 抽取式摘要方法中如何合理設置抽取單元?
抽取式摘要方法中如何合理設置抽取單元?
本期導讀:文本摘要技術(Text Summarization)是信息爆炸時代,提升人們獲取有效信息效率的關鍵技術之一,如何從冗余、非結構化的長文本中提煉出關鍵信息,構成精簡通順的摘要,是文本摘要的核心問題。抽取式摘要則是文本摘要技術中效果穩定,實現簡單的一類方法,本文結合COLING 2020中抽取式摘要相關的兩篇最新工作,對抽取式摘要方法中如何合理設置抽取單元展開介紹。
引言
在自動文本摘要任務中,抽取式摘要方法是從原文中抽取預先設置好的抽取單元,抽取單元一般為句子、短語或詞,目前大多數方法還是以句子為抽取單元,雖然句子級的抽取式摘要方法能夠實現一個較好的摘要效果,但依然存在以下問題:
冗余性,抽取出的句子存在冗余。
不必要性,抽取出的句子包含了一些不關鍵的信息。
存在抽取出的句子之間銜接生硬,不夠自然。
現有工作通常使用tri-block后處理策略,即跳過和已選擇句子存在tri-gram重疊的句子來減少冗余。還有一些工作在抽取的摘要基礎上結合生成式摘要方法進行改寫和優化,減少不相關的信息,同時提升銜接流暢度。本期介紹的兩篇工作從設計一個比句子更細粒度的抽取單元出發,希望通過細粒度的抽取單元,分割出整句中的關鍵信息和不關鍵信息,避開冗余的和不必要的內容來解決前兩點問題。
At Which Level Should We Extract An Empirical Analysis on Extractive Document Summarization
騰訊的Qingyu Zhou等人發表于COLING 2020會議上的一篇文章,論文主要針對抽取整句摘要方法存在的冗余性和不必要性問題,提出一種以子句作為抽取單元的抽取式摘要方法。本文的主要貢獻包括兩點:(1)提出了一種子句作為抽取單元的設置方式,介于短語和整句之間。(2)設計了基于BERT的子句摘要抽取模型,性能相比抽取整句有所提升。
子句的定義
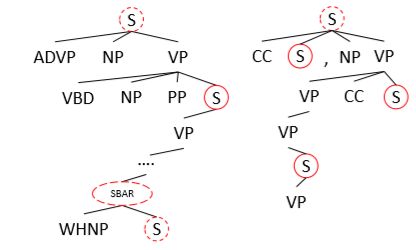
圖 1 PTB句法成分解析樹
本文通過Penn Treebank(PTB)[1]方法對句子進行句法成分分析,對每一個從句節點S和SBAR都視為子句單元。為了保留更完整的語義信息,如果一個從句節點被包括在更高層的從句節點中,則選擇最高層的子句節點(除去根節點)作為抽取的子句單元。例如圖1中,紅色實線圈中的從句節點是最終選定的子句單元,如果一個句子解析后不存在從句節點,則直接選用整句作為抽取單元。
模型概述
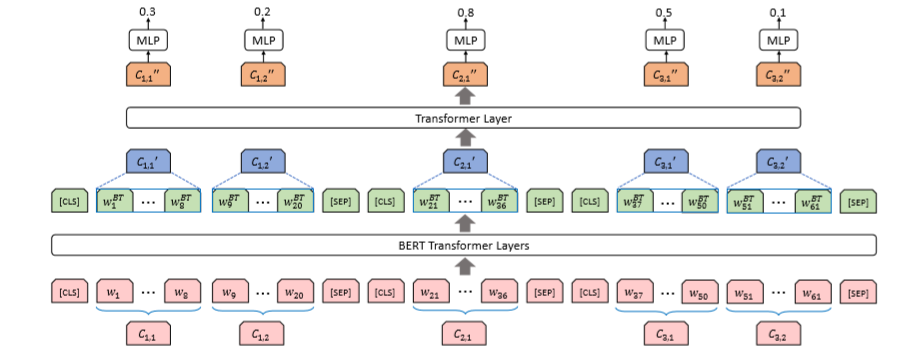
