") Python特征生成作用和生成的方法
Python特征生成作用和生成的方法
創(chuàng)造新的特征是一件十分困難的事情,需要豐富的專業(yè)知識和大量的時間。機器學習應用的本質基本上就是特征工程。——Andrew Ng
業(yè)內常說數據決定了模型效果上限,而機器學習算法是通過數據特征做出預測的,好的特征可以顯著地提升模型效果。這意味著通過特征生成(即從數據設計加工出模型可用特征),是特征工程相當關鍵的一步。
本文從特征生成作用、特征生成的方法(人工設計、自動化特征生成)展開闡述并附上代碼。
1 特征生成的作用
特征生成是特征提取中的重要一步,作用在于:
增加特征的表達能力,提升模型效果;(如體重除以身高就是表達健康情況的重要特征,而單純看身高或體重,對健康情況表達就有限。)
可以融入業(yè)務上的理解設計特征,增加模型的可解釋性;
2 一鍵數據情況分析
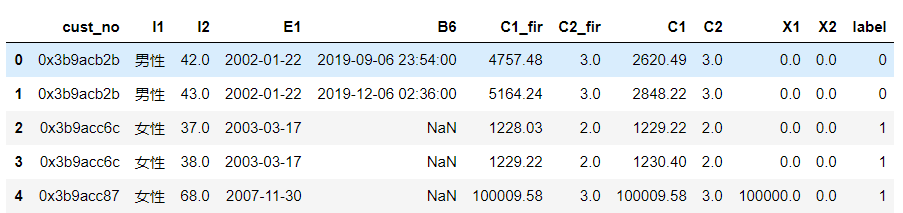
本文示例的數據集是客戶的資金變動情況,如下數據字典:
cust_no:客戶編號;I1 :性別;I2:年齡;E1:開戶日期; B6 :近期轉賬日期;C1 (后綴_fir表示上個月):存款;C2:存款產品數; X1:理財存款;X2:結構性存款; label:資金情況上升下降情況。
這里安利一個超實用Python庫,可以一鍵數據分析(數據概況、缺失、相關性、異常值等等),方便結合數據分析報告做特征生成。
#一鍵數據分析 importpandas_profiling pandas_profiling.ProfileReport(df)
3 特征生成方法(手動)
特征生成方法可以分為兩類:聚合方式、轉換方式。
3.1 聚合方式
聚合方式是指對存在一對多的字段,將其對應多條記錄分組聚合后統計平均值、計數、最大值等數據特征。如以上述數據集,同一cust_no對應多條記錄,通過對cust_no(客戶編號)做分組聚合,統計C1字段個數、唯一數、平均值、中位數、標準差、總和、最大、最小值,最終得到按每個cust_no統計的C1平均值、最大值等特征。
#以cust_no做聚合,C1字段統計個數、唯一數、平均值、中位數、標準差、總和、最大、最小值 df.groupby('cust_no').C1.agg(['count','nunique','mean','median','std','sum','max','min'])
此外還可以pandas自定義聚合函數生成特征,比如加工聚合元素的平方和:
#自定義分組聚合統計函數 defx2_sum(group): returnsum(group**2) df.groupby('cust_no').C1.apply(x2_sum)
3.2 轉換方式
轉換方式是指對字段間做加減乘除等運算生成數據特征的過程,對不同字段類型有不同轉換方式。
3.2.1 數值類型
加減乘除多個字段做運算生成新的特征,這通常需要結合業(yè)務層面的理解以及數據分布的情況,以生成較優(yōu)的特征集。
importnumpyasnp #前后兩個月資金和 df['C1+C1_fir']=df['C1']+df['C1_fir'] #前后兩個月資金差異 df['C1-C1_fir']=df['C1']-df['C1_fir'] #產品數*資金 df['C1*C2']=df['C1']*df['C2'] #前后兩個月資金變化率 df['C1/C1_fir']=df['C1']/df['C1_fir']-1 df.head()
多個列統計直接用聚合函數統計多列的方差、均值等
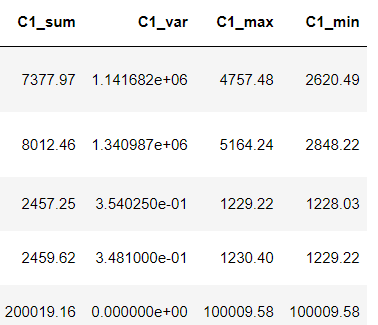
