") RISC-V和超級(jí)計(jì)算有什么關(guān)系?
RISC-V和超級(jí)計(jì)算有什么關(guān)系?
在1980年代,超級(jí)計(jì)算機(jī)的外觀如下圖所示。而Cray的半圓形則是80年代超級(jí)計(jì)算機(jī)的代名詞。那就是一臺(tái)超級(jí)計(jì)算機(jī)的樣子。
1980年代的Cray超級(jí)計(jì)算機(jī) 在一篇寫RISC-V的文章里,我們提到過去的超級(jí)計(jì)算,這兩者之間有什么關(guān)系?主要是因?yàn)椋覀兲岬降腃ray計(jì)算機(jī),也被稱為矢量處理機(jī)——一種已經(jīng)被拋棄的“老古董”。 然而,RISC-V卻將Cray風(fēng)格的矢量處理重新帶回來,并認(rèn)為它應(yīng)該替代SIMD(單指令多數(shù)據(jù)),這是否是一個(gè)異端? 這樣大膽而又不同的策略肯定需要一些解釋。為什么RISC-V設(shè)計(jì)師會(huì)采用與競爭對(duì)手x86,ARM,MIPS等完全不同的方法?
像往常一樣,我們需要繞道而行,以解釋這些技術(shù)究竟是什么以及它們有何不同。盡管SIMD指令排在最后,但我相信從SIMD開始更容易掌握矢量處理指令。
什么是SIMD(單指令多數(shù)據(jù))?
無論是基于x86還是基于ARM的大多數(shù)微處理器,在其中都提供了我們所謂的SIMD指令。您可能聽說過MMX,SSE,AVX-2和AVX-512。而ARM有自己的高級(jí)SIMD和SVE。
這些指令允許您執(zhí)行的操作是將相同的操作應(yīng)用于多個(gè)元素。我們可以將它與SISD(單指令單數(shù)據(jù))進(jìn)行對(duì)比,后者僅在單個(gè)元素之間執(zhí)行操作。下圖是對(duì)此的簡單說明:
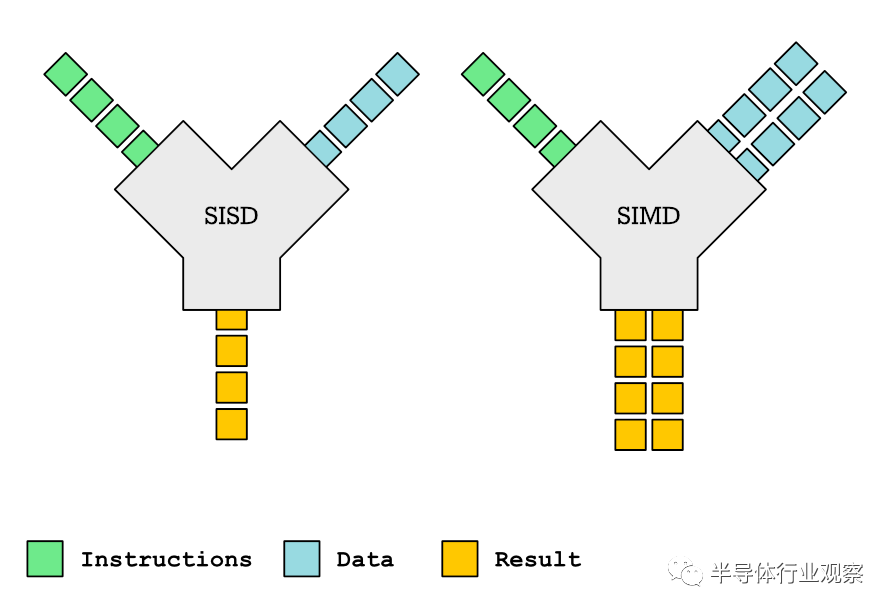
單指令單數(shù)據(jù)(SISD)與單指令多數(shù)據(jù)(SIMD) 我們可以編寫一些簡單的代碼來說明差異,以下是SISD的示例。我們也可以稱其為標(biāo)量(單個(gè)值)上的操作: 3 + 4 = 7
4 * 8 = 32 SIMD是關(guān)于向量(多個(gè)值)的操作: [3,2,1] + [1,2,2] = [4,4,3]
[3,2,1]-[1,2,2] = [2,0,-1] 讓我更詳細(xì)地了解一些用于SISD的偽匯編代碼(pseudo assembly code)。在這種情況下,我們要添加兩個(gè)數(shù)組,每個(gè)數(shù)組包含兩個(gè)元素。每個(gè)元素都是32位整數(shù)。一個(gè)從地址14開始,另一個(gè)從地址24開始: load r1,14
load r2,24
add r3,r1,r2; r3←r1 + r2
load r1,18
load r2,28
add r4,r1,r2; r4←r1 + r2 使用SIMD,我們可以加載多個(gè)值并執(zhí)行多個(gè)加法: vload.32 v1、14 vload.32
v2、24
vadd.i32 v3,v1,v2; v3←v1 + v2 通常將向量和SIMD指令加上前綴v以將它們與標(biāo)量指令分開。約定各不相同,但這是受ARM啟發(fā)的,.32后綴表示我們要加載多個(gè)32位值。假設(shè)我們的向量寄存器v1和v2是64位,則意味著每次load兩個(gè)元素。 該vadd指令的.i32后綴表示我們要添加32位帶符號(hào)整數(shù)。我們本來可以用來.u32表示無符號(hào)整數(shù)。
當(dāng)然,這是一個(gè)完全不現(xiàn)實(shí)的示例,因?yàn)闆]有人會(huì)對(duì)這幾個(gè)元素使用SIMD。更現(xiàn)實(shí)的是,我們將對(duì)16個(gè)元素進(jìn)行操作。
SIMD如何工作?
