 計算機視覺可以學習美式手語,進而幫助聽力障礙群體嗎?
計算機視覺可以學習美式手語,進而幫助聽力障礙群體嗎?
前言
計算機視覺可以學習美式手語,進而幫助聽力障礙群體嗎?數據科學家David Lee用一個項目給出了答案。
如果聽不到了,你會怎么辦?如果只能用手語交流呢?
當對方無法理解你時,即使像訂餐、討論財務事項,甚至和朋友家人對話這樣簡單的事情也可能令你氣餒。對普通人而言輕輕松松的事情對于聽障群體可能是很困難的,他們甚至還會因此遭到歧視。
在很多場景下,他們無法獲取合格的翻譯服務,從而導致失業、社會隔絕和公共衛生問題。為了讓更多人聽到聽障群體的聲音,數據科學家 David Lee 嘗試利用數據科學項目來解決這一問題:計算機視覺可以學習美式手語,進而幫助聽力障礙群體嗎?
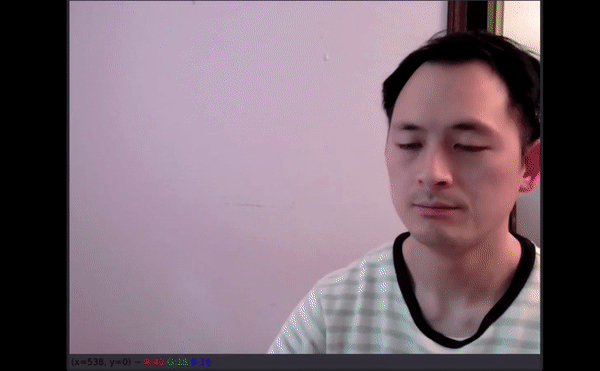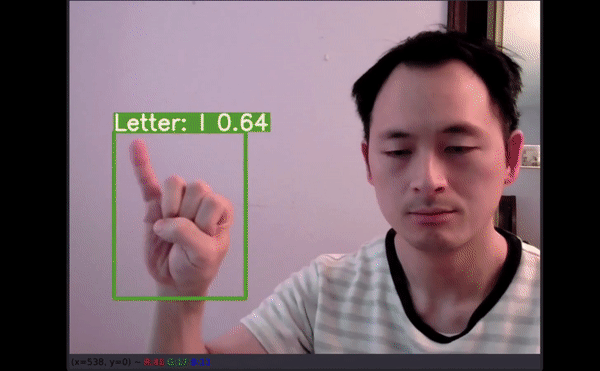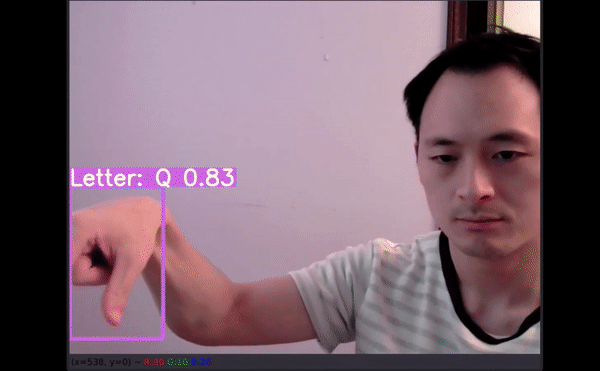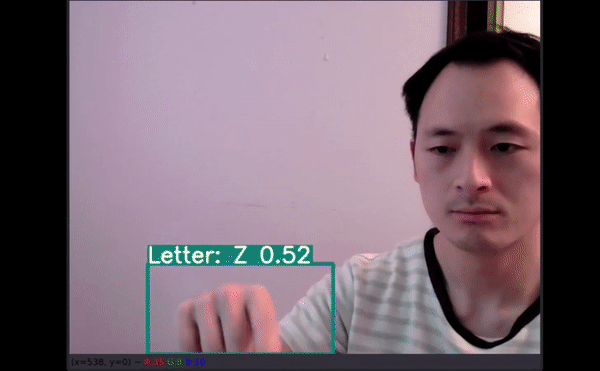
如果通過機器學習應用可以精確地翻譯美式手語,即使從最基礎的字母表開始,我們也能向著為聽力障礙群體提供更多的便利和教育資源前進一步。
數據和項目介紹
出于多種原因,David Lee決定創建一個原始圖像數據集。首先,基于移動設備或攝像頭設置想要的環境,需要的分辨率一般是720p或1080p。現有的幾個數據集分辨率較低,而且很多不包括字母「J」和「Z」,因為這兩個字母需要一些動作才能完成。

