 深入分析同步阻塞網絡IO的內部實現詳解
深入分析同步阻塞網絡IO的內部實現詳解
在網絡開發模型中,有一種非常易于開發同學使用的方式,那就是同步阻塞的網絡 IO(在 Java 中習慣叫 BIO)。
例如我們想請求服務器上的一段數據,那么 C 語言的一段代碼 demo 大概是下面這樣:
int main()
{
int sk = socket(AF_INET, SOCK_STREAM, 0);
connect(sk, 。..)
recv(sk, 。..)
}
但是在高并發的服務器開發中,這種網絡 IO 的性能奇差。因為
1.進程在 recv 的時候大概率會被阻塞掉,導致一次進程切換
2.當連接上數據就緒的時候進程又會被喚醒,又是一次進程切換
3.一個進程同時只能等待一條連接,如果有很多并發,則需要很多進程
如果用一句話來概括,那就是:同步阻塞網絡 IO 是高性能網絡開發路上的絆腳石! 俗話說得好,知己知彼方能百戰百勝。所以我們今天先不講優化,只深入分析同步阻塞網絡 IO 的內部實現。
在上面的 demo 中雖然只是簡單的兩三行代碼,但實際上用戶進程和內核配合做了非常多的工作。先是用戶進程發起創建 socket 的指令,然后切換到內核態完成了內核對象的初始化。接下來 Linux 在數據包的接收上,是硬中斷和 ksoftirqd 進程在進行處理。當 ksoftirqd 進程處理完以后,再通知到相關的用戶進程。
從用戶進程創建 socket,到一個網絡包抵達網卡到被用戶進程接收到,總體上的流程圖如下:
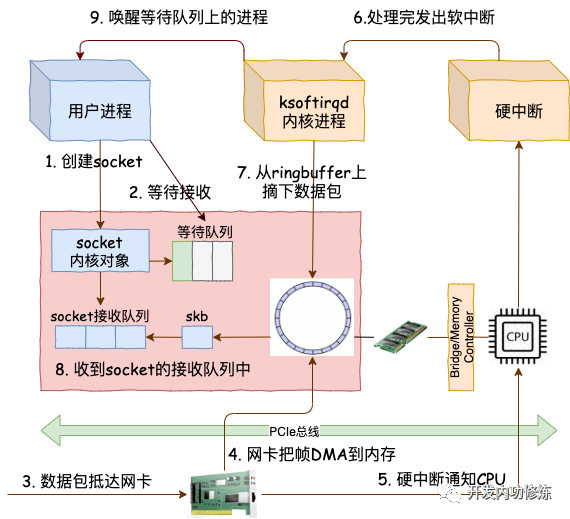
我們今天用圖解加源碼分析的方式來詳細拆解一下上面的每一個步驟,來看一下在內核里是它們是怎么實現的。閱讀完本文,你將深刻地理解在同步阻塞的網絡 IO 性能低下的原因!
一、創建一個 socket
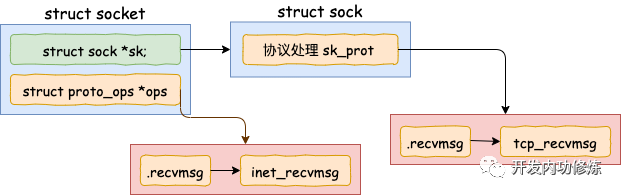
開篇源碼中的 socket 函數調用執行完以后,內核在內部創建了一系列的 socket 相關的內核對象(是的,不是只有一個)。它們互相之間的關系如圖。當然了,這個對象比圖示的還要更復雜。我只在圖中把和今天的主題相關的內容展現了出來。
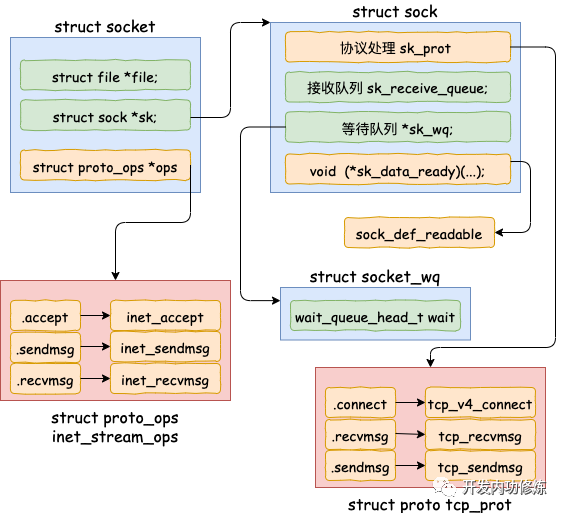
我們來翻翻源碼,看下上面的結構是如何被創造出來的。
//file:net/socket.c
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
。..。..
