 使用Redis時可能遇到哪些「坑」?
使用Redis時可能遇到哪些「坑」?
這篇文章,我想和你聊一聊在使用 Redis 時,可能會踩到的「坑」。
如果你在使用 Redis 時,也遇到過以下這些「詭異」的場景,那很大概率是踩到「坑」了:
明明一個 key 設置了過期時間,怎么變成不過期了?
使用 O(1) 復雜度的 SETBIT 命令,Redis 竟然被 OOM 了?
執行 RANDOMKEY 隨機拿出一個 key,竟然也會阻塞 Redis?
同樣的命令,為什么主庫查不到數據,從庫卻可以查到?
從庫內存為什么比主庫用得還多?
寫入到 Redis 的數據,為什么莫名其妙丟了?
究竟是什么原因,導致的這些問題呢?
這篇文章,我就來和你盤點一下,使用 Redis 時可能會踩到「坑」,以及如何去規避。
我把這些問題劃分成了三大部分:
常見命令有哪些坑?
數據持久化有哪些坑?
主從庫同步有哪些坑?
導致這些問題的原因,很有可能會「顛覆」你的認知,如果你準備好了,那就跟著我的思路開始吧!
這篇文章干貨很多,希望你可以耐心讀完。
常見命令有哪些坑?
首先,我們來看一下,平時在使用 Redis 時,有哪些常見的命令會遇到「意料之外」的結果。
1) 過期時間意外丟失?
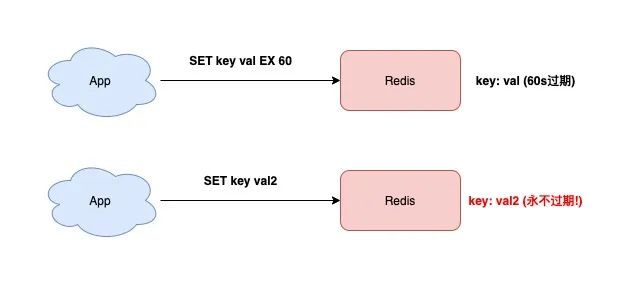
你在使用 Redis 時,肯定經常使用 SET 命令,它非常簡單。
SET 除了可以設置 key-value 之外,還可以設置 key 的過期時間,就像下面這樣:
127.0.0.1:6379》 SET testkey val1 EX 60 OK 127.0.0.1:6379》 TTL testkey (integer) 59
此時如果你想修改 key 的值,但只是單純地使用 SET 命令,而沒有加上「過期時間」的參數,那這個 key 的過期時間將會被「擦除」。
127.0.0.1:6379》 SET testkey val2 OK 127.0.0.1:6379》 TTL testkey // key永遠不過期了! (integer) -1
看到了么?testkey 變成永遠不過期了!
如果你剛剛開始使用 Redis,相信你肯定也踩過這個坑。
導致這個問題的原因在于:SET 命令如果不設置過期時間,那么 Redis 會自動「擦除」這個 key 的過期時間。
如果你發現 Redis 的內存持續增長,而且很多 key 原來設置了過期時間,后來發現過期時間丟失了,很有可能是因為這個原因導致的。
這時你的 Redis 中就會存在大量不過期的 key,消耗過多的內存資源。
所以,你在使用 SET 命令時,如果剛開始就設置了過期時間,那么之后修改這個 key,也務必要加上過期時間的參數,避免過期時間丟失問題。
2) DEL 竟然也會阻塞 Redis?
刪除一個 key,你肯定會用 DEL 命令,不知道你沒有思考過它的時間復雜度是多少?
O(1)?其實不一定。
如果你有認真閱讀 Redis 的官方文檔,就會發現:刪除一個 key 的耗時,與這個 key 的類型有關。
Redis 官方文檔在介紹 DEL 命令時,是這樣描述的:
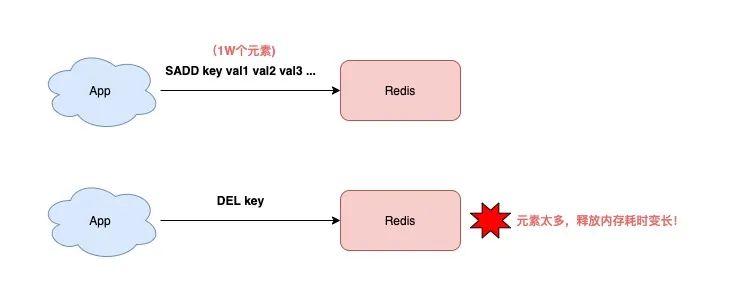
key 是 String 類型,DEL 時間復雜度是 O(1)
key 是 List/Hash/Set/ZSet 類型,DEL 時間復雜度是 O(M),M 為元素數量
也就是說,如果你要刪除的是一個非 String 類型的 key,這個 key 的元素越多,那么在執行 DEL 時耗時就越久!
為什么會這樣?
原因在于,刪除這種 key 時,Redis 需要依次釋放每個元素的內存,元素越多,這個過程就會越耗時。
而這么長的操作耗時,勢必會阻塞整個 Redis 實例,影響 Redis 的性能。
所以,當你在刪除 List/Hash/Set/ZSet 類型的 key 時,一定要格外注意,不能無腦執行 DEL,而是應該用以下方式刪除:
查詢元素數量:執行 LLEN/HLEN/SCARD/ZCARD 命令
判斷元素數量:如果元素數量較少,可直接執行 DEL 刪除,否則分批刪除
分批刪除:執行 LRANGE/HSCAN/SSCAN/ZSCAN + LPOP/RPOP/HDEL/SREM/ZREM 刪除
了解了 DEL 對于 List/Hash/Set/ZSet 類型數據的影響,我們再來分析下,刪除一個 String 類型的 key 會不會有這種問題?
啊?前面不是提到,Redis 官方文檔的描述,刪除 String 類型的 key,時間復雜度是 O(1) 么?這不會導致 Redis 阻塞吧?
