 系統是如何和MySQL交互的?
系統是如何和MySQL交互的?
天天和數據庫打交道,一天能寫上幾十條 SQL 語句,但你知道我們的系統是如何和數據庫交互的嗎?MySQL 如何幫我們存儲數據、又是如何幫我們管理事務?....是不是感覺真的除了寫幾個 「select * from dual」外基本腦子一片空白?這篇文章就將帶你走進 MySQL 的世界,讓你徹底了解系統到底是如何和 MySQL 交互的,MySQL 在接受到我們發送的 SQL 語句時又分別做了哪些事情。
MySQL 驅動
我們的系統在和 MySQL 數據庫進行通信的時候,總不可能是平白無故的就能接收和發送請求,就算是你沒有做什么操作,那總該是有其他的“人”幫我們做了一些事情,基本上使用過 MySQL 數據庫的程序員多多少少都會知道 MySQL 驅動這個概念的。就是這個 MySQL 驅動在底層幫我們做了對數據庫的連接,只有建立了連接了,才能夠有后面的交互。看下圖表示
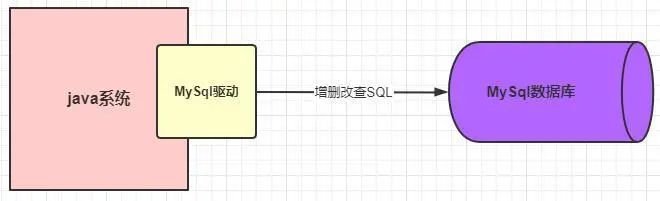
這樣的話,在系統和 MySQL 進行交互之前,MySQL 驅動會幫我們建立好連接,然后我們只需要發送 SQL 語句就可以執行 CRUD 了。一次 SQL 請求就會建立一個連接,多個請求就會建立多個連接,那么問題來了,我們系統肯定不是一個人在使用的,換句話說肯定是存在多個請求同時去爭搶連接的情況。我們的 web 系統一般都是部署在 tomcat 容器中的,而 tomcat 是可以并發處理多個請求的,這就會導致多個請求會去建立多個連接,然后使用完再都去關閉,這樣會有什么問題呢?如下圖
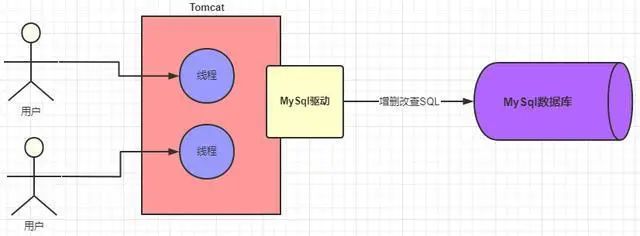
java 系統在通過 MySQL 驅動和 MySQL 數據庫連接的時候是基于 TCP/IP 協議的,所以如果每個請求都是新建連接和銷毀連接,那這樣勢必會造成不必要的浪費和性能的下降,也就說上面的多線程請求的時候頻繁的創建和銷毀連接顯然是不合理的。必然會大大降低我們系統的性能,但是如果給你提供一些固定的用來連接的線程,這樣是不是不需要反復的創建和銷毀連接了呢?相信懂行的朋友會會心一笑,沒錯,說的就是數據庫連接池。
數據庫連接池:維護一定的連接數,方便系統獲取連接,使用就去池子中獲取,用完放回去就可以了,我們不需要關心連接的創建與銷毀,也不需要關心線程池是怎么去維護這些連接的。
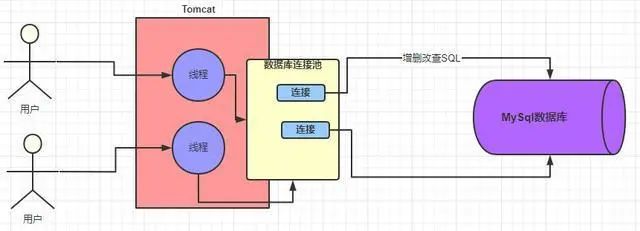
常見的數據庫連接池有 Druid、C3P0、DBCP,連接池實現原理在這里就不深入討論了,采用連接池大大節省了不斷創建與銷毀線程的開銷,這就是有名的「池化」思想,不管是線程池還是 HTTP 連接池,都能看到它的身影。
數據庫連接池
到這里,我們已經知道的是我們的系統在訪問 MySQL 數據庫的時候,建立的連接并不是每次請求都會去創建的,而是從數據庫連接池中去獲取,這樣就解決了因為反復的創建和銷毀連接而帶來的性能損耗問題了。不過這里有個小問題,業務系統是并發的,而 MySQL 接受請求的線程呢,只有一個?
