 智源聯合清華發布首個支持PyTorch框架的高性能MoE系統
智源聯合清華發布首個支持PyTorch框架的高性能MoE系統
北京智源人工智能研究院(以下簡稱“智源研究院”)和清華大學聯合發布首個支持 PyTorch 框架的高性能 MoE 系統:FastMoE 。
FastMoE 系統具有易用性強、靈活性好、訓練速度快的優勢,打破行業限制,可在不同規模的計算機或集群上支持研究者探索不同的 MoE 模型在不同領域的應用。相比直接使用 PyTorch 實現的版本,提速 47 倍。FastMoE 是智源研究院于 2020 年發起的新型超大規模預訓練模型研發項目“悟道”的最新成果,由“悟道文匯”(面向認知的超大規模新型預訓練模型)和“悟道文溯”(超大規模蛋白質序列預訓練模型)兩個研究小組聯合完成。
MoE 是什么?萬億模型的核心技術,推動預訓練模型跨越式發展,卻令 GPU 與 PyTorch 用戶望而卻步。
MoE(Mixture of Experts)是一個在神經網絡中引入若干專家網絡(Expert Network)的技術,也是 Google 最近發布的 1.5 萬億參數預訓練模型 Switch Transformer 的核心技術。它對于預訓練模型經從億級參數到萬億級參數的跨越,起了重要推動作用。然而由于其對 Google 分布式訓練框架 mesh-tensorflow 和 Google 定制硬件 TPU 的依賴,給學術界和開源社區的使用與研究帶來了不便。
MoE 設計:顯著增加模型參數量
在 ICLR 2017 上,Google 研究者提出了 MoE(Mixture of Experts)層。該層包含一個門網絡(Gating Network)和 n 個專家網絡(Expert Network)。對于每一個輸入,動態地由門網絡選擇 k 個專家網絡進行激活。在圖 1 的例子中,門網絡決定激活第 2 個專家網絡和第 n-1 個專家網絡。
圖 1:MoE 層的設計(圖片來源 https://arxiv.org/pdf/1701.06538.pdfFigure 1)
在具體設計中,每個輸入 x 激活的專家網絡數量 k 往往是一個非常小的數字。比如在 MoE 論文的一些實驗中,作者采用了 n=512,k=2 的設定,也就是每次只會從 512 個專家網絡中挑選兩個來激活。在模型運算量(FLOPs)基本不變的情況下,可以顯著增加模型的參數量。
GShard 和 Switch Transformer,達到驚人的 1.5 萬億參數量級
在 ICLR 2021 上,Google 的進一步將 MoE 應用到了基于 Transformer 的神經機器翻譯的任務上。GShard 將 Transformer 中的 Feedforward Network(FFN)層替換成了 MoE 層,并且將 MoE 層和數據并行巧妙地結合起來。在數據并行訓練時,模型在訓練集群中已經被復制了若干份。GShard 通過將每路數據并行的 FFN 看成 MoE 中的一個專家來實現 MoE 層,這樣的設計通過在多路數據并行中引入 All-to-All 通信來實現 MoE 的功能。在論文中,Google 使用 2048 個 TPU v3 cores 花 4 天時間訓練了一個 6 千億參數的模型。
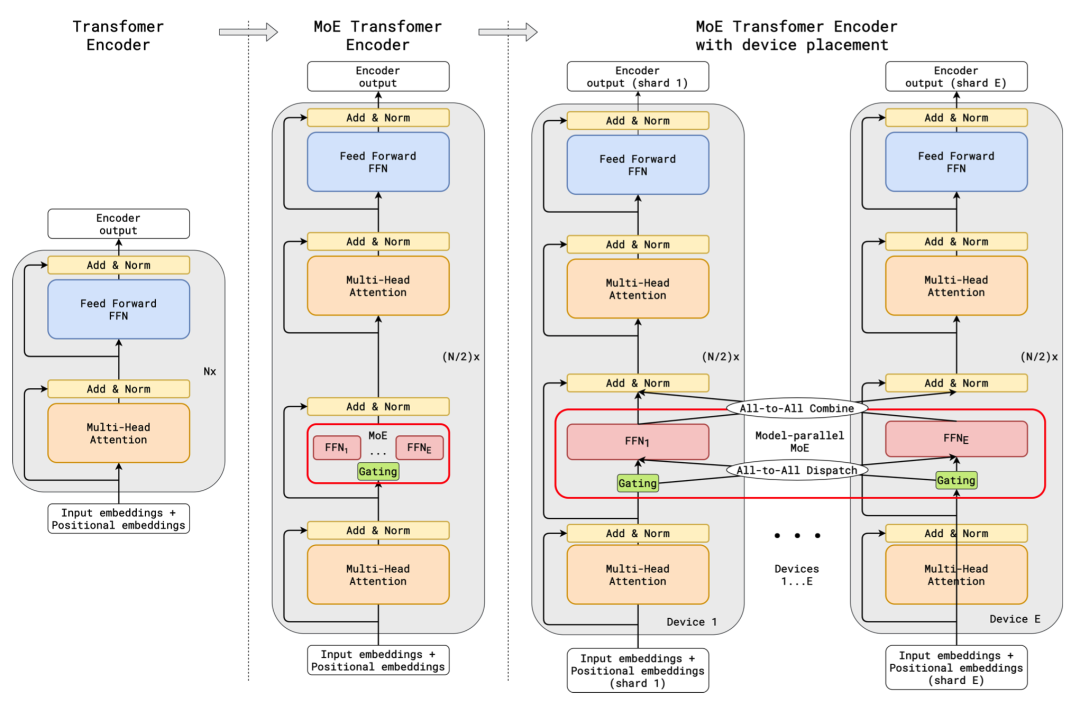
圖 2:GShard 的設計(圖片來源 https://arxiv.org/pdf/2006.16668.pdfFigure 3)
在 2021 年 1 月,Google 進一步發布了萬億規模的基于 MoE 的大規模預訓練模型 Switch Transformer。Switch Transformer 用 MoE 改進了 Google 已有的 T5 預訓練模型,其中最大的模型 Switch-C 已經達到了 1.5 萬億參數。
MMoE:MoE 的推薦系統應用
