 如何高效的使用Python和pandas清理非結構化文本字段技巧
如何高效的使用Python和pandas清理非結構化文本字段技巧
介紹
大家都知道數據清洗是數據分析過程中的一個重要部分。pandas有多種清洗文本字段的方法,可以用來為進一步分析做準備。隨著數據集越來越大,文本清洗的過程會逐漸變長,尋找一個能在合理時間內有效運行并可維護的方法變得非常重要。
本文將展示清洗大數據文件中文本字段的示例,幫助大家學習使用 Python 和 pandas 高效清理非結構化文本字段的技巧。
問題
假設你有一批全新工藝的威士忌想出售。你所在的愛荷華州,剛好有一個公開的數據集顯示了該州所有的酒類銷售情況。這似乎是一個很好的機會,你可以利用你的分析技能,看看誰是這個州最大的客戶。有了這些數據,你甚至可以為每個客戶規劃銷售流程。
你對這個機會感到興奮,但下載了數據后發現它相當大。這個數據集是一個565MB的CSV文件,包含24列和2.3百萬行。它雖然不是我們平時說的“大數據”,但它依然足夠大到可以讓Excel卡死。同時它也大到讓一些pandas方法在比較慢的筆記本電腦上運行地非常吃力。
本文中,我們將使用包括2019年所有銷售額的數據。當然你也可以從網站上下載其他不同時間段的數據。
我們從導入模塊和讀取數據開始,我會使用sidetable包來查看數據的概覽。這個包雖然不能用來做清洗,但我想強調一下它對于這些數據探索場景其實很有用。
數據
讀取數據:
import pandas as pd
import numpy as np
import sidetable
df = pd.read_csv(‘2019_Iowa_Liquor_Sales.csv’)
數據長這樣:
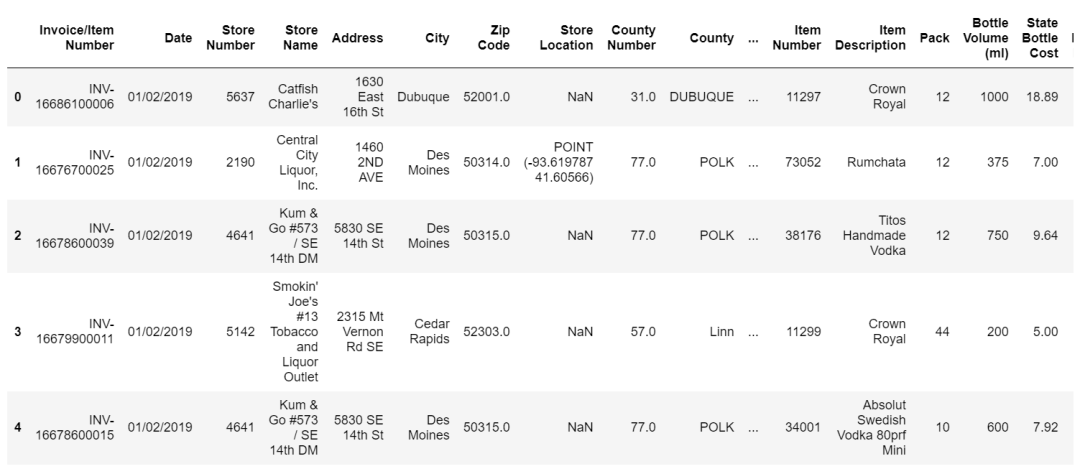
我們大概率要做的第一件事是看每一家商店的購買量,并將它們從大到小排序。資源有限所以我們應該集中精力在那些我們能從中獲得最好回報的地方。我們更應該打電話給幾個大公司的賬戶,而不是那些夫妻小店。
sidetable是以可讀格式匯總數據的快捷方式。另一種方法是groupby加上其他操作。
df.stb.freq([‘Store Name’], value=‘Sale (Dollars)’, style=True, cum_cols=False)
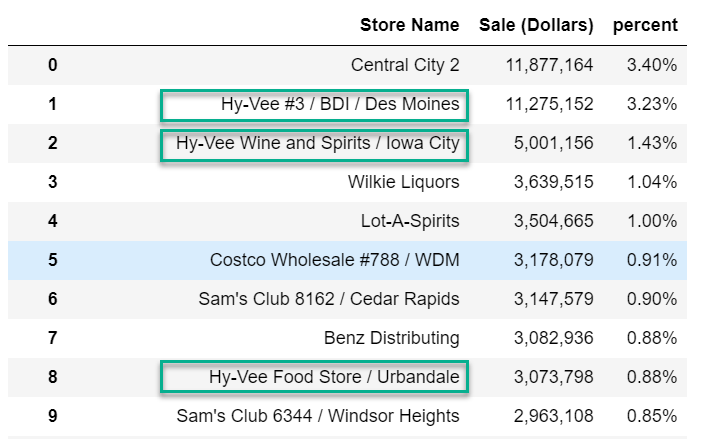
很明顯在大多數情況下,每個位置的商店名稱都是唯一的。理想情況下我們希望看到的是Hy-Vee, Costco, Sam’s 等聚合在一起的內容。
看來我們需要清洗數據了。
清洗嘗試·1
我們可以研究的第一種方法是使用.loc以及str的布爾過濾器來搜索Store Name列中的相關字符串。
df.loc[df[‘Store Name’].str.contains(‘Hy-Vee’, case=False), ‘Store_Group_1’] = ‘Hy-Vee’
上述代碼使用不區分大小寫的方式來搜索字符串“Hy Vee”,并將值“Hy Vee”存儲在名為Store_Group_1的新列中。這個代碼可以有效地將“Hy Vee#3/BDI/Des Moines”或“Hy Vee Food Store/Urbandale”等名稱轉換為正常的“Hy Vee”。
用%%timeit來計算此操作的時間:
1.43 s ± 31.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
我們不想過早地進行優化,但我們可以使用regex=False參數來稍微加速一下:
df.loc[df[‘Store Name’].str.contains(‘Hy-Vee’, case=False, regex=False), ‘Store_Group_1’] = ‘Hy-Vee’
804 ms ± 27.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