其實 MySQL 的架構體系中也已經提供了這樣的一個池子,也是數據庫連池。雙方都是通過數據庫連接池來管理各個連接的,這樣一方面線程之前不需要是爭搶連接,更重要的是不需要反復的創建的銷毀連接。
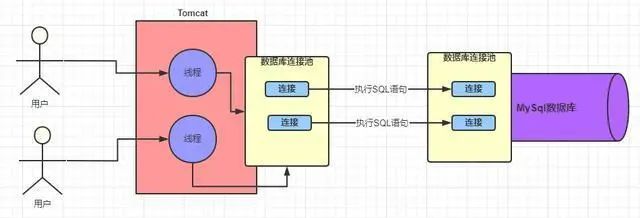
至此系統和 MySQL 數據庫之間的連接問題已經說明清楚了。那么 MySQL 數據庫中的這些連接是怎么來處理的,又是誰來處理呢?
網絡連接必須由線程來處理
對計算基礎稍微有一點了解的的同學都是知道的,網絡中的連接都是由線程來處理的,所謂網絡連接說白了就是一次請求,每次請求都會有相應的線程去處理的。也就是說對于 SQL 語句的請求在 MySQL 中是由一個個的線程去處理的。
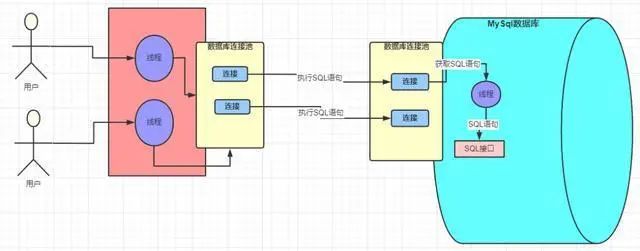
那這些線程會怎么去處理這些請求?會做哪些事情?
SQL 接口
MySQL 中處理請求的線程在獲取到請求以后獲取 SQL 語句去交給 SQL 接口去處理。
查詢解析器
假如現在有這樣的一個 SQL
SELECT stuName,age,sex FROM students WHERE id=1
但是這個 SQL 是寫給我們人看的,機器哪里知道你在說什么?這個時候解析器就上場了。他會將 SQL 接口傳遞過來的 SQL 語句進行解析,翻譯成 MySQL 自己能認識的語言,至于怎么解析的就不需要再深究了,無非是自己一套相關的規則。
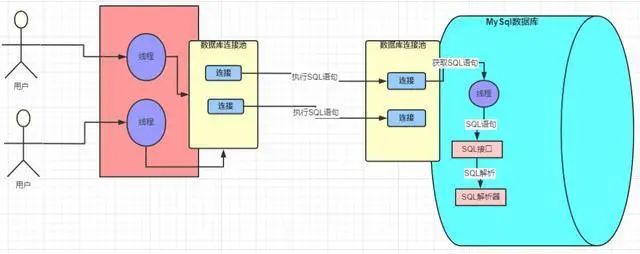
現在 SQL 已經被解析成 MySQL 認識的樣子的,那下一步是不是就是執行嗎?理論上是這樣子的,但是 MySQL 的強大遠不止于此,他還會幫我們選擇最優的查詢路徑。
什么叫最優查詢路徑?就是 MySQL 會按照自己認為的效率最高的方式去執行查詢
具體是怎么做到的呢?這就要說到 MySQL 的查詢優化器了
MySQL 查詢優化器
