了自身已復制的偏移量和主節點的運行 ID。因此會把它們當做 psync 參數發送給主節點,要求進行部分復制。 ④主節點接收到 psync 命令后首先核對參數 runId 是否與自身一致,如果一致,說明之前復制的是當前主節點。
之后根據參數 offset 在復制積壓緩沖區中查找,如果 offset 之后的數據存在,則對從節點發送+COUTINUE 命令,表示可以進行部分復制。因為緩沖區大小固定,若發生緩沖溢出,則進行全量復制。
⑤主節點根據偏移量把復制積壓緩沖區里的數據發送給從節點,保證主從復制進入正常狀態。
哨兵
面試官:那主從復制會存在哪些問題呢?
我:主從復制會存在以下問題:
一旦主節點宕機,從節點晉升為主節點,同時需要修改應用方的主節點地址,還需要命令所有從節點去復制新的主節點,整個過程需要人工干預。
主節點的寫能力受到單機的限制。
主節點的存儲能力受到單機的限制。
原生復制的弊端在早期的版本中也會比較突出,比如:Redis 復制中斷后,從節點會發起 psync。
此時如果同步不成功,則會進行全量同步,主庫執行全量備份的同時,可能會造成毫秒或秒級的卡頓。
面試官:那比較主流的解決方案是什么呢?
我:當然是哨兵啊。
面試官:那么問題又來了。那你說下哨兵有哪些功能?
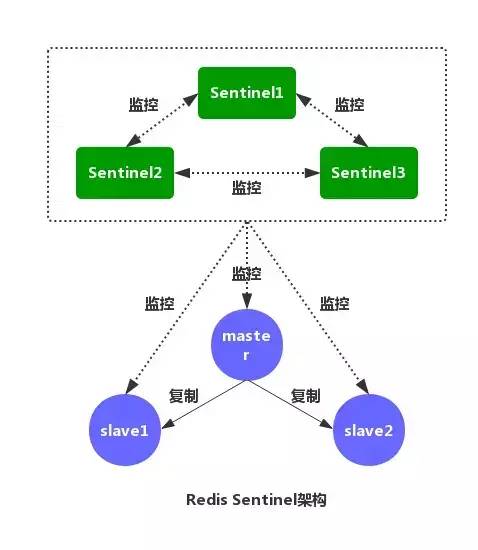
我:如圖,是 Redis Sentinel(哨兵)的架構圖。Redis Sentinel(哨兵)主要功能包括主節點存活檢測、主從運行情況檢測、自動故障轉移、主從切換。
Redis Sentinel 最小配置是一主一從。Redis 的 Sentinel 系統可以用來管理多個 Redis 服務器。
該系統可以執行以下四個任務:
監控:不斷檢查主服務器和從服務器是否正常運行。
通知:當被監控的某個 Redis 服務器出現問題,Sentinel 通過 API 腳本向管理員或者其他應用程序發出通知。
自動故障轉移:當主節點不能正常工作時,Sentinel 會開始一次自動的故障轉移操作,它會將與失效主節點是主從關系的其中一個從節點升級為新的主節點,并且將其他的從節點指向新的主節點,這樣人工干預就可以免了。
配置提供者:在 Redis Sentinel 模式下,客戶端應用在初始化時連接的是 Sentinel 節點集合,從中獲取主節點的信息。
面試官:那你能說下哨兵的工作原理嗎?
