") 刪掉Transformer中的這幾層性能變好了?
刪掉Transformer中的這幾層性能變好了?
基于Transformer結(jié)構(gòu)的各類(lèi)語(yǔ)言模型(Bert基于其encoder,Gpt-2基于其decoder)早已經(jīng)在各類(lèi)NLP任務(wù)上大放異彩,面對(duì)讓人眼花繚亂的transformer堆疊方式,你是否也會(huì)感到迷茫?沒(méi)關(guān)系,現(xiàn)在讓我們回到最初,再次看看transformer 本來(lái)的模樣——Rethinking the Value of Transformer Components。該文收錄已于COLING 2020。
眾所周知,一個(gè)完整的transformer結(jié)構(gòu)可以切分成Encoder-self attention(“E:SA”), Encoder-Feed Forward(“E:FF”), Decoder-Self Attention(“D:SA”), Decoder-Encoder Attention(“D:EA”) 和 Decoder-Feed Forward(“D:FF”) 5個(gè)sub-layer結(jié)構(gòu)。文中作者采用了兩種度量方式確認(rèn)這些sub-layer的重要程度。
方法稍后再談,先上干貨,實(shí)驗(yàn)結(jié)果表明:
Decoder self-attention layers是最不重要的,而Decoder feed-forward layers是最重要的;
離模型的輸入和輸出越近的sub-layer要比其他的重要些;
在decoder里越靠后的encoder-attention layer要比之前的重要。
這些結(jié)果對(duì)不同的度量方法,數(shù)據(jù)集,初始化種子以及模型容量都能保持一致性。
▲Transformer結(jié)構(gòu)圖
模塊重要性分析
所謂的重要性究竟是什么呢?論文認(rèn)為,這主要包括兩個(gè)方面:
Contribution in information Flow,對(duì)于模型信息流的貢獻(xiàn)程度
Criticality in Representation Generalization,模型的模塊對(duì)參數(shù)的擾動(dòng)表現(xiàn)出不同的魯棒性
Contribution in Information Flow
Transformer 最初是用來(lái)做機(jī)器翻譯任務(wù)的。所謂的information flow就是指數(shù)據(jù)如何從源語(yǔ)言經(jīng)過(guò)Transformer的encoder和decoder最終成為目標(biāo)語(yǔ)言的。如何衡量模型的每個(gè)部分對(duì)information flow做出的貢獻(xiàn)呢? 最直觀的想法就是去掉那個(gè)部分看看同樣條件下模型的效果如何。如果去掉那個(gè)部分,模型效果沒(méi)什么變化,那就說(shuō)明該部分沒(méi)做什么貢獻(xiàn),反之,如果刪掉該部分,模型效果顯著降低則說(shuō)明它貢獻(xiàn)卓著,沒(méi)它不行。作者采用了如下的量化方法:
公式中指的是去除第n個(gè)部分后模型整體的BLEU得分降。為了避免出現(xiàn)重要性指數(shù)出現(xiàn)負(fù)值和爆炸性下跌,作者將的值設(shè)定在[0,C]之間(真的會(huì)出現(xiàn)負(fù)重要性指數(shù)嗎?那樣倒挺好——模型變小,效果更好)。然后通過(guò)除以最大的得分降將的值進(jìn)行了歸一化,這里作者設(shè)置的上限C值為基線模型的BLEU得分的1/10.
Criticality in Representation Generalization
這里說(shuō)的criticality指的是模型的模塊對(duì)參數(shù)的擾動(dòng)表現(xiàn)出不同的魯棒性。比方說(shuō),如果將某個(gè)模塊的參數(shù)重置為初始化參數(shù),模型的表現(xiàn)變差,那么這個(gè)模塊就是critical的,否則就是non-critical的。有人在理論上將這個(gè)criticality給公式化了,而且他們表明這個(gè)criticality可以反映神經(jīng)網(wǎng)絡(luò)的泛化能力。
作者便是參考了這個(gè)工作,對(duì)網(wǎng)絡(luò)的第n個(gè)模塊,定義
即初始權(quán)重和最終權(quán)重的一個(gè)凸組合。
那么第n個(gè)部分的criticality score就可以表示為
這個(gè)式子定量的說(shuō)明了criticality是最小的能使模型在閾值的情況下保持性能。這個(gè)值越小說(shuō)明該模塊越不重要,這里取的是 0.5 BLEU分。
兩種度量方法雖然都是基于模塊對(duì)模型表現(xiàn)的影響的,但是又有不同之處。Contribution score可以看成是 hard metric(完全刪除模塊),而 Criticality score可以看成是一種soft metric,它衡量的是在保證模型表現(xiàn)的前提下模塊參數(shù)能多大程度的回卷。
實(shí)驗(yàn)
實(shí)驗(yàn)是在WMT2014 English-German(En-De)和English-French(En-Fr)兩個(gè)機(jī)器翻譯數(shù)據(jù)集上進(jìn)行的,作者使用的Transformer模型和Transformer的那篇原始文獻(xiàn)(Vaswani et al.,2017)是一樣的。Transformer model 一共6層編碼器和解碼器,layer size是512,feed-forward sub-layer的size是2048,attention head的數(shù)值是8,dropout是0.1,initialization seed設(shè)置為1。
觀察模塊的重要性
上圖是采用兩種度量方式在兩個(gè)數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果,其中X軸代表的是模塊類(lèi)型,Y軸表示的是layer id。其中顏色越深就越重要。可以看出兩種度量方式的結(jié)果很大程度上是一致的,比方說(shuō):
the decoder self-attention(D:SA)是最不重要的,而the decoder feed-forward layers(D:FF)是最重要的。
編碼器里越靠前(E:SA和E:FF)和解碼器里越靠后(D:EA和D:FF)是更重要的。這個(gè)其實(shí)很直觀,因?yàn)檫@些模塊離數(shù)據(jù)的輸入和輸出更近,所以對(duì)輸入句子的理解和輸出句子的生成要更加重要些。
在解碼器里越靠后的encoder-attention(D:EA)layers要比之前的encoder-attention layers重要。
分析不重要的模塊
更低的dropout比例和更多的訓(xùn)練數(shù)據(jù)會(huì)讓不重要的模塊變得更少(dropout是一種常見(jiàn)的用來(lái)防止過(guò)擬合的手段)。為了保證模型的效果,當(dāng)我們使用dropout的時(shí)候其實(shí)說(shuō)明模型本身有一定程度上的冗余。在不降低模型效果的前提下,小的dropout比例剛好說(shuō)明模型的冗余越少,也就是不重要的模塊更少。大規(guī)模的訓(xùn)練數(shù)據(jù)本身就自帶更多的patterns。需要充分發(fā)揮transformer的各個(gè)模塊才能有效地學(xué)習(xí)到。
從上面兩張圖可以明顯的看出:當(dāng)使用更小的dropout和更大的數(shù)據(jù)集時(shí),顏色深的版塊明顯變得更多。此外之前所得到的結(jié)論這里依然成立。
區(qū)分和利用一批不重要的模塊
之前的結(jié)果都是只刪除一個(gè)模塊得到,那我們一次性刪除多個(gè)模塊呢?