查詢優化器內部具體怎么實現的我們不需要是關心,我需要知道的是 MySQL 會幫我去使用他自己認為的最好的方式去優化這條 SQL 語句,并生成一條條的執行計劃,比如你創建了多個索引,MySQL 會依據成本最小原則來選擇使用對應的索引,這里的成本主要包括兩個方面, IO 成本和 CPU 成本
IO 成本: 即從磁盤把數據加載到內存的成本,默認情況下,讀取數據頁的 IO 成本是 1,MySQL 是以頁的形式讀取數據的,即當用到某個數據時,并不會只讀取這個數據,而會把這個數據相鄰的數據也一起讀到內存中,這就是有名的程序局部性原理,所以 MySQL 每次會讀取一整頁,一頁的成本就是 1。所以 IO 的成本主要和頁的大小有關
CPU 成本:將數據讀入內存后,還要檢測數據是否滿足條件和排序等 CPU 操作的成本,顯然它與行數有關,默認情況下,檢測記錄的成本是 0.2。
MySQL 優化器 會計算 「IO 成本 + CPU」 成本最小的那個索引來執行
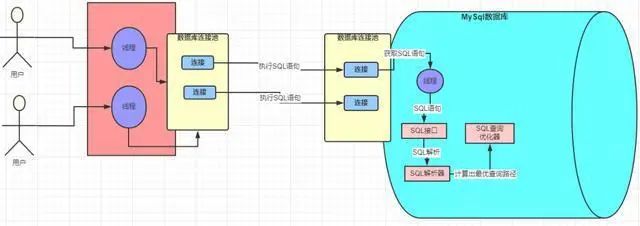
優化器執行選出最優索引等步驟后,會去調用存儲引擎接口,開始去執行被 MySQL 解析過和優化過的 SQL 語句
存儲引擎
查詢優化器會調用存儲引擎的接口,去執行 SQL,也就是說真正執行 SQL 的動作是在存儲引擎中完成的。數據是被存放在內存或者是磁盤中的(存儲引擎是一個非常重要的組件,后面會詳細介紹)
執行器
執行器是一個非常重要的組件,因為前面那些組件的操作最終必須通過執行器去調用存儲引擎接口才能被執行。執行器最終最根據一系列的執行計劃去調用存儲引擎的接口去完成 SQL 的執行
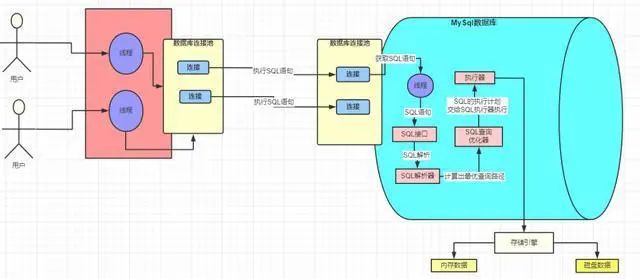
初識存儲引擎
我們以一個更新的SQL語句來說明,SQL 如下
UPDATE students SET stuName = '小強' WHERE id = 1
