 識別文本蘊涵任務的小樣本學習
識別文本蘊涵任務的小樣本學習
識別文本蘊涵的任務,也稱自然語言推理,是指確定一段文本(前提)是否可被另一段文本(假設)所暗示或否認(或兩者都不能)。雖然這一問題通常被視為機器學習 (ML) 系統推理能力的重要測試,并且在純文本輸入方面已經有過深入研究,但對于此類模型在結構化數據,如網站、表格、數據庫等方面的應用,相關投入卻要少得多。然而,每當需要將表格的內容準確地歸納并呈現給用戶時,識別文本蘊涵就顯得尤為重要,這對于高保真的問答系統和虛擬助手來說更是必不可少。
在發表于 Findings of EMNLP 2020 的“通過中間預訓練以了解表格(Understanding tables with intermediate pre-training)”中,我們介紹了為表格解析定制的首批預訓練任務,可使模型從更少的數據中更好、更快地學習。
我們在較早的 TAPAS模型基礎上進行了改進,該模型是 BERT雙向 Transformer 模型的擴展,采用特殊嵌入向量在表格中尋找答案。新的預訓練目標應用于 TAPAS 后即在涉及表格的多個數據集上達成突破性進展。
例如,在 TabFact 上,它將模型和人類之間的表現差距縮小了約 50%。我們還系統地對選擇相關輸入的方法進行了基準測試以獲得更高效率,實現了速度和內存的 4 倍提升,同時保留了 92% 的結果。適用于不同任務和規模的所有模型均已發布在 GitHub repo 中,您可以在 Colab Notebook 中試用它們。
文本蘊涵
當應用于表格數據時,相比于純文本,文本蘊涵任務更具挑戰性。以一份 Wikipedia 的表格為例,其中有一些句子來自其關聯的表格內容。評估表格內容是包含還是與句子相矛盾,這可能需要查看多個列和行,還可能需要執行簡單的數字計算,例如求平均值、求和、差分等。
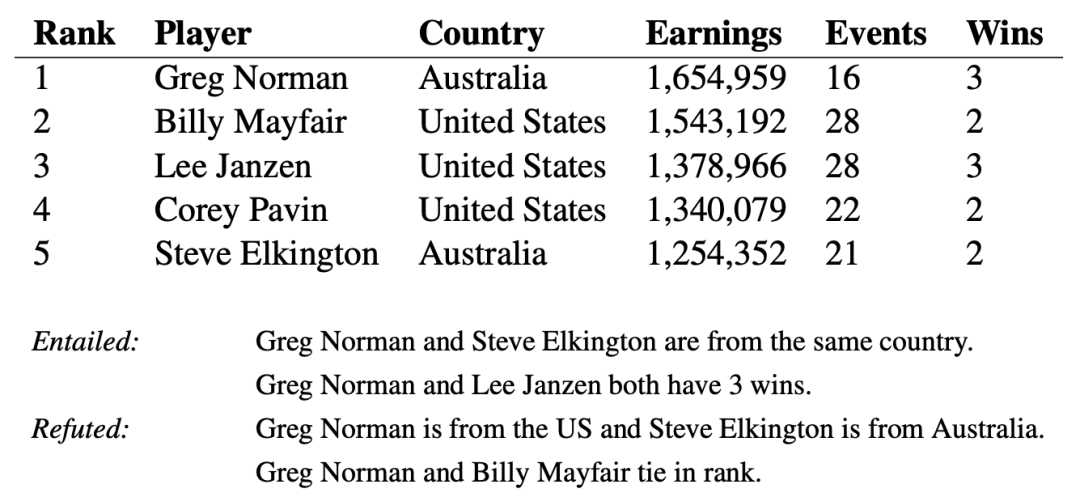
表格,以及來自 TabFact 的一些語句:表格內容可用于支持或反駁語句
按照 TAPAS 使用的方法,我們將語句和表格的內容一起編碼,通過 Transformer 模型傳遞,得到一個單一數字,表示語句被表格蘊涵或反駁的概率。
TAPAS 模型架構使用 BERT 模型對語句和展平的表格進行編碼,逐行讀取。特殊嵌入向量用于編碼表格結構。第一個令牌的向量輸出用于預測蘊涵的概率
由于訓練樣本中唯一的信息是一個二元值(即“正確”或“不正確”),因此訓練模型來理解語句是否被蘊涵是具有挑戰性的。這也凸顯了在深度學習中泛化的困難,特別是當提供的訓練信號較為稀缺的時候。發現孤立的蘊涵或反駁樣本時,模型可以輕松地在數據中提取虛假模式進行預測,例如在“Greg Norman and Billy Mayfair tie in rank”中提取“tie”一詞,而不是比較排名,因此無法超越原始訓練數據成功應用模型。
預訓練任務
預訓練任務可通過提供大量現成的未標記數據來“預熱”模型。然而,預訓練通常主要包括純文本而非表格數據。事實上,TAPAS 最初的預訓練使用的是簡單的掩碼語言建模目標,而這一目標并非為表格數據應用而設計。為了提高模型在表格數據上的性能,我們引入了兩個新的預訓練二元分類任務,稱其為反事實和合成任務,可以用作預訓練的第二階段(通常稱為中間預訓練)。
在反事實任務中,我們從 Wikipedia 提取句子,該句子提到同時出現在給定表格中的實體(人、地點或事物)。然后,在 50% 的時間里,我們將實體替換為另一個替代實體來修改語句。為了確保語句的真實性,我們在表格中同一列的實體內選擇一個替換。模型以識別語句是否被修改為目標接受訓練。這項預訓練任務包括數百萬個這樣的樣本,雖然它們的推理并不復雜,但通常還是會聽起來很自然。
對于合成任務,我們采取類似于語義解析的方法,使用一組簡單的語法規則生成語句,要求模型理解基本的數學運算,比如求和與求平均值(例如“the sum of earnings”),或者理解如何使用條件過濾表格中的元素(例如“the country is Australia”)。雖然這些語句是人為的,但它們仍然有助于提高模型的數字和邏輯推理能力。
兩個新的預訓練任務的示例實例。反事實示例將輸入表格隨附的句子中提及的實體換為一個可信的替代實體。合成語句使用語法規則創建新句子,這些句子需要以復雜的方式組合表格的信息
結果