我們對(duì)SIMD指令的工作方式進(jìn)行了高級(jí)描述。但是實(shí)際上,它們是如何在CPU級(jí)別處理的?執(zhí)行SIMD指令時(shí),CPU內(nèi)部發(fā)生了什么?
在下面,您可以看到RISC微處理器的簡化圖。
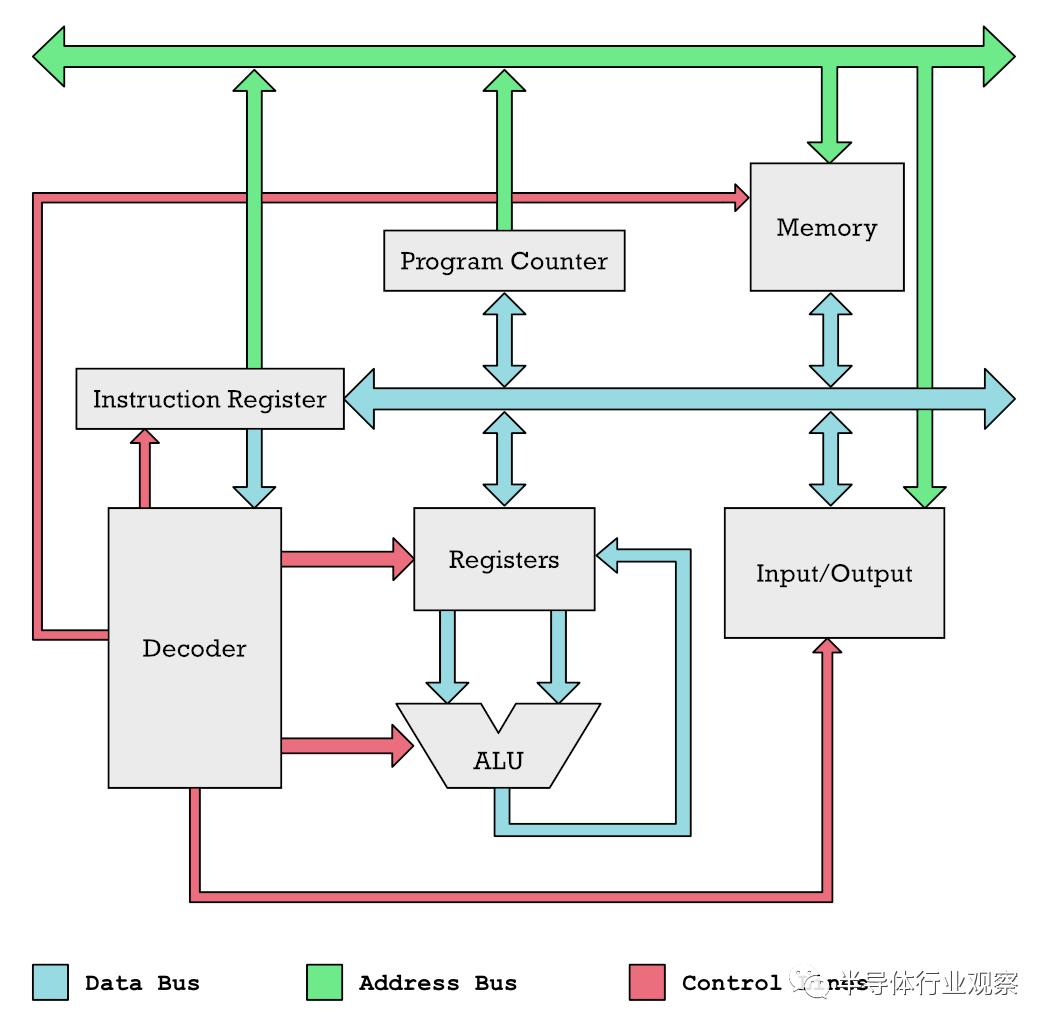
一個(gè)簡單的RISC微處理器的示意圖 您可以將彩色條視為將數(shù)據(jù)推入CPU的不同部分的管道。我們?cè)谶@里的主要興趣是藍(lán)色的東西,它們推動(dòng)了我們操作的數(shù)據(jù)以及通過系統(tǒng)的指令。綠色管道是存儲(chǔ)單元的地址位置。
Ben Eater在面包板上構(gòu)建的6502計(jì)算機(jī)。彩色線是數(shù)據(jù)和地址總線以及控制線。 在一個(gè)簡單的微處理器中,您只有一個(gè)算術(shù)邏輯單元(ALU)。這樣的處理器的一個(gè)例子是在Commodore 64中使用的6502。ALU類似于CPU的計(jì)算器。它可以加減數(shù)字,它使用兩個(gè)數(shù)字作為輸入,然后將它們相加或相減,然后將輸出到底部。輸入來自寄存器,輸出返回到寄存器(具有您要操作的保持編號(hào)的內(nèi)存單元)。 要將我們的CPU變成可以同時(shí)處理數(shù)十個(gè)數(shù)字的執(zhí)行SIMD的怪物,我們需要進(jìn)行一些更改。以下是升級(jí)的簡化示例,該升級(jí)允許同時(shí)將兩個(gè)數(shù)字相加。請(qǐng)注意,我們僅顯示與寄存器和ALU相關(guān)的部分。
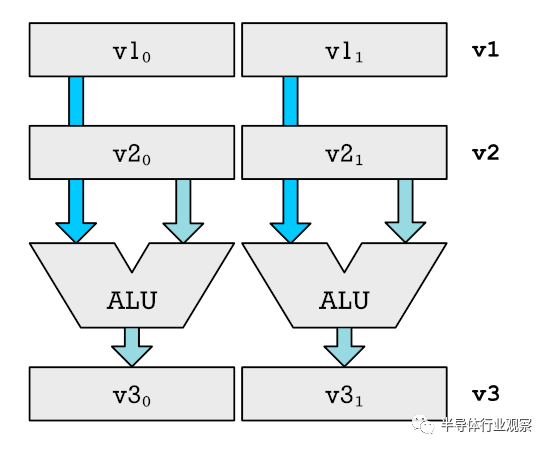
如何使用多個(gè)ALU允許執(zhí)行SIMD v1,v2而v3就是我們所說的向量寄存器。它們分為不同的部分,顯示為v1?和v1?。我們可以將向量的每個(gè)部分或元素輸入到單獨(dú)的ALU中。這使我們可以同時(shí)執(zhí)行多個(gè)添加。對(duì)于真正的CPU,我們不只是添加一個(gè)額外的ALU。我們加一打。實(shí)際上,我們變得更加瘋狂,我們添加了十二個(gè)乘法器和其他功能單元,它們能夠執(zhí)行CPU的所有不同操作。對(duì)于非常簡單的CPU,您沒有乘法器,因?yàn)槟梢酝ㄟ^重復(fù)的加法和移位(加和減數(shù)字)來模擬乘法。
我們?nèi)绾潍@得SIMD
那么這些SIMD指令是如何產(chǎn)生的呢?快速的圖像處理的需求是起點(diǎn)。圖像中的每個(gè)像素由四個(gè)8位值(RGBA)組成,需要將其視為單獨(dú)的數(shù)字。為數(shù)百萬個(gè)像素分別添加這些值很慢。SIMD指令是提高此類任務(wù)性能的明顯方法。
每個(gè)像素由四個(gè)分量組成:紅色,綠色,藍(lán)色和Alpha值。每個(gè)都是一個(gè)字節(jié),應(yīng)分別計(jì)算。如果32位寄存器是具有4個(gè)組件的向量寄存器,則可以執(zhí)行此操作。
SIMD還用于GPU內(nèi)部,因?yàn)樗鼈儠?huì)添加位置向量,相乘矩陣。復(fù)合像素顏色值等。