importnumpyasnp df['C1_sum']=np.sum(df[['C1_fir','C1']],axis=1) df['C1_var']=np.var(df[['C1_fir','C1']],axis=1) df['C1_max']=np.max(df[['C1_fir','C1']],axis=1) df['C1_min']=np.min(df[['C1_fir','C1']],axis=1) df['C1-C1_fir_abs']=np.abs(df['C1-C1_fir']) df.head()
排名編碼特征按特征值對全體樣本進行排序,以排序序號作為特征值。這種特征對異常點不敏感,也不容易導致特征值沖突。
#排序特征 df['C1_rank']=df['C1'].rank(ascending=0,method='dense') df.head()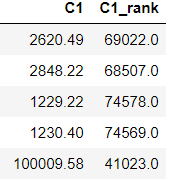
3.2.2 字符類型
截取當字符類型的值過多,通常可對字符類型變量做截取,以減少模型過擬合。如具體的家庭住址,可以截取字符串到城市級的粒度。
字符長度統計字符串長度。如轉賬場景中,轉賬留言的字數某些程度可以刻畫這筆轉賬的類型。
頻次通過統計字符出現頻次。如欺詐場景中地址出現次數越多,越有可能是團伙欺詐。
#字符特征 #由于沒有合適的例子,這邊只是用代碼實現邏輯,加工的字段并無含義。 #截取第一位字符串 df['I1_0']=df['I1'].map(lambdax:str(x)[:1]) #字符長度 df['I1_len']=df['I1'].apply(lambdax:len(str(x))) display(df.head()) #字符串頻次 df['I1'].value_counts()
3.2.3 日期類型
常用的有計算日期間隔、周幾、幾點等等。
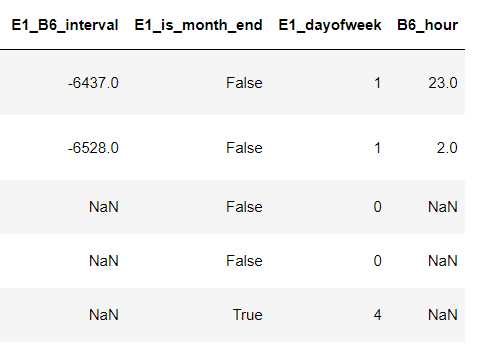
#日期類型 df['E1_B6_interval']=(df.E1.astype('datetime64[ns]')-df.B6.astype('datetime64[ns]')).map(lambdax:x.days) df['E1_is_month_end']=pd.to_datetime(df.E1).map(lambdax:x.is_month_end) df['E1_dayofweek']=df.E1.astype('datetime64[ns]').dt.dayofweek df['B6_hour']=df.B6.astype('datetime64[ns]').dt.hour df.head()
4 特征生成方法(自動化)
傳統的特征工程方法通過人工構建特征,這是一個繁瑣、耗時且容易出錯的過程。自動化特征工程是通過Fearturetools等工具,從一組相關數據表中自動生成有用的特征的過程。對比人工生成特征會更為高效,可重復性更高,能夠更快地構建模型。
4.1 FeatureTools上手
Featuretools是一個用于執(zhí)行自動化特征工程的開源庫,它有基本的3個概念:1)Feature Primitives(特征基元):生成特征的常用方法,分為聚合(agg_primitives)、轉換(trans_primitives)的方式。可通過如下代碼列出featuretools的特征加工方法及簡介。
importfeaturetoolsasft ft.list_primitives()
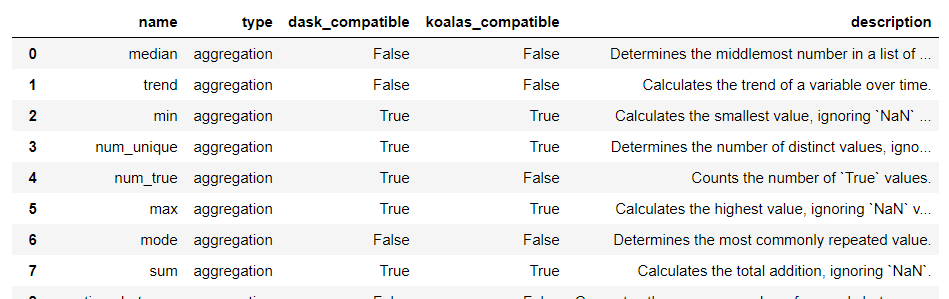
2)Entity(實體)可以被看作類似Pandas DataFrame, 多個實體的集合稱為Entityset。實體間可以根據關聯鍵添加關聯關系Relationship。