retval = sock_create(family, type, protocol, &sock);
}
sock_create 是創建 socket 的主要位置。其中 sock_create 又調用了 __sock_create。
//file:net/socket.c
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
struct socket *sock;
const struct net_proto_family *pf;
。..。..
//分配 socket 對象
sock = sock_alloc();
//獲得每個協議族的操作表
pf = rcu_dereference(net_families[family]);
//調用每個協議族的創建函數, 對于 AF_INET 對應的是
err = pf-》create(net, sock, protocol, kern);
}
在 __sock_create 里,首先調用 sock_alloc 來分配一個 struct sock 對象。接著在獲取協議族的操作函數表,并調用其 create 方法。對于 AF_INET 協議族來說,執行到的是 inet_create 方法。
//file:net/ipv4/af_inet.c
tatic int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
//查找對應的協議,對于TCP SOCK_STREAM 就是獲取到了
//static struct inet_protosw inetsw_array[] =
//{
// {
// .type = SOCK_STREAM,
// .protocol = IPPROTO_TCP,
// .prot = &tcp_prot,
// .ops = &inet_stream_ops,
// .no_check = 0,
// .flags = INET_PROTOSW_PERMANENT |
// INET_PROTOSW_ICSK,
// },
//}
list_for_each_entry_rcu(answer, &inetsw[sock-》type], list) {
//將 inet_stream_ops 賦到 socket-》ops 上
sock-》ops = answer-》ops;
//獲得 tcp_prot
answer_prot = answer-》prot;
//分配 sock 對象, 并把 tcp_prot 賦到 sock-》sk_prot 上
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot);
//對 sock 對象進行初始化
sock_init_data(sock, sk);
}
在 inet_create 中,根據類型 SOCK_STREAM 查找到對于 tcp 定義的操作方法實現集合 inet_stream_ops 和 tcp_prot。并把它們分別設置到 socket-》ops 和 sock-》sk_prot 上。
我們再往下看到了 sock_init_data。在這個方法中將 sock 中的 sk_data_ready 函數指針進行了初始化,設置為默認 sock_def_readable()。

//file: net/core/sock.c
void sock_init_data(struct socket *sock, struct sock *sk)
{
sk-》sk_data_ready = sock_def_readable;
sk-》sk_write_space = sock_def_write_space;
sk-》sk_error_report = sock_def_error_report;
}
當軟中斷上收到數據包時會通過調用 sk_data_ready 函數指針(實際被設置成了 sock_def_readable()) 來喚醒在 sock 上等待的進程。這個咱們后面介紹軟中斷的時候再說,這里記住這個就行了。