SIMD的好處
雖然很難并行執(zhí)行代碼,但是,當(dāng)處理諸如圖像,幾何,機(jī)器學(xué)習(xí)和大量科學(xué)計(jì)算之類的事情時(shí),對(duì)數(shù)據(jù)的多個(gè)元素執(zhí)行相同的操作相當(dāng)簡單。
換而言之,SIMD為我們提供了一種輕松加快這些計(jì)算速度的方法。如果可以只執(zhí)行一條指令就可以加8個(gè)數(shù)字,那么基本上可以實(shí)現(xiàn)8倍的加速。因此,多年來x86和ARM微處理器堆積在大量SIMD指令上就不足為奇了。 GPU基本上包含執(zhí)行大量SIMD計(jì)算的核心存儲(chǔ)區(qū)。這就是大大提高了圖形性能的原因,也是為什么科學(xué)代碼越來越多地使用GPU的原因。
但是,如果SIMD如此出色,為什么RISC-V放棄它并進(jìn)行向量處理呢?更具體地說,他們沒有添加SIMD指令集擴(kuò)展,而是添加了Vector指令集擴(kuò)展。
SIMD指令存在的問題
RISC-V設(shè)計(jì)師David Patterson和Andrew Waterman寫了一篇文章:SIMD指令被認(rèn)為有害。 這是一本有趣的文章,但是它比我在這里更深入地介紹了技術(shù)。Patterson和Waterman描述了問題: 就像阿片類藥物一樣,SIMD的起點(diǎn)足夠純凈。架構(gòu)師將現(xiàn)有的64位寄存器和ALU分為許多8位,16位或32位塊,然后對(duì)其并行進(jìn)行計(jì)算。操作碼提供數(shù)據(jù)寬度和操作。數(shù)據(jù)傳輸只是單個(gè)64位寄存器的加載和存儲(chǔ)。誰會(huì)反對(duì)呢? 但這是一種推托: 自1978年以來,IA-32指令集已從80條增加到大約1400條,主要是由SIMD推動(dòng)的。 因此,x86和ARM的規(guī)范和手冊(cè)非常龐大。相反,您可以在一張雙面紙上獲得所有最重要的RISC-V指令的概述。這對(duì)于那些用硅制造芯片的人以及那些制造匯編器和編譯器的人有影響,對(duì)SIMD指令的支持通常會(huì)在以后添加。 RISC-V的設(shè)計(jì)者希望有一個(gè)實(shí)用的CPU指令集,該指令集可用于長時(shí)間教學(xué)。在RISC-V到來之前,他們使用的是在商業(yè)界不再受追捧的MIPS,因?yàn)閷W(xué)術(shù)界不希望其教學(xué)是基于行業(yè)的潮流和炒作。大學(xué)強(qiáng)調(diào)教學(xué)知識(shí)的持久性。這就是為什么他們更愿意講授數(shù)據(jù)結(jié)構(gòu)和算法,而不是說如何使用調(diào)試工具或IDE。 因此,SIMD的發(fā)展是站不住腳的。每隔幾年就會(huì)有新的說明。沒有什么是非常耐用的。因此,Patterson 和Waterman認(rèn)為:
向量架構(gòu)是一種較舊的,更優(yōu)雅的利用數(shù)據(jù)級(jí)并行性的替代方法。向量計(jì)算機(jī)從主存儲(chǔ)器中收集對(duì)象,并將其放入順序的長向量寄存器中。
回到Cray樣式的矢量處理?
