 如何在NLP領域實施對抗攻擊
如何在NLP領域實施對抗攻擊
如果是咱家公眾號的忠實粉絲就一定還記得之前咱家一篇關于NLP Privacy的文章,不出意外的話,你們是不是現在依然還擔心自己的隱私被輸入法竊取而瑟瑟發抖。所以,我們又來了!今天給大家討論的是NLP Privacy中一個非常核心的話題——文本對抗攻擊。
相信大家已經非常熟悉對抗攻擊了,此類攻擊是攻擊者針對機器學習模型的輸入即數值型向量(Numeric Vectors)設計的一種可以讓模型做出誤判的攻擊。簡言之,對抗攻擊就是生成對抗樣本的過程。對抗樣本的概念最初是在2014年提出的,指的是一類人為構造的樣本,通過對原始的樣本數據添加針對性的微小擾動所得到(該微擾不會影響人類的感知),但會使機器學習模型產生錯誤的輸出[1]。因此,從上述定義可知,對抗攻擊以及對抗樣本的生成研究最開始被用于計算機視覺領域。在當時,那家伙,文章多的你看都看不完…當然在這里我也拋出當時寫的比較好的一篇綜述:“Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey”[2]。大家可以溫故而知新啦。
當視覺領域中的對抗攻擊研究很難再有重大突破的時候(坑已滿,請換坑),研究人員便把目光轉移到了NLP領域。其實就NLP領域而言,垃圾郵件檢測、有害文本檢測、惡意軟件查殺等實用系統已經大規模部署了深度學習模型,安全性對于這些系統尤為重要。但相比于圖像領域,NLP領域對抗攻擊的研究還遠遠不夠,特別是文本具有離散和前后輸入具有邏輯的特點使得對抗樣本的生成更具挑戰性,也有更多的研究空間。我們欣喜地看到,目前有越來越多的 NLP 研究者開始探索文本對抗攻擊這一方向,以 2020 年 ACL 為例,粗略統計有超過 10 篇相關論文,其中最佳論文Beyond Accuracy: Behavioral Testing of NLP Models with CheckList[3]中大部分測試方法其實和文本對抗攻擊有異曲同工之妙。故在本次推文中,我們一起來探究和領略一下如何在NLP領域實施對抗攻擊,并提供一些在該領域繼續深入挖掘的工具和方向。
對抗攻擊的分類
對抗攻擊按攻擊者所掌握的知識來分的話,可分為以下兩類:
白盒攻擊:稱為white-box attack,也稱為open-box attack,即攻擊者對模型(包括參數、梯度等信息)和訓練集完全了解,這種情況比較攻擊成功,但是在實際情況中很難進行操作和實現。
黑盒攻擊:稱為black-box attack,即攻擊者對模型不了解,對訓練集不了解或了解很少。這種情況攻擊很難成功但是與實際情況比較符合,因此也是主要的研究方向。
如果按攻擊者的攻擊目標來分的話,可以分為以下兩類:
定向攻擊:稱為targeted attack,即對于一個多分類網絡,把輸入分類誤判到一個指定的類上
非定向攻擊:稱為non-target attack,即只需要生成對抗樣本來欺騙神經網絡,可以看作是上面的一種特例。
發展歷史與方法分類
我們先談談白盒攻擊,因為白盒攻擊易于實現,因此早在2014年關于對抗樣本的開山之作“Intriguing Properties of Neural Networks”中設計了一種基于梯度的白盒攻擊方法。具體來說,作者通過尋找最小的損失函數添加項,使得神經網絡做出誤分類,將問題轉化成了凸優化。問題的數學表述如下:
表示習得的分類映射函數,表示改變的步長,公式表達了尋找使得映射到指定的類上的最小的。在此之后,許多研究人員在上述方法的基礎上提出了許多改進的基于梯度的方法,具體可見[4-6]。
后來,研究人員逐漸從白盒攻擊的研究轉向研究黑盒攻擊,Transfer-based方法就是過渡時期的產物。Nicolas Papernot等人在2017年的時候利用訓練數據可以訓練出從中生成對抗性擾動的完全可觀察的替代模型[7]。因此,基于Transfer的攻擊不依賴模型信息,但需要有關訓練數據的信息。此外,[8]文獻證明了如果在一組替代模型上生成對抗性樣本,則在某些情況下,模型被攻擊的成功率可以達到100%(好家伙,100%真厲害)。近幾年,不同類型的攻擊方法越來越多,但總體來說歸為以下三類:Score-based方法、Decision-based方法、Attack on Attention方法[9](這個方法非常新,有坑可跳),前兩大類方法的相關研究和參考文獻可閱讀原文一探究竟,在這里不再贅述。
文本對抗攻擊
基本概念
下圖展示了文本領域內實現對抗攻擊的一個例子。語句(1)為原始樣本,語句(2)為經過幾個字符變換后得到的對抗樣本。深度學習模型能正確地將原始樣本判為正面評論,而將對抗樣本誤判為負面評論。而顯然,這種微小擾動并不會影響人類的判斷。
