 計算機中的高速緩存詳解
計算機中的高速緩存詳解
1. 什么是緩存??緩存又叫高速緩存,是計算機存儲器中的一種,本質上和硬盤是一樣的,都是用來存儲數據和指令的 。它們最大的區別在于讀取速度的不同。程序一般是放在內存中的,當CPU執行程序的時候,執行完一條指令需要從內存中讀取下一條指令,讀取內存中的指令要花費100000個時鐘周期(緩存讀取速度為200個時鐘周期,相差500倍),如果每次都從內存中取指令,CPU運行時將花費大量的時間在讀取指令上。這顯然是一種資源浪費。
如何解決這個問題呢?有人肯定會問,直接把程序存儲在緩存中不行嗎?
答案是可以的。但是,緩存的造價太貴了。具體如下圖所示。以2015年的售價為例,1GB SRAM的價格大約為327680美元,而1GB 普通硬盤的價格僅僅為0.03美元。用緩存來存儲程序成本太高了,得不償失。
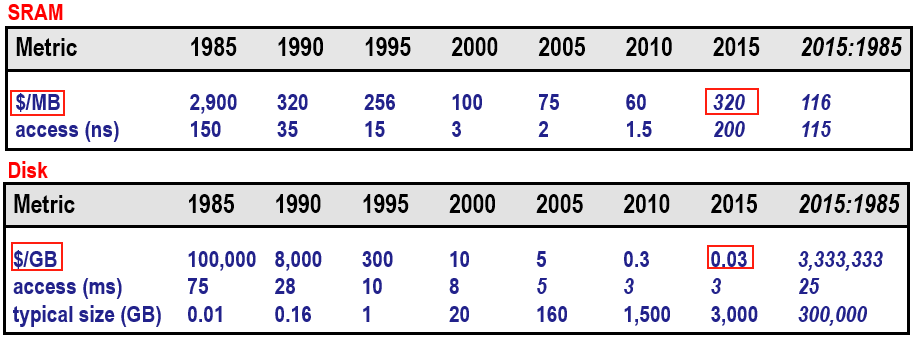
SRAM和DISK價格比較
于是,有人就提出了這樣一種方法,在CPU和內存之間添加一個高速內存, 這個高速內存容量小,只用來存儲CPU執行時常用的指令。既保證了硬件成本,又提高了CPU的訪問速度。這個高速內存就是緩存(高速緩存)。
2. 緩存的定義??高速緩存是一個小而快速的存儲設備 ,它作為存儲在更大更慢的設 備中的數據對象的緩沖區域。使用高速緩存的過程稱為緩存 。
具體如下圖所示,主存可以作為一個存儲設備,L3是主存的緩沖區域,從L3存取數據的過程就叫做緩存。
存儲器的層次結構
3. 計算機中的高速緩存3.1 高速緩存相關名詞
如下圖所示,數據總是以塊為單位 在高速緩存和主存之間來回復制。
緩存和內存的數據交換
如果我們的程序請求一個數據字,這個數據字存儲在編號為10的塊中。將分以下幾種情況考慮:
1. 高速緩存行中為空,這叫做冷不命中 。
2.高速緩存中有數據塊,但沒有數據塊10,這叫做緩存不命中 。接下來緩存請求主存將該塊復制到高速緩存,高速緩存接收到之后將替換一個現有的數據塊,從而存儲新的數據塊在高速緩存中。最后,高速緩存將數據塊10返回給CPU。
3. 高速緩存中有數據,將內存中的數據塊放置到高速緩存中時,發生了沖突,這叫做沖突不命中 。
放置策略中最常用的是:第k+1層的塊i必須放在第k層的塊(i mod 4)中。比如,第k+1層的0,4,8,12會映射到第k層的塊0。塊1,5,9,13會映射到塊1。
4. 緩存中有數據塊10,則直接返回給CPU。這叫做緩存命中 。
3.2 計算機中的高速緩存存儲器模型
高速緩存完全由硬件管理,硬件邏輯必須要知道,如何查找緩存中的塊,并確定是否包含特定塊。因此,必須以非常嚴格且簡單的方式去構建高速緩存。在計算機中,高速緩存模型如下圖所示。
計算機中的高速緩存模型
我們可以將高速緩存存儲器視為有個高速緩存組的數組 。每個組包含個高速緩存行 。每個行是由一個字節的數據塊組成的。
一般而言,高速緩存的結構可以用元組(S,E,B,m)來描述。高速緩存的大小(或容量)C指的是所有塊的大小的和。標記位和有效位不包括在內 。因此,C=S×E×B。
每個高速緩存存儲器有m位,可以組成個不同的地址,。每個數據塊由以下三部分構成。
有效位:有效位為t位,t一般為1,指明這個行是否包含有效信息。