至此,一個 tcp對象,確切地說是 AF_INET 協議族下 SOCK_STREAM對象就算是創建完成了。這里花費了一次 socket 系統調用的開銷
二、等待接收消息
接著我們來看 recv 函數依賴的底層實現。首先通過 strace 命令跟蹤,可以看到 clib 庫函數 recv 會執行到 recvfrom 系統調用。
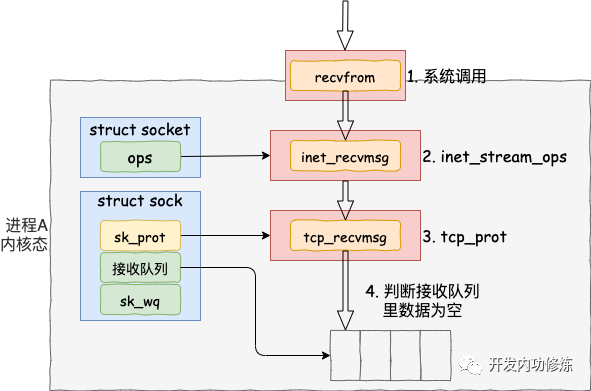
進入系統調用后,用戶進程就進入到了內核態,通過執行一系列的內核協議層函數,然后到 socket 對象的接收隊列中查看是否有數據,沒有的話就把自己添加到 socket 對應的等待隊列里。最后讓出CPU,操作系統會選擇下一個就緒狀態的進程來執行。整個流程圖如下:
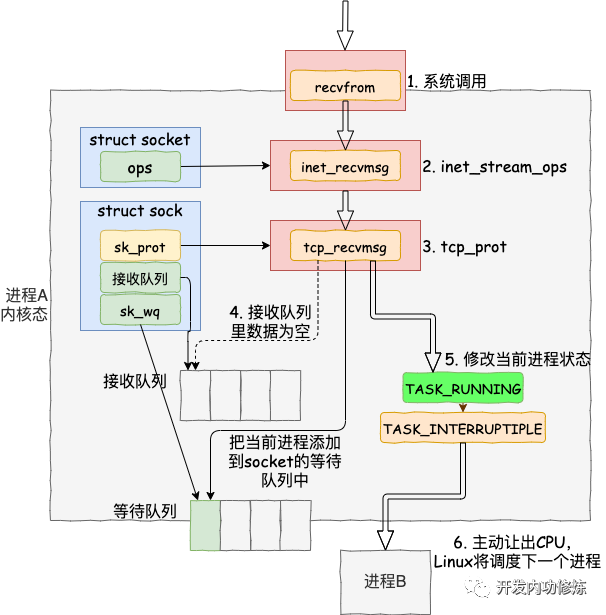
看完了整個流程圖,接下來讓我們根據源碼來看更詳細的細節。其中我們今天要關注的重點是 recvfrom 最后是怎么把自己的進程給阻塞掉的(假如我們沒有使用 O_NONBLOCK 標記)。
//file: net/socket.c
SYSCALL_DEFINE6(recvfrom, int, fd, void __user *, ubuf, size_t, size,
unsigned int, flags, struct sockaddr __user *, addr,
int __user *, addr_len)
{
struct socket *sock;
//根據用戶傳入的 fd 找到 socket 對象
sock = sockfd_lookup_light(fd, &err, &fput_needed);
。..。..
err = sock_recvmsg(sock, &msg, size, flags);
。..。..
}
sock_recvmsg ==》 __sock_recvmsg =》 __sock_recvmsg_nosec
static inline int __sock_recvmsg_nosec(struct kiocb *iocb, struct socket *sock,
struct msghdr *msg, size_t size, int flags)
{
。..。..
return sock-》ops-》recvmsg(iocb, sock, msg, size, flags);
}
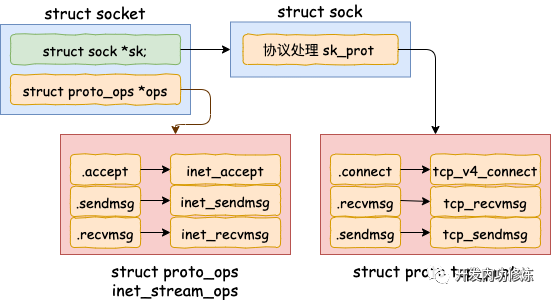
調用 socket 對象 ops 里的 recvmsg, 回憶我們上面的 socket 對象圖,從圖中可以看到 recvmsg 指向的是 inet_recvmsg 方法。
//file: net/ipv4/af_inet.c
int inet_recvmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,
size_t size, int flags)
{
。..
err = sk-》sk_prot-》recvmsg(iocb, sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
這里又遇到一個函數指針,這次調用的是 socket 對象里的 sk_prot 下面的 recvmsg方法。同上,得出這個 recvmsg 方法對應的是 tcp_recvmsg 方法。
//file: net/ipv4/tcp.c
int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t len, int nonblock, int flags, int *addr_len)
{
int copied = 0;
。..
do {
//遍歷接收隊列接收數據
skb_queue_walk(&sk-》sk_receive_queue, skb) {
。..
}
。..