因此,RISC-V設(shè)計(jì)人員使用矢量指令而不是SIMD指令創(chuàng)建了擴(kuò)展。但是,如果這樣好得多,為什么它沒有更早發(fā)生,為什么矢量處理在過去就不受歡迎了?
在回答任何一個(gè)問題之前,我們需要實(shí)際了解什么是向量處理。
向量與SIMD處理
理解差異的最好方法是查看一些C / C ++代碼。在SIMD中,向量是固定大小的,并被視為固定長度類型,如下所示: struct Vec3 {
int x0;
int x1;
int x2;
};
struct Vec4 {
int x0;
int x1;
int x2;
int x4;
}; 這意味著矢量加法函數(shù)處理的是固定長度: Vec3 vadd3(Vec3 v1,Vec3 v2){
return Vec3(v1.x0 + v2.x0,
v1.x1 + v2.x1,
v1.x2 + v2.x2);
} 我們能想到的Vec3,Vec4并vadd3為現(xiàn)有的硬件。但是,開發(fā)人員需要更高級(jí)別的功能,并且可以組合以下操作以創(chuàng)建更多通用功能: void vadd(int v1 [],int v2 [],int n,int v3 []){
int i = 0;
while(i 《n){
u = Vec3(v1 [i],v1 [i + 1],v1 [i + 3]);
v = Vec3(v2 [i],v2 [i + 1],v2 [i + 3]);
w = vadd3(u,v); //efficient vector operation
v3 [i] = w.x0;
v3 [i + 1] = w.x1;
v3 [i + 2] = w.x2;
i+ = 3;
}
} 您可以將其視為偽代碼(pseudo-code)。要了解的一點(diǎn)是,您可以在處理較小固定長度向量的函數(shù)上構(gòu)建功能來處理任何長度的向量。 像使用老式Cray超級(jí)計(jì)算機(jī)一樣進(jìn)行矢量處理,這實(shí)際上是RISC-V人士提出的,就是將諸如vadd硬件之類的功能。
那這實(shí)際上是什么意思呢?
向量處理在硬件中的實(shí)現(xiàn)
這意味著在內(nèi)部,我們?nèi)匀豢梢栽谀承┕潭▽挾仁噶可线\(yùn)行SIMD單元。但這不是匯編程序員所看到的。相反,就像vadd匯編代碼一樣,指令也不限于特定的向量長度。程序員可以將特殊的狀態(tài)和控制寄存器(CSR)設(shè)置為他或她正在操作的向量的長度。這有點(diǎn)類似于如何vadd使用n參數(shù)指定向量的長度。
相反,我們得到了一些很長的向量。比SIMD指令使用的向量寄存器長得多。可能有數(shù)百個(gè)合適的元素。像我們對(duì)SIMD樣式矢量寄存器所做的那樣,為這些元素的每一個(gè)創(chuàng)建ALU和乘法器是不切實(shí)際的。
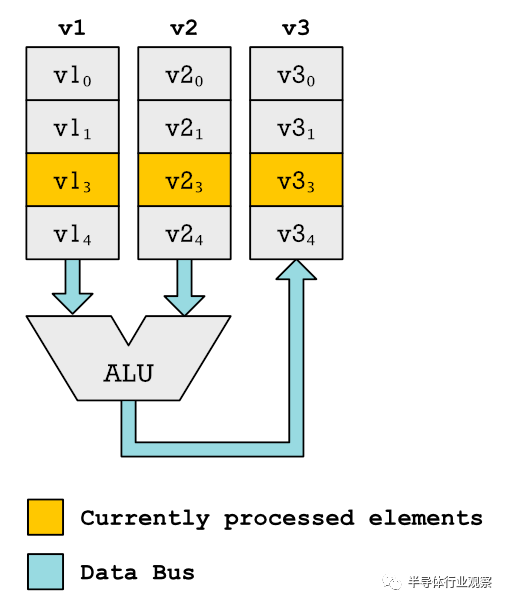
向量單元按順序處理元素。當(dāng)前處理的元素將突出顯示。在這里,我們將單對(duì)元素。但實(shí)際上,我們使用多個(gè)ALU并按順序處理多個(gè)元素。 相反,當(dāng)CPU讀取一個(gè)vadd函數(shù)時(shí)會(huì)發(fā)生什么,就像我們?cè)趥未a示例中所做的那樣,它開始遍歷這些大寄存器。這是一個(gè)代碼示例: vsetlen r1 , 16, 120 ; 120 element vector. Each element 16-bit
vload v1, 14 ; Load 120 elements start at address 14
vload v2, 134 ; Load elements starting at address 123
vadd v3, v1, v2 ; Add all 120 elements.
vstore v3, 254 ; Store result at address 254 在執(zhí)行操作之前,必須通過設(shè)置向量中元素的數(shù)量以及每個(gè)元素的大小和類型來配置向量處理器。在此示例中,我將其簡化。我們一直在處理帶符號(hào)整數(shù)。但是在實(shí)際系統(tǒng)中,您必須能夠指定要處理的是浮點(diǎn)數(shù)以及帶符號(hào)的還是無符號(hào)的整數(shù)。 vload做什么操作取決于配置。在這種情況下,我們將加載120個(gè)元素,每個(gè)元素距離內(nèi)存16位寬。 vadd遍歷v1andv2向量寄存器中的所有120個(gè)元素。將每個(gè)元素相加并將結(jié)果寫入寄存器 v3。為了更好地了解它是如何工作的,讓我們討論一下所涉及的時(shí)鐘周期數(shù)。 時(shí)鐘周期是微處理器執(zhí)行一項(xiàng)簡單任務(wù)所需要的時(shí)間。解碼指令可能需要一個(gè)時(shí)鐘周期,一個(gè)指令要添加兩個(gè)數(shù)字。諸如乘法之類的更復(fù)雜的操作可能需要多個(gè)時(shí)鐘周期。 因?yàn)槲覀冇兴膫€(gè)ALU,所以我們可以在每個(gè)時(shí)鐘周期執(zhí)行四個(gè)加法運(yùn)算。這意味著vadd需要30個(gè)時(shí)鐘周期才能完成: 120/4 = 30
這聽起來可能不太好。為什么不使用直接循環(huán)并執(zhí)行這些SIMD指令的匯編程序直接執(zhí)行相同操作。為什么要在硬件中實(shí)施必須迭代執(zhí)行的操作?