為此,David Lee 在社交平臺上發送了手語圖像數據收集請求,介紹了這個項目和如何提交手語圖像的說明,希望借此提高大家的認識并收集數據。
數據變形和過采樣
David Lee 為該項目收集了 720 張圖片,其中還有幾張是他自己的手部圖像。由于這個數據集規模較小,于是 David 使用 labelImg 軟件手動進行邊界框標記,設置變換函數的概率以基于同一張圖像創建多個實例,每個實例上的邊界框有所不同。下圖展示了數據增強示例:

經過數據增強后,該數據集的規模從 720 張圖像擴展到 18,000 張圖像。
建模
David 選擇使用 YOLOv5 進行建模。將數據集中 90% 的圖像用作訓練數據,10% 的圖像用作驗證集。使用遷移學習和 YOLOv5m 預訓練權重訓練 300 個 epoch。

在驗證集上成功創建具備標簽和預測置信度的新邊界框。
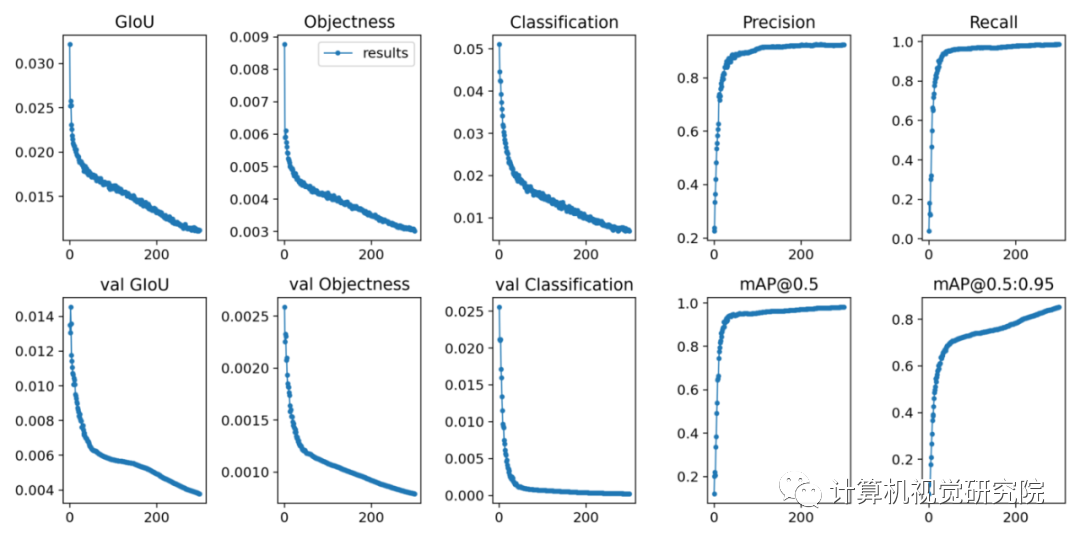
由于損失值并未出現增長,表明模型未過擬合,因此該模型或許可以訓練更多輪次。模型最終獲得了 85.27% 的 mAP@.5:.95 分數。
圖像推斷測試
David 額外收集了他兒子的手部圖像數據作為測試集。事實上,還沒有兒童手部圖像用于訓練該模型。理想情況下,再多幾張圖像有助于展示模型的性能,但這只是個開始。

