 將線性Transformer作為快速權重系統進行分析和改進
將線性Transformer作為快速權重系統進行分析和改進
Transformer 在深度學習中占據主導地位,但二次存儲和計算需求使得 Transformer 的訓練成本很高,而且很難使用。許多研究都嘗試線性化核心模塊:以 Performer 為例,使用帶核的注意力機制。然而,這種方法還存在很多缺點,例如它們依賴于隨機特征。 本文中,來自瑞士人工智能實驗室(IDSIA)、亞琛工業大學的研究者建立起了線性(核)注意力與 90 年代深度學習之父 Jürgen Schmidhuber 推廣的更古老的快速權重存儲系統之間的內在聯系,不僅指出了這些算法的基本局限性,還提出了新的更新規則和新的核來解決這些問題。在關鍵的綜合實驗和實際任務中,所得到的模型優于 Performers。

論文鏈接:https://arxiv.org/abs/2102.11174
代碼地址:https://github.com/ischlag/fast-weight-transformers
具體而言,該研究推測線性化的 softmax 注意力變量存在存儲容量限制。在有限存儲的情況下,快速權重存儲模型的一個理想行為是操縱存儲的內容并與之動態交互。 受過去對快速權重研究的啟發,研究者建議用產生這種行為的替代規則替換更新規則。此外,該研究還提出了一個新的核函數來線性化注意力,平衡簡單性和有效性。他們進行了大量的實驗,實驗內容包括合成檢索問題、標準機器翻譯以及語言建模。實驗結果證明了該研究方法的益處。 將線性 Transformer 作為快速權重系統進行分析和改進 將線性 Transformer 變量視為快速權重系統,研究者給出了兩個見解:作為關聯存儲容量的限制;無法編輯以前存儲的關聯內容。 容量限制 不斷地將新的關聯添加到有限大小的存儲中,如下公式 17 所示,這樣不可避免地會達到極限。在線性注意力中,信息存儲在矩陣中,并使用矩陣乘法進行檢索(如下公式 19)。因此,為了防止關聯在檢索時相互干擾,各個鍵(keys)需要正交。否則,點積將處理多個鍵并返回值的線性組合。對于嵌入在 d_dot 空間中的鍵,則不能有多余 d_dot 正交向量。
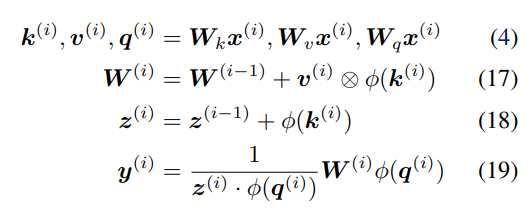
也就是說,存儲多個 d_dot 關聯將導致檢索誤差。在線性 Transformer 中,當序列長度大于 d_dot 時,模型可能處于這樣一種容量過剩狀態。 改進與更新 受快速權重存儲研究(Schlag 等人,2021 年)的啟發,研究者提出了以下存儲更新規則。 給定新的輸入鍵 - 值對 (k^ (i) , v ^(i) ),模型首先訪問存儲的當前狀態 W^(i?1),并檢索當前與鍵 k^(i) 配對的值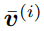 。然后,該模型存儲檢索值和輸入 v^(i) 的凸組合
。然后,該模型存儲檢索值和輸入 v^(i) 的凸組合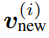 ,使用插值權重 0≤β^(i)≤1 的輸入 v ^(i) 也由該模型生成。因此,該模型按順序將輸入序列
,使用插值權重 0≤β^(i)≤1 的輸入 v ^(i) 也由該模型生成。因此,該模型按順序將輸入序列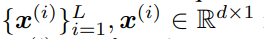 轉化為輸出序列
轉化為輸出序列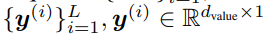 ,如下所示: ?
,如下所示: ?