其實這也不一定!
你思考一下,如果這個 key 占用的內存非常大呢?
例如,這個 key 存儲了 500MB 的數據(很明顯,它是一個 bigkey),那在執行 DEL 時,耗時依舊會變長!
這是因為,Redis 釋放這么大的內存給操作系統,也是需要時間的,所以操作耗時也會變長。
所以,對于 String 類型來說,你最好也不要存儲過大的數據,否則在刪除它時,也會有性能問題。
此時,你可能會想:Redis 4.0 不是推出了 lazy-free 機制么?打開這個機制,釋放內存的操作會放到后臺線程中執行,那是不是就不會阻塞主線程了?
這個問題非常好。
真的會是這樣嗎?
這里我先告訴你結論:即使 Redis 打開了 lazy-free,在刪除一個 String 類型的 bigkey 時,它仍舊是在主線程中處理,而不是放到后臺線程中執行。所以,依舊有阻塞 Redis 的風險!
這是為什么?
這里先賣一個關子,感興趣的同學可以先自行查閱 lazy-free 相關資料尋找答案。:)
其實,關于 lazy-free 的知識點也很多,由于篇幅原因,所以我打算后面專門寫一篇文章來講,歡迎持續關注~
3) RANDOMKEY 竟然也會阻塞 Redis?
如果你想隨機查看 Redis 中的一個 key,通常會使用 RANDOMKEY 這個命令。
這個命令會從 Redis 中「隨機」取出一個 key。
既然是隨機,那這個執行速度肯定非常快吧?
其實不然。
要解釋清楚這個問題,就要結合 Redis 的過期策略來講。
如果你對 Redis 的過期策略有所了解,應該知道 Redis 清理過期 key,是采用定時清理 + 懶惰清理 2 種方式結合來做的。
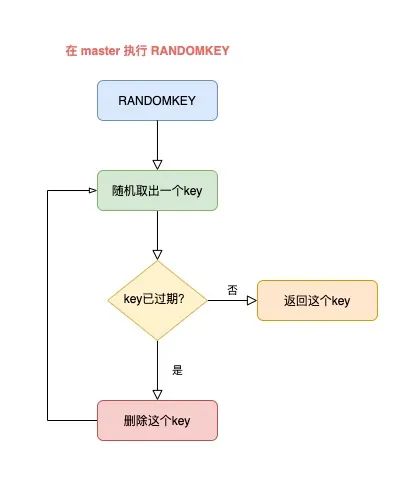
而 RANDOMKEY 在隨機拿出一個 key 后,首先會先檢查這個 key 是否已過期。
如果該 key 已經過期,那么 Redis 會刪除它,這個過程就是懶惰清理。
但清理完了還不能結束,Redis 還要找出一個「不過期」的 key,返回給客戶端。
此時,Redis 則會繼續隨機拿出一個 key,然后再判斷是它否過期,直到找出一個未過期的 key 返回給客戶端。
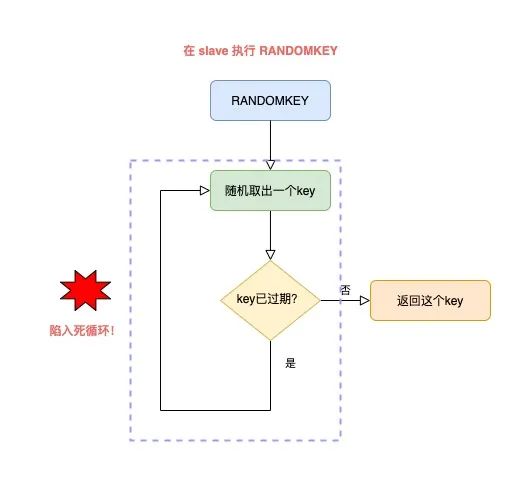
整個流程就是這樣的:
master 隨機取出一個 key,判斷是否已過期
如果 key 已過期,刪除它,繼續隨機取 key
以此循環往復,直到找到一個不過期的 key,返回
但這里就有一個問題了:如果此時 Redis 中,有大量 key 已經過期,但還未來得及被清理掉,那這個循環就會持續很久才能結束,而且,這個耗時都花費在了清理過期 key + 尋找不過期 key 上。
導致的結果就是,RANDOMKEY 執行耗時變長,影響 Redis 性能。
以上流程,其實是在 master 上執行的。
如果在 slave 上執行 RANDOMEKY,那么問題會更嚴重!
為什么?
主要原因就在于,slave 自己是不會清理過期 key。
那 slave 什么時候刪除過期 key 呢?
其實,當一個 key 要過期時,master 會先清理刪除它,之后 master 向 slave 發送一個 DEL 命令,告知 slave 也刪除這個 key,以此達到主從庫的數據一致性。
還是同樣的場景:Redis 中存在大量已過期,但還未被清理的 key,那在 slave 上執行 RANDOMKEY 時,就會發生以下問題:
slave 隨機取出一個 key,判斷是否已過期
key 已過期,但 slave 不會刪除它,而是繼續隨機尋找不過期的 key
由于大量 key 都已過期,那 slave 就會尋找不到符合條件的 key,此時就會陷入「死循環」!
也就是說,在 slave 上執行 RANDOMKEY,有可能會造成整個 Redis 實例卡死!
是不是沒想到?在 slave 上隨機拿一個 key,竟然有可能造成這么嚴重的后果?