}
if (copied 》= target) {
release_sock(sk);
lock_sock(sk);
} else //沒有收到足夠數據,啟用 sk_wait_data 阻塞當前進程
sk_wait_data(sk, &timeo);
}
終于看到了我們想要看的東西,skb_queue_walk 是在訪問 sock 對象下面的接收隊列了。
如果沒有收到數據,或者收到不足夠多,則調用 sk_wait_data 把當前進程阻塞掉。
//file: net/core/sock.c
int sk_wait_data(struct sock *sk, long *timeo)
{
//當前進程(current)關聯到所定義的等待隊列項上
DEFINE_WAIT(wait);
// 調用 sk_sleep 獲取 sock 對象下的 wait
// 并準備掛起,將進程狀態設置為可打斷 INTERRUPTIBLE
prepare_to_wait(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE);
set_bit(SOCK_ASYNC_WAITDATA, &sk-》sk_socket-》flags);
// 通過調用schedule_timeout讓出CPU,然后進行睡眠
rc = sk_wait_event(sk, timeo, !skb_queue_empty(&sk-》sk_receive_queue));
。..
我們再來詳細看下 sk_wait_data 是怎么把當前進程給阻塞掉的。
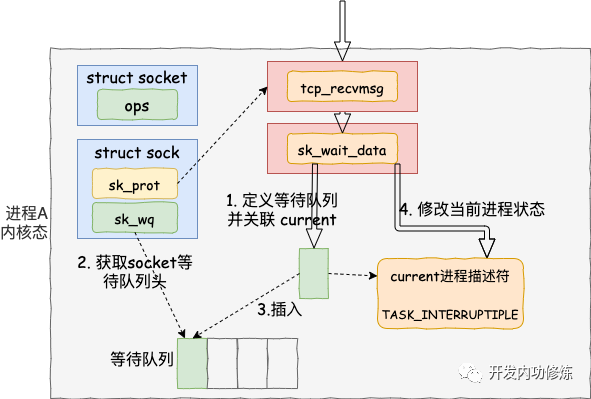
首先在 DEFINE_WAIT 宏下,定義了一個等待隊列項 wait。在這個新的等待隊列項上,注冊了回調函數 autoremove_wake_function,并把當前進程描述符 current 關聯到其 .private成員上。
//file: include/linux/wait.h
#define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function)
#define DEFINE_WAIT_FUNC(name, function)
wait_queue_t name = {
.private = current,
.func = function,
.task_list = LIST_HEAD_INIT((name).task_list),
}
緊接著在 sk_wait_data 中 調用 sk_sleep 獲取 sock 對象下的等待隊列列表頭 wait_queue_head_t。sk_sleep 源代碼如下:
//file: include/net/sock.h
static inline wait_queue_head_t *sk_sleep(struct sock *sk)
{
BUILD_BUG_ON(offsetof(struct socket_wq, wait) != 0);
return &rcu_dereference_raw(sk-》sk_wq)-》wait;
}
接著調用 prepare_to_wait 來把新定義的等待隊列項 wait 插入到 sock 對象的等待隊列下。
//file: kernel/wait.c
void
prepare_to_wait(wait_queue_head_t *q, wait_queue_t *wait, int state)
{
unsigned long flags;
wait-》flags &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q-》lock, flags);
if (list_empty(&wait-》task_list))
__add_wait_queue(q, wait);
set_current_state(state);
spin_unlock_irqrestore(&q-》lock, flags);
}
這樣后面當內核收完數據產生就緒時間的時候,就可以查找 socket 等待隊列上的等待項,進而就可以找到回調函數和在等待該 socket 就緒事件的進程了。
最后再調用 sk_wait_event 讓出 CPU,進程將進入睡眠狀態,這會導致一次進程上下文的開銷。
接下來的小節里我們將能看到進程是如何被喚醒的了。
三、軟中斷模塊
接著我們再轉換一下視角,來看負責接收和處理數據包的軟中斷這邊。關于網絡包到網卡后是怎么被網卡接收,最后在交由軟中斷處理的,這里就不多贅述了。感興趣的請看之前的文章《圖解Linux網絡包接收過程》。我們今天直接從 tcp 協議的接收函數 tcp_v4_rcv 看起。
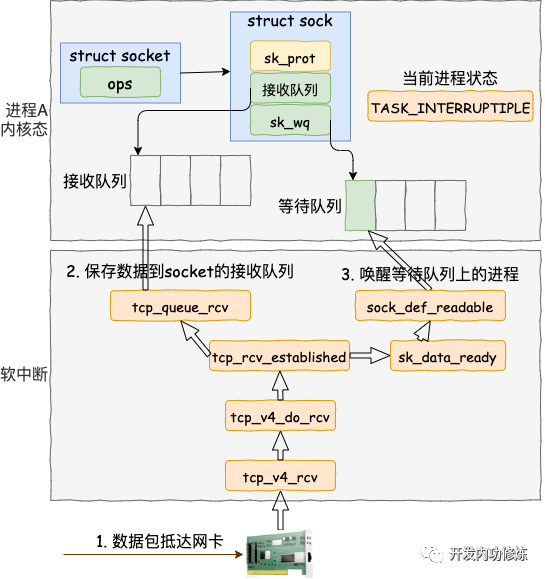
軟中斷(也就是 Linux 里的 ksoftirqd 進程)里收到數據包以后,發現是 tcp 的包的話就會執行到 tcp_v4_rcv 函數。接著走,如果是 ESTABLISH 狀態下的數據包,則最終會把數據拆出來放到對應 socket 的接收隊列中。然后調用 sk_data_ready 來喚醒用戶進程。
我們看更詳細一點的代碼:
// file: net/ipv4/tcp_ipv4.c
int tcp_v4_rcv(struct sk_buff *skb)
{
。..。..