向量處理的好處
一個(gè)主要的好處是我們需要小得多的程序。我們不需要編寫具有多個(gè)加載,比較和循環(huán)的程序。
Patterson和Waterman在他們的文章“ SIMD指令被認(rèn)為有害”中提供了一個(gè)示例程序進(jìn)行比較。這是他們對(duì)程序大小差異的觀察。 MIPS-32 MSA和IA-32 AVX2的代碼的三分之二至四分之三是SIMD開銷,用于為主SIMD循環(huán)準(zhǔn)備數(shù)據(jù)或在n不等于n的倍數(shù)時(shí)處理邊緣元素。SIMD寄存器中的浮點(diǎn)數(shù)。 但是更重要的是,對(duì)于矢量指令,您不必繼續(xù)重復(fù)解碼相同的指令。執(zhí)行重復(fù)的條件分支等。在代碼示例中,Patterson和Waterman使用它們來表示,與使用矢量指令的RISC-V版本相比,SIMD程序需要執(zhí)行的指令多10至20倍。 原因是SIMD循環(huán)每次迭代僅處理2到4個(gè)元素。在矢量代碼中,假定硬件支持具有64個(gè)元素的矢量寄存器。因此,每次迭代處理了64個(gè)元素的批處理,從而減少了需要迭代的次數(shù)。 可以在運(yùn)行時(shí)查詢最大向量長度,因此不需要對(duì)64個(gè)元素的大批量大小進(jìn)行硬編碼。 解碼較少的指令會(huì)減少功耗,因?yàn)榻獯a和獲取會(huì)消耗大量功耗。
此外,我們實(shí)現(xiàn)了所有好的界面設(shè)計(jì)應(yīng)努力實(shí)現(xiàn)的目標(biāo):隱藏實(shí)現(xiàn)細(xì)節(jié)。為什么這么重要?看看USB插頭嗎?當(dāng)USB標(biāo)準(zhǔn)無需物理改變插頭即可提高性能時(shí),我們會(huì)喜歡它。
從USB-1到USB-3,我們避免更改接口。我們可以使用相同的電纜。同樣,Vector擴(kuò)展使我們可以在進(jìn)行內(nèi)部改進(jìn)時(shí)保持相同的界面。
隨著芯片技術(shù)的改進(jìn),您可以使用更多的晶體管。您可以使用它來添加更多的ALU和乘數(shù),以并行處理更多的矢量元素。對(duì)于具有SIMD指令的CPU,這意味著您現(xiàn)在可以處理幾百條針對(duì)新向量長度的新指令。我們也必須重新編譯程序才能處理這些新添加的長向量,以提高性能。
但使用RISC-V則不需要這樣,因?yàn)榇a看起來一樣。唯一的改變是,vadd它將以更少的周期完成,因?yàn)樗哂懈蟮腟IMD單元,從而可以在每個(gè)時(shí)鐘周期內(nèi)處理更大數(shù)量的元素。
如果矢量機(jī)如此厲害,為什么會(huì)被拋棄?
我想David Patterson在他先前的著作中沒有很好地解釋這個(gè)問題——為什么Cray矢量處理機(jī)基本上已經(jīng)淘汰了。
卡車還是賽車?