這其實是 Redis 的一個 Bug,這個 Bug 一直持續到 5.0 才被修復。
修復的解決方案是,在 slave 上執行 RANDOMKEY 時,會先判斷整個實例所有 key 是否都設置了過期時間,如果是,為了避免長時間找不到符合條件的 key,slave 最多只會在哈希表中尋找 100 次,無論是否能找到,都會退出循環。
這個方案就是增加上了一個最大重試次數,這樣一來,就避免了陷入死循環。
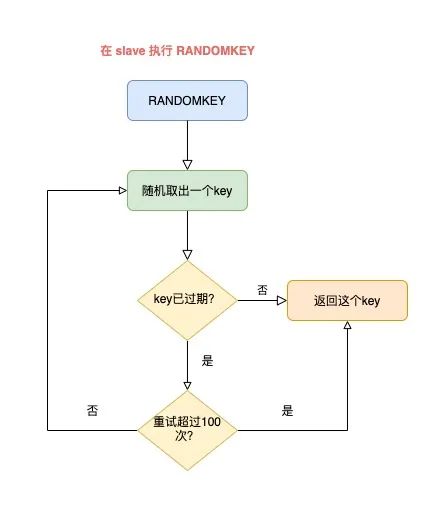
雖然這個方案可以避免了 slave 陷入死循環、卡死整個實例的問題,但是,在 master 上執行這個命令時,依舊有概率導致耗時變長。
所以,你在使用 RANDOMKEY 時,如果發現 Redis 發生了「抖動」,很有可能是因為這個原因導致的!
4) O(1) 復雜度的 SETBIT,竟然會導致 Redis OOM?
在使用 Redis 的 String 類型時,除了直接寫入一個字符串之外,還可以把它當做 bitmap 來用。
具體來講就是,我們可以把一個 String 類型的 key,拆分成一個個 bit 來操作,就像下面這樣:
127.0.0.1:6379》 SETBIT testkey 10 1 (integer) 1 127.0.0.1:6379》 GETBIT testkey 10 (integer) 1
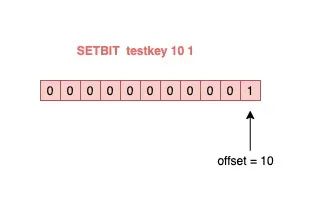
其中,操作的每一個 bit 位叫做 offset。
但是,這里有一個坑,你需要注意起來。
如果這個 key 不存在,或者 key 的內存使用很小,此時你要操作的 offset 非常大,那么 Redis 就需要分配「更大的內存空間」,這個操作耗時就會變長,影響性能。
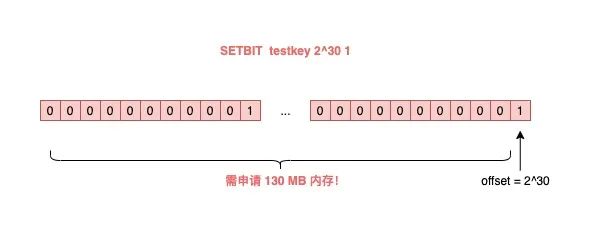
所以,當你在使用 SETBIT 時,也一定要注意 offset 的大小,操作過大的 offset 也會引發 Redis 卡頓。
這種類型的 key,也是典型的 bigkey,除了分配內存影響性能之外,在刪除它時,耗時同樣也會變長。
5) 執行 MONITOR 也會導致 Redis OOM?
這個坑你肯定聽說過很多次了。
當你在執行 MONITOR 命令時,Redis 會把每一條命令寫到客戶端的「輸出緩沖區」中,然后客戶端從這個緩沖區讀取服務端返回的結果。
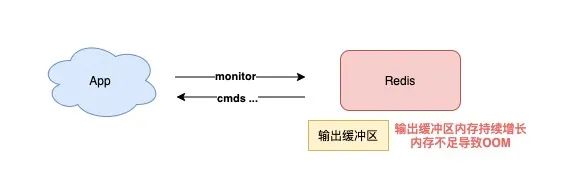
但是,如果你的 Redis QPS 很高,這將會導致這個輸出緩沖區內存持續增長,占用 Redis 大量的內存資源,如果恰好你的機器的內存資源不足,那 Redis 實例就會面臨被 OOM 的風險。
所以,你需要謹慎使用 MONITOR,尤其在 QPS 很高的情況下。
以上這些問題場景,都是我們在使用常見命令時發生的,而且,很可能都是「無意」就會觸發的。
下面我們來看 Redis「數據持久化」都存在哪些坑?
數據持久化有哪些坑?
Redis 的數據持久化,分為 RDB 和 AOF 兩種方式。
其中,RDB 是數據快照,而 AOF 會記錄每一個寫命令到日志文件中。
在數據持久化方面發生問題,主要也集中在這兩大塊,我們依次來看。
1) master 宕機,slave 數據也丟失了?
如果你的 Redis 采用如下模式部署,就會發生數據丟失的問題:
master-slave + 哨兵部署實例
master 沒有開啟數據持久化功能
Redis 進程使用 supervisor 管理,并配置為「進程宕機,自動重啟」
如果此時 master 宕機,就會導致下面的問題:
master 宕機,哨兵還未發起切換,此時 master 進程立即被 supervisor 自動拉起
但 master 沒有開啟任何數據持久化,啟動后是一個「空」實例
此時 slave 為了與 master 保持一致,它會自動「清空」實例中的所有數據,slave 也變成了一個「空」實例
看到了么?在這個場景下,master / slave 的數據就全部丟失了。
這時,業務應用在訪問 Redis 時,發現緩存中沒有任何數據,就會把請求全部打到后端數據庫上,這還會進一步引發「緩存雪崩」,對業務影響非常大。
所以,你一定要避免這種情況發生,我給你的建議是:
Redis 實例不使用進程管理工具自動拉起
master 宕機后,讓哨兵發起切換,把 slave 提升為 master
切換完成后,再重啟 master,讓其退化成 slave
你在配置數據持久化時,要避免這個問題的發生。
2) AOF everysec 真的不會阻塞主線程嗎?
當 Redis 開啟 AOF 時,需要配置 AOF 的刷盤策略。
基于性能和數據安全的平衡,你肯定會采用 appendfsync everysec 這種方案。
這種方案的工作模式為,Redis 的后臺線程每間隔 1 秒,就把 AOF page cache 的數據,刷到磁盤(fsync)上。
這種方案的優勢在于,把 AOF 刷盤的耗時操作,放到了后臺線程中去執行,避免了對主線程的影響。
但真的不會影響主線程嗎?
