 關于AI芯片的概念與發展歷程及其應用領域
關于AI芯片的概念與發展歷程及其應用領域
2010年以來,由于大數據產業的發展,數據量呈現爆炸性增長態勢,而傳統的計算架構又無法支撐深度學習的大規模并行計算需求,于是研究界對AI芯片進行了新一輪的技術研發與應用研究。這一新興技術既為科技巨頭的業務升級和拓展帶來轉機,也給了新創企業顛覆現有格局的機會。
AI芯片是人工智能時代的技術核心之一,決定了平臺的基礎架構和發展生態。作為人工智能產業的重中之重,AI芯片已經成了最熱門的投資領域,各種AI芯片層出不窮。
從廣義上講,只要能夠運行人工智能算法的芯片都叫作AI芯片。但是通常意義上的AI芯片指的是針對人工智能算法做了特殊加速設計的芯片,現階段,這些人工智能算法一般以深度學習算法為主,也可以包括其它機器學習算法。
一般來說,所謂的AI芯片,是指針對AI算法的ASIC(專用芯片)。傳統的CPU、GPU都可以拿來執行AI算法,但是速度慢,性能低,無法實際商用。
比如,自動駕駛需要識別道路行人紅綠燈等狀況,但是如果是當前的CPU去算,那么估計車翻到河里了還沒發現前方是河,這是速度慢,時間就是生命。如果用GPU,的確速度要快得多,但是,功耗大,汽車的電池估計無法長時間支撐正常使用,而且, GPU巨貴,普通消費者也用不起。另外,GPU因為不是專門針對AI算法開發的ASIC,所以,說到底,速度還沒到極限,還有提升空間。而類似智能駕駛這樣的領域,必須快!在手機終端,可以自行人臉識別、語音識別等AI應用,這個又必須功耗低。
AI芯片到底是什么?
回答這個問題之前,先來弄明白兩個概念,什么是CPU和GPU?
簡單來說,CPU就是手機的“大腦”,也是手機正常運行的“總指揮官”。GPU被翻譯成圖形處理器,主要工作確實是圖像處理。
再來說說CPU和GPU之間的分工,CPU遵循的是馮諾依曼架構,核心就是“存儲程序,順序執行”,就像是做事一板一眼的管家,什么事情都要一步一步來。假如你讓CPU去種一棵樹,挖坑、澆水、植樹、封土等工作都要獨自一步一步進行。
如果讓GPU去種一棵樹的話,會喊來小A、小B、小C等一同來完成,把挖坑、澆水、植樹、封土等工作分割成不同的子任務。這是因為GPU執行的是并行運算,即把一個問題分解成若干個部分,各部分由獨立的計算單元去完成。恰好圖像處理的每一個像素點都需要被計算,與GPU的工作原理不謀而合。

就如同比方:CPU像是老教授,積分、微分什么都會算,但有些工作是計算大量一百以內的加減乘除,最好的方法當然不是讓老教授挨個算下去,而是雇上幾十個小學生把任務分配下去。這就是CPU和GPU的分工,CPU負責大型運算,GPU為圖像處理而生,從電腦到智能手機都是如此。
但當人工智能的需求出現后,CPU和GPU的分工就出現了問題,人工智能終端的深度學習和傳統計算不同,借由后臺預先從大量訓練數據中總結出規律,得到可以給人工智能終端判定的參數,比如訓練樣本是人臉圖像數據,實現的功能在終端上就是人臉識別。
CPU往往需要數百甚至上千條指令才能完成一個神經元的處理,無法支撐起大規模的并行運算,而手機上的GPU又需要處理各種應用的圖像處理需求。強行使用CPU和GPU進行人工智能任務,結果普遍是效率低下、發熱嚴重。