來看下新列的情況:
df[‘Store_Group_1’].value_counts(dropna=False)
NaN 1617777
Hy-Vee 762568
Name: Store_Group_1, dtype: int64
可以看到我們已經清理了Hy-Vee,但還有很多其他值需要我們處理。
.loc方法內部包含大量代碼,速度其實可能很慢。我們可以利用這個思想,來尋找一些更易于執行和維護的替代方案。
清洗嘗試·2
另一種非常有效和靈活的方法是使用np.select來進行多匹配并在匹配時指定值。
有幾個很好的資源可以幫你學習如何使用np.select。這篇來自Dataquest的文章就是一個很好的概述。Nathan Cheever的這篇演講也十分有趣,內容豐富。我建議你們可以看下這兩篇文章。
關于np.select的作用最簡單的解釋是,它計算一個條件列表,如果有條件為真,就應用相應值的列表。
在我們的例子中,我們想查找不同的字符串,來替換為我們想要的規范值。
瀏覽完我們的數據后,我們把條件和值列表總結在store_patterns列表中。列表中的每個元組都是一個str.contains()方法,來查找和替換對應的我們想要做聚合的規范值。
store_patterns = [
(df[‘Store Name’].str.contains(‘Hy-Vee’, case=False, regex=False), ‘Hy-Vee’),
(df[‘Store Name’].str.contains(‘Central City’,
case=False, regex=False), ‘Central City’),
(df[‘Store Name’].str.contains(“Smokin‘ Joe’s”,
case=False, regex=False), “Smokin‘ Joe’s”),
(df[‘Store Name’].str.contains(‘Walmart|Wal-Mart’,
case=False), ‘Wal-Mart’),
(df[‘Store Name’].str.contains(‘Fareway Stores’,
case=False, regex=False), ‘Fareway Stores’),
(df[‘Store Name’].str.contains(“Casey‘s”,
case=False, regex=False), “Casey’s General Store”),
(df[‘Store Name’].str.contains(“Sam‘s Club”, case=False, regex=False), “Sam’s Club”),
(df[‘Store Name’].str.contains(‘Kum & Go’, regex=False, case=False), ‘Kum & Go’),
(df[‘Store Name’].str.contains(‘CVS’, regex=False, case=False), ‘CVS Pharmacy’),
(df[‘Store Name’].str.contains(‘Walgreens’, regex=False, case=False), ‘Walgreens’),
(df[‘Store Name’].str.contains(‘Yesway’, regex=False, case=False), ‘Yesway Store’),
(df[‘Store Name’].str.contains(‘Target Store’, regex=False, case=False), ‘Target’),
(df[‘Store Name’].str.contains(‘Quik Trip’, regex=False, case=False), ‘Quik Trip’),
