") 使神經(jīng)網(wǎng)絡(luò)在智能手機上實時運行的技術(shù)
使神經(jīng)網(wǎng)絡(luò)在智能手機上實時運行的技術(shù)
計算機具有高儲量的硬盤和強大的CPU和GPU。但是智能手機卻沒有,為了彌補這個缺陷,我們需要技巧來讓智能手機高效地運行深度學(xué)習(xí)應(yīng)用程序。
介紹
深度學(xué)習(xí)是一個令人難以置信的靈活且強大的技術(shù),但運行的神經(jīng)網(wǎng)絡(luò)可以在計算方面需要非常大的電力,且對磁盤空間也有要求。這通常不是云空間能夠解決的問題,一般都需要大硬盤服務(wù)器上運行驅(qū)動器和多個GPU模塊。
不幸的是,在移動設(shè)備上運行神經(jīng)網(wǎng)絡(luò)并不容易。事實上,即使智能手機變得越來越強大,它們?nèi)匀痪哂杏邢薜挠嬎隳芰Α㈦姵貕勖涂捎么疟P空間,尤其是對于我們希望保持盡可能輕的應(yīng)用程序。這樣做可以實現(xiàn)更快的下載速度、更小的更新時間和更長的電池使用時間,這些都是用戶所欣賞的。
為了執(zhí)行圖像分類、人像模式攝影、文本預(yù)測以及其他幾十項任務(wù),智能手機需要使用技巧來快速,準(zhǔn)確地運行神經(jīng)網(wǎng)絡(luò),而無需使用太多的磁盤空間。
在這篇文章中,我們將看到一些最強大的技術(shù),使神經(jīng)網(wǎng)絡(luò)能夠在手機上實時運行。
使神經(jīng)網(wǎng)絡(luò)變得更小更快的技術(shù)
基本上,我們對三個指標(biāo)感興趣:模型的準(zhǔn)確性、速度以及它在手機上占用的空間量。由于沒有免費午餐這樣的好事,所以我們必須做出妥協(xié)。
對于大多數(shù)技術(shù),我們會密切關(guān)注我們的指標(biāo)并尋找我們稱之為飽和點的東西。這是一個指標(biāo)的收益停止而其他指標(biāo)損失的時刻。通過在飽和點之前保持優(yōu)化值,我們可以獲得最佳值。
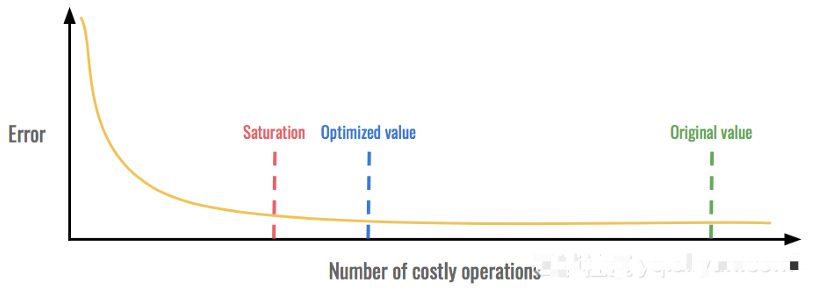
在這個例子中,我們可以在不增加錯誤的情況下顯著減少昂貴的操作次數(shù)。但是,在飽和點附近,錯誤變得太高而無法接受。
1. 避免完全連接的層
完全連接的層是神經(jīng)網(wǎng)絡(luò)最常見的組成部分之一,它們曾經(jīng)創(chuàng)造奇跡。然而,由于每個神經(jīng)元都連接到前一層的所有神經(jīng)元,因此它們需要存儲和更新眾多參數(shù)。這對速度和磁盤空間是不利的。
卷積層是利用輸入中的局部一致性(通常是圖像)的層。每個神經(jīng)元不再連接到前一層的所有神經(jīng)元。這有助于在保持高精度的同時減少連接/重量的數(shù)量。
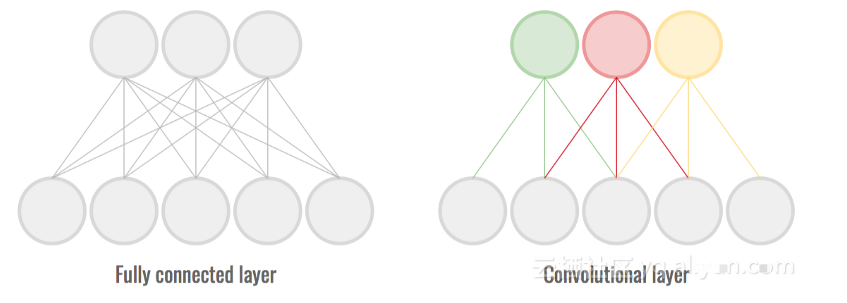
完全連接層中的連接/權(quán)重比卷積層中多得多。
使用很少或沒有完全連接的層可以減少模型的大小,同時保持高精度。這可以提高速度和磁盤使用率。
在上面的配置中,具有1024個輸入和512個輸出的完全連接層,這個完全連接層大約有500k個參數(shù)。如果是具有相同特征和32個卷積層特征映射,那么它將只具有50K參數(shù),這是一個10倍的改進(jìn)!
