 如何讓Transformer在多種模態下處理不同領域的廣泛應用?
如何讓Transformer在多種模態下處理不同領域的廣泛應用?
一個模型完成了CV,NLP方向的7個任務,每個任務上表現都非常好。
Transformer架構在自然語言處理和其他領域的機器學習(ML)任務中表現出了巨大的成功,但大多僅限于單個領域或特定的多模態領域的任務。例如,ViT專門用于視覺相關的任務,BERT專注于語言任務,而VILBERT-MT只用于相關的視覺和語言任務。
一個自然產生的問題是:我們能否建立一個單一的Transformer,能夠在多種模態下處理不同領域的廣泛應用?最近,Facebook的一個人工智能研究團隊進行了一個新的統一Transformer(UniT) encoder-decoder模型的挑戰,該模型在不同的模態下聯合訓練多個任務,并通過一組統一的模型參數在這些不同的任務上都實現了強大的性能。
Transformer首先應用于sequence-to-sequence模型的語言領域。它們已經擴展到視覺領域,甚至被應用于視覺和語言的聯合推理任務。盡管可以針對各種下游任務中的應用對預先訓練好的Transformer進行微調,并獲得良好的結果,但這種模型微調方法會導致為每個下游任務創建不同的參數集。
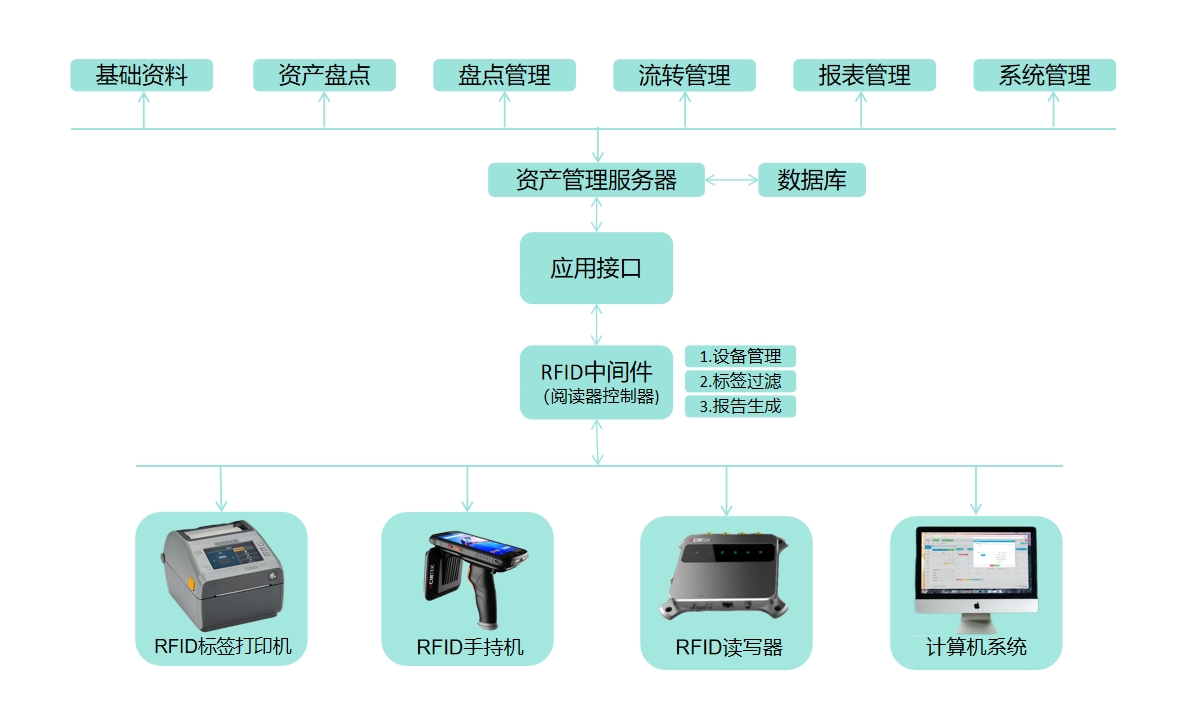
Facebook的人工智能研究人員提出,一個Transformer可能就是我們真正需要的。他們的UniT是建立在傳統的Transformer編碼器-解碼器架構上,包括每個輸入模態類型的獨立編碼器,后面跟一個具有簡單的每個任務特定的頭的解碼器。輸入有兩種形式:圖像和文本。首先,卷積神經網絡骨干網提取視覺特征,然后BERT將語言輸入編碼成隱藏狀態序列。然后,Transformer解碼器應用于編碼的單個模態或兩個編碼模態的連接序列(取決于任務是單模態還是多模態)。最后,Transformer解碼器的表示將被傳遞到特定任務的頭,該頭將輸出最終的預測。
UniT模型概要
評估UniT的性能,研究人員進行了實驗,需要共同學習來自不同領域的許多流行的任務:COCO目標檢測和 Visual Genome數據集,語言理解任務的GLUE基準(QNLI, QQP、MNLI-mismatched SST-2),以及視覺推理任務VQAv2 SNLI-VE數據集。
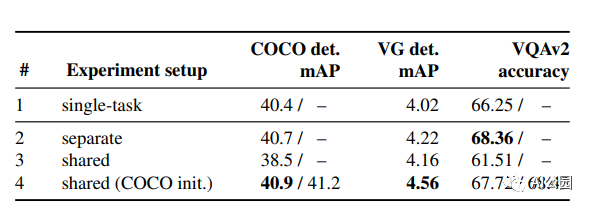