標記位:標記位為s位。唯一的標識了存儲在高速緩存中的塊(數組索引)。
塊偏移:數據塊為字節。指明CPU請求的內容在數據塊中的偏移。
地址和計算機緩存模型
下面對以上內容出現的參數做個總結:
參數描述
S=2^s組數
E每個組的行數
B=2^b塊大小(字節)
m=log2(M)物理地址位數
M=2^m內存地址的最大數量
s=log2(S)組索引位數量
b=log2(B)塊偏移位數量
t=m-(s+b)標記位數量
C=B*E*S不包括像有效位和標記位這樣開銷的高速緩存大小(字節)
3.3 計算機中有哪些緩存
下表為現代計算機中用到的各種緩存。
類型緩存什么被緩存在何處延遲(周期數)由誰管理
TLB地址翻譯芯片上的TLB0硬件MMU
L1高速緩存64字節塊芯片上的L1高速緩存4硬件
L2高速緩存64字節塊芯片上的L2高速緩存10硬件
L3高速緩存64字節塊芯片上的L3高速緩存50硬件
虛擬內存4KB頁主存200硬件
緩沖區緩存部分文件主存200OS
磁盤緩存磁盤扇區磁盤控制器100000控制器固件
網絡緩存部分文件本地磁盤10000000NFS客戶
瀏覽器緩存Web頁本地磁盤10000000Web瀏覽器
Web緩存Web頁遠程服務器磁盤1000000000Web代理服務器
3.4 硬件讀取高速緩存的過程
當一條加載指令指示CPU從主存地址A中讀取一個字w時,會將該主存地址A發送到高速緩存中,則高速緩存會根據以下步驟判斷地址A是否命中:
組選擇:根據地址劃分,將中間的s位表示為無符號數作為組的索引 ,可得到該地址對應的組。
行匹配:根據地址劃分,可得到t位的標志位,由于組內的任意一行都可以包含任意映射到該組的數據塊,所以就要線性搜索組中的每一行,判斷是否有和標志位匹配且設置了有效位的行 ,如果存在,則緩存命中,否則緩沖不命中。
字抽取:如果找到了對應的高速緩存行,則可以將b位表示為無符號數作為塊偏移量 ,得到對應位置的字。
當高速緩存命中時,會很快抽取出字w,并將其返回給CPU。如果緩存不命中,CPU會進行等待,高速緩存會向主存請求包含字w的數據塊,當請求的塊從主存到達時,高速緩存會將這個塊保存到它的一個高速緩存行中,然后從被存儲的塊中抽取出字w,將其返回給CPU。
4. 直接映射高速緩存??上面我們介紹了計算機中的高速緩存模型,我們可以根據每個組的高速緩存行數E,將高速緩存分成不同的類型。下面我們看下直接映射高速緩存(E=1)的具體例子。
4.1 組選擇
組選擇示意圖如下所示。假設有 S 組,每組由一行組成,緩存塊為8字節。CPU發出地址要取數據字,高速緩存將該地址分解為三部分,對于圖中的地址來說,塊偏移量為4。組索引是 1 ,粉紅色的為t位標記位。因此,高速緩存提取的組索引為 1,即圖中第二行。
直接映射高速緩存組選擇
4.2 行匹配
然后,檢查地址中的標記位與緩存行中的標記位是否匹配。如果匹配,將進行下一步字選擇。如果不匹配,則表示未命中。在未命中時,高速緩存必須從內存中重新取數據塊, 在行中覆蓋此塊。
直接映射高速緩存行匹配
4.3 字選擇
當標記位匹配時,表示命中,接著檢查地址中的塊偏移為4,即要從緩存行數據塊的第5位開始取值,并返回給CPU。
直接映射高速緩存字選擇
4.4 模擬直接映射緩存
下面,我們模擬下直接映射高速緩存的過程,以便加深理解高速緩存是如何工作的。假設,內存地址為4字節,S=4組,E=1行/組,B=2字節/塊。其結構圖如下所示。