諸如蘋果A12、麒麟980和Exynos 9820提供的AI芯片的一種。通俗來說就是人工智能加速器,因為GPU是基于塊數據處理的,但手機上的AI應用是需要實時處理的,人工智能加速器剛好解決了這個痛點,把深度學習相關的工作接管過來,從而緩解CPU 和GPU 的壓力。
它們將CPU和GPU的計算量分開,諸如面部識別、語音識別等AI相關的任務卸載到ASIC上處理,AI芯片核早已成為一種行業趨勢。
一方面AI芯片的價值在于與CPU、GPU進行協同分工,CPU和GPU過多的任務堆疊只會虛耗電量、提高溫度。
另一方面在AI芯片的協同下,可以對用戶行為進行學習,進而對用戶的使用場景進行預測,然后進行合理的性能分配。好比說當你在游戲時讓CPU高效運算,而當你在看電子書時避免性能浪費。
AI芯片發展歷程
從圖靈的論文《計算機器與智能》和圖靈測試,到最初級的神經元模擬單元——感知機,再到現在多達上百層的深度神經網絡,人類對人工智能的探索從來就沒有停止過。上世紀八十年代,多層神經網絡和反向傳播算法的出現給人工智能行業點燃了新的火花。反向傳播的主要創新在于能將信息輸出和目標輸出之間的誤差通過多層網絡往前一級迭代反饋,將最終的輸出收斂到某一個目標范圍之內。1989年貝爾實驗室成功利用反向傳播算法,在多層神經網絡開發了一個手寫郵編識別器。1998年Yann LeCun和Yoshua Bengio發表了手寫識別神經網絡和反向傳播優化相關的論文《Gradient-based learning applied to document recognition》,開創了卷積神經網絡的時代。
此后,人工智能陷入了長時間的發展沉寂階段,直到1997年IBM的深藍戰勝國際象棋大師和2011年IBM的沃森智能系統在Jeopardy節目中勝出,人工智能才又一次為人們所關注。2016年Alpha Go擊敗韓國圍棋九段職業選手,則標志著人工智能的又一波高潮。從基礎算法、底層硬件、工具框架到實際應用場景,現階段的人工智能領域已經全面開花。
作為人工智能核心的底層硬件AI芯片,也同樣經歷了多次的起伏和波折,總體看來,AI芯片的發展前后經歷了四次大的變化,其發展歷程如圖所示。
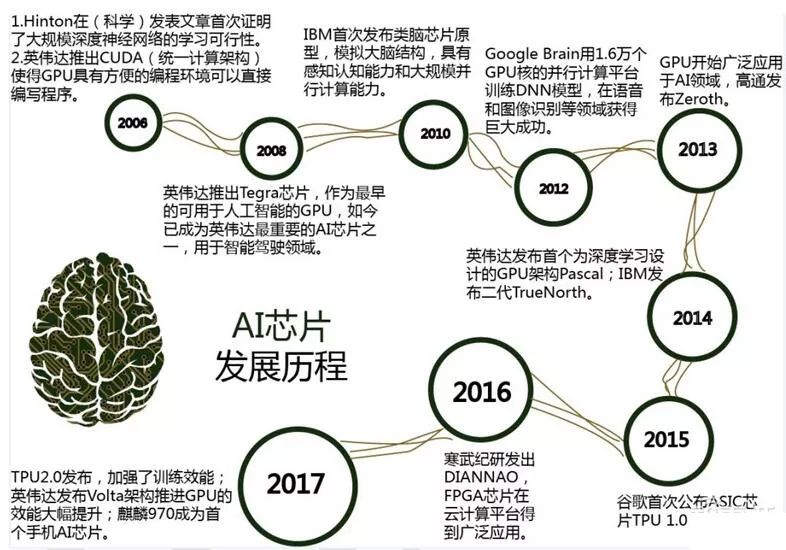
1、2007年以前,AI芯片產業一直沒有發展成為成熟的產業;同時由于當時算法、數據量等因素,這個階段AI芯片并沒有特別強烈的市場需求,通用的CPU芯片即可滿足應用需要。
2、隨著高清視頻、VR、AR游戲等行業的發展,GPU產品取得快速的突破;同時人們發現GPU的并行計算特性恰好適應人工智能算法及大數據并行計算的需求,如GPU比之前傳統的CPU在深度學習算法的運算上可以提高幾十倍的效率,因此開始嘗試使用GPU進行人工智能計算。
3、進入2010年后,云計算廣泛推廣,人工智能的研究人員可以通過云計算借助大量CPU和GPU進行混合運算,進一步推進了AI芯片的深入應用,從而催生了各類AI芯片的研發與應用。
4、人工智能對于計算能力的要求不斷快速地提升,進入2015年后,GPU性能功耗比不高的特點使其在工作適用場合受到多種限制,業界開始研發針對人工智能的專用芯片,以期通過更好的硬件和芯片架構,在計算效率、能耗比等性能上得到進一步提升。
AI芯片與普通芯片的區別在哪里?