多任務訓練的UniT性能優于單獨訓練的目標檢測和VQA
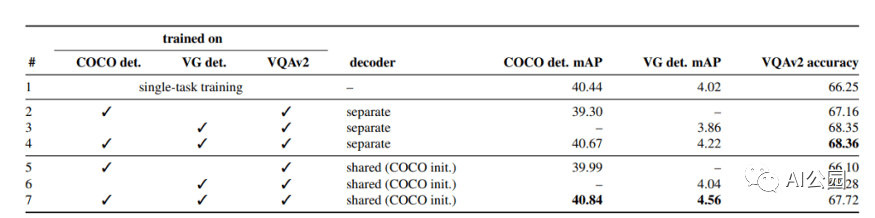
基于UniT模型的目標檢測與VQA的分析
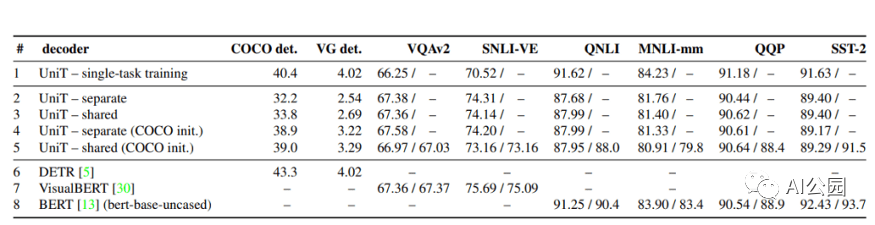
UniT模型在8個數據集的7個任務上的性能
具有共享解碼器的UniT模型的預測
結果表明,所提出的UniT 模型同時處理8個數據集上的7個任務,在統一的模型參數集下,每個任務都有較強的性能。強大的性能表明UniT有潛力成為一種領域未知的transformer 架構,向更通用的智能的目標邁進了一步。
原文標題:【多模態】來自Facebook AI的多任務多模態的統一Transformer:向更通用的智能邁出了一步
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
AI
+關注
關注
87文章
30239瀏覽量
268478 -
人工智能
+關注
關注
1791文章
46896瀏覽量
237670 -
機器學習
+關注
關注
66文章
8382瀏覽量
132444
原文標題:【多模態】來自Facebook AI的多任務多模態的統一Transformer:向更通用的智能邁出了一步
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
IP宿主信息在不同領域的廣泛應用
FPGA在自動駕駛領域有哪些應用?
Transformer能代替圖神經網絡嗎
Transformer語言模型簡介與實現過程
Transformer架構在自然語言處理中的應用
Transformer模型在語音識別和語音生成中的應用優勢
使用PyTorch搭建Transformer模型
基于Transformer模型的壓縮方法

三坐標測量儀的高精度測量功能與廣泛應用領域詳解

基于Transformer的多模態BEV融合方案
RFID在物流、供應鏈管理、工業自動化等領域的廣泛應用
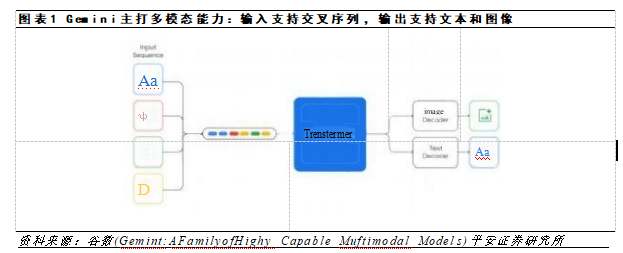
成都匯陽投資關于多模態驅動應用前景廣闊,上游算力迎機會!
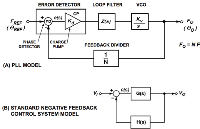
鎖相環技術在晶體振蕩器中的廣泛應用
Transformer迎來強勁競爭者 新架構Mamba引爆AI圈!






 工商網監
工商網監
評論