當我們系統發出這樣的查詢去交給 MySQL 的時候,MySQL 會按照我們上面介紹的一系列的流程最終通過執行器調用存儲引擎去執行,流程圖就是上面那個。在執行這個 SQL 的時候 SQL 語句對應的數據要么是在內存中,要么是在磁盤中,如果直接在磁盤中操作,那這樣的隨機IO讀寫的速度肯定讓人無法接受的,所以每次在執行 SQL 的時候都會將其數據加載到內存中,這塊內存就是 InnoDB 中一個非常重要的組件:緩沖池Buffer Pool
Buffer Pool
Buffer Pool (緩沖池)是InnoDB存儲引擎中非常重要的內存結構,顧名思義,緩沖池其實就是類似 Redis 一樣的作用,起到一個緩存的作用,因為我們都知道MySQL的數據最終是存儲在磁盤中的,如果沒有這個 Buffer Pool 那么我們每次的數據庫請求都會磁盤中查找,這樣必然會存在 IO 操作,這肯定是無法接受的。但是有了 Buffer Pool 就是我們第一次在查詢的時候會將查詢的結果存到 Buffer Pool 中,這樣后面再有請求的時候就會先從緩沖池中去查詢,如果沒有再去磁盤中查找,然后再放到 Buffer Pool 中,如下圖
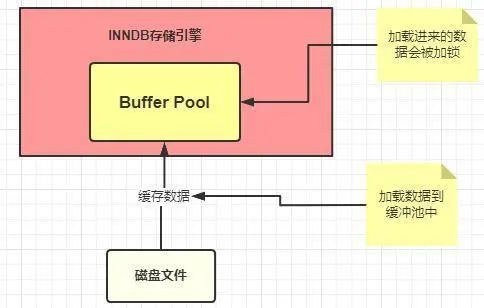
按照上面的那幅圖,這條 SQL 語句的執行步驟大致是這樣子的
innodb 存儲引擎會在緩沖池中查找 id=1 的這條數據是否存在
發現不存在,那么就會去磁盤中加載,并將其存放在緩沖池中
該條記錄會被加上一個獨占鎖(總不能你在修改的時候別人也在修改吧,這個機制本篇文章不重點介紹,以后會專門寫文章來詳細講解)
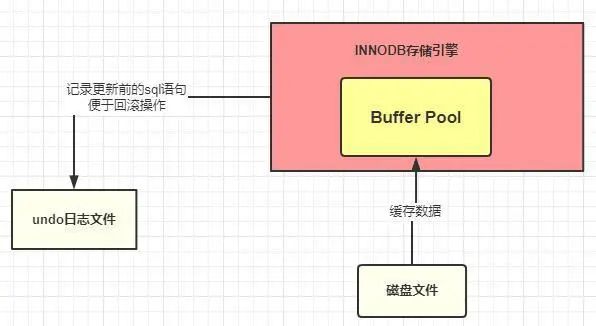
undo 日志文件:記錄數據被修改前的樣子
undo 顧名思義,就是沒有做,沒發生的意思。undo log 就是沒有發生事情(原本事情是什么)的一些日志
我們剛剛已經說了,在準備更新一條語句的時候,該條語句已經被加載到 Buffer pool 中了,實際上這里還有這樣的操作,就是在將該條語句加載到 Buffer Pool 中的時候同時會往 undo 日志文件中插入一條日志,也就是將 id=1 的這條記錄的原來的值記錄下來。
這樣做的目的是什么?