#df1為原始的特征數據 df1=df.drop('label',axis=1) #df2為客戶清單(cust_no唯一值) df2=df[['cust_no']].drop_duplicates() df2.head() #定義數據集 es=ft.EntitySet(id='dfs') #增加一個df1數據框實體 es.entity_from_dataframe(entity_id='df1', dataframe=df1, index='id', make_index=True) #增加一個df2數據實體 es.entity_from_dataframe(entity_id='df2', dataframe=df2, index='cust_no') #添加實體間關系:通過 cust_no鍵關聯 df_1 和 df 2實體 relation1=ft.Relationship(es['df2']['cust_no'],es['df1']['cust_no']) es=es.add_relationship(relation1)
3)dfs(深度特征合成):是從多個數據集創(chuàng)建新特征的過程,可以通過設置搜索的最大深度(max_depth)來控制所特征生成的復雜性
##運行DFS特征衍生 features_matrix,feature_names=ft.dfs(entityset=es, target_entity='df2', relationships=[relation1], trans_primitives=['divide_numeric','multiply_numeric','subtract_numeric'], agg_primitives=['sum'], max_depth=2,n_jobs=1,verbose=-1)
4.2 FeatureTools問題點
4.2.1 內存溢出問題Fearturetools是通過工程層面暴力生成所有特征的過程,當數據量大的時候,容易造成內存溢出。解決這個問題除了升級服務器內存,減少njobs,還有一個常用的是通過只選擇重要的特征進行暴力衍生特征。
4.2.2 特征維度爆炸當原始特征數量多,或max_depth、特征基元的種類設定較大,Fearturetools生成的特征數量巨大,容易維度爆炸。這是就需要考慮到特征選擇、特征降維。
原文標題:一文歸納Python特征生成方法(全)
文章出處:【微信公眾號:數據分析與開發(fā)】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
數據
+關注
關注
8文章
6895瀏覽量
88832 -
機器學習
+關注
關注
66文章
8378瀏覽量
132412 -
python
+關注
關注
56文章
4782瀏覽量
84456
原文標題:一文歸納Python特征生成方法(全)
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發(fā)】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
生成式AI工具作用
如何使用 Llama 3 進行文本生成
AIGC生成內容的優(yōu)勢與挑戰(zhàn)
三行代碼完成生成式AI部署
微液滴生成方法及發(fā)展趨勢
如何用C++創(chuàng)建簡單的生成式AI模型
生成式AI的定義和特征
任意波形發(fā)生器中波形生成方法
如何使用Python生成四位隨機數字
生成SPWM波形的方法
計算機快速全息生成技術研究





 工商網監(jiān)
工商網監(jiān)
評論