 不同拓撲結構的并行粒子群優化算法如何去實現?
不同拓撲結構的并行粒子群優化算法如何去實現?
摘 要: 針對粒子群優化算法的鄰域拓撲結構對算法性能有重要影響、PSO算法在CPU上求解最優化問題時計算效率低下這兩點,分析了鄰域拓撲結構改變時PSO算法的并行特征,實現了環形和星形拓撲結構的PSO算法在統一計算設備架構上的尋優過程。分別在CPU和GPU上用兩種PSO算法對7個benchmark測試函數進行求解。程序仿真結果顯示,基于CUDA的PSO算法計算效率均大大高于CPU;同時發現,GPU顯著地加快了星形結構PSO算法的收斂速度,而對環形結構PSO算法影響不大。
料子群優化PSO(Particle Swarm Optimization)算法最早于1995年由EBERHART博士和KENNEDY博士提出[1],由于實現容易、精度高和收斂快等優點,引起了學術界的重視,并且在實際問題的解決中展示了其優越性。
近年來,針對基本PSO算法易陷入局部極值,求解某些問題時精度不足的缺點[1],研究人員們提出了各種改進算法,包括參數調整[2],改變搜索網絡空間[3-4],混合其他算法[5-6]等。目前,PSO算法作為優化工具成功應用于多個領域,如無線傳感器網絡(WSN)覆蓋問題的研究[7]。PSO算法性能對社會網絡結構具有強烈的依賴性[1,3-4],鄰域拓撲結構的改變對PSO算法的收斂性有重要作用。
求解高維復雜函數時,傳統PSO算法因需處理大量數據,致計算效率過低,研究人員基于算法本身特性提出了各種并行PSO算法[8-10],均取得了至少10倍以上的加速比。GPU起初只是負責圖形渲染,直到2006年公布了GeForce系列GPU,GPU才開始應用于通用計算[11]。GPU和CPU的協同工作,現已被廣泛應用于石油勘探[12]、生物計算[13]等領域。本文借助于CUDA平臺,對鄰域拓撲結構發生變化時的PSO算法進行了探究,驗證了并行計算平臺的高效性,同時探索了并行計算平臺對星形和環形PSO算法收斂性的影響。
1 標準PSO算法
PSO算法[1]源于對鳥類覓食過程的模擬:將每只鳥看成D維空間中沒有質量和體積的微粒,這些微粒以一定速度飛行,速度由個體的飛行經驗和群體的飛行經驗進行動態調整。
標準PSO算法的速度和位置更新方程如下:
v(t+1)=?棕v(t)+c1×r1×(p(t)-x(t))+c2×r2×(pg(t)-x(t))(1)
x(t+1)=x(t)+v(t+1)(2)
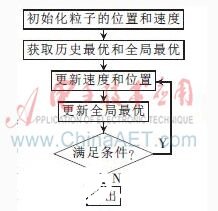
其中,v(t)=(v1,v2,…,vd)為當前微粒在第t代的速度;為慣性權重,文中取?棕=0.5;c1為認知系數;c2為社會系數,通常取c1=c2=2;r1,r2為服從均勻分布的0~1之間的隨機數;p(t)=(p1,p2,…,pd)為當前微粒的歷史最優位置;x(t)=(x1,x2,…,xd)為當前微粒在第t代的位置;p(t)=(pg1,pg2,…,pgd)為群體歷史最優位置。典型的標準PSO算法的尋優流程如圖所示。
2 PSO算法的拓撲結構
為提高PSO算法的性能,參考文獻[3-4]提出了不同類型的拓撲結構,包括動態拓撲和靜態拓撲。KENNEDY J對在各種靜態鄰域結構中的PSO算法性能進行了分析[1],認為星型、環型和Von Neumann拓撲適用性最好,并稱小鄰域的PSO算法在復雜問題上性能較好,大鄰域的PSO算法在簡單問題上性能更好,在本實驗中得到進一步論證。
