 一種處理多標簽文本分類的新穎推理機制
一種處理多標簽文本分類的新穎推理機制
研究動機
多標簽文本分類(multi-label text classification, 簡稱MLTC)的目的是在給定文本后要求模型預測其多個非互斥的相關標簽。該任務在許多自然語言處理任務上都有體現。如在表1中,需要給該文檔打上標簽:basketball、NBA、sport。
表1多標簽文本分類的例子
| 文本 | This article is about a game between Houston Rockets and Los Angeles Lakers. |
| 相關標簽 | basketball, NBA, sport |
| 不相關標簽 | football |
一種處理MLTC的簡單方法是將其轉換為多個獨立的二分類問題。該方法被稱為BinaryRelevance (BR),由于其簡單性而被大規模使用。但該方法的弊端也十分明顯,即該方法完全忽略了標簽之間的相關信息。直覺上,知道一些標簽——如上例中的basketball及NBA——會使得預測其他標簽(如sport)更加簡單。研究者指出對于多標簽分類任務而言,有效利用標簽之間的相關性是有益的、甚至是必要的。為此,涌現出許多利用標簽關系的算法,其中最知名的就是算法Classifier Chains(CC)。該算法將多個二分類器串聯起來,其中每個分類器使用之前分類器的預測結果作為額外的輸入。該方法將潛在的標簽依賴納入考慮,但該問題的最大缺陷在于不同的標簽順序會產生天壤之別的性能。同時,CC算法的鏈式結構使得算法無法并行,在處理大規模數據集時效率低下。
近年來,也有學者將標簽集合視作標簽序列,并使用基于神經網絡的端到端模型(seq2seq)來處理該任務。相較于CC預測所有標簽,這類seq2seq的模型只預測相關標簽。因此該類模型的決策鏈條長度更短,性能更優。但這類模型的性能強烈依賴于標簽的順序。在多標簽數據集中,標簽本質上是無序的集合,未必可以線性排列。學者們指出不同的標簽順序對于學習和預測有著重大影響。舉例來說,對于表1中的例子,如果標簽序列以sport開始,則對于預測其他相關標簽的幫助不大。
02
—
解決方案
為了處理上述問題,我們提出了Multi-Label Reasoner(ML-Reasoner),一個基于推理機制的算法。ML-Reasoner的框架如圖1所示,我們為每一個標簽分配一個二分類器,它們同時預測所有標簽以滿足標簽的無序性質。這樣的話,ML-Reasoner可以同時計算每一個標簽相關的概率。例如在處理上例時,ML-Reasoner可能認為標簽NBA相關的概率為0.9,basketball的為0.7,sport為0.55,football為0.3.這樣,ML-Reasoner就完全避免依賴標簽順序。同時為了有效利用標簽的相關性,我們設置了一種新穎的迭代推理機制,即將上一輪對所有標簽相關的預測作為下一次迭代的額外特征輸入。這種方法使得ML-Reasoner可以在每一輪的迭代中完善預測結果。舉例來說,考慮到標簽NBA與basketball相關的概率較高,模型可以在后續迭代中,將標簽sport的概率調高。
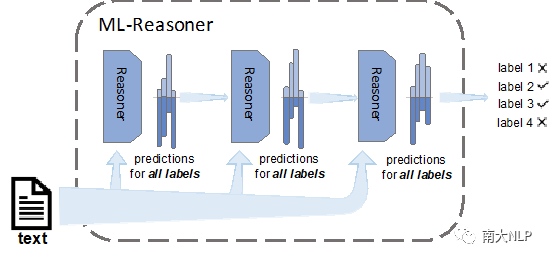
圖1 Multi-Label Reasoner整體框架圖
具體到Reasoner的實現,我們將其劃分為五個組件,其相關交互關系見圖2。
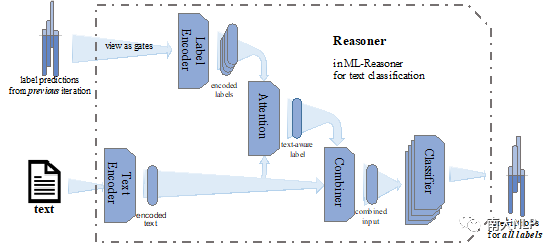
圖2多標簽文本分類的Reasoner模塊
- Text Encoder將詞語序列轉換為稠密的向量表示,主要負責抽取文本特征;
- Label Encoder將上一輪次所有標簽的相關概率轉換為相應的標簽表示;
- Attention模塊負責計算文本與不同標簽之間的相關性;
- Combiner則將文本的原始特征與標簽特征進行整合;
- 具有相同結構但不同參數的Classifier則預測各個標簽的相關性。
至于損失函數,我們選擇了Binary Cross Entropy (BCE)。更具體的設置請參見原文。
03
—
實驗
我們在兩個常用的多標簽文本分類數據集Arxiv Acadmeic Paper Dataset(AAPD)及Reuters Corpus Volum I (RCV1-V2)上進行了實驗。AAPD數據量更少、標簽密度更大,分類難度更大。評價指標則選用了hamming loss,micro-precision,micro-recall及micro-F1;其中hamming loss越低越好,其他則越高越好。至于基準模型,我們選用了經典模型如BR、CC、LP,也有性能優越的seq2seq模型如CNN-RNN、SGM,還有其他一些表現卓越的多標簽文本分類模型如LSAN,之外也將seq2set納入進來作為比較。seq2set使用強化學習算法來緩解seq2seq模型對于標簽順序的依賴程度。同時,為了驗證ML-Reasoner在不同文本編碼器上能帶來的性能提升,我們分別使用了CNN、LSTM及BERT作為ML-Reasoner框架中的Text Encoder模塊。實驗結果如表2所示。
表2 ML-Reasoner及基準模型在兩個數據集上的性能
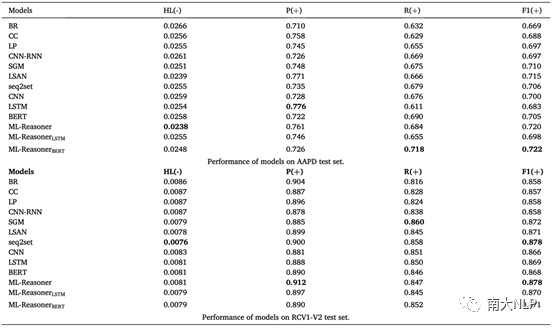
從表中可以看出,ML-Reasoner在兩個數據集上均達到了SOTA水準,且在三種不同文本編碼器上都能帶來顯著提升。
為了驗證ML-Reasoner可以完全避免對標簽順序的依賴,我們隨機打亂AAPD數據集的標簽順序,并進行了測試;各個模型的性能如表3所示。從表中可以看到,CC及seq2seq模型的性能受標簽順序的劇烈影響;seq2set可以顯著緩解seq2seq的問題;而ML-Reasoner則完全不受標簽順序的影響。
表3各模型在標簽打亂的AAPD數據集上的性能