Innodb 存儲引擎的最大特點就是支持事務,如果本次更新失敗,也就是事務提交失敗,那么該事務中的所有的操作都必須回滾到執行前的樣子,也就是說當事務失敗的時候,也不會對原始數據有影響,看圖說話
這里說句額外話,其實 MySQL 也是一個系統,就好比我們平時開發的 java 的功能系統一樣,MySQL 使用的是自己相應的語言開發出來的一套系統而已,它根據自己需要的功能去設計對應的功能,它即然能做到哪些事情,那么必然是設計者們當初這么定義或者是根據實際的場景變更演化而來的。所以大家放平心態,把 MySQL 當作一個系統去了解熟悉他。
到這一步,我們的執行的 SQL 語句已經被加載到 Buffer Pool 中了,然后開始更新這條語句,更新的操作實際是在Buffer Pool中執行的,那問題來了,按照我們平時開發的一套理論緩沖池中的數據和數據庫中的數據不一致時候,我們就認為緩存中的數據是臟數據,那此時 Buffer Pool 中的數據豈不是成了臟數據?沒錯,目前這條數據就是臟數據,Buffer Pool 中的記錄是小強 數據庫中的記錄是旺財 ,這種情況 MySQL是怎么處理的呢,繼續往下看
redo 日志文件:記錄數據被修改后的樣子
除了從磁盤中加載文件和將操作前的記錄保存到 undo 日志文件中,其他的操作是在內存中完成的,內存中的數據的特點就是:斷電丟失。如果此時 MySQL 所在的服務器宕機了,那么 Buffer Pool 中的數據會全部丟失的。這個時候 redo 日志文件就需要來大顯神通了
畫外音:redo 日志文件是 InnoDB 特有的,他是存儲引擎級別的,不是 MySQL 級別的
redo 記錄的是數據修改之后的值,不管事務是否提交都會記錄下來,例如,此時將要做的是update students set stuName='小強' where id=1; 那么這條操作就會被記錄到 redo log buffer 中,啥?怎么又出來一個 redo log buffer ,很簡單,MySQL 為了提高效率,所以將這些操作都先放在內存中去完成,然后會在某個時機將其持久化到磁盤中。
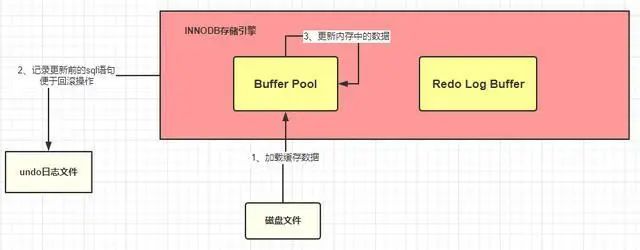
截至目前,我們應該都熟悉了 MySQL 的執行器調用存儲引擎是怎么將一條 SQL 加載到緩沖池和記錄哪些日志的,流程如下:
準備更新一條 SQL 語句
MySQL(innodb)會先去緩沖池(BufferPool)中去查找這條數據,沒找到就會去磁盤中查找,如果查找到就會將這條數據加載到緩沖池(BufferPool)中
在加載到 Buffer Pool 的同時,會將這條數據的原始記錄保存到 undo 日志文件中
innodb 會在 Buffer Pool 中執行更新操作
更新后的數據會記錄在 redo log buffer 中
上面說的步驟都是在正常情況下的操作,但是程序的設計和優化并不僅是為了這些正常情況而去做的,也是為了那些臨界區和極端情況下出現的問題去優化設計的
這個時候如果服務器宕機了,那么緩存中的數據還是丟失了。真煩,竟然數據總是丟失,那能不能不要放在內存中,直接保存到磁盤呢?很顯然不行,因為在上面也已經介紹了,在內存中的操作目的是為了提高效率。
此時,如果 MySQL 真的宕機了,那么沒關系的,因為 MySQL 會認為本次事務是失敗的,所以數據依舊是更新前的樣子,并不會有任何的影響。
好了,語句也更新好了那么需要將更新的值提交啊,也就是需要提交本次的事務了,因為只要事務成功提交了,才會將最后的變更保存到數據庫,在提交事務前仍然會具有相關的其他操作
將 redo Log Buffer 中的數據持久化到磁盤中,就是將 redo log buffer 中的數據寫入到 redo log 磁盤文件中,一般情況下,redo log Buffer 數據寫入磁盤的策略是立即刷入磁盤(具體策略情況在下面小總結出會詳細介紹),上圖
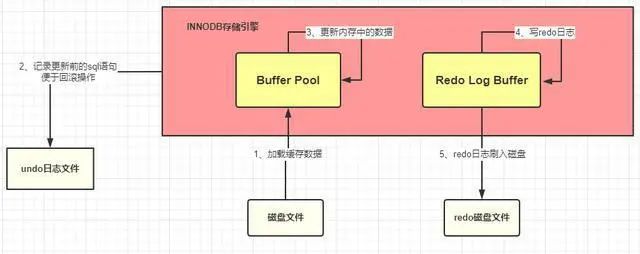
如果 redo log Buffer 刷入磁盤后,數據庫服務器宕機了,那我們更新的數據怎么辦?此時數據是在內存中,數據豈不是丟失了?不,這次數據就不會丟失了,因為 redo log buffer 中的數據已經被寫入到磁盤了,已經被持久化了,就算數據庫宕機了,在下次重啟的時候 MySQL 也會將 redo 日志文件內容恢復到 Buffer Pool 中(這邊我的理解是和 Redis 的持久化機制是差不多的,在 Redis 啟動的時候會檢查 rdb 或者是 aof 或者是兩者都檢查,根據持久化的文件來將數據恢復到內存中)
到此為止,從執行器開始調用存儲引擎接口做了哪些事情呢?
