 簡單闡述一下計算機視覺的幾大任務!
簡單闡述一下計算機視覺的幾大任務!
計算機視覺的幾大任務:
目標跟蹤、圖像和視頻的生成
這里有一些比較常見的計算機視覺的應用,平時我們也會用到,包括多重的人臉識別,現在有些比較流行的照片應用,不知道大家平時會不會用到,包括比如像 Google photos,基本上傳一張照片上去,它就會對同樣的照片同樣的人物進行歸類,這個也是目前非常常見的一個應用。
中間那個叫 OCR,就是對文本進行掃描和識別,這個技術目前已經比較成熟了。照片上這張是比較老的技術,當時我記得有公司做這個應用,有個掃描筆,掃描一下就變成文字,現在的話,基本上已經不需要這么近的去掃描了,大家只要拍一張照片,如果這張照片是比較清晰的,經過一兩秒鐘,一般我們現在算法就可以直接把它轉換成文字,而且準確率相當高,所以圖片上的這種 OCR 是一個過時的技術。
右下角是車牌檢測,開車的時候不小心壓到線了,闖紅燈了,收到一張罰單,這個怎么做到呢?也是計算機視覺的功勞,它們可以很容易的就去識別這個照片里的車牌,甚至車牌有一定的污損,經過計算機視覺的增強都是可以把它給可以優化回來的,所以這個技術也是比較實用的。
01. 圖像識別
車牌識別、人臉識別
02. 目標檢測
行人檢測、車輛檢測
03. 圖像分割
圖像語義分割、個體分割=檢測+分割
視頻分割:
04. 目標跟蹤
下面聊幾個比較有挑戰性的計算機視覺的任務。首先是目標跟蹤,目標跟蹤就是我們在連續的圖片或者視頻流里面,想要去追蹤某一個指定的對象,這個聽起來對人來說是一個非常容易的任務,大家只要目不轉睛盯著一個東西,沒有人能逃脫我們的視野。
實際上對機器來說,這是一個很有挑戰性的任務,為什么呢?因為機器在追蹤對象的時候,大部分會使用最原始的一些方法,采取一些對目標圖片進行形變的匹配,就是比較早期的計算機識別的方法,而這個方法在實際應用中間是非常難以實現的,為什么?因為需要跟蹤的對象,它由于角度、光照、遮擋的原因包括運動的時候,它會變得模糊,還有相似背景的干擾,所以我們很難利用模板匹配這種方法去追蹤這個對象。
一個人他面對你、背對你、側對你,可能景象完全不一樣,這種情況下,同樣一個模板是無法匹配的,所以說,很有潛力但也很有挑戰性,因為目前對象追蹤的算法完全沒有達到人臉識別的準確率,還有很多的人在不斷的努力去尋找新的方法去提升。
右邊也是一個例子,就是簡單的一個對我們頭部的追蹤,也是非常有挑戰性的,因為我們頭可以旋轉,尺度也可能發生變化,用手去遮擋,這都給匹配造成很大的難度。
05. 多模態問題
后面還有一些比較有挑戰性的計算機視覺任務,我們歸類把它們叫做多模態問題,其中包括 VQA,這是什么意思?這個就是說給定一張圖片,我們可以任意的去問它一些問題,一般是比較直接的一些問題,Who、Where、How,類似這些問題,或者這個多模態的模型,要能夠根據圖片的真實信息去回答我們的問題。
舉個例子,比如底下圖片中間有兩張是小朋友的,計算機視覺看到這張圖片的時候它要把其中所有的對象全部分割出來,要了解每個對象是什么,知道它們其中的聯系。比如左邊的小朋友在喝奶,如果把他的奶瓶分出來以后,它必須要知道這個小朋友在喝奶,這個關系也是很重要的。
屏幕上的問題是“Where is the child sitting?”,這個問題的復雜度就比單純的只是解析圖像要復雜的多。他需要把里面所有信息的全部解析出來,并且能準確的去關聯他們的關系,同時這個模型還要能夠理解我們問這個問題到底是個什么用意,他要知道問的是位置,而且這個對象是這個小孩,所以這個是包含著計算機視覺加上自然語言識別,兩種這種技術的相結合,所以才叫多模態問題,模態指的是像語音,文字,圖像,語音,這種幾種模態放在一起就叫多模態問題。
右邊一個例子是 Caption Generation,現在非常流行的研究的領域,給定一張圖片,然后對圖片里面的東西進行描述。
編輯:jq
-
人臉識別
+關注
關注
76文章
4005瀏覽量
81768 -
OCR
+關注
關注
0文章
144瀏覽量
16329
發布評論請先 登錄
相關推薦
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
計算機視覺怎么給圖像分類
計算機視覺的主要研究方向

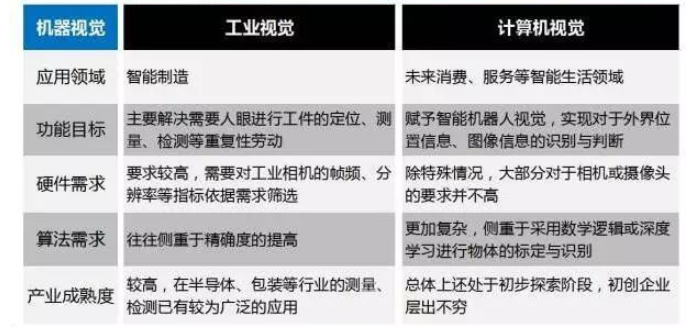
工業視覺與計算機視覺的區別





 工商網監
工商網監
評論