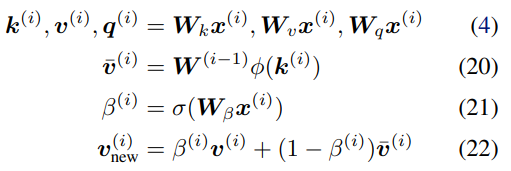
歸一化:在以上等式中,檢索的值沒有應用歸一化。通過推導可以得到一個簡單的歸一化,即通過引入累加器(accumulator):
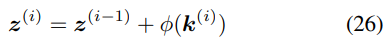
將公式 20、25 分別替換為:
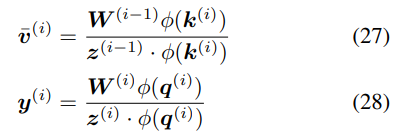
然而,這種方法也有缺陷。首先,公式 26 中正值的累積總是隨著步數的增加而增加,并且可能導致不穩定;其次,特別是對于該研究提出的更新規則,這種歸一化不足以平衡公式 23 中寫入和刪除運算之間的權重(參見附錄 A.2 中的推導)。 在這里,研究者提出了一種基于簡單歸一化的更好方法,將有效值和查詢向量φ(k^(i))、φ(q^(i)) 除以其分量之和。例如,對于查詢:
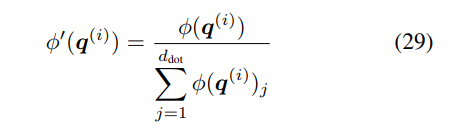
線性注意力函數Katharopoulos 線性注意力 Katharopoulos 等人提出使用簡單的逐元素 ELU + 1 函數(Clevert 等人, 2016):
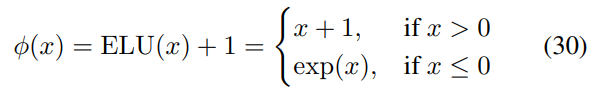
選擇 ELU 而不是 ReLU 的動機是因為負數部分的非零梯度。重要的是,作為一個簡單的函數,這個Φ函數保留了輸入鍵向量(d_key=d_dot)的維數,而不需要修改第 4.1 節中討論的存儲容量。 DPFP 前面兩小節強調了現有Φ函數的次優性。采樣會給 FAVOR + 增加額外的復雜度,而線性 Transformer 缺乏投影點積維數的能力。因此,研究者提出了一種稱為確定性無參數投影(deterministic parameter-free projection, DPFP) 的替代方法。它是確定性的,并像線性 Transformer 一樣易于計算,同時增加點積維數,而不需要 FAVOR + 的隨機特性。 下圖中四維空間的元素被顯示為四個彩色表面的 z 分量,以及 2d 平面中的每個向量如何在 4d 空間中具有單個非零分量,并將輸入空間平均分割為在投影空間中正交的四個區域。