AI算法,在圖像識別等領域,常用的是CNN卷積網絡,語音識別、自然語言處理等領域,主要是RNN,這是兩類有區別的算法。但是,他們本質上,都是矩陣或vector的乘法、加法,然后配合一些除法、指數等算法。
一個成熟的AI算法,比如YOLO-V3,就是大量的卷積、殘差網絡、全連接等類型的計算,本質是乘法和加法。對于YOLO-V3來說,如果確定了具體的輸入圖形尺寸,那么總的乘法加法計算次數是確定的。比如一萬億次。(真實的情況比這個大得多的多)那么要快速執行一次YOLO-V3,就必須執行完一萬億次的加法乘法次數。
這個時候就來看了,比如IBM的POWER8,最先進的服務器用超標量CPU之一,4GHz,SIMD,128bit,假設是處理16bit的數據,那就是8個數,那么一個周期,最多執行8個乘加計算。一次最多執行16個操作。這還是理論上,其實是不大可能的。那么CPU一秒鐘的巔峰計算次數=16X4Gops=64Gops。這樣,可以算算CPU計算一次的時間了。同樣的,換成GPU算算,也能知道執行時間。
再來說說AI芯片。比如大名鼎鼎的谷歌的TPU1。
TPU1,大約700M Hz,有256X256尺寸的脈動陣列,如下圖所示。一共256X256=64K個乘加單元,每個單元一次可執行一個乘法和一個加法。那就是128K個操作。(乘法算一個,加法再算一個)
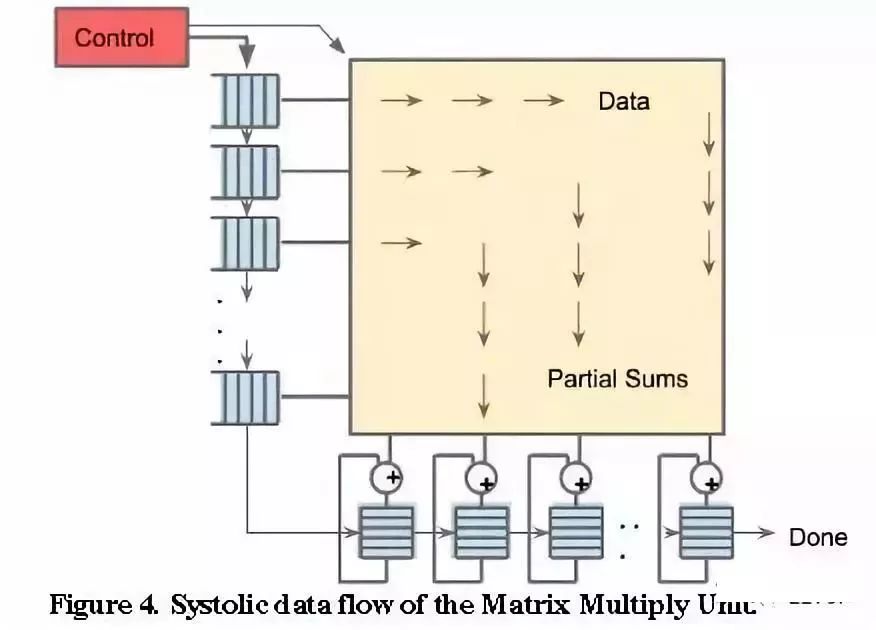
另外,除了脈動陣列,還有其他模塊,比如激活等,這些里面也有乘法、加法等。所以,看看TPU1一秒鐘的巔峰計算次數至少是=128K X 700MHz=89600Gops=大約90Tops。對比一下CPU與TPU1,會發現計算能力有幾個數量級的差距,這就是為啥說CPU慢。
當然,以上的數據都是完全最理想的理論值,實際情況,能夠達到5%吧。因為,芯片上的存儲不夠大,所以數據會存儲在DRAM中,從DRAM取數據很慢的,所以,乘法邏輯往往要等待。另外,AI算法有許多層網絡組成,必須一層一層的算,所以,在切換層的時候,乘法邏輯又是休息的,所以,諸多因素造成了實際的芯片并不能達到利潤的計算峰值,而且差距還極大。
目前來看,神經網絡的尺寸是越來越大,參數越來越多,遇到大型NN模型,訓練需要花幾周甚至一兩個月的時候。突然斷電,還得一切重來。修改了模型,需要幾個星期才能知道對錯,確定等得起?突然有了TPU,然后你發現,吃個午飯回來就好了,參數優化一下,繼續跑,多么爽!