我:話不多說,直接上圖:
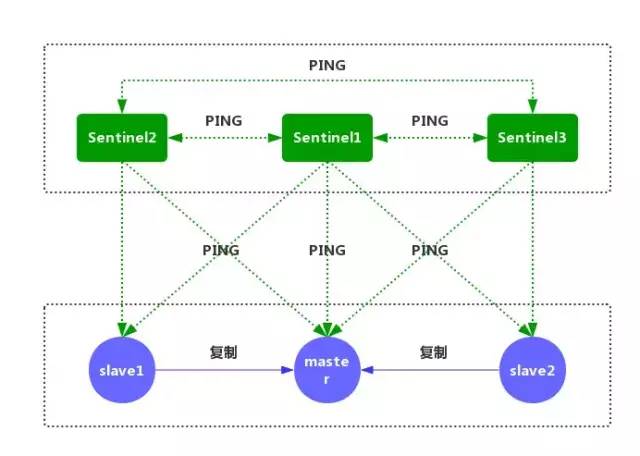
①每個 Sentinel 節點都需要定期執行以下任務:每個 Sentinel 以每秒一次的頻率,向它所知的主服務器、從服務器以及其他的 Sentinel 實例發送一個 PING 命令。(如上圖)
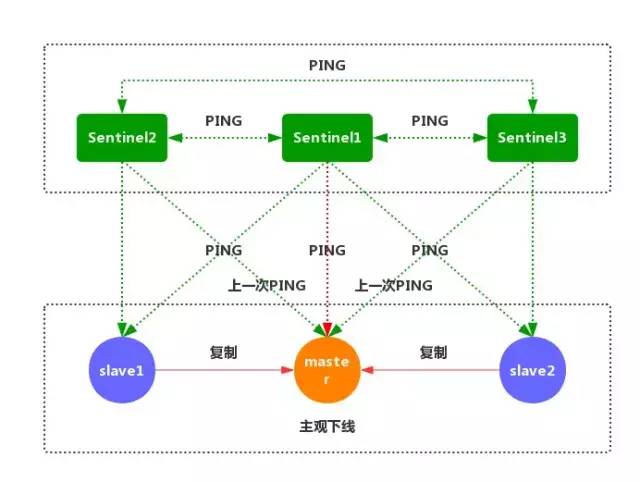
②如果一個實例距離最后一次有效回復 PING 命令的時間超過 down-after-milliseconds 所指定的值,那么這個實例會被 Sentinel 標記為主觀下線。(如上圖)
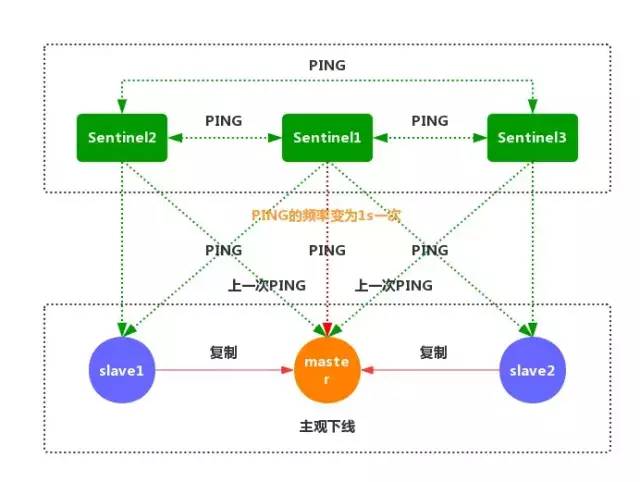
③如果一個主服務器被標記為主觀下線,那么正在監視這個服務器的所有 Sentinel 節點,要以每秒一次的頻率確認主服務器的確進入了主觀下線狀態。
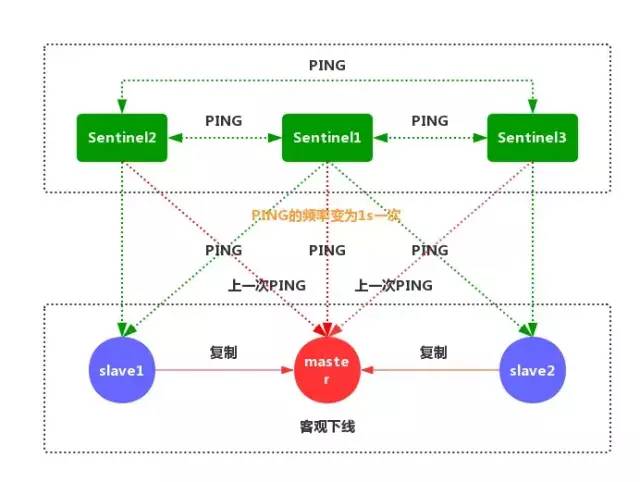
④如果一個主服務器被標記為主觀下線,并且有足夠數量的 Sentinel(至少要達到配置文件指定的數量)在指定的時間范圍內同意這一判斷,那么這個主服務器被標記為客觀下線。
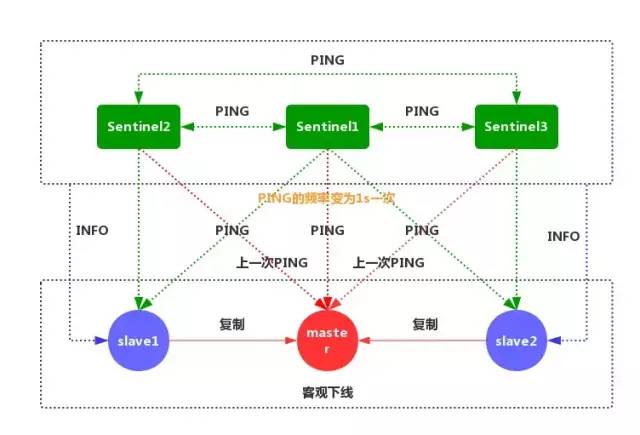
⑤一般情況下,每個 Sentinel 會以每 10 秒一次的頻率向它已知的所有主服務器和從服務器發送 INFO 命令。
當一個主服務器被標記為客觀下線時,Sentinel 向下線主服務器的所有從服務器發送 INFO 命令的頻率,會從 10 秒一次改為每秒一次。
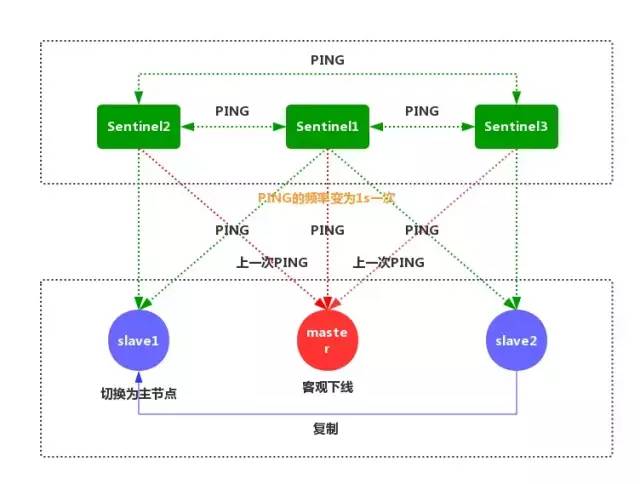
⑥Sentinel 和其他 Sentinel 協商客觀下線的主節點的狀態,如果處于 SDOWN 狀態,則投票自動選出新的主節點,將剩余從節點指向新的主節點進行數據復制。