圖2 基于BERT的子句抽取模型SSE(Sub-Sentential Extraction )
抽取模型參考了BERTSUM[2],這里對子句范圍內的token做平均池化得到子句單元的表示,收集到所有子句單元的表示后再經過一層Transformer層混合上下句之間的信息,經過一層全連接層進行二分類預測當前子句單元是需要抽取。訓練時學習每個子句是否需要抽取,預測時選擇分數最高的top-N個子句拼接后輸出。
實驗評價
實驗數據集使用經典的文本摘要數據集CNN/DailyMail。
表1 CNN/DM數據集中對參考摘要,句子級抽取的標準摘要,子句級抽取的標準摘要的統計
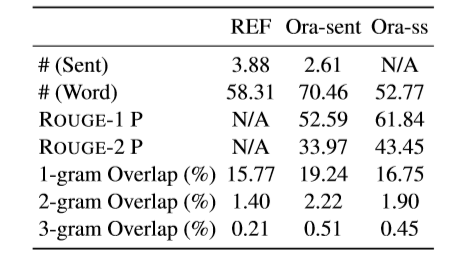
表1中Ora表示抽取式摘要方法中對目標抽取單元的Oracle構造方法,一般以貪心思想依次選擇ROUGE增量分數最高的抽取單元加入,選擇N個或沒有可使ROUGE分數增加的選擇時停止。可以看到,以子句作為抽取單元,Ora-ss抽取方法的ROUGE P分數更高,說明以子句為抽取單元能夠避免抽取到不必要信息。從n-gram Overlap指標可以看出,Ora-ss抽取的內容重復度更低,冗余性相對抽取整句Ora-sent方法更低。
表2 CNN/DM測試集上的ROUGE F1評測結果
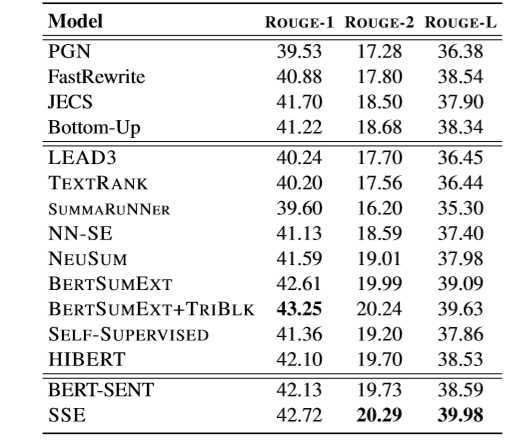
實驗結果如表2所示,SSE模型不依賴后處理策略,在ROUGE-2和ROUGE-L上都超越了基線方法,且對比BERT-SENT(作者復現的BERTSUMEXT)提升顯著。
表3 人工評估結果
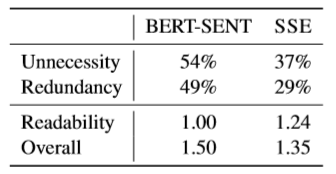
人工評估結果如表3,隨機采樣了50條樣本,經過人工打分對比兩個模型之間的優劣,各指標均是越低表示模型表現越優秀。可以看到SSE模型犧牲了一定的可讀性,帶來了整體上性能的提升,減少了冗余性和不必要性。
結論
以句法成分解析樹中從句節點作為抽取式摘要的抽取單元,能夠有效降低抽取摘要的冗余性和不必要性,犧牲一定的可讀性,提升整體摘要性能,可讀性受句法解析器準確率,以及子句片段自身相對于整個句子的不完備性影響,但整體上SSE達到相比抽取句子更優的性能。
Fact-level Extractive Summarization with Hierarchical Graph Mask on BERT
浙江大學Hanlu Wu等人在COLING 2020會議上發表的一篇文章,本文主要貢獻包括兩點:(1)基于依存分析方法設計了一種子句單元,命名為事實(Fact)。(2)設計了層次化的事實抽取摘要模型,通過改變注意力Mask對BERT直接引入了結構化信息。