th = tcp_hdr(skb); //獲取tcp header
iph = ip_hdr(skb); //獲取ip header
//根據數據包 header 中的 ip、端口信息查找到對應的socket
sk = __inet_lookup_skb(&tcp_hashinfo, skb, th-》source, th-》dest);
。..。..
//socket 未被用戶鎖定
if (!sock_owned_by_user(sk)) {
{
if (!tcp_prequeue(sk, skb))
ret = tcp_v4_do_rcv(sk, skb);
}
}
}
在 tcp_v4_rcv 中首先根據收到的網絡包的 header 里的 source 和 dest 信息來在本機上查詢對應的 socket。找到以后,我們直接進入接收的主體函數 tcp_v4_do_rcv 來看。
//file: net/ipv4/tcp_ipv4.c
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
if (sk-》sk_state == TCP_ESTABLISHED) {
//執行連接狀態下的數據處理
if (tcp_rcv_established(sk, skb, tcp_hdr(skb), skb-》len)) {
rsk = sk;
goto reset;
}
return 0;
}
//其它非 ESTABLISH 狀態的數據包處理
。..。..
}
我們假設處理的是 ESTABLISH 狀態下的包,這樣就又進入 tcp_rcv_established 函數中進行處理。
//file: net/ipv4/tcp_input.c
int tcp_rcv_established(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th, unsigned int len)
{
。..。..
//接收數據到隊列中
eaten = tcp_queue_rcv(sk, skb, tcp_header_len,
&fragstolen);
//數據 ready,喚醒 socket 上阻塞掉的進程
sk-》sk_data_ready(sk, 0);
在 tcp_rcv_established 中通過調用 tcp_queue_rcv 函數中完成了將接收數據放到 socket 的接收隊列上。
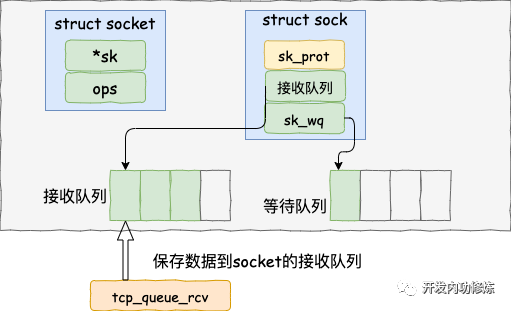
如下源碼所示
//file: net/ipv4/tcp_input.c
static int __must_check tcp_queue_rcv(struct sock *sk, struct sk_buff *skb, int hdrlen,
bool *fragstolen)
{
//把接收到的數據放到 socket 的接收隊列的尾部
if (!eaten) {
__skb_queue_tail(&sk-》sk_receive_queue, skb);
skb_set_owner_r(skb, sk);
}
return eaten;
}
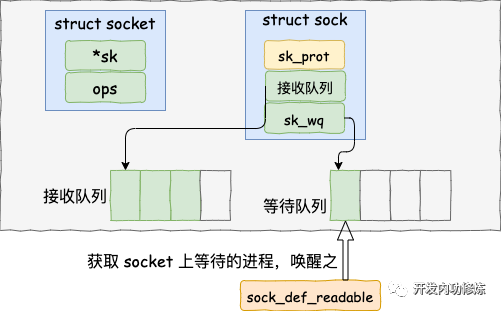
調用 tcp_queue_rcv 接收完成之后,接著再調用 sk_data_ready 來喚醒在socket上等待的用戶進程。 這又是一個函數指針。回想上面我們在 創建 socket 流程里執行到的 sock_init_data 函數,在這個函數里已經把 sk_data_ready 設置成 sock_def_readable 函數了(可以ctrl + f 搜索前文)。它是默認的數據就緒處理函數。
//file: net/core/sock.c
static void sock_def_readable(struct sock *sk, int len)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk-》sk_wq);