2. 減少通道數(shù)量和內(nèi)核大小
這一步代表了模型復(fù)雜性和速度之間的一個非常直接的折衷。卷積層中有許多通道允許網(wǎng)絡(luò)提取相關(guān)信息,但需付出代價。刪除一些這樣的功能是節(jié)省空間并使模型變得更快的簡單方法。
我們可以用卷積運算的接受域來做同樣的事情。通過減小內(nèi)核大小,卷積對本地模式的了解較少,但涉及的參數(shù)較少。
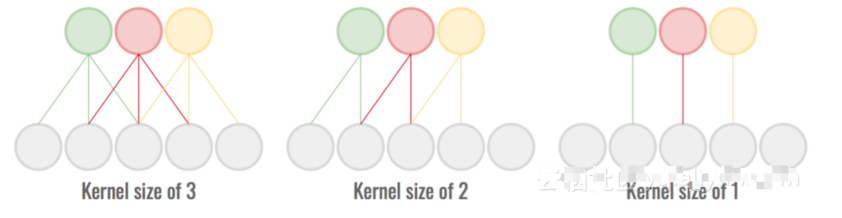
較小的接受區(qū)域/內(nèi)核大小計算起來更便宜,但傳達(dá)的信息較少。
在這兩種情況下,通過查找飽和點來選擇地圖/內(nèi)核大小的數(shù)量,以便精度不會降低太多。
3. 優(yōu)化縮減采樣(Optimizing the downsampling)
對于固定數(shù)量的層和固定數(shù)量的池操作,神經(jīng)網(wǎng)絡(luò)可以表現(xiàn)得非常不同。這來自于一個事實,即表示該數(shù)據(jù)以及計算量的依賴于在池操作完成:
當(dāng)池化操作提早完成時,數(shù)據(jù)的維度會降低。越小的維度意味著網(wǎng)絡(luò)處理速度越快,但意味著信息量越少,準(zhǔn)確性越差。
當(dāng)聯(lián)網(wǎng)操作在網(wǎng)絡(luò)后期完成時,大部分信息都會保留下來,從而具有很高的準(zhǔn)確性。然而,這也意味著計算是在具有許多維度的對象上進(jìn)行的,并且在計算上更昂貴。
在整個神經(jīng)網(wǎng)絡(luò)中均勻分布下采樣作為一個經(jīng)驗有效的架構(gòu),并在準(zhǔn)確性和速度之間提供了一個很好的平衡。
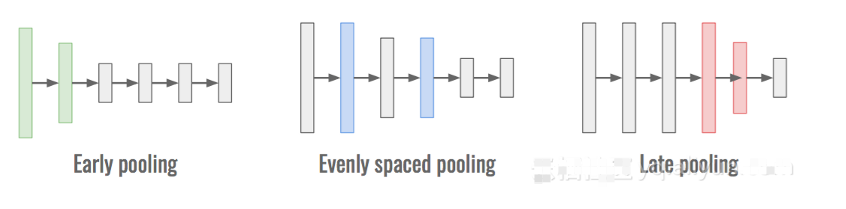
早期的池化速度很快,晚期的池化是準(zhǔn)確的,均勻間隔的池化是有點兩者。
4. 修剪重量(Pruning the weights)
在訓(xùn)練完成的神經(jīng)網(wǎng)絡(luò)中,一些權(quán)重對神經(jīng)元的激活起著強烈作用,而另一些權(quán)重幾乎不影響結(jié)果。盡管如此,我們?nèi)匀粚@些弱權(quán)重做一些計算。