總的來說,CPU與GPU并不是AI專用芯片,為了實現其他功能,內部有大量其他邏輯,而這些邏輯對于目前的AI算法來說是完全用不上的,所以,自然造成CPU與GPU并不能達到最優的性價比。
目前在圖像識別、語音識別、自然語言處理等領域,精度最高的算法就是基于深度學習的,傳統的機器學習的計算精度已經被超越,目前應用最廣的算法,估計非深度學習莫屬,而且,傳統機器學習的計算量與深度學習比起來少很多,所以,討論AI芯片時就針對計算量特別大的深度學習而言。畢竟,計算量小的算法,說實話,CPU已經很快了。而且,CPU適合執行調度復雜的算法,這一點是GPU與AI芯片都做不到的,所以他們三者只是針對不同的應用場景而已,都有各自的主場。
AI芯片的分類及技術
人工智能芯片目前有兩種發展路徑:一種是延續傳統計算架構,加速硬件計算能力,主要以3種類型的芯片為代表,即GPU、FPGA、ASIC,但CPU依舊發揮著不可替代的作用;另一種是顛覆經典的馮·諾依曼計算架構,采用類腦神經結構來提升計算能力,以IBM TrueNorth芯片為代表。
傳統的CPU
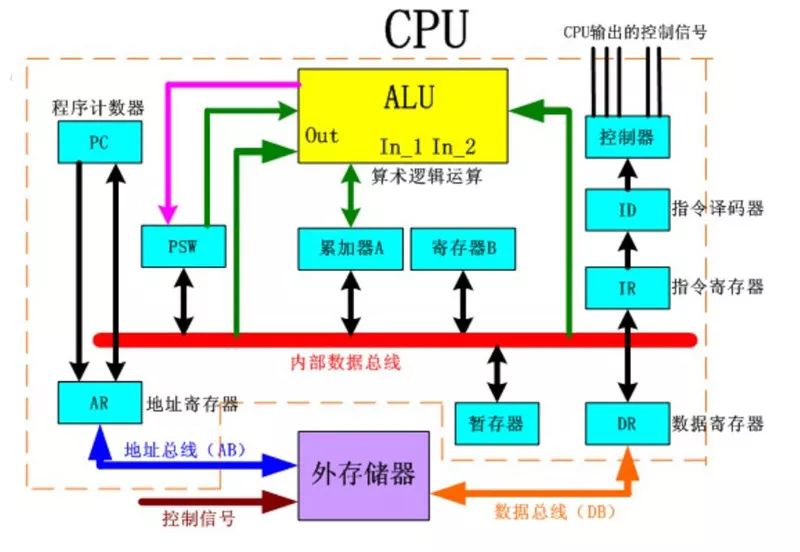
計算機工業從1960年代早期開始使用CPU這個術語。迄今為止,CPU從形態、設計到實現都已發生了巨大的變化,但是其基本工作原理卻一直沒有大的改變。通常CPU由控制器和運算器這兩個主要部件組成。傳統的CPU內部結構圖如圖3所示,從圖中我們可以看到:實質上僅單獨的ALU模塊(邏輯運算單元)是用來完成數據計算的,其他各個模塊的存在都是為了保證指令能夠一條接一條的有序執行。這種通用性結構對于傳統的編程計算模式非常適合,同時可以通過提升CPU主頻(提升單位時間內執行指令的條數)來提升計算速度。但對于深度學習中的并不需要太多的程序指令、卻需要海量數據運算的計算需求,這種結構就顯得有些力不從心。尤其是在功耗限制下,無法通過無限制的提升CPU和內存的工作頻率來加快指令執行速度,這種情況導致CPU系統的發展遇到不可逾越的瓶頸。
并行加速計算的GPU
GPU作為最早從事并行加速計算的處理器,相比CPU速度快,同時比其他加速器芯片編程靈活簡單。
傳統的CPU之所以不適合人工智能算法的執行,主要原因在于其計算指令遵循串行執行的方式,沒能發揮出芯片的全部潛力。與之不同的是,GPU具有高并行結構,在處理圖形數據和復雜算法方面擁有比CPU更高的效率。對比GPU和CPU在結構上的差異,CPU大部分面積為控制器和寄存器,而GPU擁有更ALU(ARITHMETIC LOGIC UNIT,邏輯運算單元)用于數據處理,這樣的結構適合對密集型數據進行并行處理,CPU與GPU的結構對比如圖所示。程序在GPU系統上的運行速度相較于單核CPU往往提升幾十倍乃至上千倍。隨著英偉達、AMD等公司不斷推進其對GPU大規模并行架構的支持,面向通用計算的GPU(即GPGPU,GENERAL PURPOSE GPU,通用計算圖形處理器)已成為加速可并行應用程序的重要手段。