(df[‘Store Name’].str.contains(‘Circle K’, regex=False, case=False), ‘Circle K’),
(df[‘Store Name’].str.contains(‘Hometown Foods’, regex=False,
case=False), ‘Hometown Foods’),
(df[‘Store Name’].str.contains(“Bucky‘s”, case=False, regex=False), “Bucky’s Express”),
(df[‘Store Name’].str.contains(‘Kwik’, case=False, regex=False), ‘Kwik Shop’)
]
使用np.select很容易遇到條件和值不匹配的情況。所以我們將其合并為元組,以便更容易地跟蹤數據匹配。
想使用這種數據結構,我們需要將元組分成兩個單獨的列表。使用zip來把store_patterns分為store_criteria和store_values:
store_criteria, store_values = zip(*store_patterns)
df[‘Store_Group_1’] = np.select(store_criteria, store_values, ‘other’)
上述代碼將用文本值填充每個匹配項。如果沒有匹配項,我們給它賦值‘other’。
數據現在長這樣:
df.stb.freq([‘Store_Group_1’], value=‘Sale (Dollars)’, style=True, cum_cols=False)
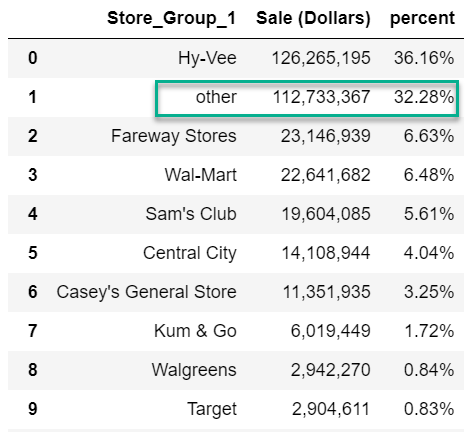
看起來比之前好,但仍然有32.28%的‘other’。
思考下這樣做是不是更好:如果帳戶不匹配,我們使用Store Name字段,而不是‘other’。這樣來實現:
df[‘Store_Group_1’] = np.select(store_criteria, store_values, None)
df[‘Store_Group_1’] = df[‘Store_Group_1’].combine_first(df[‘Store Name’])
這里使用了combine_first方法來將Store Name填充None值,這是清理數據時要記住的一個簡便技巧。
再來看下數據:
df.stb.freq([‘Store_Group_1’], value=‘Sale (Dollars)’, style=True, cum_cols=False)
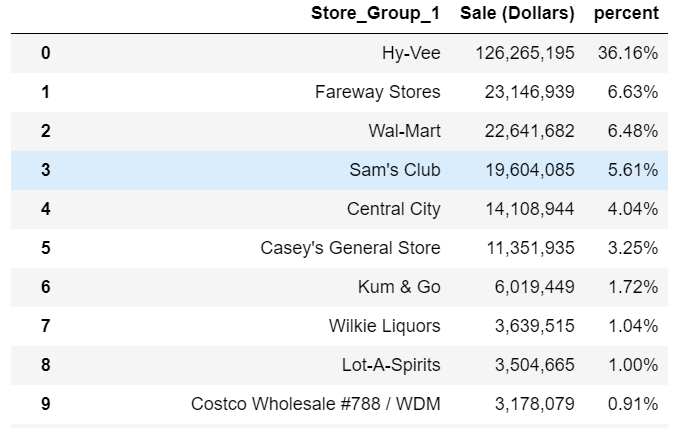
這樣看起來更好了,我們可以根據需要繼續細化分組。例如我們可能需要為Costco構建一個字符串查找。
對于這個大型數據集來說,性能也還不錯:
13.2 s ± 328 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
這個方法的好處是你可以使用np.select來做數值分析或者上面展示的文本示例,非常靈活。這個方法也有一個弊端,那就是代碼量很大。如果你要清理的數據集非常大,那么用這個方法可能導致很多數據和代碼混合在一起。那么有沒有其他方法可以有差不多的性能,代碼更整潔一些?
清洗嘗試·3
這里要介紹的解決方案基于Matt Harrison的優秀代碼示例,他開發了一個可以做匹配和清洗的generalize函數。我做了一些修改,讓這個方法可以在這個示例中使用,我想給Matt一個大大的贊。如果沒有他前期99%的工作,我永遠不會想到這個解決方案!
def generalize(ser, match_name, default=None, regex=False, case=False):
“”“ Search a series for text matches.