模擬直接映射高速緩存地址結構圖
我們模擬CPU要從高速緩存中讀取地址為0,1,7,8,0的數據。下面是具體的過程。
地址二進制是否命中
0[](t=0,s=00,b=0)
1[](t=0,s=00,b=1)
7[](t=0,s=11,b=1)
8[](t=1,s=00,b=0)
0[](t=00,s=0,b=0)
1. 讀地址0的數據。標記位為0,索引位為00,偏移位為0,塊號為0。緩存行中沒有數據,組0的有效位為0,地址的標記位和組0的標記位不匹配,因此,未命中。然后,高速緩存從內存中取出塊0,塊1, 共2字節,并存儲在組0中。具體如下圖所示。
模擬直接映射高速緩存讀地址0的數據
2. 讀地址1的數據。標記位為0,索引位為00,偏移位為1,塊號1。緩存行中已有數據數據,組0的有效位為1,地址1的標記位和組0的標記位匹配,因此,命中。具體如下圖所示。
模擬直接映射高速緩存讀地址1的數據
3. 讀地址7的數據。標記位為0,索引位為11(3),偏移位為1,塊號為3。緩存行中有數據,組3的有效位為0,地址的標記位和組0的標記位不匹配,因此,未命中。然后,高速緩存從內存中取出塊6,塊7, 共2字節,并存儲在組3中。具體如下圖所示。
模擬直接映射高速緩存讀地址7的數據
4. 讀地址8的數據。標記位為1,索引位為00,偏移位為0,塊號為4。緩存行中有數據,組0的有效位為1,地址的標記位和組0的標記位不匹配,因此,未命中。然后,高速緩存從內存中取出塊8,塊9, 共2字節,并存儲在組0中。具體如下圖所示。
模擬直接映射高速緩存讀地址8的數據
5. 讀地址0的數據。標記位為0,索引位為00,偏移位為0,塊號為0。緩存行中有數據,組0的有效位為1,地址的標記位和組0的標記位不匹配,因此,未命中。然后,高速緩存從內存中取出塊0,塊1, 共2字節,并存儲在組0中。具體如下圖所示。
模擬直接映射高速緩存再次讀地址0的數據
最終結果如下:緩存命中率為20%。
地址二進制是否命中
0[](t=0,s=00,b=0)否
1[](t=0,s=00,b=1)是
7[](t=0,s=11,b=1)否
8[](t=1,s=00,b=0)否
0[](t=00,s=0,b=0)否
注意:塊大小為2字節,所以從內存中取數據總是以偶數倍開始的,所以會看到M[8-9],而不是M[7-8]。
如果你看懂了上述高速緩存的整個過程,考慮下如何編程來模擬高速緩存呢?后面的文章我會詳細講解如何用C語言模擬高速緩存,歡迎關注我的公眾號【嵌入式與Linux那些事】,第一時間獲取更新。
4.5 直接映射高速緩存的缺陷
觀察以上過程其實可以發現,在第5步,讀地址0的數據的時候,我們又得重新從內存中取數據到緩存行中。在讀地址8的數據的時候,M[8-9]替換了緩存行中的M[0-1]。
最主要的原因是每一個組中只允許存放一行緩存。假設,E = 2,每組中有2個緩存行,M[8-9]和M[0-1]就有很大可能同時存在于組0中。我們在第5步訪問時,就不需要重新從內存中取數據了。因此,就有了E = 2的兩路相聯高速緩存。
5. 兩路相聯高速緩存??直接映射高速緩存中沖突不命中造成的問題源于每個組只有一行這個限制。組相聯高速存放松了這條限制,所以每個組都保存有多于一個的高速緩存行。如下圖所示為兩路相聯的高速緩存。