GPU的發展歷程如圖所示:
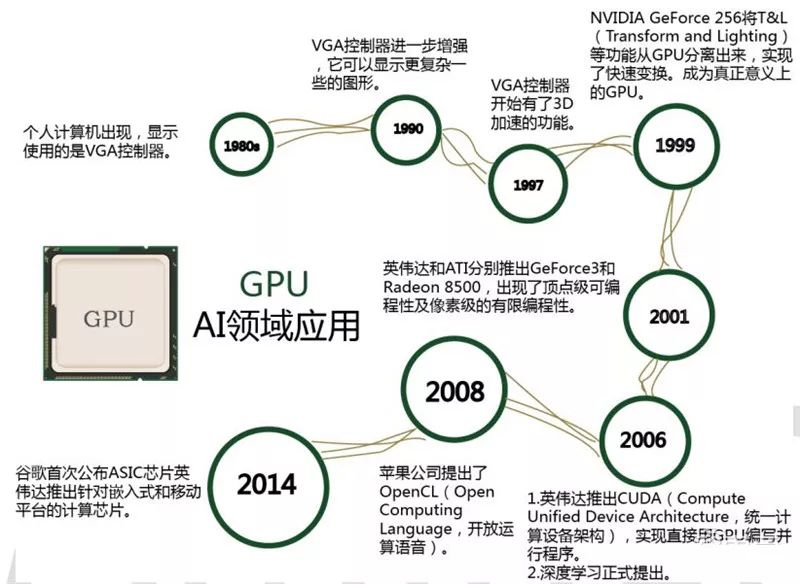
目前,GPU已經發展到較為成熟的階段。谷歌、FACEBOOK、微軟、TWITTER和百度等公司都在使用GPU分析圖片、視頻和音頻文件,以改進搜索和圖像標簽等應用功能。此外,很多汽車生產商也在使用GPU芯片發展無人駕駛。不僅如此,GPU也被應用于VR/AR相關的產業。但是GPU也有一定的局限性。深度學習算法分為訓練和推斷兩部分,GPU平臺在算法訓練上非常高效。但在推斷中對于單項輸入進行處理的時候,并行計算的優勢不能完全發揮出來。
半定制化的FPGA
FPGA是在PAL、GAL、CPLD等可編程器件基礎上進一步發展的產物。用戶可以通過燒入FPGA配置文件來定義這些門電路以及存儲器之間的連線。這種燒入不是一次性的,比如用戶可以把FPGA配置成一個微控制器MCU,使用完畢后可以編輯配置文件把同一個FPGA配置成一個音頻編解碼器。因此,它既解決了定制電路靈活性的不足,又克服了原有可編程器件門電路數有限的缺點。
FPGA可同時進行數據并行和任務并行計算,在處理特定應用時有更加明顯的效率提升。對于某個特定運算,通用CPU可能需要多個時鐘周期;而FPGA可以通過編程重組電路,直接生成專用電路,僅消耗少量甚至一次時鐘周期就可完成運算。
此外,由于FPGA的靈活性,很多使用通用處理器或ASIC難以實現的底層硬件控制操作技術,利用FPGA可以很方便的實現。這個特性為算法的功能實現和優化留出了更大空間。同時FPGA一次性成本(光刻掩模制作成本)遠低于ASIC,在芯片需求還未成規模、深度學習算法暫未穩定,需要不斷迭代改進的情況下,利用FPGA芯片具備可重構的特性來實現半定制的人工智能芯片是最佳選擇之一。
功耗方面,從體系結構而言,FPGA也具有天生的優勢。傳統的馮氏結構中,執行單元(如CPU核)執行任意指令,都需要有指令存儲器、譯碼器、各種指令的運算器及分支跳轉處理邏輯參與運行,而FPGA每個邏輯單元的功能在重編程(即燒入)時就已經確定,不需要指令,無需共享內存,從而可以極大的降低單位執行的功耗,提高整體的能耗比。
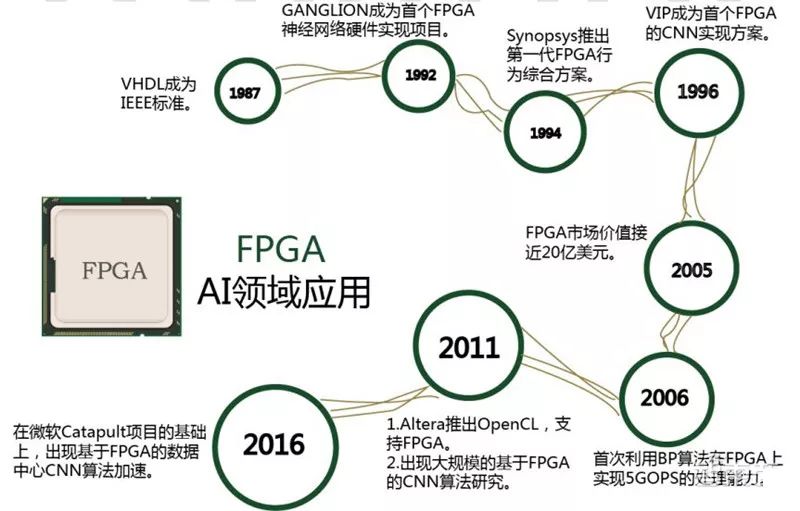
由于FPGA具備靈活快速的特點,因此在眾多領域都有替代ASIC的趨勢。FPGA在人工智能領域的應用如圖所示。
全定制化的ASIC