26 個字母中,有 4 個沒有預測結果(分別是 G、H、J 和 Z)。四個沒有得到準確預測:
D 被預測為 F;
E 被預測為 T;
P 被預測為 Q;
R 被預測為 U。
視頻推斷測試
即使只有幾個手部圖像用于訓練,模型仍能在如此小的數據集上展現不錯的性能,而且還能以一定的速度提供優秀的預測結果,這一結果表現出了很大的潛力。更多數據有助于創建可在多種新環境中使用的模型。如以上視頻所示,即使字母有一部分出框了,模型仍能給出不錯的預測結果。最令人驚訝的是,字母 J 和 Z 也得到了準確識別。
其他測試
執行其他一些測試,例如:左手手語測試
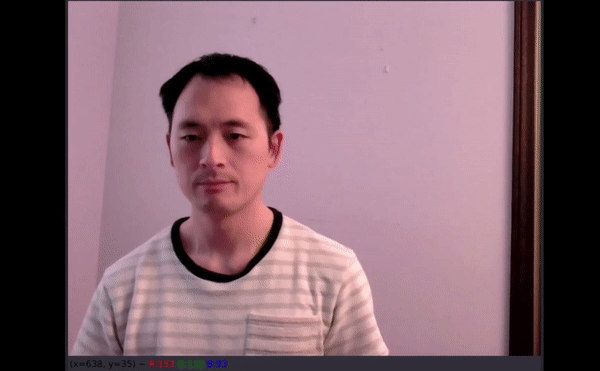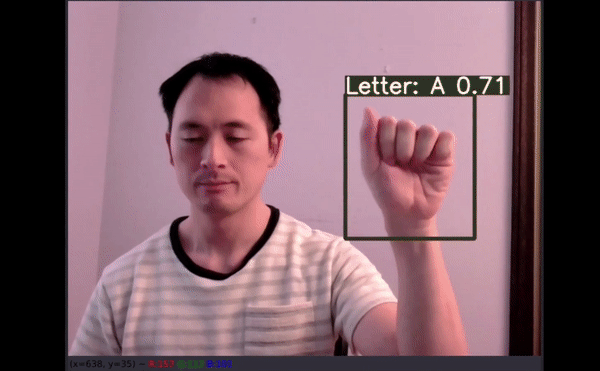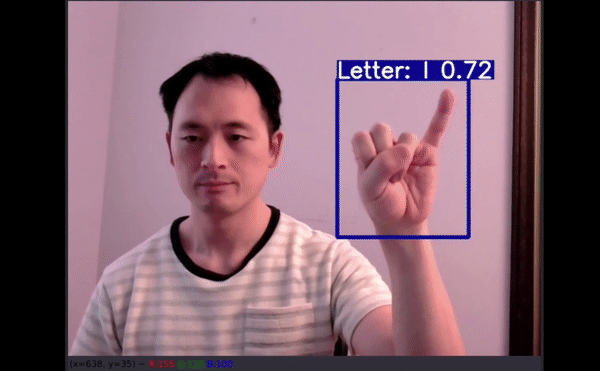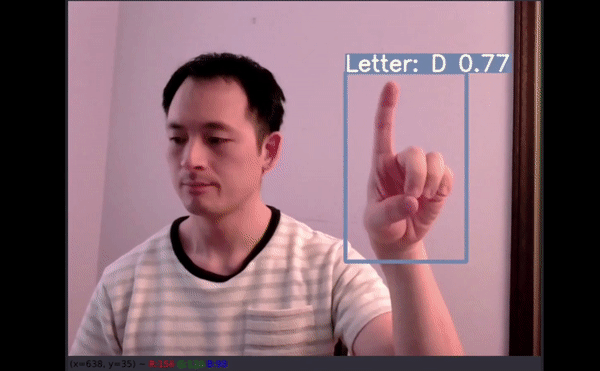
幾乎所有原始圖像都顯示的是右手,但驚喜地發現數據增強在這里起到了作用,因為有 50% 的可能性是針對左手用戶進行水平翻轉。
兒童手語測試

兒童的手語數據未被用于訓練集,但模型對此仍有不錯的預測。
多實例

盡管手語的使用和視頻中有所不同,但這個示例表明當多個人出現在屏幕上時,模型可以分辨出不止一個手語實例。
模型局限性
發現該模型還有一些地方有待改進。
距離

許多原始圖像是用手機拍攝的,手到攝像頭的距離比較近,這對遠距離推斷有一定負面影響。
新環境

這支視頻來自于志愿者,未用于模型訓練。盡管模型看到過很多字母,但對此的預測置信度較低,還有一些錯誤分類。
背景推斷

該測試旨在驗證不同的背景會影響模型的性能。
結論
這個項目表明:計算機視覺可用于幫助聽力障礙群體獲取更多便利和教育資源!該模型在僅使用小型數據集的情況下仍能取得不錯的性能。即使對于不同環境中的不同手部,模型也能實現良好的檢測結果。
而且一些局限性是可以通過更多訓練數據得到解決的。經過調整和數據集的擴大,該模型或許可以擴展到美式手語字母表以外的場景。

責任編輯:lq
-
手勢識別
+關注
關注
8文章
225瀏覽量
47772 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45928 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:YOLOv5的項目實踐 | 手勢識別項目落地全過程(附源碼)
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺有哪些優缺點
計算機視覺的五大技術
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
計算機視覺在人工智能領域有哪些主要應用?
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
開源項目!設計一款智能手語翻譯眼鏡
計算機視覺的十大算法






 工商網監
工商網監
評論