我們通過與基線 TAPAS 模型和先前兩個文本蘊涵領域的成功模型 LogicalFactChecker (LFC) 和 Structure Aware Transformer (SAT) 進行比較,評估了反事實和合成預訓練目標在 TabFact 數據集上的成功。基線 TAPAS 模型相對于 LFC 和 SAT 表現出更好的性能,但預訓練的模型 (TAPAS+CS) 的性能明顯更好,達到新的技術水平。
我們還將 TAPAS+CS 應用于 SQA 數據集上的問答任務,這要求模型在對話框環境下從表格內容中找到答案。加入 CS 目標后,最佳性能相比于之前提高了 4 個百分點以上,這表明這種方法還可以將性能泛化到文本蘊涵之外。
TabFact(左)和 SQA(右)的結果。使用合成和反事實數據集,我們在這兩項任務中都以較大優勢取得了新的最先進結果
數據和計算效率
反事實和合成預訓練任務的另一個方面是,由于模型已經針對二元分類進行了調整,因此可以應用而無需對 TabFact 進行任何微調。我們探索了只對數據的一個子集(甚至沒有數據)進行訓練時,每個模型會發生什么。不查看單個樣本時,TAPAS+CS 模型與強基線 Table-Bert 不相上下,只包含 10% 的數據時,結果與先前的最先進水平相當。
TabFact 上的開發準確率相對于所用訓練數據的分數
試圖使用此類大型模型對表格進行操作時,一個普遍的擔憂是,高計算要求會使其難以解析非常大的表格。為了解決這個問題,我們研究了是否可以啟發式地選擇要通過模型的輸入子集,以優化其計算效率。
我們對各種過濾輸入的方法進行了系統性研究,發現選擇整列和主題語句之間的單詞重疊的簡單方法可獲得最佳結果。通過動態選擇要包括的輸入令牌,我們可以使用更少的資源或以相同的成本處理更大的輸入。這樣做的挑戰是如何保留重要信息和準確率。
例如,上述模型全部使用 512 個令牌的序列,接近于 Transformer 模型的正常極限(盡管最近的效率方法,如 Reformer或 Performer被證明可以有效地縮放輸入大小)。我們在這里提出的列選擇方法可以讓訓練速度更快,同時還能在 TabFact 上實現高準確率。對于 256 個輸入令牌,我們的準確率下降非常小,但現在可以對模型進行預訓練、微調,并使預測速度提高 2 倍。在 128 個令牌的情況下,模型仍然優于之前的最先進模型,速度提升更為顯著,獲得 4 倍全面提升。
通過我們的列選擇方法縮短輸入,使用不同序列長度在 TabFact 上得出的準確率
使用我們提出的列選擇方法和新穎的預訓練任務,可以創建出以更少數據和更少計算能力得出更好結果的表格解析模型。
我們已經在 GitHub repo 中提供了新的模型和預訓練技術,您可以在 Colab 中親自嘗試。為了使這種方法更易于使用,我們還共享了不同大小的模型,最小到“Tiny”。我們希望這些結果有助于在更廣泛的研究社區中推動表格推理的發展。
這項工作由蘇黎世語言團隊的 Julian Martin Eisenschlos、Syrine Krichene 和 Thomas Müller 完成。
原文標題:用于表格數據推理的小樣本學習
文章出處:【微信公眾號:TensorFlow】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
數據
+關注
關注
8文章
6899瀏覽量
88841 -
機器學習
+關注
關注
66文章
8381瀏覽量
132425 -
自然語言
+關注
關注
1文章
287瀏覽量
13332
原文標題:用于表格數據推理的小樣本學習
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
語音識別技術的應用與發展
【飛凌嵌入式OK3576-C開發板體驗】RKNPU圖像識別測試
深度識別人臉識別在任務中為什么有很強大的建模能力
NVIDIA文本嵌入模型NV-Embed的精度基準
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
如何學習智能家居?8:Text文本實體使用方法

基于Python的深度學習人臉識別方法
卷積神經網絡在文本分類領域的應用
基于深度學習的鳥類聲音識別系統
基于深度神經網絡的嬰兒哭聲識別算法
在全志V853平臺上成功部署深度學習步態識別算法
科大訊飛發布星火認知大模型V3.5
【技術科普】主流的深度學習模型有哪些?AI開發工程師必備!

如何使用Python進行圖像識別的自動學習自動訓練?
異構信號驅動下小樣本跨域軸承故障診斷的GMAML算法





 工商網監
工商網監
評論