我們也通過燒蝕實驗(見圖3),確定了推理機制確實是性能提升的關鍵。
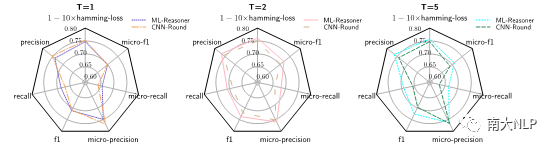
圖3 ML-Reasoner(T=1,2,5)及CNN-Round(T=1,2,5)在AAPD測試集上的性能雷達圖
我們也探究了迭代次數對模型性能的影響,由圖4可知,進行了一次推理就可以帶來顯著提升;而推理次數的再次提高并不能帶來更多的提升。這可能是因為模型及數據集的選擇導致的。
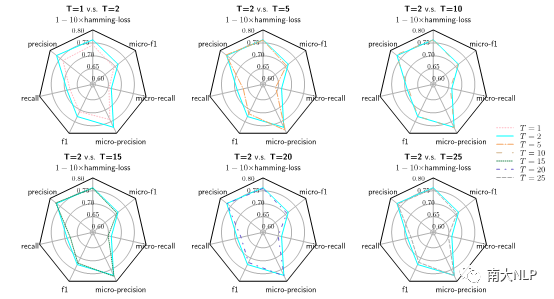
圖4不同迭代輪數下的ML-Reasoner在AAPD測試集上的性能雷達圖
為了進一步理解Reasoner發揮作用的機制,我們從數據集中選取了一些典型示例(見表4)。在第一個例子中,模型通過推理將相關標簽math.OC添上;模型處理第二個例子時,則將無關標簽cs.LO剔除;有時添加與刪除的動作也會同時發生(見第三個例子)。當然,推理偶爾也會使預測結果變差(見第四、第五個例子)。
表4 AAPD測試集中一些由于推理機制預測結果出現變化的實例