實驗 該研究從三個方面進行了實驗:合成檢索問題、機器翻譯和語言模型。 合成檢索問題 所有模型都以最小批次 32 進行訓練,直到評估損失降到 0.001 以下,或者進行了 1000 訓練步。下圖 2 展示了模型的最佳驗證集性能以及對不同 S 的顯示。唯一鍵的數量初始值 S=20,然后每次遞增 20,直到 S=600 為止。實驗對以下模型進行對比:Softmax、線性注意力、具有 64、128 和 512 個隨機特征的 FAVOR + 以及ν∈{1、2、3} 的 DPFP-ν。
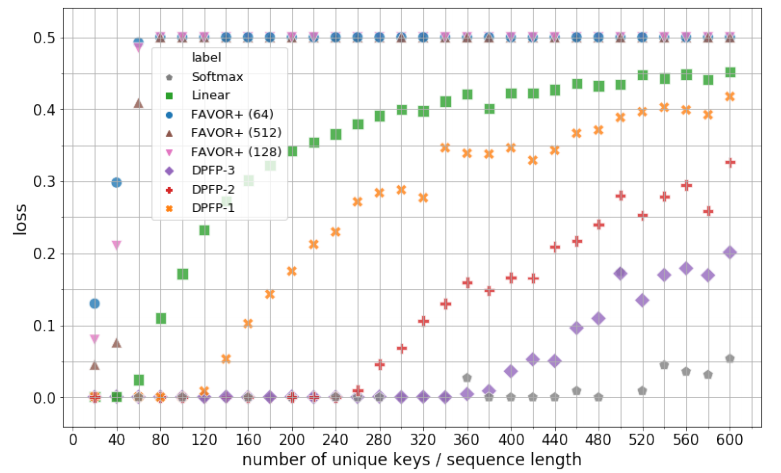
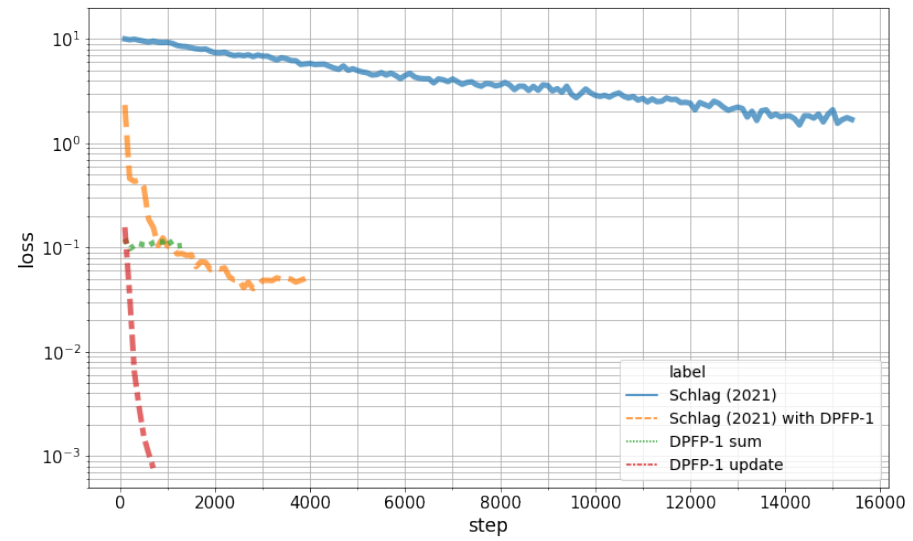
下圖 3 展示了學習曲線。實驗結果表明,該研究提出的更新規則優于其他變體。正如預期的那樣,基線總和更新規則失敗。
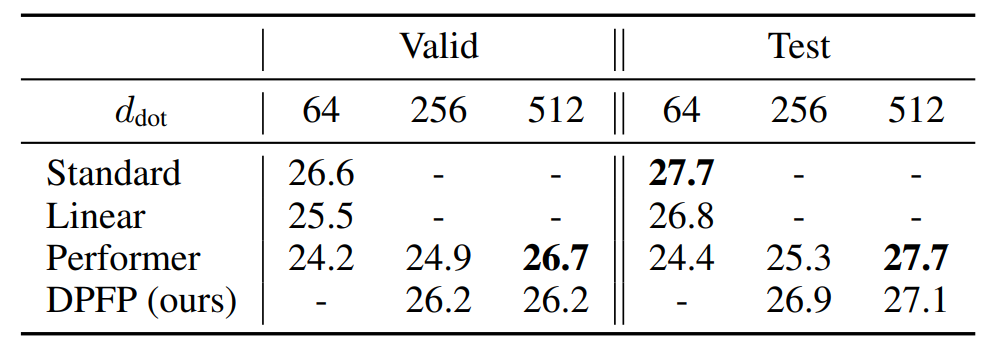
機器翻譯 下表 1 顯示了 BLEU 得分結果。當樣本數 m 足夠大時(當 d_dot=512,m=256),Performer 與基礎 Transformer 性能相當。實際上,當 d_key=64 時,m 的推薦值是 d_dot log(d_dot)=266。當 d_dot 相對較小時,該研究的 DPFP 模型優于線性 Transformer 和 Performer;在簡單性和性能之間提供了一個很好的折衷。
語言模型 該研究使用標準 WikiText-103(Merity 等,2017)數據集進行實驗。WikiText-103 數據集由維基百科的長文組成;訓練集包含大約 28K 篇文章、總共 103M 個單詞。這將產生約 3600 個單詞的上下文文本塊。驗證集和測試集也包含類似的長依賴關系,分別有 218K 和 246K 個運行單詞,對應 60 篇文章,詞匯量約為 268K 個單詞。下表 2 展示了在該研究更新規則下,WikiText-103 語言模型的困惑度結果。