除了在自然語言處理中大放異彩之外,MoE 還在推薦系統中找到了一席之地。在 KDD 2018 中,Google 的研究人員提出了 MMoE(Multi-gate Mixture-of-Experts),并將其應用到了 Google 的推薦系統的多任務分類問題中,取得了十分好的效果。隨后,Google 在 RecSys 2019 介紹了 MMoE 在 YouTube 視頻推薦中的應用。類似的 MMoE 模型也被快手的研究員應用到了快手推薦系統的 1.9 萬億參數的大規模精排模型中。
FastMoE 是首個支持 PyTorch 框架的 MoE 系統,簡單,靈活,高性能,支持大規模并行訓練
MoE 潛力巨大,但因為綁定 Google 軟硬件,無法直接應用于 PyTorch 框架。FastMoE 是首個基于當前最流行的 PyTorch 框架的 MoE 開源系統,使得普通的用戶可以使用常見的 GPU 資源來嘗試和研究自己的 MoE 模型。與樸素版本相比,實現了 47 倍的提速優化,更加簡單、靈活、高效。
特色一:簡單易用,一行代碼即可 MoE
FastMoE 系統既可以作為 PyTorch 網絡中的一個模塊使用,也可用于“改造”現有網絡中某個層:將其復制多份,并引入 Gate,變為 MoE 層。
例如,對于當前流行的 Megatron-LM 訓練系統,僅需要對代碼進行如下改動,就可以將 Transformer 模型中的前饋網絡(Feed Forward Network)全部替換為 MoE 網絡。
特色二:靈活性,支持多種擴展方式
除了傳統的兩層 MLP 網絡,FastMoE 也支持將任意神經網絡模塊作為專家網絡,而進行這樣的操作僅需通過修改 MoE 層構造函數中的一個參數即可實現。
此外,專家選擇模塊 Gate 也有較高的研究價值。FastMoE 系統目前僅提供了基于單層全連接網絡的基礎版本,但是通過給定接口,研究者可以方便地使用自己編寫的深度神經網絡模塊作為 Gate,從而探索出更好的專家選擇方案。
特色三:運行高效,專有性能優化
FastMoE 中包含了一些專門優化的 CUDA 代碼。在單塊 GPU 上,相對于一個樸素的 PyTorch 實現,FastMoE 的算子更加充分地利用了 GPU 大規模并行計算的能力,從而實現多達 47 倍的加速,從而使得模型研究者可以在更短的時間內驗證他們的想法。
FastMoE 支持在同一個 worker 上運行多個 experts,從而減少模型研究者在探索更多 experts 數量時所需的硬件資源。當 experts 數量較多時,FastMoE 針對傳統的兩層 MLP 全連接網絡(即 Transformer 中的 FFN 網絡)使用了更精細的并行策略,從而使得 Transformer 模型中 MLP 部分的運算速度相比樸素的實現較大的加速。
圖 3:單 GPU 多 experts 情況下,FastMoE 相比普通 PyTorch 實現的加速比。性能的提升主要來自 FastMoE 針對傳統的兩層 MLP 全連接網絡(即 Transformer 中的 FFN 網絡)使用了更精細的并行策略。
單 GPU 的 FastMoE 優化配合 PyTorch 的數據并行,已經可以支持少量專家的 MoE 分布式訓練,這種訓練模式被稱為 FastMoE 的數據并行模式。圖 4 展示了一個在 2 個 workers(GPU)上對一個由 3 個 experts 構成的 MoE 網絡進行前向計算的例子。
圖 4:FastMoE 數據并行模式,每個 worker 放置多個 experts,worker 之間數據并行。top-2 gate 指的是門網絡會選擇激活分數最高的 2 個專家網絡。
FastMoE 的數據并行模式已經可以支持許多應用,開發者在著名的 Transformer-XL 模型上進行了實驗。具體來說,Transformer-XL 模型中的每一個 FFN 層(兩層的帶 ReLU 激活函數的 MLP,隱層大小為 512->2048->512)都被一個 64 選 2 的專家網絡替代(每個專家網絡是兩層的帶 ReLU 激活函數的 MLP,隱層大小為 512->1024->512)。這樣一來,改造后的 FastMoE-Transformer-XL 在模型計算量基本不變的情況下,可以獲得原始 Transformer-XL 模型約 20 倍的參數。如圖 5 所示,改造后的 FastMoE-Transformer-XL 收斂得比 Transformer-XL 更快。