分別為星形和環形拓撲圖,星形PSO算法中所有粒子全部相聯,每個粒子都可以同除自己以外的其他粒子通信,以共享整個群體最佳解;環形網絡結構中每個粒子跟它的n個鄰居通信,每個粒子向鄰域內的最優位置靠攏,來更新自己的位置,可見,每個粒子只是共享所在鄰域內的最優解,即局部最優,而全局最優流動在整個環形網絡中。
除以上兩種基本拓撲結構外,還有馮諾依曼型、輪型、金字塔型、四聚類型結構和一些基于這幾種結構的改進拓撲[1,3-4],其中普遍認為馮諾依曼結構在解決大多數問題時要優于其他結構[1]。當然,并不存在對所有問題都適用的最好拓撲。
3 CUDA及CUDAC
3.1 CUDA編程模型
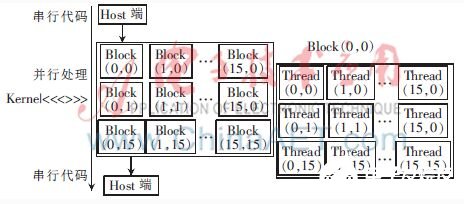
統一計算設備架構CUDA(Compute Unified Device Arch-itecture),在CUDA編程模型中,CPU為主機(Host)端,GPU作為協處理器,兩者各自擁有獨立的存儲器和各自的編譯器[14-15]。一個完整的CUDA編程模型如圖4所示:程序執行始于主機,止于主機。圖中Kernel并行處理部分為基于單指令多線程SIMD(Single Instruction Multiple Thread)計算模型,線程被CUDA組織成3個不同的層次:線程(Thread)、線程塊(Block)以及線程格(Grid)。
3.2 CUDA存儲器模型
線程在執行指令時,需訪問處于不同存儲器的數據,而對各類存儲器的訪問速度差異很大[13]。CUDA存儲器分為3層:(1)私有本地存儲器(private local memory),容量小,訪問速度快;(2)全局存儲器(global memory),所有線程都可訪問,訪問速度慢;(3)共享存儲器(shared memory),屬于片上存儲器,訪問速度與寄存器相當,定義共享類型變量時需使用限定符__shared__。
3.3 CUDA C
CUDA C是對C的擴展,為程序員提供了一種用C語言在設備上編寫代碼的編程方式。主要擴展[14-15]:(1)引入__device__,__host__和__global__3個限定符,限定函數調用和執行的位置;(2)引入4個內置變量,blockIdx,threadIdx,gridDim和blockDim;(3)引入<<<>>>運算符,內含4個參數,主要用于設置線程格和線程塊的尺寸;(4)擴展了一些數學函數庫,如CURAND[16]。
4 基于CUDA的PSO算法
4.1 PSO算法的并行編程
群體中各粒子只在更新全局最優時互相交換信息,其他步驟均相互獨立。獲取歷史最優時,一個線程對應一個粒子,各線程同時調用適應函數;更新位置和速度時,一個線程對應粒子的每一維;均按線程索引來讀取數據并處理。
主機端初始化粒子的位置和速度,將數據從CPU復制到GPU上,在設備上迭代尋優,最后將最優解復制到CPU輸出。表1列出了實現各部分功能的函數,獲取全局最優值時,星形結構可以通過線程歸約比較獲取全局最優,環形結構由于多鄰域而相對復雜,在后續部分詳述。
4.2 環形PSO算法尋優過程
星形PSO算法獲取全局最優較為簡單,不作分析,環形PSO算法在獲取局部最優時,文中設定每個粒子只有左右兩個鄰居。在編寫該部分程序時,設置讓相鄰線程訪問索引間隔為3的共享內存中的數據,這種方法避開了bank沖突,但以時間消耗作為代價。各線程具體負責找出粒子的歷史最優值.