目前以深度學習為代表的人工智能計算需求,主要采用GPU、FPGA等已有的適合并行計算的通用芯片來實現加速。在產業應用沒有大規模興起之時,使用這類已有的通用芯片可以避免專門研發定制芯片(ASIC)的高投入和高風險。但是,由于這類通用芯片設計初衷并非專門針對深度學習,因而天然存在性能、功耗等方面的局限性。隨著人工智能應用規模的擴大,這類問題日益突顯。
GPU作為圖像處理器,設計初衷是為了應對圖像處理中的大規模并行計算。因此,在應用于深度學習算法時,有三個方面的局限性:第一,應用過程中無法充分發揮并行計算優勢。深度學習包含訓練和推斷兩個計算環節,GPU在深度學習算法訓練上非常高效,但對于單一輸入進行推斷的場合,并行度的優勢不能完全發揮。第二,無法靈活配置硬件結構。GPU采用SIMT計算模式,硬件結構相對固定。目前深度學習算法還未完全穩定,若深度學習算法發生大的變化,GPU無法像FPGA一樣可以靈活的配制硬件結構。第三,運行深度學習算法能效低于FPGA。
盡管FPGA倍受看好,甚至新一代百度大腦也是基于FPGA平臺研發,但其畢竟不是專門為了適用深度學習算法而研發,實際應用中也存在諸多局限:第一,基本單元的計算能力有限。為了實現可重構特性,FPGA內部有大量極細粒度的基本單元,但是每個單元的計算能力(主要依靠LUT查找表)都遠遠低于CPU和GPU中的ALU模塊;第二、計算資源占比相對較低。為實現可重構特性,FPGA內部大量資源被用于可配置的片上路由與連線;第三,速度和功耗相對專用定制芯片(ASIC)仍然存在不小差距;第四,FPGA價格較為昂貴,在規模放量的情況下單塊FPGA的成本要遠高于專用定制芯片。
深度學習算法穩定后,AI芯片可采用ASIC設計方法進行全定制,使性能、功耗和面積等指標面向深度學習算法做到最優。
類腦芯片
類腦芯片不采用經典的馮·諾依曼架構,而是基于神經形態架構設計,以IBM Truenorth為代表。IBM研究人員將存儲單元作為突觸、計算單元作為神經元、傳輸單元作為軸突搭建了神經芯片的原型。目前,Truenorth用三星28nm功耗工藝技術,由54億個晶體管組成的芯片構成的片上網絡有4096個神經突觸核心,實時作業功耗僅為70mW。由于神經突觸要求權重可變且要有記憶功能,IBM采用與CMOS工藝兼容的相變非揮發存儲器(PCM)的技術實驗性的實現了新型突觸,加快了商業化進程。
AI芯片應用領域
隨著人工智能芯片的持續發展,應用領域會隨時間推移而不斷向多維方向發展。
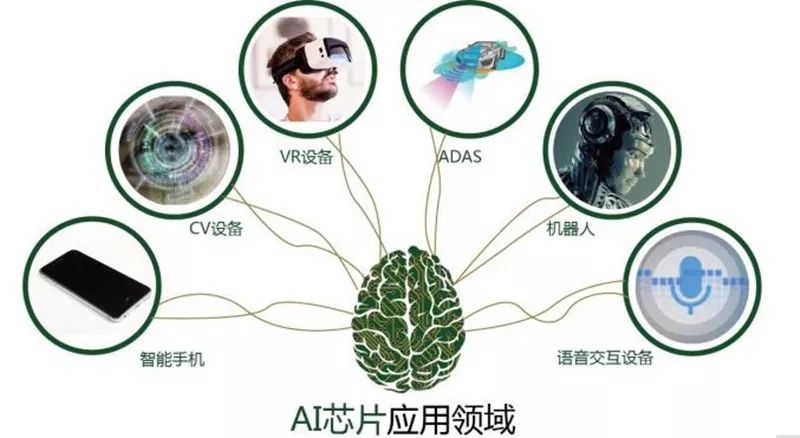
智能手機
2017年9月,華為在德國柏林消費電子展發布了麒麟970芯片,該芯片搭載了寒武紀的NPU,成為“全球首款智能手機移動端AI芯片”;2017年10月中旬Mate10系列新品(該系列手機的處理器為麒麟970)上市。搭載了NPU的華為Mate10系列智能手機具備了較強的深度學習、本地端推斷能力,讓各類基于深度神經網絡的攝影、圖像處理應用能夠為用戶提供更加完美的體驗。