Based on code from https://www.metasnake.com/blog/pydata-assign.html
ser: pandas series to search
match_name: tuple containing text to search for and text to use for normalization
default: If no match, use this to provide a default value, otherwise use the original text
regex: Boolean to indicate if match_name contains a regular expression
case: Case sensitive search
Returns a pandas series with the matched value
”“”
seen = None
for match, name in match_name:
mask = ser.str.contains(match, case=case, regex=regex)
if seen is None:
seen = mask
else:
seen |= mask
ser = ser.where(~mask, name)
if default:
ser = ser.where(seen, default)
else:
ser = ser.where(seen, ser.values)
return ser
這個函數可以在pandas上調用,傳參是一個元組列表。第一個元組項是要搜索的值,第二個是要為匹配值填充的值。
以下是等效的模式列表:
store_patterns_2 = [(‘Hy-Vee’, ‘Hy-Vee’), (“Smokin‘ Joe’s”, “Smokin‘ Joe’s”),
(‘Central City’, ‘Central City’),
(‘Costco Wholesale’, ‘Costco Wholesale’),
(‘Walmart’, ‘Walmart’), (‘Wal-Mart’, ‘Walmart’),
(‘Fareway Stores’, ‘Fareway Stores’),
(“Casey‘s”, “Casey’s General Store”),
(“Sam‘s Club”, “Sam’s Club”), (‘Kum & Go’, ‘Kum & Go’),
(‘CVS’, ‘CVS Pharmacy’), (‘Walgreens’, ‘Walgreens’),
(‘Yesway’, ‘Yesway Store’), (‘Target Store’, ‘Target’),
(‘Quik Trip’, ‘Quik Trip’), (‘Circle K’, ‘Circle K’),
(‘Hometown Foods’, ‘Hometown Foods’),
(“Bucky‘s”, “Bucky’s Express”), (‘Kwik’, ‘Kwik Shop’)]
這個方案的一個好處是,與前面的store_patterns示例相比,維護這個列表要容易得多。
我對generalize函數做的另一個更改是,如果沒有提供默認值,那么將保留原始值,而不是像上面那樣使用combine_first函數。最后,為了提高性能,我默認關閉了正則匹配。
現在數據都設置好了,調用它很簡單:
df[‘Store_Group_2’] = generalize(df[‘Store Name’], store_patterns_2)
性能如何?
15.5 s ± 409 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
比起上面它稍微有一點慢,但我認為它是一個更優雅的解決方案,如果我要做一個類似的文本清理工作,我會用這個方法。
這種方法的缺點是,它只能做字符串清洗。而np.select也可以應用于數值,所以應用范圍更廣。
關于數據類型
在pandas的最新版本中,有一個專用的字符串類型。我嘗試將Store Name轉換為該字符串類型,想看是否有性能優化。結果沒有看到任何變化。不過,未來有可能會有速度的提升,這點大家可以關注一下。
雖然string類型沒有什么區別,但是category類型在這個數據集上顯示了很大的潛力。有關category數據類型的詳細信息,可以參閱我的上一篇文章:https://pbpython.com/pandas_dtypes_cat.html。
我們可以使用astype將數據轉換為category類型:
df[‘Store Name’] = df[‘Store Name’].astype(‘category’)
然后我們跟之前那樣在運行np.select的方法
df[‘Store_Group_3’] = np.select(store_criteria, store_values, None)