答案是否定的。
其實存在這樣一種場景:Redis 后臺線程在執行 AOF page cache 刷盤(fysnc)時,如果此時磁盤 IO 負載過高,那么調用 fsync 就會被阻塞住。
此時,主線程仍然接收寫請求進來,那么此時的主線程會先判斷,上一次后臺線程是否已刷盤成功。
如何判斷呢?
后臺線程在刷盤成功后,都會記錄刷盤的時間。
主線程會根據這個時間來判斷,距離上一次刷盤已經過去多久了。整個流程是這樣的:
主線程在寫 AOF page cache(write系統調用)前,先檢查后臺 fsync 是否已完成?
fsync 已完成,主線程直接寫 AOF page cache
fsync 未完成,則檢查距離上次 fsync 過去多久?
如果距離上次 fysnc 成功在 2 秒內,那么主線程會直接返回,不寫 AOF page cache
如果距離上次 fysnc 成功超過了 2 秒,那主線程會強制寫 AOF page cache(write系統調用)
由于磁盤 IO 負載過高,此時,后臺線程 fynsc 會發生阻塞,那主線程在寫 AOF page cache 時,也會發生阻塞等待(操作同一個 fd,fsync 和 write 是互斥的,一方必須等另一方成功才可以繼續執行,否則阻塞等待)
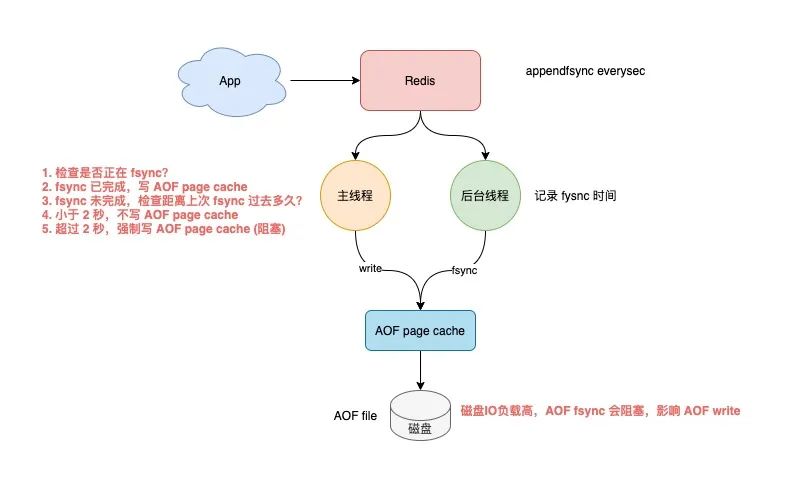
通過分析我們可以發現,即使你配置的 AOF 刷盤策略是 appendfsync everysec,也依舊會有阻塞主線程的風險。
其實,產生這個問題的重點在于,磁盤 IO 負載過高導致 fynsc 阻塞,進而導致主線程寫 AOF page cache 也發生阻塞。
所以,你一定要保證磁盤有充足的 IO 資源,避免這個問題。
3) AOF everysec 真的只會丟失 1 秒數據?
接著上面的問題繼續分析。
如上所述,這里我們需要重點關注上面的步驟 4。
也就是:主線程在寫 AOF page cache 時,會先判斷上一次 fsync 成功的時間,如果距離上次 fysnc 成功在 2 秒內,那么主線程會直接返回,不再寫 AOF page cache。
這就意味著,后臺線程在執行 fsync 刷盤時,主線程最多等待 2 秒不會寫 AOF page cache。
如果此時 Redis 發生了宕機,那么,AOF 文件中丟失是 2 秒的數據,而不是 1 秒!
我們繼續分析,Redis 主線程為什么要等待 2 秒不寫 AOF page cache 呢?
其實,Redis AOF 配置為 appendfsync everysec 時,正常來講,后臺線程每隔 1 秒執行一次 fsync 刷盤,如果磁盤資源充足,是不會被阻塞住的。
也就是說,Redis 主線程其實根本不用關心后臺線程是否刷盤成功,只要無腦寫 AOF page cache 即可。
但是,Redis 作者考慮到,如果此時的磁盤 IO 資源比較緊張,那么后臺線程 fsync 就有概率發生阻塞風險。
所以,Redis 作者在主線程寫 AOF page cache 之前,先檢查一下距離上一次 fsync 成功的時間,如果大于 1 秒沒有成功,那么主線程此時就能知道,fsync 可能阻塞了。
所以,主線程會等待 2 秒不寫 AOF page cache,其目的在于:
降低主線程阻塞的風險(如果無腦寫 AOF page cache,主線程則會立即阻塞住)
如果 fsync 阻塞,主線程就會給后臺線程留出 1 秒的時間,等待 fsync 成功
但代價就是,如果此時發生宕機,AOF 丟失的就是 2 秒的數據,而不是 1 秒。
這個方案應該是 Redis 作者對性能和數據安全性的進一步權衡。
無論如何,這里你只需要知道的是,即使 AOF 配置為每秒刷盤,在發生上述極端情況時,AOF 丟失的數據其實是 2 秒。
4) RDB 和 AOF rewrite 時,Redis 發生 OOM?
最后,我們來看一下,當 Redis 在執行 RDB 快照和 AOF rewrite 時,會發生的問題。
Redis 在做 RDB 快照和 AOF rewrite 時,會采用創建子進程的方式,把實例中的數據持久化到磁盤上。
創建子進程,會調用操作系統的 fork 函數。
fork 執行完成后,父進程和子進程會同時共享同一份內存數據。
但此時的主進程依舊是可以接收寫請求的,而進來的寫請求,會采用 Copy On Write(寫時復制)的方式操作內存數據。
也就是說,主進程一旦有數據需要修改,Redis 并不會直接修改現有內存中的數據,而是先將這塊內存數據拷貝出來,再修改這塊新內存的數據,這就是所謂的「寫時復制」。
寫時復制你也可以理解成,誰需要發生寫操作,誰就先拷貝,再修改。
你應該發現了,如果父進程要修改一個 key,就需要拷貝原有的內存數據,到新內存中,這個過程涉及到了「新內存」的申請。
如果你的業務特點是「寫多讀少」,而且 OPS 非常高,那在 RDB 和 AOF rewrite 期間,就會產生大量的內存拷貝工作。
這會有什么問題呢?