圖 5:FastMoE-Transformer-XL (64 個 experts)在 enwik8 數據集上前 100K 步的 Training Loss,其收斂速度顯著快于 Transformer-XL。
特色四:支持大規模并行訓練
圖 6:FastMoE 模型并行模式,每個 worker 放置多個 experts,worker 之間進行 experts 的模型并行。top-2 gate 指的是門網絡會選擇激活分數最高的 2 個專家網絡。
FastMoE 還支持在多個 worker 間以模型并行的方式進行擴展(如圖 6 所示),即不同的 worker 上放置不同的 experts,輸入數據在計算前將被傳輸到所需的 worker 上,計算后會被傳回原來的 worker 以進行后續計算。通過這種并行方式,模型規模可以以線性擴展,從而支持研究者探索更大規模的模型。這種模式被稱為 FastMoE 的模型并行模式。
值得一提的是,FastMoE 已經和英偉達開發的超大規模預訓練工具 Megatron-LM 進行了深度整合,從而使研究者對現有代碼做盡量小的修改即可并行運行基于 MoE 的超大規模預訓練模型。開發者在 Megatron-LM 的 GPT 模型上進行了測試。如圖 7 所示,類似在 Transformer-XL 上觀察到的現象,一個 96 個 experts 的 GPT 模型可以收斂得比 GPT 模型更快。
圖 7:FastMoE-GPT (96 個 experts)在 GPT 上前 60K 步的 Training Loss,其收斂速度顯著快于 GPT。
智源研究院
新型人工智能研究機構、支持科學家勇闖 AI「無人區」
智源研究院是在科技部和北京市委市政府的指導和支持下成立的新型研發機構,旨在聚焦原始創新和核心技術,建立自由探索與目標導向相結合的科研體制,支持科學家勇闖人工智能科技前沿“無人區”。
FastMoE 團隊成員來自于智源研究院和清華大學計算機系 KEG 和 PACMAN 實驗室,打通了算法、系統等不同背景的學術人才,由智源研究院學術副院長 - 清華大學計算機系唐杰教授、智源青年科學家 - 清華大學計算機系翟季冬副教授、智源青年科學家 - 循環智能創始人楊植麟博士領導,團隊成員有清華大學計算機系博士研究生何家傲、裘捷中以及本科生曾奧涵。
原文標題:首個支持 PyTorch 框架的 MoE 系統來了!智源聯合清華開源FastMoE,萬億AI模型基石
文章出處:【微信公眾號:通信信號處理研究所】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
人工智能
+關注
關注
1791文章
46863瀏覽量
237587 -
pytorch
+關注
關注
2文章
803瀏覽量
13149
原文標題:首個支持 PyTorch 框架的 MoE 系統來了!智源聯合清華開源FastMoE,萬億AI模型基石
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
字節跳動與清華AIR成立聯合研究中心
澎峰科技高性能大模型推理引擎PerfXLM解析

華發數智攜手字節跳動共同發布AI數字人及大模型綜合解決方案
pytorch環境搭建詳細步驟
tensorflow和pytorch哪個更簡單?
tensorflow和pytorch哪個好
TensorFlow與PyTorch深度學習框架的比較與選擇
清華大學聯合中交興路發布《中國公路貨運大數據碳排放報告》

Fedora 40發布,全方位升級并新增PyTorch支持
清華權威報告公布,文心一言多項指標“遙遙領先”

昆侖萬維發布新版MoE大語言模型天工2.0
幻方量化發布了國內首個開源MoE大模型—DeepSeekMoE
對標OpenAI GPT-4,MiniMax國內首個MoE大語言模型全量上線





 工商網監
工商網監
評論