要了解原因,我們需要了解權(quán)衡。如果您想將最大數(shù)量的貨物從A運(yùn)到B,則基本上可以采用兩種方式。使用賽車以少量貨物來回快速行駛。 或者,您可以使用大型的緩慢移動(dòng)的卡車,該卡車可以拖運(yùn)大量貨物但移動(dòng)緩慢。
快速傳送少量數(shù)據(jù)或緩慢傳送大量數(shù)據(jù)? 大多數(shù)通用軟件是由賽車提供。通用程序不容易序列化。他們需要什么數(shù)據(jù)取決于執(zhí)行的指令,有各種各樣的條件分支和對(duì)內(nèi)存的隨機(jī)訪問要考慮在內(nèi)。每次訪問倉庫(內(nèi)存)時(shí),您根本無法拿起很多貨物(數(shù)據(jù)),因?yàn)槟恢澜酉聛硇枰裁础?因此,通用微處理器往往具有較大的快速存儲(chǔ)器高速緩存,因此CPU可以在需要時(shí)快速獲得所需的信息(與汽車類似)。 相反,矢量處理器的工作方式與GPU非常相似。他們沒有處理通用程序。通常,它們用于科學(xué)軟件,例如天氣模擬,在其中您需要大量可以并行處理的數(shù)據(jù)。GPU同樣可以并行處理大量像素或坐標(biāo)。 因此,您無需快速移動(dòng),因?yàn)槊看味伎梢允叭〈罅繑?shù)據(jù)。因此,GPU和矢量機(jī)通常具有較低的時(shí)鐘頻率和較小的緩存。相反,他們的內(nèi)存系統(tǒng)設(shè)置為并行獲取大量數(shù)據(jù)。換句話說,它們像卡車一樣移動(dòng)貨物來移動(dòng)數(shù)據(jù)。一次很多,但是很慢。
向量機(jī)實(shí)際上在pipelines中具有數(shù)據(jù),因?yàn)榭梢灶A(yù)測下一個(gè)數(shù)據(jù)是什么。
向量處理器很小
當(dāng)然,您可以提高矢量處理器的時(shí)鐘頻率,并為它們提供大量的高速緩存,但是,當(dāng)您獲得更多更好的選擇時(shí),又有什么意義呢?您不用花在緩存上的所有晶體管,就可以用來擴(kuò)展并行處理更多元素的能力。此外,瓦特使用率和健康水平也不隨時(shí)鐘頻率線性增長。它增長更快。因此,要降低熱預(yù)算,必須降低時(shí)鐘頻率。
如果查看Esperanto Technologies的ET-SoC-1解決方案,您會(huì)發(fā)現(xiàn)所有這些折衷考慮在內(nèi)。就晶體管數(shù)量而言,它們的SoC大小與Apple的M1 SoC相同。然而,矢量處理內(nèi)核所需的硅要少得多,因?yàn)槲覀兊哪繕?biāo)不是高單線程性能。M1 Firestorm核心是怪獸,因?yàn)樗鼈兪褂昧嗽S多晶體管來實(shí)現(xiàn)亂序執(zhí)行(OoOE),分支預(yù)測,深層流水線和許多其他功能,以使單線程性能讓你大跌眼鏡。
板載6個(gè)ET-SoC-1芯片 圖片:Enterpriseai 相比之下,ET-SoC-1可以容納1000個(gè)以上實(shí)現(xiàn)Vector指令擴(kuò)展的RISC-V CPU內(nèi)核。這是因?yàn)槭噶刻幚砥骺梢宰龅梅浅P。?/p>
緩存需求最少。
它們是有序的,因此您可以通過不實(shí)現(xiàn)復(fù)雜的OoOE控制器邏輯來節(jié)省大量芯片。
較低的時(shí)鐘頻率簡化了很多。
因此,如果您可以將問題描述為對(duì)大向量的運(yùn)算,那么通過進(jìn)行向量機(jī)設(shè)計(jì),使用相同數(shù)量的晶體管,您可以獲得一些瘋狂的性能提升。
向量處理器吸引了通用計(jì)算
但是這里有一個(gè)關(guān)鍵:如果無法以這種方式表示您的程序,那么您就陷入了一個(gè)痛苦的世界。執(zhí)行不能在大向量上運(yùn)行的常規(guī)桌面軟件將獲得可怕的性能。為什么?
您的時(shí)鐘頻率低。您沒有OoOE,并且您的緩存很小。因此,每條需要獲取一些數(shù)據(jù)的指令都必須等待很長時(shí)間。這是CrY的問題。它們根本無法用于通用計(jì)算。由于使用其他傳統(tǒng)CPU的其他市場價(jià)格便宜,而且Cray計(jì)算機(jī)上運(yùn)行的許多軟件都可以通過在多核計(jì)算機(jī)上運(yùn)行,使用群集或其他方法來很好地完成。 當(dāng)常規(guī)計(jì)算機(jī)開始需要矢量處理時(shí),這是用于多媒體應(yīng)用程序的。圖像處理之類的東西。在這種情況下,您通常使用小的短向量。然后,SIMD指令是顯而易見的簡單解決方案。他們非常直接地進(jìn)行設(shè)置。只需添加一些向量寄存器和操作即可。矢量指令需要更多的思考和計(jì)劃。您需要設(shè)置矢量長度和元素類型的方法。在程序之間切換時(shí),大的向量對(duì)于保存和恢復(fù)是不切實(shí)際的。無論如何,這些程序不需要長向量。 因此,與SIMD相比,矢量擴(kuò)展最初沒有明顯的優(yōu)勢。由于矢量處理對(duì)于通用計(jì)算而言不是很好,因此Esperanto 公司開發(fā)的ET-SoC-1例如具有四個(gè)用于通用計(jì)算的RISC-V核心,稱為ET-Maxion。這些更像是M1 Firestorm核心:
更大的緩存
智能分支預(yù)測器
多指令解碼器
亂序執(zhí)行
這些將運(yùn)行操作系統(tǒng)并將工作任務(wù)調(diào)度到帶有矢量擴(kuò)展的較小的RISC-V內(nèi)核(ET-minion)。這可能是架構(gòu)選擇的類型,我們將看到更多:混合使用具有不同強(qiáng)度的不同類型的核心。 通用計(jì)算不能真正受益于擁有大量內(nèi)核。但是,對(duì)于特殊任務(wù),使用非常規(guī)內(nèi)核要比用于通用計(jì)算的大型內(nèi)核好得多。 例如,矢量處理器可以很好地完成所有這些任務(wù):