事實的定義

圖3 依存分析樹中對整句拆分出事實片段的例子
本文提出了一種經驗性的事實拆分算法,流程如下:
用依存分析方法(Stanford CoreNLP)對候選句子進行解析,每個句子用標點符號、連接詞和從句的節點進行拆分,包括PU(標點), CC(連詞), IP(從句)。
為了獲得完整的語義單元,我們對一些特殊的關系連邊兩端的子句進行合并,包括acl:relcl,advcl(狀語從句修飾詞),appos(同位詞),ccomp(從句補充)。
判斷conj(連接關系)連接的2個元素是從句還是詞語,如果2個元素距離低于一個閾值,則視為連接2個詞語進行合并,否則視為2個子句。
預先定義了一個最小事實長度和最大事實長度,在執行上述合并過程中,如果某個子句長度超過最大長度,則視為獨立的子句,不參與合并。一切合并操作執行完成后,若存在小于最小長度的子句,和前置的子句進行合并,最后所有的子句作為事實。
表4 CNN/DM數據訓練集原文切分結果的統計

表4統計了CNN/DM數據中訓練集的文章按句子切分和按事實切分后的數量和長度,平均1個句子包含1.6個事實,存在一部分句子獨立作為單個事實,其他情況下通常一個句子被拆分為2到3個事實。
模型概述
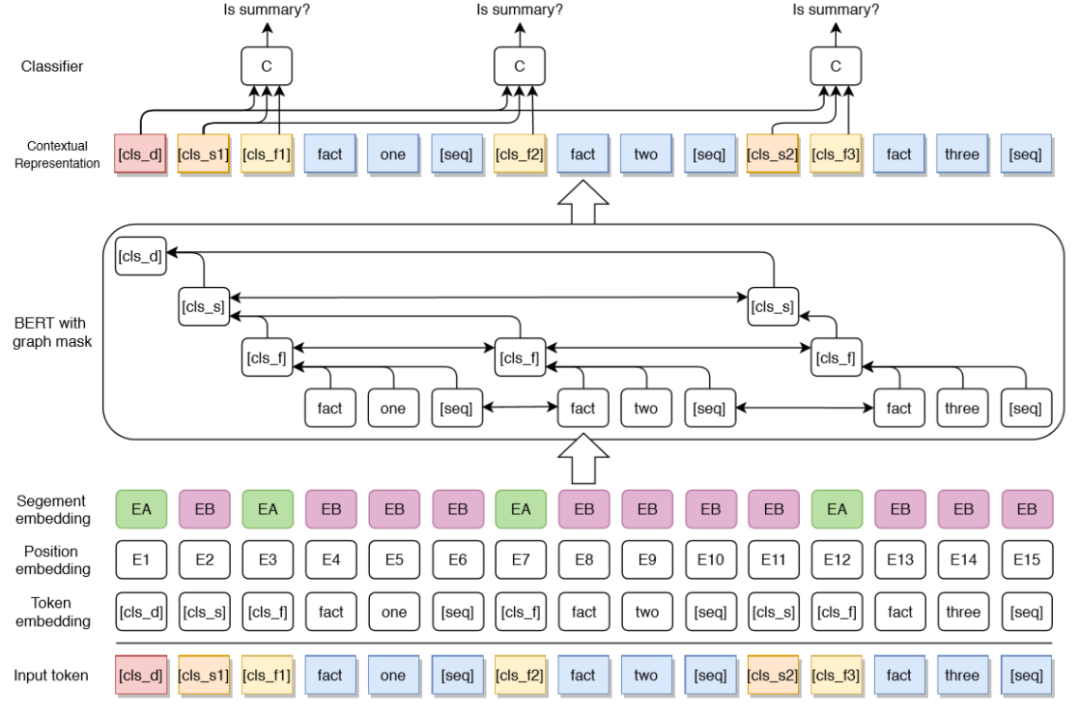
圖4 層次化的事實級摘要抽取模型框架
模型如圖4所示,在BERT的注意力層加入了一個Mask矩陣來加入層次化的結構信息,主要構造了2種連邊:
同粒度下當前token和其他token之間的雙向連邊,圖4中同色token之間都存在雙向連邊。
細粒度token指向粗粒度token的單向連邊,例如圖4中藍色token指向自己所在事實token [cls_f]的連邊,以及事實指向句子,句子指向文檔的連邊。
在輸出層用全連接來對每個事實做分類,結合了文檔的表示和所在句子的表示:
||表示連接,在輸出時使用文檔和對應句子的表示一同判斷當前事實是否抽取。
訓練時只學習事實的loss,預測時預測top-4的事實,加上tri-block去冗余策略。
實驗評價
本文實驗數據采用CNN/DM數據集。
表5 CNN/DM測試集上不同粒度的Oracle摘要對比
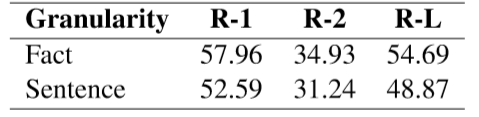
首先展示了基于事實用Oracle方法抽取摘要的效果,如表5所示,基于事實的Oracle方法提高了抽取方法的理論上界,能夠生產更精確的抽取標簽。
表6 CNN/DM測試集評測結果
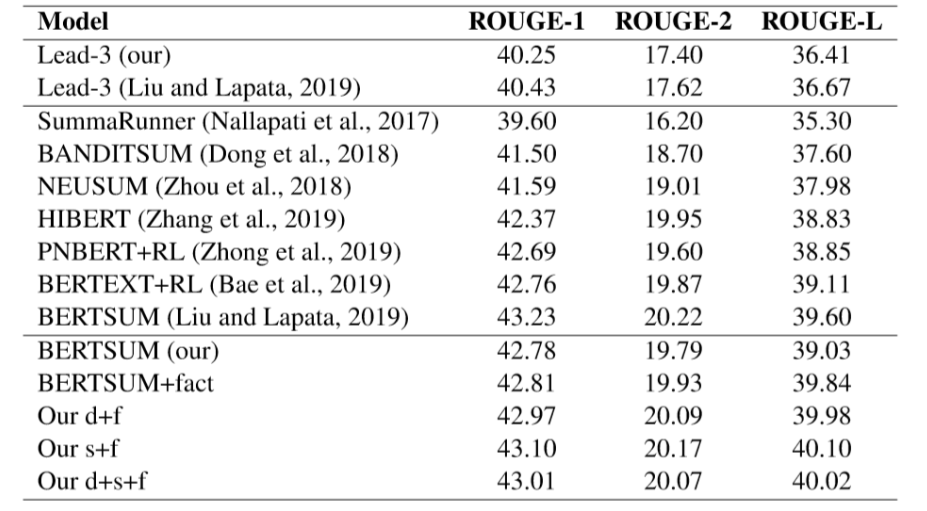