為了驗證上述例子的變化確實是因為考慮了標簽之間的相關性,我們進一步統計模型在添加或刪除某個標簽時與其他標簽的共現頻率。從圖5中,可以觀察到模型往往在添加某個標簽時,其共現頻率(第二行)與真實共現頻率接近(第一行);而刪除某個標簽時,其共現頻率(第三行)與真實共現頻率(第一行)則相差較遠。
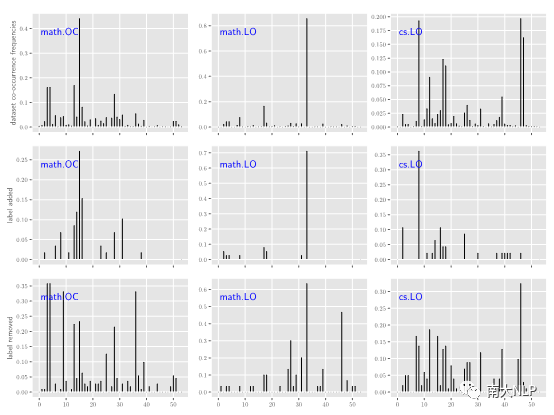
圖5 AAPD標簽的共現頻率圖
04
—
結論
在本文中,我們提出了算法ML-Reasoner。該算法可以同時預測所有標簽進而避免了對標簽順序的依賴;之外,他通過新穎的推理機制利用了標簽之間的高階關系。實驗結果表明了ML-Reasoner在捕獲標簽依賴之間的有效性;進一步的分析驗證了其確實未對標簽順序產生依賴。一些經驗性試驗也揭示了該算法發揮作用的機制。由于ML-Reasoner未顯式利用標簽之間的關系,如層次結構等,如何將這些信息納入考慮是值得進一步探索的。
原文標題:【IPM2020】一種處理多標簽文本分類的新穎推理機制
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
人工智能
+關注
關注
1791文章
46877瀏覽量
237613 -
機器學習
+關注
關注
66文章
8381瀏覽量
132425 -
nlp
+關注
關注
1文章
487瀏覽量
22013
原文標題:【IPM2020】一種處理多標簽文本分類的新穎推理機制
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
單日獲客成本超20萬,國產大模型開卷200萬字以上的長文本處理

BitEnergy AI公司開發出一種新AI處理方法
光學字符識別是什么的一種技術
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
如何訓練一個有效的eIQ基本分類模型

利用TensorFlow實現基于深度神經網絡的文本分類模型
llm模型有哪些格式
llm模型和chatGPT的區別
自然語言處理是什么技術的一種應用
卷積神經網絡在文本分類領域的應用
基于神經網絡的呼吸音分類算法
自動駕駛和多模態大語言模型的發展歷程

人工智能中文本分類的基本原理和關鍵技術
TechInsights關于蘋果智能手表金屬殼電池的探討——一種適用于便攜式和可穿戴電子產品的新穎設計





 工商網監
工商網監
評論