而蘋果發布以iPhone X為代表的手機及它們內置的A11 Bionic芯片。A11 Bionic中自主研發的雙核架構Neural Engine(神經網絡處理引擎),它每秒處理相應神經網絡計算需求的次數可達6000億次。這個Neural Engine的出現,讓A11 Bionic成為一塊真正的AI芯片。A11 Bionic大大提升了iPhone X在拍照方面的使用體驗,并提供了一些富有創意的新用法。
ADAS(高級輔助駕駛系統)
ADAS是最吸引大眾眼球的人工智能應用之一,它需要處理海量的由激光雷達、毫米波雷達、攝像頭等傳感器采集的實時數據。相對于傳統的車輛控制方法,智能控制方法主要體現在對控制對象模型的運用和綜合信息學習運用上,包括神經網絡控制和深度學習方法等。
CV(計算機視覺(Computer Vision)設備
需要使用計算機視覺技術的設備,如智能攝像頭、無人機、行車記錄儀、人臉識別迎賓機器人以及智能手寫板等設備,往往都具有本地端推斷的需要,如果僅能在聯網下工作,無疑將帶來糟糕的體驗。而計算機視覺技術目前看來將會成為人工智能應用的沃土之一,計算機視覺芯片將擁有廣闊的市場前景。
VR設備
VR設備芯片的代表為HPU芯片,是微軟為自身VR設備Hololens研發定制的。這顆由臺積電代工的芯片能同時處理來自5個攝像頭、1個深度傳感器以及運動傳感器的數據,并具備計算機視覺的矩陣運算和CNN運算的加速功能。這使得VR設備可重建高質量的人像3D影像,并實時傳送到任何地方。
語音交互設備
語音交互設備芯片方面,國內有啟英泰倫以及云知聲兩家公司,其提供的芯片方案均內置了為語音識別而優化的深度神經網絡加速方案,實現設備的語音離線識別。穩定的識別能力為語音技術的落地提供了可能;與此同時,語音交互的核心環節也取得重大突破。語音識別環節突破了單點能力,從遠場識別,到語音分析和語義理解有了重大突破,呈現出一種整體的交互方案。
機器人
無論是家居機器人還是商用服務機器人均需要專用軟件+芯片的人工智能解決方案,這方面典型公司有由前百度深度學習實驗室負責人余凱創辦的地平線機器人,當然地平線機器人除此之外,還提供ADAS、智能家居等其他嵌入式人工智能解決方案。
編輯:lyn
-
機器人
+關注
關注
210文章
28191瀏覽量
206505 -
人工智能
+關注
關注
1791文章
46845瀏覽量
237535 -
CV
+關注
關注
0文章
52瀏覽量
16852 -
vr
+關注
關注
34文章
9633瀏覽量
150055 -
AI芯片
+關注
關注
17文章
1859瀏覽量
34908
原文標題:當芯片有了AI思維
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論