表6顯示加入事實后,相對于作者復現的BERTSUM都有一定的提升,其中結合句子級的表示效果最佳,而額外使用文檔級的信息沒有帶來提升,說明句子級的信息能夠有助于判斷句子內的事實是否應該抽取,而全文的文檔級信息過于粗粒度,對判斷事實是否抽取沒有幫助。
表7 在CNN/DM測試集上的消融實驗結果
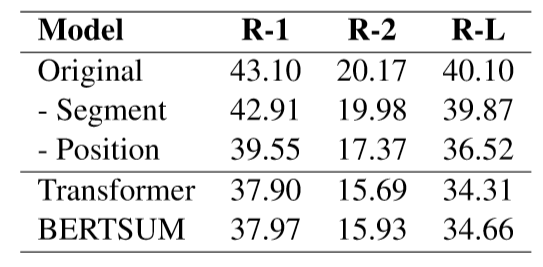
消融實驗中對比了減去片段編碼和位置編碼的模型結果,表7下半部分是兩種基線方法去除位置編碼的結果,可以看出本文的方法去除位置信息后效果下降相對較小,說明層次化的結構信息有助于更好地幫助模型理解語義信息而不會過度依賴位置信息。
總結
兩篇工作都是以設計粒度介于詞和句子之間的抽取單元為主要思想,對比來看,第一篇的子句抽取單元粒度更細,有著更高的理論上界,但存在一些可讀性上的問題。第二篇定義的事實作為抽取單元,在劃分事實的算法中加入經驗性的處理,保證了事實拆分的準確度和語義完整度。從模型優化上來看,第二篇提供了一種從修改掩碼角度來對預訓練模型引入結構化信息的思路,但實驗中個人認為缺少了對應的消融驗證實驗,應當對比結構化掩碼和全連接掩碼的實驗結果。
抽取式摘要是文本摘要中的一類重要方法,除了本期兩篇工作關注的冗余性問題和不必要性問題,還存在例如抽取句子之間語義不連貫,銜接生硬等問題,以及如何對抽取式摘要進行準確評價也是值得探究的一個問題。在實際應用中設計方法時我們更應該關注問題本身,使得方法具有更好地滿足真實需要。
原文標題:【摘要抽取】抽取式摘要最新研究進展
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
信息抽取
+關注
關注
0文章
6瀏覽量
6448
原文標題:【摘要抽取】抽取式摘要最新研究進展
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ADS1299用ADS采集數據,ADS可以不抽取看原始得數據嗎?
求助,關于AMC1306M25抽取率OSR的疑問求解
有獎問卷:隨機抽取 30 名用戶送出快充數據線
求助,AD7190關于Σ-Δ ADC其中的抽取濾波器的數據轉換問題求解
防水和防振動功能2.5 英寸SAS/SATA硬盤抽取盒 非常適合車載數據存儲

步進電機撥碼開關怎樣設置最合理?

步進電機撥碼開關怎樣設置最合理
ICY DOCK Expresscage MB038SP-B硬盤抽取盒評測

用STM8做一個用于抽取頻譜的東西, 如何采樣128個點用于FFT數據計算?
按鍵式和藍牙時控開關的設置方法
在線節目制播嵌入式設備的ICY DOCK硬盤抽取盒應用






 工商網監
工商網監
評論