修剪是完全去除最小量級連接的過程,以便我們可以跳過計算。這可能會降低了準(zhǔn)確性,但使網(wǎng)絡(luò)更輕、更快。我們需要找到飽和點,以便盡可能多地刪除連接,而不會過多地?fù)p害準(zhǔn)確性。
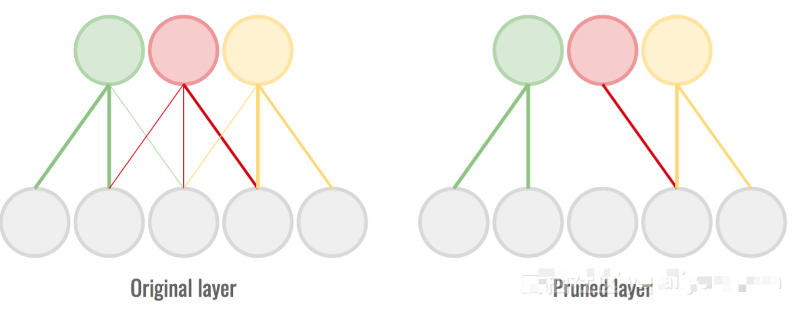
除去最薄弱的連接以節(jié)省計算時間和空間。
5. 量化權(quán)重(Quantizing the weights)
為了將網(wǎng)絡(luò)保存在磁盤上,我們需要記錄網(wǎng)絡(luò)中每個單一權(quán)重的值。這意味著為每個參數(shù)保存一個浮點數(shù),這代表了磁盤上占用的大量空間。作為參考,在C中,一個浮點占用4個字節(jié),即32個比特。一個參數(shù)在數(shù)億的網(wǎng)絡(luò)(例如GoogLe-Net或VGG-16)可以輕松達(dá)到數(shù)百兆,這在移動設(shè)備上是不可接受的。
為了保持網(wǎng)絡(luò)足跡盡可能小,一種方法是通過量化它們來降低權(quán)重的分辨率。在這個過程中,我們改變了數(shù)字的表示形式,使其不再能夠取得任何價值,但相當(dāng)受限于一部分?jǐn)?shù)值。這使我們只能存儲一次量化值,然后參考網(wǎng)絡(luò)的權(quán)重。
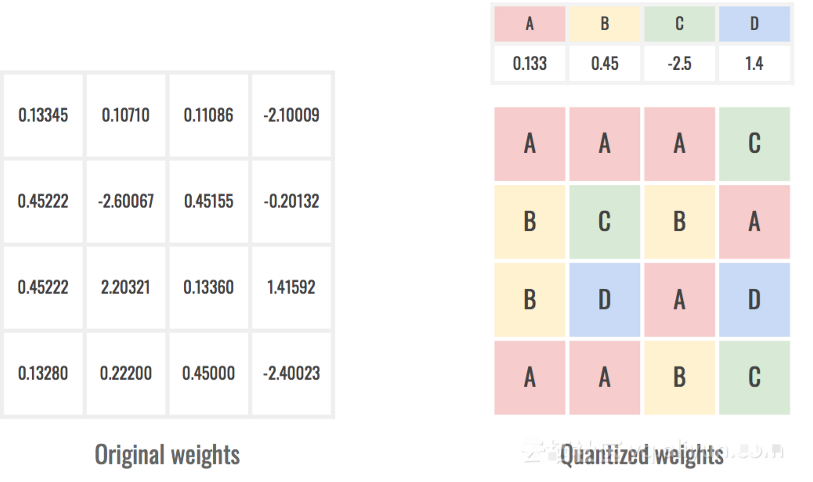
量化權(quán)重存儲鍵而不是浮動。
我們將再次通過查找飽和點來確定要使用多少個值。更多的值意味著更高的準(zhǔn)確性,但也是更大的儲存空間。例如,通過使用256個量化值,每個權(quán)重可以僅使用1個字節(jié) 即 8個比特來引用。與之前(32位)相比,我們已將大小除以4!
6. 編碼模型的表示
我們已經(jīng)處理了關(guān)于權(quán)重的一些事情,但是我們可以進(jìn)一步改進(jìn)網(wǎng)絡(luò)!這個技巧依賴于權(quán)重不均勻分布的事實。一旦量化,我們就沒有相同數(shù)量的權(quán)值來承載每個量化值。這意味著在我們的模型表示中,一些引用會比其他引用更頻繁地出現(xiàn),我們可以利用它!