1.準備更新一條 SQL 語句
2.MySQL(innodb)會先去緩沖池(BufferPool)中去查找這條數據,沒找到就會去磁盤中查找,如果查找到就會將這條數據加載
到緩沖池(BufferPool)中 3.在加載到 Buffer Pool 的同時,會將這條數據的原始記錄保存到 undo 日志文件中
4.innodb 會在 Buffer Pool 中執行更新操作
5.更新后的數據會記錄在 redo log buffer 中
---到此是前面已經總結過的---
6.MySQL 提交事務的時候,會將 redo log buffer 中的數據寫入到 redo 日志文件中 刷磁盤可以通過 innodb_flush_log_at_trx_commit 參數來設置
值為 0 表示不刷入磁盤
值為 1 表示立即刷入磁盤
值為 2 表示先刷到 os cache
7.myslq 重啟的時候會將 redo 日志恢復到緩沖池中
截止到目前為止,MySQL 的執行器調用存儲引擎的接口去執行【執行計劃】提供的 SQL 的時候 InnoDB 做了哪些事情也就基本差不多了,但是這還沒完。下面還需要介紹下 MySQL 級別的日志文件 bin log
bin log 日志文件:記錄整個操作過程
上面介紹到的redo log是 InnoDB 存儲引擎特有的日志文件,而bin log屬于是 MySQL 級別的日志。redo log記錄的東西是偏向于物理性質的,如:“對什么數據,做了什么修改”。bin log是偏向于邏輯性質的,類似于:“對 students 表中的 id 為 1 的記錄做了更新操作” 兩者的主要特點總結如下:
bin log文件是如何刷入磁盤的?
bin log 的刷盤是有相關的策略的,策略可以通過sync_bin log來修改,默認為 0,表示先寫入 os cache,也就是說在提交事務的時候,數據不會直接到磁盤中,這樣如果宕機bin log數據仍然會丟失。所以建議將sync_bin log設置為 1 表示直接將數據寫入到磁盤文件中。
刷入 bin log 有以下幾種模式
1、 STATMENT
基于 SQL 語句的復制(statement-based replication, SBR),每一條會修改數據的 SQL 語句會記錄到 bin log 中
【優點】:不需要記錄每一行的變化,減少了 bin log 日志量,節約了 IO , 從而提高了性能
【缺點】:在某些情況下會導致主從數據不一致,比如執行sysdate()、slepp()等
2、ROW
基于行的復制(row-based replication, RBR),不記錄每條SQL語句的上下文信息,僅需記錄哪條數據被修改了
【優點】:不會出現某些特定情況下的存儲過程、或 function、或 trigger 的調用和觸發無法被正確復制的問題
【缺點】:會產生大量的日志,尤其是 alter table 的時候會讓日志暴漲
3、MIXED
基于 STATMENT 和 ROW 兩種模式的混合復制( mixed-based replication, MBR ),一般的復制使用 STATEMENT 模式保存 bin log ,對于 STATEMENT 模式無法復制的操作使用 ROW 模式保存 bin log
那既然bin log也是日志文件,那它是在什么記錄數據的呢?