因為寫請求很多,這會導致 Redis 父進程會申請非常多的內存。在這期間,修改 key 的范圍越廣,新內存的申請就越多。
如果你的機器內存資源不足,這就會導致 Redis 面臨被 OOM 的風險!
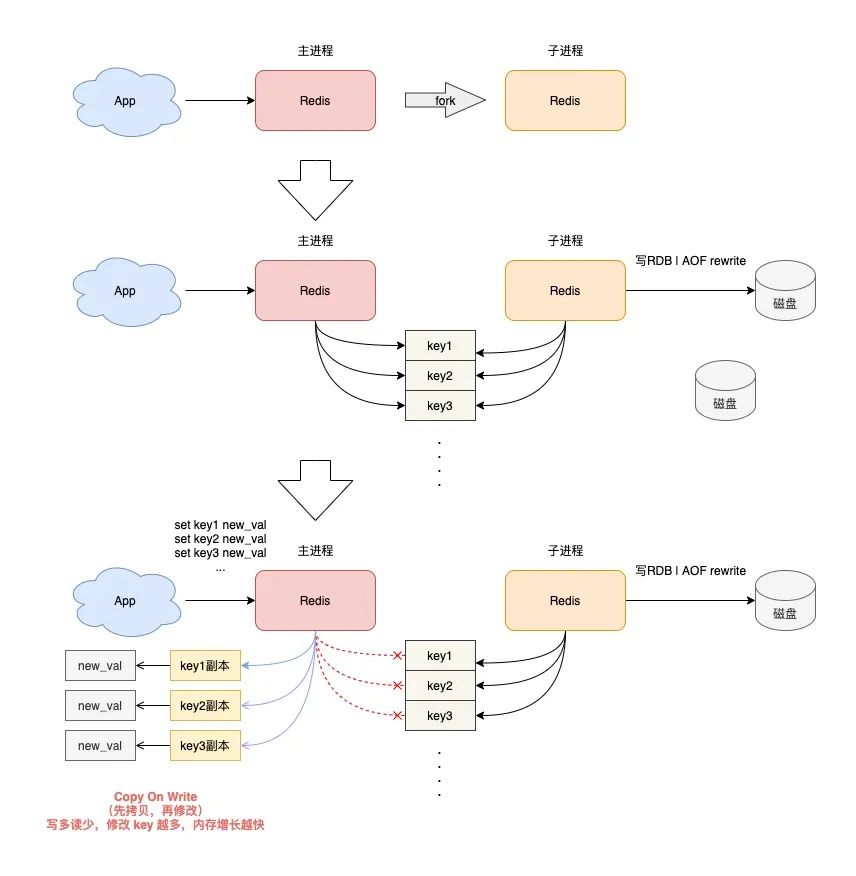
這就是你會從 DBA 同學那里聽到的,要給 Redis 機器預留內存的原因。
其目的就是避免在 RDB 和 AOF rewrite 期間,防止 Redis OOM。
以上這些,就是「數據持久化」會遇到的坑,你踩到過幾個?
下面我們再來看「主從復制」會存在哪些問題。
主從復制有哪些坑?
Redis 為了保證高可用,提供了主從復制的方式,這樣就可以保證 Redis 有多個「副本」,當主庫宕機后,我們依舊有從庫可以使用。
在主從同步期間,依舊存在很多坑,我們依次來看。
1) 主從復制會丟數據嗎?
首先,你需要知道,Redis 的主從復制是采用「異步」的方式進行的。
這就意味著,如果 master 突然宕機,可能存在有部分數據還未同步到 slave 的情況發生。
這會導致什么問題呢?
如果你把 Redis 當做純緩存來使用,那對業務來說沒有什么影響。
master 未同步到 slave 的數據,業務應用可以從后端數據庫中重新查詢到。
但是,對于把 Redis 當做數據庫,或是當做分布式鎖來使用的業務,有可能因為異步復制的問題,導致數據丟失 / 鎖丟失。
關于 Redis 分布式鎖可靠性的更多細節,這里先不展開,后面會單獨寫一篇文章詳細剖析這個知識點。這里你只需要先知道,Redis 主從復制是有概率發生數據丟失的。
2) 同樣命令查詢一個 key,主從庫卻返回不同的結果?
不知道你是否思考過這樣一個問題:如果一個 key 已過期,但這個 key 還未被 master 清理,此時在 slave 上查詢這個 key,會返回什么結果呢?
slave 正常返回 key 的值
slave 返回 NULL
你認為是哪一種?可以思考一下。
答案是:不一定。
嗯?為什么會不一定?
這個問題非常有意思,請跟緊我的思路,我會帶你一步步分析其中的原因。
其實,返回什么結果,這要取決于以下 3 個因素:
Redis 的版本
具體執行的命令
機器時鐘
先來看 Redis 版本。
如果你使用的是 Redis 3.2 以下版本,只要這個 key 還未被 master 清理,那么,在 slave 上查詢這個 key,它會永遠返回 value 給你。
也就是說,即使這個 key 已過期,在 slave 上依舊可以查詢到這個 key。
// Redis 2.8 版本 在 slave 上執行 127.0.0.1:6479》 TTL testkey (integer) -2 // 已過期 127.0.0.1:6479》 GET testkey “testval” // 還能查詢到!