霍夫曼編碼是這個問題的完美解決方案。它通過將最小占用空間的密鑰歸屬到最常用的值以及最小占用空間的值來實現(xiàn)。這有助于減小設(shè)備上模型的誤差,最好的結(jié)果是精度沒有損失。
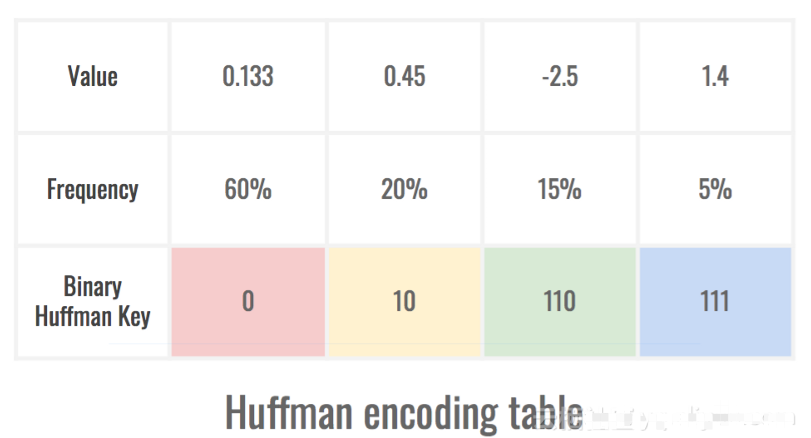
最頻繁的符號僅使用1 位的空間,而最不頻繁的使用3 位。這是由后者很少出現(xiàn)在表示中的事實所平衡的。
這個簡單的技巧使我們能夠進(jìn)一步縮小神經(jīng)網(wǎng)絡(luò)占用的空間,通常約為30%。
注意:量化和編碼對于網(wǎng)絡(luò)中的每一層都是不同的,從而提供更大的靈活性
7. 糾正準(zhǔn)確度損失(Correctiong the accuracy loss)
使用我們的技巧,我們的神經(jīng)網(wǎng)絡(luò)已經(jīng)變得非常粗糙了。我們刪除了弱連接(修剪),甚至改變了一些權(quán)重(量化)。雖然這使得網(wǎng)絡(luò)超級輕巧,而且速度非常快,但其準(zhǔn)確度并非如此。
為了解決這個問題,我們需要在每一步迭代地重新訓(xùn)練網(wǎng)絡(luò)。這只是意味著在修剪或量化權(quán)重后,我們需要再次訓(xùn)練網(wǎng)絡(luò),以便它能夠適應(yīng)變化并重復(fù)這個過程,直到權(quán)重停止變化太多。
結(jié)論
雖然智能手機不具備老式桌面計算機的磁盤空間、計算能力或電池壽命,但它們?nèi)匀皇巧疃葘W(xué)習(xí)應(yīng)用程序非常好的目標(biāo)。借助少數(shù)技巧,并以幾個百分點的精度為代價,現(xiàn)在可以在這些多功能手持設(shè)備上運行強大的神經(jīng)網(wǎng)絡(luò)。這為數(shù)以千計的激動人心的應(yīng)用打開了大門。
責(zé)任編輯:lq6
-
智能手機
+關(guān)注
關(guān)注
66文章
18431瀏覽量
179860 -
cpu
+關(guān)注
關(guān)注
68文章
10825瀏覽量
211151 -
gpu
+關(guān)注
關(guān)注
28文章
4701瀏覽量
128707 -
計算機
+關(guān)注
關(guān)注
19文章
7421瀏覽量
87718
發(fā)布評論請先 登錄
相關(guān)推薦
卷積神經(jīng)網(wǎng)絡(luò)與傳統(tǒng)神經(jīng)網(wǎng)絡(luò)的比較
LSTM神經(jīng)網(wǎng)絡(luò)在語音識別中的應(yīng)用實例
如何在FPGA上實現(xiàn)神經(jīng)網(wǎng)絡(luò)
BP神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)的關(guān)系
全連接前饋神經(jīng)網(wǎng)絡(luò)與前饋神經(jīng)網(wǎng)絡(luò)的比較
rnn是遞歸神經(jīng)網(wǎng)絡(luò)還是循環(huán)神經(jīng)網(wǎng)絡(luò)
遞歸神經(jīng)網(wǎng)絡(luò)是循環(huán)神經(jīng)網(wǎng)絡(luò)嗎
深度神經(jīng)網(wǎng)絡(luò)與基本神經(jīng)網(wǎng)絡(luò)的區(qū)別
人工智能神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)是什么
反向傳播神經(jīng)網(wǎng)絡(luò)和bp神經(jīng)網(wǎng)絡(luò)的區(qū)別
神經(jīng)網(wǎng)絡(luò)和人工智能的關(guān)系是什么
bp神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)區(qū)別是什么
卷積神經(jīng)網(wǎng)絡(luò)和bp神經(jīng)網(wǎng)絡(luò)的區(qū)別
神經(jīng)網(wǎng)絡(luò)在圖像識別中的應(yīng)用
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論