找出歷史最優值的方式有以下兩種情形(其中N為粒子規模):
(1)N%3=0時,各線程按圖5所示處理相應的數據,3次并行運行即可得到每個粒子在其鄰域內的局部最優。
(2)N%3≠0時,將圖5中N令為N-N%3,按情形(1)可以得到0~N-N%3-1號粒子在其鄰域內的局部最優,再對余下的1或2個粒子依次找出其鄰域內局部最優。
由于環型PSO算法有N個局部最優值,設備上尋優結束后,需將N個局部最優從GPU復制到CPU進行比較,最后輸出全局最佳解。
4.3 CUDA程序性能優化
GPU性能雖然出色,但很大程度上受限于算法本身[15]。在CUDA的使用中,數據結構和對內存的訪問對GPU性能有極大地影響,有時甚至起決定性作用。文中實驗程序對CUDA性能優化,主要考慮了以下4個方面:(1)最大化并行性;(2)優化內存訪問以獲得最大的帶寬;(3)優化指令使用以獲得最大指令的吞吐量;(4)線程塊和線程數的設置,實驗表明當設置線程塊數為32,每個塊中線程數為256時獲得最高效率。
5 結論分析
5.1 計算時間對比
在獨立的CPU和CPU+GPU并行計算平臺上,分別對以下7個benchmark函數進行了測試,其中D表示粒子的維數,xi的范圍表示搜索空間。
(1)Sphere函數
f1(x)=x,|xi|≤15(3)
(2)Ackley函數
f2(x)=20exp-0.2-
expcos(2πoi)+20+e),|xi|≤15(4)
(3)Schwefel函數
f3=418.928×D-xisin(),|xi|≤500(5)
(4)Levy函數
f4=sin2(πyl)+[(yi-1)2×(1+10sin2(πyi+1))]+(yD-1)2(1+sin2(2π2n)) yi=1+,|xi|≤10(6)
(5)Griewank函數
f5+1,|xi|≤600(7)
(6)Rastrigin函數
f6=10cos(2ππi)+10],|xi|≤5.12(8)
(7)Rosenbrock函數
f7=xi+12+(xi-1)2,-5≤xi≤10(9)
星形結構和環形結構PSO算法在CPU和CUDA上的運行時間如表2所示,測試時取粒子數為1 000,粒子維數為50,迭代次數為5 000。表中數據經多次測試,取均值得到。表2顯示,相同條件下,GPU和CPU上的環型PSO算法均略慢于星型。還可以看到,函數越復雜,加速比越大。并經多次測試比較發現,迭代次數增加,加速比增大。表3為迭代次數為10 000時的函數f1~f7求解時間。
表4列出了維數50,粒子數為500,迭代次數10 000時,星形和環形PSO算法求解函數f1~f7的時間。對比表3和表4,可知粒子數為500時的加速比明顯要低于粒子數為1 000時,對比表2和表4發現,盡管迭代變大,而粒子數較大時加速比越大,說明種群規模對加速比的影響要大于迭代數。這正體現了PSO算法粒子的并行性,粒子規模越大,在GPU上的并行處理越具優勢;反而當粒子數較小時,由于并行前后CPU和GPU之間的通信所需時間隱藏被弱化,此時在GPU上運行不占任何優勢,有時甚至差于CPU。進一步說明了GPU適用于大規模數據并行運算中。
5.2 收斂性對比
除計算效率極大提升外,GPU還加快了星型PSO算法的收斂速度。圖6描繪了兩種結構PSO算法在CPU和GPU上求解函數f2的收斂曲線,實驗取粒子數500,維數50,迭代次數從0逐漸增大,基于算法本身的隨機性,記錄最優解數據時對指定的迭代數循環100次,取其平均值。
可見,迭代早期兩種結構PSO算法的收斂速度相差不大,而隨著迭代增大,星形PSO算法的收斂速度明顯加快。實驗結果還表明,對于環形PSO算法,GPU并未加快收斂,而對于星形結構,GPU明顯加快了算法的收斂速度。其余6個benchmark函數的求解也表明,GPU確實加快了星形PSO算法的收斂速度。
本實驗GPU顯卡型號為NVIDIA GeForce GT 630M,CUDA計算能力為2.1。圖表中僅列出了粒子數和迭代數改變時加速比的變化情況,維數的改變對加速比也有重要影響。PSO算法的這種并行策略,在遺傳算法、蟻群算法、文化算法及一些混合算法中具有較強的通用性,可以很大地提高搜索效率。PSO作為一種新興進化算法,各種研究工作種類繁多,在函數優化、多目標優化、約束優化、算法結構改進、應用工程領域等方面[17]均取得重大成果,而CUDA作為一種新興計算平臺,必將推動PSO算法的發展。
參考文獻
[1] KENNEDY J, EBERHART R C. Particle swarm optimiza-tion[C]. Proceedings of IEEE International Conference on Neural Networks, Piscataway, 1995:1942-1948.