但如果此時在 master 上查詢這個 key,發現已經過期,就會把它清理掉,然后返回 NULL。
// Redis 2.8 版本 在 master 上執行 127.0.0.1:6379》 TTL testkey (integer) -2 127.0.0.1:6379》 GET testkey (nil)
發現了嗎?在 master 和 slave 上查詢同一個 key,結果竟然不一樣?
其實,slave 應該要與 master 保持一致,key 已過期,就應該給客戶端返回 NULL,而不是還正常返回 key 的值。
為什么會發生這種情況?
其實這是 Redis 的一個 Bug:3.2 以下版本的 Redis,在 slave 上查詢一個 key 時,并不會判斷這個 key 是否已過期,而是直接無腦返回給客戶端結果。
這個 Bug 在 3.2 版本進行了修復,但是,它修復得「不夠徹底」。
什么叫修復得「不夠徹底」?
這就要結合前面提到的,第 2 個影響因素「具體執行的命令」來解釋了。
Redis 3.2 雖然修復了這個 Bug,但卻遺漏了一個命令:EXISTS。
也就是說,一個 key 已過期,在 slave 直接查詢它的數據,例如執行 GET/LRANGE/HGETALL/SMEMBERS/ZRANGE 這類命令時,slave 會返回 NULL。
但如果執行的是 EXISTS,slave 依舊會返回:key 還存在。
// Redis 3.2 版本 在 slave 上執行 127.0.0.1:6479》 GET testkey (nil) // key 已邏輯過期 127.0.0.1:6479》 EXISTS testkey (integer) 1 // 還存在!
原因在于,EXISTS 與查詢數據的命令,使用的不是同一個方法。
Redis 作者只在查詢數據時增加了過期時間的校驗,但 EXISTS 命令依舊沒有這么做。
直到 Redis 4.0.11 這個版本,Redis 才真正把這個遺漏的 Bug 完全修復。
如果你使用的是這個之上的版本,那在 slave 上執行數據查詢或 EXISTS,對于已過期的 key,就都會返回「不存在」了。
這里我們先小結一下,slave 查詢過期 key,經歷了 3 個階段:
3.2 以下版本,key 過期未被清理,無論哪個命令,查詢 slave,均正常返回 value
3.2 - 4.0.11 版本,查詢數據返回 NULL,但 EXISTS 依舊返回 true
4.0.11 以上版本,所有命令均已修復,過期 key 在 slave 上查詢,均返回「不存在」
這里要特別鳴謝《Redis開發與運維》的作者,付磊。
這個問題我是在他的文章中看到的,感覺非常有趣,原來 Redis 之前還存在這樣的 Bug 。隨后我又查閱了相關源碼,并對邏輯進行了梳理,在這里才寫成文章分享給大家。
雖然已在微信中親自答謝,但在這里再次表達對他的謝意~
最后,我們來看影響查詢結果的第 3 個因素:「機器時鐘」。
假設我們已規避了上面提到的版本 Bug,例如,我們使用 Redis 5.0 版本,在 slave 查詢一個 key,還會和 master 結果不同嗎?
答案是,還是有可能會的。
這就與 master / slave 的機器時鐘有關了。
無論是 master 還是 slave,在判斷一個 key 是否過期時,都是基于「本機時鐘」來判斷的。
如果 slave 的機器時鐘比 master 走得「快」,那就會導致,即使這個 key 還未過期,但以 slave 上視角來看,這個 key 其實已經過期了,那客戶端在 slave 上查詢時,就會返回 NULL。
是不是很有意思?一個小小的過期 key,竟然藏匿這么多貓膩。
如果你也遇到了類似的情況,就可以通過上述步驟進行排查,確認是否踩到了這個坑。
3) 主從切換會導致緩存雪崩?
這個問題是上一個問題的延伸。
我們假設,slave 的機器時鐘比 master 走得「快」,而且是「快很多」。
此時,從 slave 角度來看,Redis 中的數據存在「大量過期」。
如果此時操作「主從切換」,把 slave 提升為新的 master。
它成為 master 后,就會開始大量清理過期 key,此時就會導致以下結果:
master 大量清理過期 key,主線程發生阻塞,無法及時處理客戶端請求
Redis 中數據大量過期,引發緩存雪崩
你看,當 master / slave 機器時鐘嚴重不一致時,對業務的影響非常大!
所以,如果你是 DBA 運維,一定要保證主從庫的機器時鐘一致性,避免發生這些問題。
4) master / slave 大量數據不一致?
還有一種場景,會導致 master / slave 的數據存在大量不一致。
這就涉及到 Redis 的 maxmemory 配置了。
Redis 的 maxmemory 可以控制整個實例的內存使用上限,超過這個上限,并且配置了淘汰策略,那么實例就開始淘汰數據。
但這里有個問題:假設 master / slave 配置的 maxmemory 不一樣,那此時就會發生數據不一致。
例如,master 配置的 maxmemory 為 5G,而 slave 的 maxmemory 為 3G,當 Redis 中的數據超過 3G 時,slave 就會「提前」開始淘汰數據,此時主從庫數據發生不一致。
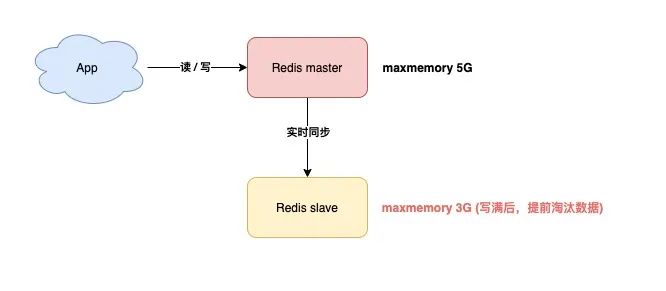
另外,盡管 master / slave 設置的 maxmemory 相同,如果你要調整它們的上限,也要格外注意,否則也會導致 slave 淘汰數據:
調大 maxmemory 時,先調整 slave,再調整 master
調小 maxmemory 時,先調整 master,再調整 slave
以此方式操作,就避免了 slave 提前超過 maxmemory 的問題。
其實,你可以思考一下,發生這些問題的關鍵在哪?