其實 MySQL 在提交事務的時候,不僅僅會將 redo log buffer 中的數據寫入到redo log 文件中,同時也會將本次修改的數據記錄到 bin log文件中,同時會將本次修改的bin log文件名和修改的內容在bin log中的位置記錄到redo log中,最后還會在redo log最后寫入 commit 標記,這樣就表示本次事務被成功的提交了。
如果在數據被寫入到bin log文件的時候,剛寫完,數據庫宕機了,數據會丟失嗎?
首先可以確定的是,只要redo log最后沒有 commit 標記,說明本次的事務一定是失敗的。但是數據是沒有丟失了,因為已經被記錄到redo log的磁盤文件中了。在 MySQL 重啟的時候,就會將 redo log 中的數據恢復(加載)到Buffer Pool中。
好了,到目前為止,一個更新操作我們基本介紹得差不多,但是你有沒有感覺少了哪件事情還沒有做?是不是你也發現這個時候被更新記錄僅僅是在內存中執行的,哪怕是宕機又恢復了也僅僅是將更新后的記錄加載到Buffer Pool中,這個時候 MySQL 數據庫中的這條記錄依舊是舊值,也就是說內存中的數據在我們看來依舊是臟數據,那這個時候怎么辦呢?
其實 MySQL 會有一個后臺線程,它會在某個時機將我們Buffer Pool中的臟數據刷到 MySQL 數據庫中,這樣就將內存和數據庫的數據保持統一了。
本文總結
到此,關于Buffer Pool、Redo Log Buffer 和undo log、redo log、bin log 概念以及關系就基本差不多了。
我們再回顧下
Buffer Pool 是 MySQL 的一個非常重要的組件,因為針對數據庫的增刪改操作都是在 Buffer Pool 中完成的
Undo log 記錄的是數據操作前的樣子
redo log 記錄的是數據被操作后的樣子(redo log 是 Innodb 存儲引擎特有)
bin log 記錄的是整個操作記錄(這個對于主從復制具有非常重要的意義)
從準備更新一條數據到事務的提交的流程描述
首先執行器根據 MySQL 的執行計劃來查詢數據,先是從緩存池中查詢數據,如果沒有就會去數據庫中查詢,如果查詢到了就將其放到緩存池中
在數據被緩存到緩存池的同時,會寫入 undo log 日志文件
更新的動作是在 BufferPool 中完成的,同時會將更新后的數據添加到 redo log buffer 中
完成以后就可以提交事務,在提交的同時會做以下三件事
(第一件事)將redo log buffer中的數據刷入到 redo log 文件中
(第二件事)將本次操作記錄寫入到 bin log文件中
(第三件事)將 bin log 文件名字和更新內容在 bin log 中的位置記錄到redo log中,同時在 redo log 最后添加 commit 標記
至此表示整個更新事務已經完成
總結
文章到這里就結束了,系統是如何和 MySQL 數據庫打交道,提交一條更新的 SQL 語句到 MySQL,MySQL 執行了哪些流程,做了哪些事情從宏觀上都已經講解完成了。
原文標題:字節三面:詳解一條 SQL 的執行過程
文章出處:【微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
操作系統
+關注
關注
37文章
6738瀏覽量
123190 -
SQL
+關注
關注
1文章
760瀏覽量
44076
原文標題:字節三面:詳解一條 SQL 的執行過程
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MySQL還能跟上PostgreSQL的步伐嗎

MySQL編碼機制原理
適用于MySQL的dbForge架構比較

華納云:如何修改MySQL的默認端口

MySQL的整體邏輯架構





 工商網監
工商網監
評論