5.1 組選擇
它的組選擇與直接映射高速緩存的組選擇一樣,組索引位標識組。具體如下圖所示,這里不再贅述。
兩路相聯高速緩存組選擇
5.2 行匹配
組相聯高速緩存中的行匹配比直接映射高速緩存中的更復雜,因為它必須每次檢查多個行 的標記位和有效位,以確定所請求的字是否在集合中。具體如下圖所示。
兩路相聯高速緩存行匹配
5.3 字選擇
字選擇的過程和直接映射高速緩存中的方式一樣,這里就不再贅述。
兩路相聯高速緩存字選擇
5.4 模擬兩路相聯高速緩存
下面,我們模擬下兩路相聯高速緩存的過程,以便加深理解高速緩存是如何工作的。假設,內存地址為4字節,S=2組,E=2行/組,B=2字節/塊。其結構圖如下所示。
兩路相聯高速緩存地址結構
我們模擬CPU要從高速緩存中讀取地址為0,1,7,8,0的數據。下面是具體的過程。
地址二進制是否命中
0[] (t=00,s=0,b=0)
1[](t=00,s=0,b=1)
7[](t=01,s=1,b=1)
8[](t=10,s=0,b=0)
0[](t=00,s=0,b=0)
1. 讀地址0的數據。標記位為00,索引位為0,偏移位為0,塊號為0。緩存行中沒有數據,組0的有效位為0,地址的標記位和組0的第一行和第二行的標記位都不匹配,因此,未命中。然后,高速緩存從內存中取出塊0,塊1, 共2字節,并存儲在組0第一行中。具體如下圖所示。
模擬兩路相聯高速緩存讀地址0的數據
2. 讀地址1的數據。標記位為00,索引位為0,偏移位為1,塊號為1。緩存行中已有數據數據,組0的第一行有效位為1,地址1的標記位和組0的第一行標記位匹配,因此,命中。具體如下圖所示。
模擬兩路相聯高速緩存讀地址1的數據
3. 讀地址7的數據。標記位為01,索引位為1,偏移位為1,塊號為1。緩存行中有數據,組1的有效位為0,地址的標記位和組1中的第一行和第二行的標記位不匹配,因此,未命中。然后,高速緩存從內存中取出塊6,塊7, 共2字節,并存儲在組1中。具體如下圖所示。
模擬兩路相聯高速緩存讀地址7的數據
4. 讀地址8的數據。標記位為10,索引位為0,偏移位為0,塊號為0。緩存行中有數據,組0的第一行有效位為1,第二行有效位為0,地址的標記位和組0的第一行和第二行的標記位不匹配,因此,未命中。然后,高速緩存從內存中取出塊8,塊9, 共2字節,并存儲在組0的第二行中。具體如下圖所示。
模擬兩路相聯高速緩存讀地址8的數據
5. 讀地址0的數據。標記位為00,索引位為0,偏移位為0,塊號為0。緩存行中有數據,組0的第一行有效位為1,地址的標記位和組0的第一行的標記位匹配,因此,命中。具體如下圖所示。
模擬兩路相聯高速緩存再次讀地址0的數據地址二進制是否命中
0[] (t=00,s=0,b=0)否
1[](t=00,s=0,b=1)是
7[](t=01,s=1,b=1)否
8[](t=10,s=0,b=0)否
0[](t=00,s=0,b=0)是
兩路相聯高速緩存與直接映射高速緩存相比,在每組中增加了一行,緩存命中率提升了15%。避免了緩存頻繁從內存中存取數據的情況,提高了程序運行速度。
6. 全相聯高速緩存??全相聯高速緩存中的行匹配和字選擇與組相聯高速緩存中的是一樣的,過程就不再贅述,其結構圖如下所示。
全相聯高速緩存結構示意圖
相聯度越高越好嗎?