其根本原因在于,slave 超過 maxmemory 后,會「自行」淘汰數據。
如果不讓 slave 自己淘汰數據,那這些問題是不是都可以規避了?
沒錯。
針對這個問題,Redis 官方應該也收到了很多用戶的反饋。在 Redis 5.0 版本,官方終于把這個問題徹底解決了!
Redis 5.0 增加了一個配置項:replica-ignore-maxmemory,默認 yes。
這個參數表示,盡管 slave 內存超過了 maxmemory,也不會自行淘汰數據了!
這樣一來,slave 永遠會向 master 看齊,只會老老實實地復制 master 發送過來的數據,不會自己再搞「小動作」。
至此,master / slave 的數據就可以保證完全一致了!
如果你使用的恰好是 5.0 版本,就不用擔心這個問題了。
5) slave 竟然會有內存泄露問題?
是的,你沒看錯。
這是怎么發生的?我們具體來看一下。
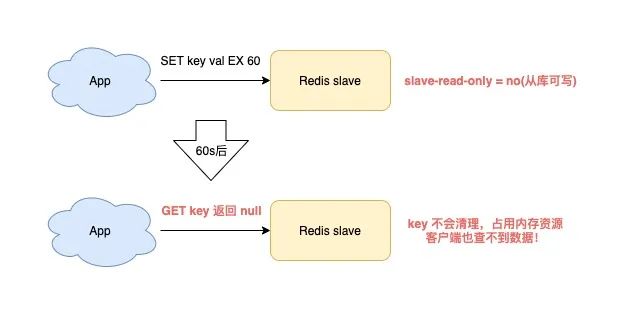
當你在使用 Redis 時,符合以下場景,就會觸發 slave 內存泄露:
Redis 使用的是 4.0 以下版本
slave 配置項為 read-only=no(從庫可寫)
向 slave 寫入了有過期時間的 key
這時的 slave 就會發生內存泄露:slave 中的 key,即使到了過期時間,也不會自動清理。
如果你不主動刪除它,那這些 key 就會一直殘留在 slave 內存中,消耗 slave 的內存。
最麻煩的是,你使用命令查詢這些 key,卻還查不到任何結果!
這就 slave 「內存泄露」問題。
這其實也是 Redis 的一個 Bug,Redis 4.0 才修復了這個問題。
解決方案是,在可寫的 slave 上,寫入帶有過期時間 key 時,slave 會「記錄」下來這些 key。
然后 slave 會定時掃描這些 key,如果到達過期時間,則清理之。
如果你的業務需要在 slave 上臨時存儲數據,而且這些 key 也都設置了過期時間,那么就要注意這個問題了。
你需要確認你的 Redis 版本,如果是 4.0 以下版本,一定要避免踩這個坑。
其實,最好的方案是,制定一個 Redis 使用規范,slave 必須強制設置為 read-only,不允許寫,這樣不僅可以保證 master / slave 的數據一致性,還避免了 slave 內存泄露問題。
6) 為什么主從全量同步一直失敗?
在主從全量同步時,你可能會遇到同步失敗的問題,具體場景如下:
slave 向 master 發起全量同步請求,master 生成 RDB 后發給 slave,slave 加載 RDB。
由于 RDB 數據太大,slave 加載耗時也會變得很長。
此時你會發現,slave 加載 RDB 還未完成,master 和 slave 的連接卻斷開了,數據同步也失敗了。
之后你又會發現,slave 又發起了全量同步,master 又生成 RDB 發送給 slave。
同樣地,slave 在加載 RDB 時,master / slave 同步又失敗了,以此往復。
這是怎么回事?
其實,這就是 Redis 的「復制風暴」問題。
什么是復制風暴?
就像剛才描述的:主從全量同步失敗,又重新開始同步,之后又同步失敗,以此往復,惡性循環,持續浪費機器資源。
為什么會導致這種問題呢?
如果你的 Redis 有以下特點,就有可能發生這種問題:
master 的實例數據過大,slave 在加載 RDB 時耗時太長
復制緩沖區(slave client-output-buffer-limit)配置過小
master 寫請求量很大
主從在全量同步數據時,master 接收到的寫請求,會先寫到主從「復制緩沖區」中,這個緩沖區的「上限」是配置決定的。
當 slave 加載 RDB 太慢時,就會導致 slave 無法及時讀取「復制緩沖區」的數據,這就引發了復制緩沖區「溢出」。
為了避免內存持續增長,此時的 master 會「強制」斷開 slave 的連接,這時全量同步就會失敗。
之后,同步失敗的 slave 又會「重新」發起全量同步,進而又陷入上面描述的問題中,以此往復,惡性循環,這就是所謂的「復制風暴」。
如何解決這個問題呢?我給你以下幾點建議:
Redis 實例不要太大,避免過大的 RDB
復制緩沖區配置的盡量大一些,給 slave 加載 RDB 留足時間,降低全量同步失敗的概率
如果你也踩到了這個坑,可以通過這個方案來解決。
總結
好了,總結一下,這篇文章我們主要講了 Redis 在「命令使用」、「數據持久化」、「主從同步」3 個方面可能存在的「坑」。
怎么樣?有沒有顛覆你的認知呢?