//有進程在此 socket 的等待隊列
if (wq_has_sleeper(wq))
//喚醒等待隊列上的進程
wake_up_interruptible_sync_poll(&wq-》wait, POLLIN | POLLPRI |
POLLRDNORM | POLLRDBAND);
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
rcu_read_unlock();
}
在 sock_def_readable 中再一次訪問到了 sock-》sk_wq 下的wait。回憶下我們前面調用 recvfrom 執行的最后,通過 DEFINE_WAIT(wait) 將當前進程關聯的等待隊列添加到 sock-》sk_wq 下的 wait 里了。
那接下來就是調用 wake_up_interruptible_sync_poll 來喚醒在 socket 上因為等待數據而被阻塞掉的進程了。
//file: include/linux/wait.h
#define wake_up_interruptible_sync_poll(x, m)
__wake_up_sync_key((x), TASK_INTERRUPTIBLE, 1, (void *) (m))
//file: kernel/sched/core.c
void __wake_up_sync_key(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, void *key)
{
unsigned long flags;
int wake_flags = WF_SYNC;
if (unlikely(!q))
return;
if (unlikely(!nr_exclusive))
wake_flags = 0;
spin_lock_irqsave(&q-》lock, flags);
__wake_up_common(q, mode, nr_exclusive, wake_flags, key);
spin_unlock_irqrestore(&q-》lock, flags);
}
__wake_up_common 實現喚醒。這里注意下, 該函數調用是參數 nr_exclusive 傳入的是 1,這里指的是即使是有多個進程都阻塞在同一個 socket 上,也只喚醒 1 個進程。其作用是為了避免驚群。
//file: kernel/sched/core.c
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q-》task_list, task_list) {
unsigned flags = curr-》flags;
if (curr-》func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
在 __wake_up_common 中找出一個等待隊列項 curr,然后調用其 curr-》func。回憶我們前面在 recv 函數執行的時候,使用 DEFINE_WAIT() 定義等待隊列項的細節,內核把 curr-》func 設置成了 autoremove_wake_function。
//file: include/linux/wait.h
#define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function)
#define DEFINE_WAIT_FUNC(name, function)
wait_queue_t name = {
.private = current,
.func = function,
.task_list = LIST_HEAD_INIT((name).task_list),
}
在 autoremove_wake_function 中,調用了 default_wake_function。