df[‘Store_Group_3’] = df[‘Store_Group_1’].combine_first(df[‘Store Name’])
786 ms ± 108 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
我們只做了一個簡單的改動,運行時間從13秒到不到1秒。太神了!效果這么明顯的原因其實很簡單。當pandas將列轉換為分組類型時,它只會對每個唯一的文本值調用珍貴的str.contains()函數。因為這個數據集有很多重復的數據,所以我們得到了巨大的性能提升。
讓我們看看這是否適用于我們的generalize函數:
df[‘Store_Group_4’] = generalize(df[‘Store Name’], store_patterns_2)
不幸的是報錯了:
ValueError: Cannot setitem on a Categorical with a new category, set the categories first
這個錯誤讓我回憶起我過去處理分組數據時遇到的一些挑戰。當你合并和關聯分組數據時,你很容易遇到這些錯誤。
我試圖找到一個比較好的方法來修改generage(),想讓它起作用,但目前還沒找到。如果有任何讀者能找到方法,可以聯系我獲得獎金。這里,我們通過構建一個查找表來復制Category方法。
查找表
正如我們通過分類方法了解到的,這個數據集有很多重復的數據。我們可以構建一個查找表,每個字符串處理一次資源密集型函數。
為了說明它是如何在字符串上工作的,我們將值從category轉換回字符串類型:
df[‘Store Name’] = df[‘Store Name’].astype(‘string’)
首先,我們構建一個包含所有唯一值的lookup DataFrame并運行generalize函數:
lookup_df = pd.DataFrame()
lookup_df[‘Store Name’] = df[‘Store Name’].unique()
lookup_df[‘Store_Group_5’] = generalize(lookup_df[‘Store Name’], store_patterns_2)
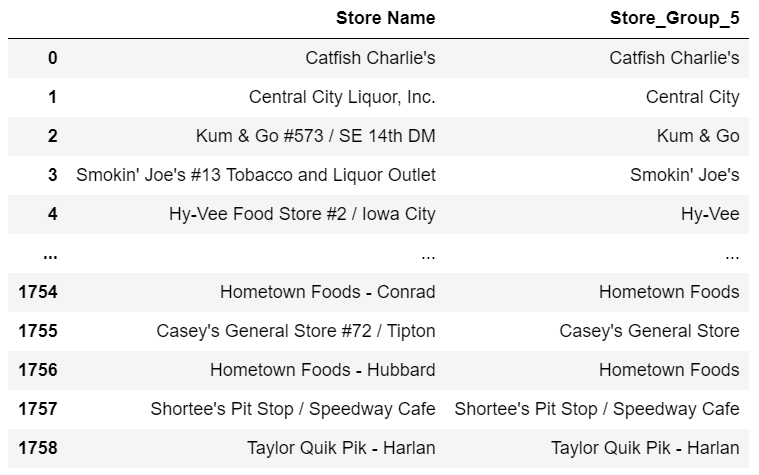
我們可以把它合并到最終的DataFrame:
df = pd.merge(df, lookup_df, how=‘left’)
1.38 s ± 15.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
比起np.select使用分組數據的方法稍慢一些,但是代碼可讀性和易維護程度更高,性能和這兩者之間其實需要掌握一個平衡。
此外,中間的lookup_df可以很好的輸出給分析師共享,從而讓分析師幫助你清洗更多數據。這可能節省你幾小時的時間!
總結
根據我的經驗,通過本文中概述的清洗示例,你可以了解很多關于底層數據的信息。
我推測你會在你的日常分析中發現很多需要進行文本清理的案例,就像我在本文中展示的那樣。
下面是本文解決方案的簡要總結:
解決方案執行時間注釋
np.select13s可用于非文本分析
generalize15s只支持文本
分組數據和np.select786ms在合并和關聯時,分組數據可能會變得棘手
查找表和generalize1.3s查找表可以由其他人維護
對于一些數據集來說,性能不是問題,所以你可以隨意選擇。
然而,隨著數據規模的增長(想象一下對50個州的數據進行分析),你需要了解如何高效地使用pandas進行文本清洗。我建議你可以收藏這篇文章,當你面對類似的問題時可以再回來看看。
當然,如果你有一些其他的建議,可能會對別人有用,可以寫在評論里。如果你知道如何使我的generalize函數與分組數據一起工作,也記得告訴我。
編輯:lyn
-
數據分析
+關注
關注
2文章
1427瀏覽量
34015 -
python
+關注
關注
56文章
4782瀏覽量
84453
原文標題:用 pandas 高效清洗文本數據
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
結構化布線在AI數據中心的關鍵作用
使用ReMEmbR實現機器人推理與行動能力
如何在文本字段中使用上標、下標及變量

定期維護結構化布線對于辦公室得重要性
什么是結構化網絡布線?結構化網絡布線有哪些好處?
結構化布線的好處多嗎
什么是網絡系統中的結構化布線?
arcgis值類型與字段類型不兼容
科通技術推出基于FPGA的應用設計結構化技術
CFD 設計利器:結構化和非結構化網格的組合使用

使用關系數據庫中的半結構化數據

Python利用pandas讀寫Excel文件

Python編程的十大依賴庫有哪些
使用pandas進行數據選擇和過濾的基本技術和函數





 工商網監
工商網監
評論