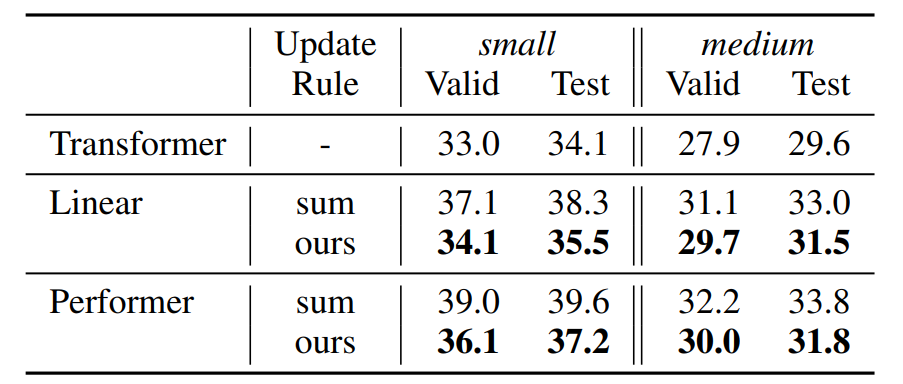
在下表 3 中,使用該研究更新規則下的 Transformer(medium 配置),在 WikiText-103 語言模型的困惑度結果。
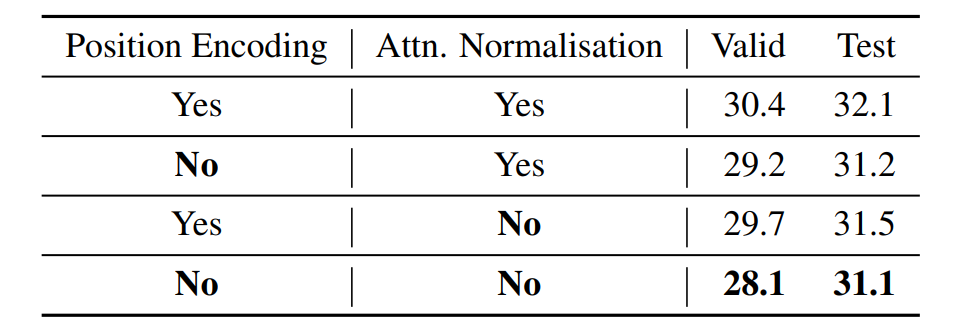
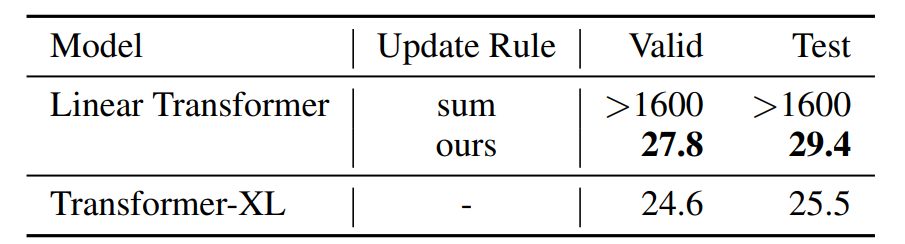
在下表 4 中,WikiText-103 語言模型在沒有截斷上下文的情況下訓練和評估模型的困惑度,這與上表 2 中上下文窗口受到限制的情況相反。medium 配置既不用于位置編碼,也不用于注意力標準化。
責任編輯:lq
-
人工智能
+關注
關注
1791文章
46868瀏覽量
237592 -
深度學習
+關注
關注
73文章
5493瀏覽量
120979 -
Transformer
+關注
關注
0文章
141瀏覽量
5982
原文標題:LSTM之父重提30年前的「快速權重存儲系統」:線性Transformer只是它的一種變體
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

USB Type-C系統中TPS25947和LM73100的快速角色交換、線性或運算

Transformer能代替圖神經網絡嗎
Transformer語言模型簡介與實現過程
深度學習中的模型權重
使用PyTorch搭建Transformer模型
基于Transformer的多模態BEV融合方案
UPS電源蓄電池快速充電的改進方法
Spring Boot和飛騰派融合構建的農業物聯網系統-改進自適應加權融合算法
更深層的理解視覺Transformer, 對視覺Transformer的剖析
降低Transformer復雜度O(N^2)的方法匯總






 工商網監
工商網監
評論