//file: kernel/sched/core.c
int default_wake_function(wait_queue_t *curr, unsigned mode, int wake_flags,
void *key)
{
return try_to_wake_up(curr-》private, mode, wake_flags);
}
調用 try_to_wake_up 時傳入的 task_struct 是 curr-》private。這個就是當時因為等待而被阻塞的進程項。當這個函數執行完的時候,在 socket 上等待而被阻塞的進程就被推入到可運行隊列里了,這又將是一次進程上下文切換的開銷。
小結
好了,我們把上面的流程總結一下。內核在通知網絡包的運行環境分兩部分:
第一部分是我們自己代碼所在的進程,我們調用的 socket() 函數會進入內核態創建必要內核對象。recv() 函數在進入內核態以后負責查看接收隊列,以及在沒有數據可處理的時候把當前進程阻塞掉,讓出 CPU。
第二部分是硬中斷、軟中斷上下文(系統進程 ksoftirqd)。在這些組件中,將包處理完后會放到 socket 的接收隊列中。然后再根據 socket 內核對象找到其等待隊列中正在因為等待而被阻塞掉的進程,然后把它喚醒。
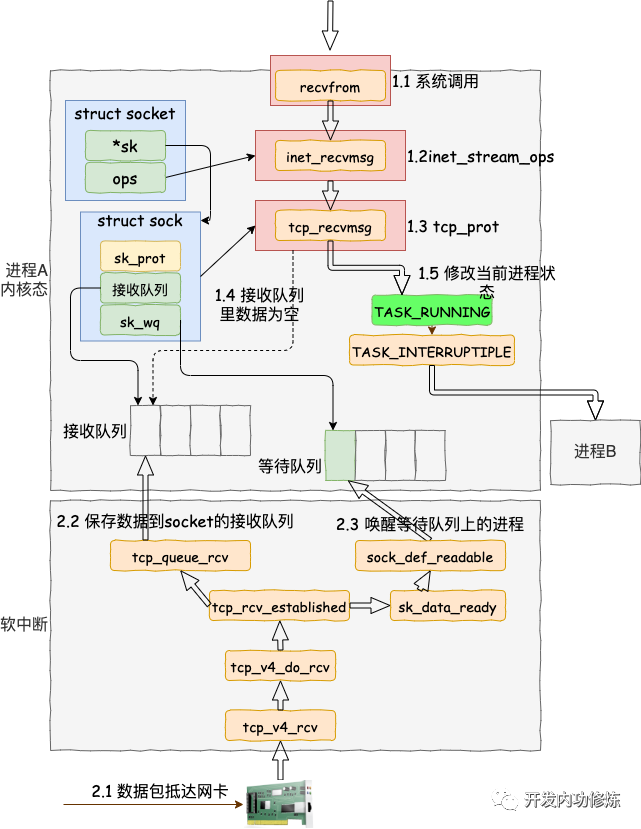
每次一個進程專門為了等一個 socket 上的數據就得被從 CPU 上拿下來。然后再換上另一個進程。等到數據 ready 了,睡眠的進程又會被喚醒。總共兩次進程上下文切換開銷,根據之前的測試來看,每一次切換大約是 3-5 us(微秒)左右。如果是網絡 IO 密集型的應用的話,CPU 就不停地做進程切換這種無用功。
在服務端角色上,這種模式完全沒辦法使用。因為這種簡單模型里的 socket 和進程是一對一的。我們現在要在單臺機器上承載成千上萬,甚至十幾、上百萬的用戶連接請求。如果用上面的方式,那就得為每個用戶請求都創建一個進程。相信你在無論多原始的服務器網絡編程里,都沒見過有人這么干吧。
如果讓我給它起一個名字的話,它就叫單路不復用(飛哥自創名詞)。那么有沒有更高效的網絡 IO 模型呢?當然有,那就是你所熟知的 select、poll 和 epoll了。下次飛哥再開始拆解 epoll 的實現源碼,敬請期待!
這種模式在客戶端角色上,現在還存在使用的情形。因為你的進程可能確實得等 Mysql 的數據返回成功之后,才能渲染頁面返回給用戶,否則啥也干不了。
注意一下,我說的是角色,不是具體的機器。例如對于你的 php/java/golang 接口機,你接收用戶請求的時候,你是服務端角色。但當你再請求 redis 的時候,就變為客戶端角色了。
不過現在有一些封裝的很好的網絡框架例如 Sogou Workflow,Golang 的 net 包等在網絡客戶端角色上也早已摒棄了這種低效的模式!
編輯:lyn
-
Socket
+關注
關注
0文章
211瀏覽量
34637 -
代碼
+關注
關注
30文章
4753瀏覽量
68368 -
BIO
+關注
關注
0文章
6瀏覽量
9363 -
C 語言
+關注
關注
0文章
18瀏覽量
14223 -
網絡開發
+關注
關注
0文章
13瀏覽量
7851
原文標題:圖解:深入理解高性能網絡開發路上的絆腳石,同步阻塞網絡 IO
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
socket編程中的阻塞與非阻塞

SystemView上下文統計窗口識別阻塞原因
socket阻塞和非阻塞的區別是什么
深度神經網絡與基本神經網絡的區別
利用NVIDIA的nvJPEG2000庫分析DICOM醫學影像的解碼功能
verilog同步和異步的區別 verilog阻塞賦值和非阻塞賦值的區別
國產數字隔離器實現進口替代:關鍵點深度分析







 工商網監
工商網監
評論