算法的分類
首先,根據上述對抗攻擊的分類。同樣地,文本中的對抗攻擊也可以分為黑盒攻擊和白盒攻擊。除此之外,由于文本涉及到字符、詞匯、句子。因此我們可以根據添加擾動時所操作的文本粒度可以分為字符級、單詞級和語句級攻擊。具體來說,字符級攻擊是通過插入、刪除或替換字符,以及交換字符順序實現;單詞級攻擊主要通過替換單詞實現,基于近義詞、形近詞、錯誤拼寫等建立候選詞庫;語句級攻擊主要通過文本復述或插入句子實現。具體分類詳見下圖.
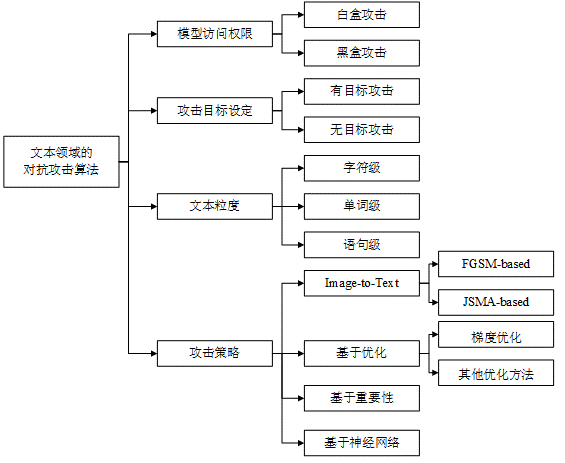
攻擊方式的發展和分類
根據攻擊策略和攻擊方式我們可以分為Image-to-Text(借鑒圖像領域的經典算法)、基于優化的攻擊、基于重要性的攻擊以及基于神經網絡的攻擊。Image-to-Text攻擊方式的思想是將文本數據映射到連續空間,然后借鑒圖像領域的一些經典算法如FGSM、JSMA等,生成對抗樣本;基于優化的攻擊則是將對抗攻擊表述為帶約束的優化問題,利用現有的優化技術求解,如梯度優化、遺傳算法優化;基于重要性的攻擊通常首先利用梯度或文本特性設計評分函數鎖定關鍵詞,然后通過文本編輯添加擾動;基于神經網絡的攻擊訓練神經網絡模型自動學習對抗樣本的特征,從而實現對抗樣本的自動化生成。具體的算法細節大家可移步一篇寫的非常全面的綜述“Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey“。
文本對抗攻擊相關資源
文獻總結
如下圖所示,清華大學自然語言處理與社會人文計算實驗室(THUNLP)總結了各類文本對抗領域的相關文獻,其中包含但不限于工具包、綜述、文本對抗攻擊、文本對抗防御、模型魯棒性驗證、基準和評估等內容。針對本文涉及的文本對抗攻擊領域,該列表收錄了句級、詞級、字級、混合四個子部分,并且還為每篇論文打上了受害模型可見性的標簽:
gradient/score/decision/blind
除了提供論文 pdf 鏈接之外,如果某篇論文有公開代碼或數據,也會附上相應的鏈接[19]。
其中必須的綜述論文如下:
-- Analysis Methods in Neural Language Processing: A Survey. Yonatan Belinkov, James Glass. TACL 2019.
-- Towards a Robust Deep Neural Network in Text Domain A Survey. Wenqi Wang, Lina Wang, Benxiao Tang, Run Wang, Aoshuang Ye. 2019.
-- Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey. Wei Emma Zhang, Quan Z. Sheng, Ahoud Alhazmi, Chenliang Li. 2019.
文本對抗攻擊工具包
目前文本攻擊工具包為該領域的研究人員提供了非常好的開發和研究基礎。這里介紹兩個比較常用的:
清華大學自然語言處理與社會人文計算實驗室開源的OpenAttack[20]
弗吉尼亞大學祁妍軍教授領導的 Qdata 實驗室開發的TextAttack[21]
至于如何使用上述兩種工具包,請大家火速前往項目主頁一探究竟,并不要忘了給一個Star哦!!!
責任編輯:lq
-
文本
+關注
關注
0文章
118瀏覽量
17068 -
深度學習
+關注
關注
73文章
5492瀏覽量
120976 -
nlp
+關注
關注
1文章
487瀏覽量
22011
原文標題:文本對抗攻擊入坑寶典
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
鑒源實驗室·如何通過雷達攻擊自動駕駛汽車-針對點云識別模型的對抗性攻擊的科普
nlp神經語言和NLP自然語言的區別和聯系
nlp自然語言處理基本概念及關鍵技術
nlp自然語言處理框架有哪些
nlp自然語言處理的主要任務及技術方法
nlp自然語言處理模型怎么做
nlp自然語言處理的應用有哪些
NLP技術在機器人中的應用
NLP技術在人工智能領域的重要性
NLP模型中RNN與CNN的選擇
什么是自然語言處理 (NLP)
隨機通信下多智能體系統的干擾攻擊影響研究

DDoS攻擊的多種方式
NLP領域的語言偏置問題分析

如何在同步反相降壓/升壓拓撲結構中實施ADP2441/ADP2442






 工商網監
工商網監
評論