機(jī)器學(xué)習(xí)
壓縮圖像,壓縮文件等
密碼學(xué)
演講和手寫
聯(lián)網(wǎng)。奇偶校驗(yàn),校驗(yàn)和
數(shù)據(jù)庫。哈希/聯(lián)接
因此,給定X晶體管數(shù)量的預(yù)算,要加快這些任務(wù)的執(zhí)行速度,最好選擇矢量處理器設(shè)計(jì),而不是增加更多的通用內(nèi)核。 在這兩種情況下,我都在談?wù)撎O果如何通過使用專用協(xié)處理器來從其M1芯片中提高速度。這就是這個(gè)意思。原則上,我們可以簡單地將向量擴(kuò)展名添加到任何RISC-V通用CPU中。但是您可以選擇通過以下方式來定制向量處理的方法:刪除大型緩存,將無序執(zhí)行單元踢到路邊,降低時(shí)鐘頻率,使用更簡單的分支預(yù)測器以及擴(kuò)大內(nèi)存訪問范圍(讀取更多數(shù)據(jù))一次插入數(shù)據(jù)管道)。 如果這樣做的話,您將獲得功耗更低得多的小得多的芯片,與用于快速通用計(jì)算的胖芯片相比,矢量處理的性能可能更好。由于它體積小,功耗低,因此可以有很多。
實(shí)際上,這只是驗(yàn)證我先前制作的專用協(xié)處理器案例的另一種方法。
為什么矢量處理器再次出現(xiàn)問題
因此,這使我們可以完整地回到我們一直以來一直試圖回答的內(nèi)容。為什么矢量指令現(xiàn)在有意義,但過去卻被放棄了。
該問題已得到部分回答。SIMD方法使我們陷入困境。但是更重要的是,我們的計(jì)算機(jī)現(xiàn)在正在執(zhí)行更多各種各樣的任務(wù)。特別是機(jī)器學(xué)習(xí)已經(jīng)變得非常龐大。這已成為數(shù)據(jù)中心的主要重點(diǎn)。蘋果并非沒有理由在其iPad和iPhone蘋果硅芯片上添加了神經(jīng)引擎。 Google并非毫無理由地使用Tensor處理單元(TPU)在人群中提供了更高速度的機(jī)器學(xué)習(xí)。由于深度學(xué)習(xí)的興起,處理非常大的陣列又重新投入了業(yè)務(wù)。 因此,我認(rèn)為RISC-V將使用Vector擴(kuò)展而不是SIMD擴(kuò)展是非常明智的舉動(dòng)。SIMD誕生于一個(gè)世界,在多媒體環(huán)境中主要需要短向量。我們已經(jīng)不在那個(gè)世界上了。向量擴(kuò)展使用一塊石頭殺死兩只鳥:
矢量指令不會(huì)使ISA膨脹。我們不需要繼續(xù)添加新的。
未來的證據(jù)更多。
添加更多的ALU,乘法器和其他功能單元后,無需重新編譯。
它們是機(jī)器學(xué)習(xí)應(yīng)用程序的絕佳選擇。
對(duì)矢量指令的批評(píng)
當(dāng)然,并不是每個(gè)人都對(duì)我對(duì)矢量指令的熱情滿懷。我們得看一些批評(píng)。經(jīng)常看到的一種指責(zé)是整個(gè)系統(tǒng)更加復(fù)雜,SIMD更加容易。人們認(rèn)為矢量擴(kuò)展將使芯片膨脹。
坦率地說,這不是批評(píng),我們應(yīng)該認(rèn)真對(duì)待。Esperanto 已經(jīng)證明,他們可以使用RISC-V向量擴(kuò)展來制造小型高效芯片。 David Patterson本人并不是該領(lǐng)域的新手。他知道自己在做什么。他不僅是第一個(gè)RISC處理器背后的關(guān)鍵架構(gòu)師之一,而且還積極參與了1990年代另一個(gè)鮮為人知的項(xiàng)目,即IRAM項(xiàng)目。 這在許多方面都是RISC的替代方法,后者采用了矢量處理方法。實(shí)際上,與發(fā)明原始的RISC相比,最后從事矢量處理的RISC-V人士可能會(huì)受到更大的影響。Patterson和其他人開始真正從他們的IRAM項(xiàng)目中相信矢量處理的強(qiáng)大功能和優(yōu)雅。因此,V在RISC-V實(shí)際上代表兩個(gè)5和載體。RISC-V從一開始就被認(rèn)為是用于矢量處理的體系結(jié)構(gòu)。 IRAM項(xiàng)目非常有趣,因?yàn)樗A(yù)示了蘋果M1芯片后來發(fā)生的許多事情。在廣泛討論如何在SoC上使用DRAM及其優(yōu)勢。提示認(rèn)為統(tǒng)一內(nèi)存。
當(dāng)被問及使用向量處理指令的復(fù)雜性和難度時(shí),David Patterson寫道:沒那么難。我們很早以前在IRAM項(xiàng)目中通過并行執(zhí)行較小的數(shù)據(jù)類型來做到這一點(diǎn)。許多人都在使用這種矢量架構(gòu)樣式來構(gòu)建RISC-V處理器。
在向量函數(shù)之間傳遞數(shù)據(jù)
但是,這也許是更嚴(yán)重的批評(píng)。您可以輕松創(chuàng)建固定長度的具體矢量類型和元素類型,并可以在高級(jí)語言中使用。因此,您可以創(chuàng)建一系列函數(shù),這些函數(shù)可以獲取通過向量寄存器傳遞參數(shù)數(shù)據(jù)。因此,我們可以組合多個(gè)功能,其中所有數(shù)據(jù)都使用矢量寄存器在它們之間傳遞。
例如,如果函數(shù)看起來像這樣,我們可以很容易地與其他帶有Vec3參數(shù)的函數(shù)一起使用: Vec3 vadd3(Vec3 v1,Vec3 v2){
return Vec3(v1.x0 + v2.x0,
v1.x1 + v2.x1,
v1.x2 + v2.x2);