[2] 延麗平,曾建潮.具有自適應隨機慣性權重的PSO算法[J].計算機工程與設計,2006,27(24):4677-4679,4706.
[3] 楊道平.粒子群算法鄰域拓撲結構研究[J].中國高新技術企業評價,2009,(16):36-37.
[4] 姚燦中,楊建梅.基于網絡鄰域拓撲的粒子群優化算法[J].計算機工程,2010,36(19):18-20.
[5] 王志,胡小兵,何雪海,等.一種新的差分與粒子群算法的混合算法[J].計算機工程與應用,2012,48(6):46-48.
[6] 易文周,張超英,王強,等.基于改進PSO和DE的混合算法[J].計算機工程,2010,36(10):233-235.
[7] 史朝亞,樊春麗.基于PSO算法的無線傳感器網絡覆蓋的研究[D].南京:南京理工大學,2013.
[8] You Zhou, Ying Tan. GPU-based parallel part- icle swarm optimization[J]. Proceedings of IEEE International Conference on Evolutionary Computation, 2009:1493-1500.
[9] LUCAS DE P VERONESE, RENATO A K-ROHLING. Swarm′s flight: accelerating the particles using C-CUDA[C]. Proceedings of IEEE International Conference on Evolutionary Computation,2009:3264-3270.
[10] 蔡勇,李光耀,王琥.基于CUDA的并行粒子群優化算法的設計與實現[J].計算機應用研究,2013,30(8):2415-2418.
[11] 劉金碩,劉天曉,吳慧,等.從圖形處理器到基于GPU的通用計算[J].武漢大學學報(理學版),2013,59(2):198-199.
[12] 張兵,趙改善,黃俊,等.地震疊前深度偏移在CUDA上的實現[J].勘探地球物理進展,2008,31(6):427-430.
[13] 余林彬,徐云.基于CUDA的高性能計算研究及生物信息學應用[D].合肥:中國科學技術大學,2009.
[14] NVIDIA. NVIDIA CUDA Programming Guide Version 2.3.1[EB/OL].https://developer.nvidia.com/category/zone/cuda-zone[2007].
[15] 張舒,褚艷利,趙開勇,等.GPU高性能運算之CUDA[M].北京:中國水利水電出版社,2009.
[16] NVIDIA. NVIDIA CUDA CURAND Library[EB/OL]. http://docs.nvidia.com/cuda/curand/index.html[2010].
[17] 倪慶劍,邢漢承,張志政,等.粒子群優化算法研究進展[J].模式識別與人工智能,2007,20(3):350-357.
編輯:jq
-
cpu
+關注
關注
68文章
10826瀏覽量
211160 -
PSO
+關注
關注
0文章
49瀏覽量
12921 -
粒子群優化算法
+關注
關注
0文章
14瀏覽量
2496
發布評論請先 登錄
相關推薦
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+內容簡介
三電平dcdc拓撲結構有幾種
開關電源幾種拓撲結構介紹
什么是Mesh?Mesh組網拓撲結構淺析
網絡拓撲結構有哪幾種類型 網絡拓撲結構的優缺點
網絡拓撲結構的隱患和網絡硬件的安全缺陷屬于
什么是計算機網絡的拓撲結構?主要的拓撲結構有哪些?
網絡拓撲結構有哪幾種類型 網絡拓撲結構優缺點
網絡拓撲結構有幾種?各有什么優缺點?
三電平拓撲結構的脈沖整流器的優缺點
DDR拓撲結構的詳細解析


盤點GPU Fabric典型拓撲結構





 工商網監
工商網監
評論