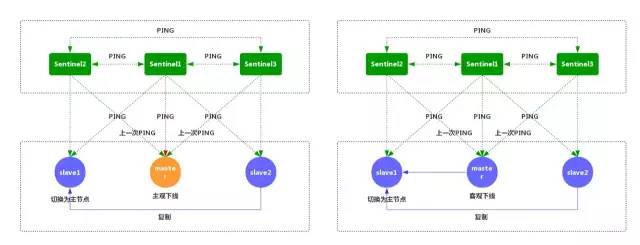
⑦當沒有足夠數量的 Sentinel 同意主服務器下線時,主服務器的客觀下線狀態就會被移除。
當主服務器重新向 Sentinel 的 PING 命令返回有效回復時,主服務器的主觀下線狀態就會被移除。
面試官:不錯,面試前沒少下工夫啊,今天 Redis 這關你過了,明天找個時間我們再聊聊其他的。(露出欣慰的微笑)
我:沒問題。
總結
本文在一次面試的過程中講述了 Redis 是什么,Redis 的特點和功能,Redis 緩存的使用,Redis 為什么能這么快,Redis 緩存的淘汰策略,持久化的兩種方式,Redis 高可用部分的主從復制和哨兵的基本原理。
只要功夫深,鐵杵磨成針,平時準備好,面試不用慌。雖然面試不一定是這樣問的,但萬變不離其“宗”。
責任編輯:lq
-
數據庫
+關注
關注
7文章
3765瀏覽量
64276 -
數據類型
+關注
關注
0文章
236瀏覽量
13609 -
Redis
+關注
關注
0文章
371瀏覽量
10846
原文標題:2W 字圖解 Redis,掃盲必備!
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Redis開源版與Redis企業版,怎么選用?

新版 Redis 不再“開源”,對使用者都有哪些影響?
redis容器內怎么查看redis日志
redis的lru原理
redis的原理和使用場景
redis hash底層實現原理
redis的持久化方式RDB和AOF的區別
redis的淘汰策略
redis查看主從節點命令
redis查看集群狀態命令
Java redis鎖怎么實現
Redis工具集的實現和使用
Windows Docker部署Redis的流程






 工商網監
工商網監
評論