} 如果矢量擴(kuò)展名要求您將數(shù)據(jù)作為數(shù)組或指針傳遞給內(nèi)存,則要困難得多。這意味著兩個(gè)向量函數(shù)之間的數(shù)據(jù)將始終必須通過拋出主存儲(chǔ)器來交換數(shù)據(jù)。這肯定會(huì)減慢速度。這是爭論的重點(diǎn): 您提倡的方法不能完全做到這一點(diǎn)。您無法為采用或返回千字節(jié)數(shù)據(jù)的函數(shù)發(fā)明合理的調(diào)用約定。當(dāng)前的體系結(jié)構(gòu)都在這些向量寄存器中傳遞參數(shù)和返回值,因?yàn)樗鼈兊挠?jì)數(shù)和大小是ISA的一部分,即穩(wěn)定且為編譯器所知。 但是,我可以看到一些解決方法。例如,使用GPU編程,人們使用可以任意長度的CUDA陣列。這些實(shí)際上只是包裝處理程序到圖形內(nèi)存中的數(shù)組。我不明白為什么向量寄存器不能以相同的方式工作。您只需使用特殊的數(shù)組類型作為這些向量函數(shù)的參數(shù)。
如果這不可能,那么“ Just in Time Compilation”實(shí)際上可能是一個(gè)不錯(cuò)的選擇。例如,使用Julia編程語言,即時(shí)編譯器通常會(huì)消除不同函數(shù)調(diào)用之間的接口。可以想象一個(gè)JIT以這種方式將幾個(gè)基于向量的功能合并在一起,以避免在所有處理完成之前將結(jié)果寫到內(nèi)存中。 但老實(shí)說,這是我希望看到的。 為什么不使用GPU? 我看到的最后一個(gè)批評(píng)是,如果需要對(duì)長向量進(jìn)行運(yùn)算,則應(yīng)該只使用GPU。這里的想法是,如果您需要對(duì)大數(shù)據(jù)塊進(jìn)行操作,那么您還可能會(huì)承受將大數(shù)據(jù)塊傳輸?shù)紾PU進(jìn)行處理然后讀取結(jié)果的性能損失。 有兩種看待批評(píng)的方法。如果向量擴(kuò)展名僅用于較臃腫的通用CPU,它將有一些優(yōu)點(diǎn)。無論如何,為快速處理標(biāo)量數(shù)據(jù)而優(yōu)化的CPU都將在向量處理方面具有劣勢。
但是,我們不能假設(shè)這一點(diǎn)。正如我們從Esperanto中所看到的,設(shè)計(jì)專門的RISC-V處理器(例如ET-Minion)是完全有效的,ET-Minion是用于快速矢量處理的定制模式。 而且,如果我們相信Esperanto公司的主張,他們的解決方案將勝過基于GPU的機(jī)器學(xué)習(xí)解決方案。 我通常會(huì)在很多RISC-V批評(píng)中看到這個(gè)問題。它常常會(huì)遺漏標(biāo)記,因?yàn)樗俣ㄎ覀円恢痹谡務(wù)撚糜谶\(yùn)行Windows,Linux或macOS的通用處理器。但是,RISC-V應(yīng)該適用于從微控制器,協(xié)處理器到超級(jí)計(jì)算機(jī)的任何事物。
矢量擴(kuò)展對(duì)于通用CPU仍然有意義,僅因?yàn)樗[藏了矢量處理的實(shí)現(xiàn)細(xì)節(jié)。SIMD不能做的事情引起了很多ISA膨脹。
通用指令集的好處
即使專用處理器更適合長矢量,這并不意味著通用CPU和專用內(nèi)核不能同時(shí)是具有矢量擴(kuò)展的RISC-V處理器。
Playstation 3新穎的單元體系結(jié)構(gòu)的問題之一是通用PowerPC CPU無法與功能更有限的協(xié)處理器共享指令集。實(shí)際上,PS3架構(gòu)與Esperanto ET-SoC-1有很多共同點(diǎn)。PS3不是使用ET-Maxion內(nèi)核作為通用CPU,而是使用PowerPC CPU來運(yùn)行操作系統(tǒng)。PS3使用協(xié)同處理元素(SPE)代替了ET-Minion核心來處理面向矢量的主要工作量。 這是早期嘗試做M1今天正在做的事情以及ET-SoC-1將來可能做的事情的嘗試。 盡管寫了無數(shù)關(guān)于PS3失敗的頁面,但提到的一個(gè)原因是中央處理器和SPE沒有共享指令集。
原文標(biāo)題:深入淺出RISC-V “V”向量擴(kuò)展
文章出處:【微信公眾號(hào):FPGA之家】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7430瀏覽量
87735 -
RISC-V
+關(guān)注
關(guān)注
44文章
2233瀏覽量
46045
原文標(biāo)題:深入淺出RISC-V “V”向量擴(kuò)展
文章出處:【微信號(hào):zhuyandz,微信公眾號(hào):FPGA之家】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
RISC-V,即將進(jìn)入應(yīng)用的爆發(fā)期
加入全球 RISC-V Advocate 行列,共筑 RISC-V 的未來 !

RISC-V Summit China 2024 青稞RISC-V+接口PHY,賦能RISC-V高效落地

2024 RISC-V 中國峰會(huì):華秋電子助力RISC-V生態(tài)!

risc-v的發(fā)展歷史
rIsc-v的缺的是什么?
淺析RISC-V領(lǐng)先ARM的優(yōu)勢
有系統(tǒng)的RISC-V 教程嗎?
【RISC-V人才行】走進(jìn)國家超級(jí)計(jì)算深圳中心(深圳云計(jì)算中心)
RISC-V有哪些優(yōu)點(diǎn)和缺點(diǎn)
RISC-V有哪些優(yōu)缺點(diǎn)?是堅(jiān)持ARM方向還是投入risc-V的懷抱?
解鎖RISC-V技術(shù)力量丨曹英杰:RISC-V與大模型探索






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論