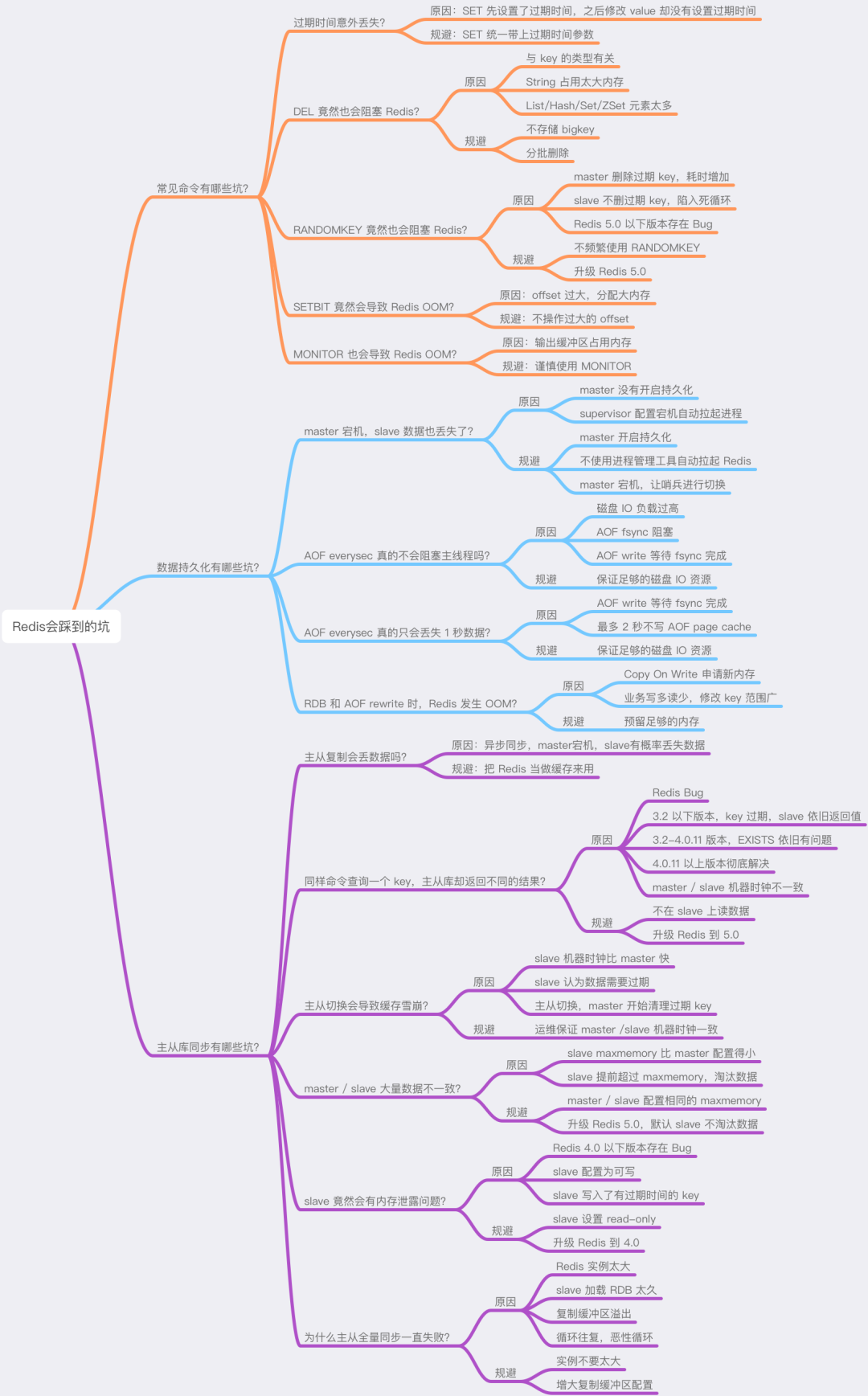
這篇文章信息量還是比較大的,如果你現在的思維已經有些「凌亂」了,別急,我也給你準備好了思維導圖,方便你更好地理解和記憶。
希望你在使用 Redis 時,可以提前規避這些坑,讓 Redis 更好地提供服務。
后記
最后,我想和你聊一聊在開發過程中,關于踩坑的經驗和心得。
其實,接觸任何一個新領域,都會經歷陌生、熟悉、踩坑、吸收經驗、游刃有余這幾個階段。
那在踩坑這個階段,如何少踩坑?或者踩坑后如何高效率地排查問題呢?
這里我總結出了 4 個方面,應該可以幫助到你:
1) 多看官方文檔 + 配置文件的注釋
一定要多看官方文檔,以及配置文件的注釋說明。其實很多可能存在風險的地方,優秀的軟件都會在文檔和注釋里提示你的,認真讀一讀,可以提前規避很多基礎問題。
2) 不放過疑問細節,多思考為什么?
永遠要保持好奇心。遇到問題,掌握剝絲抽繭,逐步定位問題的能力,時刻保持探尋事物問題本質的心態。
3) 敢于提出質疑,源碼不會騙人
如果你覺得一個問題很蹊蹺,可能是一個 Bug,要敢于提出質疑。
通過源碼尋找問題的真相,這種方式要好過你看一百篇網上互相抄襲的文章(抄來抄去很有可能都是錯的)。
4) 沒有完美的軟件,優秀軟件都是一步步迭代出來的
任何優秀的軟件,都是一步步迭代出來的。在迭代過程中,存在 Bug 很正常,我們需要抱著正確的心態去看待它。
這些經驗和心得,適用于學習任何領域,希望對你有所幫助。
原文標題:Redis 會遇到的15個「坑」,你踩過幾個?
文章出處:【微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
命令
+關注
關注
5文章
678瀏覽量
21984 -
Redis
+關注
關注
0文章
371瀏覽量
10846
原文標題:Redis 會遇到的15個「坑」,你踩過幾個?
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Redis 開源協議調整,我們怎么辦?
Redis開源版與Redis企業版,怎么選用?

數據安全沒保障?GaussDB(for Redis) 為你保駕護航
新版 Redis 不再“開源”,對使用者都有哪些影響?
如何解決連接國外大帶寬服務器時可能遇到的問題
redis數據會自動清除嗎
redis容器內怎么查看redis日志
redis的lru原理
redis的原理和使用場景
redis的淘汰策略
redis鎖超時了怎么處理
redis分布式鎖可能出現的問題及解決方案
Java redis鎖怎么實現
Windows Docker部署Redis的流程






 工商網監
工商網監
評論