答案是否定的。較高的相聯度會造成較高的成本。實現難度大,價格昂貴,而且很難使之速度變快。較高的相聯度會增加命中時間,因為復雜性增加了,另外,還會增加不命中處罰,因為選擇犧牲行的復雜性也增加了。
相聯度的選擇最終變成了命中時間和不命中處罰之問的折中。一般來講,高性能系統會為L1高速緩存選擇較低的相聯度(這里的不命中處罰只是幾個周期),而在不命中處罰比較高的較低層上使用比較小的相聯度。例如, Intel Core i7系統中,L和L2高速緩存是8路組相聯的,而L3高速緩存是16路組相聯的。
7. 真實計算機系統中的緩存??在此之前,我們一直假設高速緩存只保存數據。不過,實際上,高速緩存既保存數據,也保存指令。只保存指令的高速緩存稱為 i-cache 。只保存程序數據的高速緩存稱為 d-cache 。既保存指令又包括數據的高速緩存稱為 統一的高速緩存 。
如下圖所示為 Intel Core i7處理器的高速緩存層次結構。每個CPU芯片有四個核。每個核有自己的L1 i-cache, L1 d-cache和L2統一的高速緩存。所有的核共享片上L3統一的高速緩存。其具體參數如下表所示。
真實計算機的緩存模型緩存大小內部結構訪問時間
L132KB8路相聯4時鐘
L2256KB8路相聯10時鐘
L38M16路相聯40-75時鐘
8. 緩存的評價指標??最后介紹下衡量高速緩存性能的一些指標:
8.1 不命中率
在一個程序執行或程序的一部分執行期間,內存引用不命中的比率,它等于: 不命中數量/引用數量。
8.2 命中率
命中的內存引用比率。它等于: 1-不命中率。
8.3 命中時間
從高速緩存傳送一個字到CPU所需的時間,包括組選擇、行確認和字選擇的時間。一般來講,L1緩存的命中時間為:4個時鐘。L2緩存的命中時間為:10個時鐘。
8.4 未命中懲罰
未命中需要的額外時間。對于主存來說,一般為 50 ~ 200個時鐘周期。
舉個例子:
假設緩存命中時間為1個時鐘周期,緩存未命中懲罰為100個時鐘周期。
下面計算下97%緩存命中率和99%的緩存命中率的平均訪問時間為多少?計算公式為命中時間加上未命中處罰乘以百分系數。
97%的命中率:時鐘。
99%的命中率:時鐘。
結論:命中率增加2%,平均訪問時間減少了50%。
9. 總結??計算機中存在著各種各樣的緩存,比如, 文件緩存 把一些需要高速存取的變量緩存在內存中,每次訪問直接讀出即可。 瀏覽器緩存 根據一套與服務器約定的規則進行工作,如果在瀏覽過程中前進或后退時訪問到同一個圖片,這些圖片可以從瀏覽器緩存中調出而即時顯示。數據庫緩存 經常需要從數據庫查詢的數據、或經常更新的數據放入到緩存中,這樣下次查詢時,直接從緩存直接返回,減輕數據庫壓力。
我們了解這么多基本概念有什么用呢?如果我們理解了計算機系統是如何將數據在內存中組織和移動的,那么在寫程序時就可以把數據項存儲在合適的位置,CPU能更快地訪問到它們,提高程序的執行效率。
原文標題:24張圖7000字詳解計算機中的高速緩存
文章出處:【微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
計算機
+關注
關注
19文章
7430瀏覽量
87733 -
緩存
+關注
關注
1文章
233瀏覽量
26649
原文標題:24張圖7000字詳解計算機中的高速緩存
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
TMS320C64x在高性能DSP應用中的高速緩存使用情況

德國建成歐洲首個量子計算機中心
計算機存儲系統的構成
寄存器和高速緩存有什么區別
計算機中總線的作用是什么
邊沿觸發器在計算機中的應用
三態緩沖器在計算機中的應用
DRAM在計算機中的應用
工業計算機與普通計算機的區別
量子計算機——高密度微波互連模組

【量子計算機重構未來 | 閱讀體驗】+ 了解量子疊加原理
一文了解CPU高速緩存





 工商網監
工商網監
評論