上圖顯示當(dāng)我們刪除3到4個(gè)不重要的模塊時(shí),模型效果并沒(méi)有明顯降低。但是當(dāng)刪的更多了之后,模型的效果會(huì)受到較大的影響。那么我們是否可以利用這些不怎么重要的模塊去對(duì)模型進(jìn)行優(yōu)化呢?作者采用了兩種方式:一個(gè)是模塊剪枝,另一個(gè)是模塊回卷。
模塊剪枝就是將不重要的模塊直接刪掉,因?yàn)閯h掉了相應(yīng)模塊使得模型的參數(shù)變小,作為對(duì)比作者在相同參數(shù)量下使用了一個(gè)淺層的decoder模型結(jié)果如表:
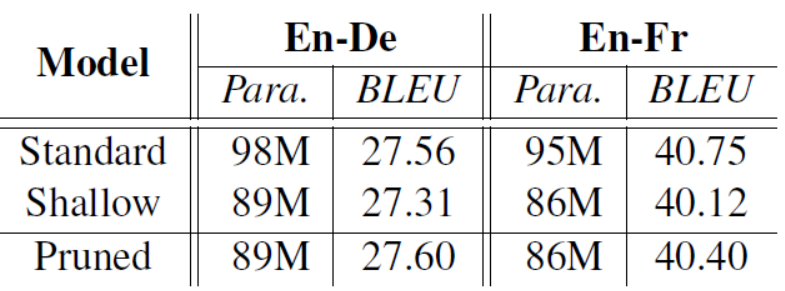
可以看出剪枝后的模型要比同樣參數(shù)下的淺層模型結(jié)果要好,而且也能達(dá)到和原始模型相應(yīng)的效果,有的甚至更好(還真有)。
模塊回卷就是將不重要的模塊參數(shù)回卷到初始化狀態(tài),再和其他模塊一起微調(diào)一下得到的訓(xùn)練結(jié)果要比原始模型好一點(diǎn)。
總結(jié)
我們可以利用contribution score和criticality score評(píng)價(jià)模型中各個(gè)模塊的重要性,知曉了模塊的重要性程度后我們可以對(duì)不重要的模塊進(jìn)行剪枝或者參數(shù)回卷都能在一定程度上讓原有模型得到優(yōu)化。
原文標(biāo)題:我刪掉了Transformer中的這幾層…性能反而變好了?
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
人工智能
+關(guān)注
關(guān)注
1791文章
46896瀏覽量
237669 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120998 -
Transformer
+關(guān)注
關(guān)注
0文章
141瀏覽量
5982
原文標(biāo)題:我刪掉了Transformer中的這幾層…性能反而變好了?
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Transformer模型的具體應(yīng)用

ADS1258使用內(nèi)部16M時(shí)鐘時(shí)動(dòng)態(tài)性能變差,是什么原因?qū)е碌模?/a>
EasyGo實(shí)時(shí)仿真丨PCS儲(chǔ)能變流器控制仿真應(yīng)用
Transformer語(yǔ)言模型簡(jiǎn)介與實(shí)現(xiàn)過(guò)程
Transformer架構(gòu)在自然語(yǔ)言處理中的應(yīng)用
Transformer模型在語(yǔ)音識(shí)別和語(yǔ)音生成中的應(yīng)用優(yōu)勢(shì)
使用PyTorch搭建Transformer模型
儲(chǔ)能變流器的拓?fù)浣Y(jié)構(gòu)介紹
儲(chǔ)能變流器的工作原理是什么
儲(chǔ)能變流器模塊作用是什么
儲(chǔ)能變流器拓?fù)浣Y(jié)構(gòu)有哪些種類(lèi)
Transformer壓縮部署的前沿技術(shù):RPTQ與PB-LLM
儲(chǔ)能變流器的特點(diǎn)有哪些
更深層的理解視覺(jué)Transformer, 對(duì)視覺(jué)Transformer的剖析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論