") 關(guān)于InnoDB的內(nèi)存結(jié)構(gòu)及原理詳解
關(guān)于InnoDB的內(nèi)存結(jié)構(gòu)及原理詳解
之前寫過一篇文章「簡(jiǎn)單了解InnoDB原理」,現(xiàn)在回過頭看,其實(shí)里面只是把緩沖池(Buffer Pool),重做日志緩沖(Redo Log Buffer)、插入緩沖(Insert Buffer)和自適應(yīng)哈希索引(Adaptive Hash Index)等概念簡(jiǎn)單的介紹了一下。
除此之外還聊了一下MySQL和InnoDB的日志,和兩次寫,總的來說算是一個(gè)入門級(jí)別的介紹,這篇文章就來詳細(xì)介紹一下InnoDB的內(nèi)存結(jié)構(gòu)。
InnoDB內(nèi)存結(jié)構(gòu)
其大致結(jié)構(gòu)如下圖。
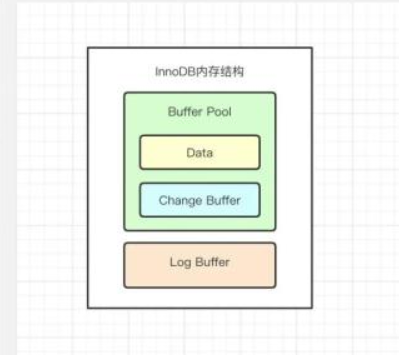
InnoDB內(nèi)存的兩個(gè)主要區(qū)域分別為Buffer Pool和Log Buffer,此處的Log Buffer目前是用于緩存Redo Log。而Buffer Pool則是MySQL或者說InnoDB中,十分重要、核心的一部分,位于主存。這也是為什么其訪問數(shù)據(jù)的效率高,你可以暫時(shí)把它理解成Redis那樣的內(nèi)存數(shù)據(jù)庫,因?yàn)槲覀兏潞托略霎?dāng)然它不是,只是這樣會(huì)更加方便我們理解。
Buffer Pool
通常來說,宿主機(jī)80%的內(nèi)存都應(yīng)該分配給Buffer Pool,因?yàn)锽uffer Pool越大,其能緩存的數(shù)據(jù)就更多,更多的操作都會(huì)發(fā)生在內(nèi)存,從而達(dá)到提升效率的目的。
由于其存儲(chǔ)的數(shù)據(jù)類型和數(shù)據(jù)量非常多,Buffer Pool存儲(chǔ)的時(shí)候一定會(huì)按照某些結(jié)構(gòu)去存儲(chǔ),并且做了某些處理。否則獲取的時(shí)候除了遍歷所有數(shù)據(jù)之外,沒有其他的捷徑,這樣的低效率操作肯定是無法支撐MySQL的高性能的。
因此,Buffer Pool被分成了很多頁,這在之前的文章中也有講過,這里不再贅述。每頁可以存放很多數(shù)據(jù),剛剛也提到了,InnoDB一定是對(duì)數(shù)據(jù)做了某些操作。
InnoDB使用了鏈表來組織頁和頁中存儲(chǔ)的數(shù)據(jù),頁與頁之間形成了雙向鏈表,這樣可以方便的從當(dāng)前頁跳到下一頁,同時(shí)使用LRU(Least Recently Used)算法去淘汰那些不經(jīng)常使用的數(shù)據(jù)。
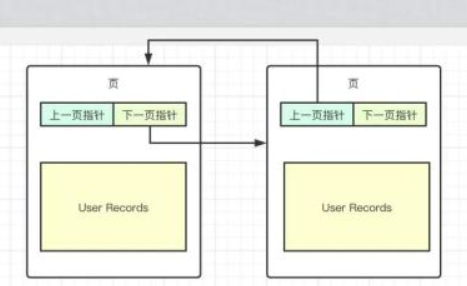
同時(shí),每頁中的數(shù)據(jù)也通過單向鏈表進(jìn)行鏈接。因?yàn)檫@些數(shù)據(jù)是分散到Buffer Pool中的,單向鏈表將這些分散的內(nèi)存給連接了起來。

Log Buffer
Log Buffer用來存儲(chǔ)那些即將被刷入到磁盤文件中的日志,例如Redo Log,該區(qū)域也是InnoDB內(nèi)存的重要組成部分。Log Buffer的默認(rèn)值為16M,如果我們需要進(jìn)行調(diào)整的話,可以通過配置參數(shù)innodb_log_buffer_size來進(jìn)行調(diào)整。
當(dāng)Log Buffer如果較大,就可以存儲(chǔ)更多的Redo Log,這樣一來在事務(wù)提交之前我們就不需要將Redo Log刷入磁盤,只需要丟到Log Buffer中去即可。因此較大的Log Buffer就可以更好的支持較大的事務(wù)運(yùn)行;同理,如果有事務(wù)會(huì)大量的更新、插入或者刪除行,那么適當(dāng)?shù)脑龃驦og Buffer的大小,也可以有效的減少部分磁盤I/O操作。
至于Log Buffer中的數(shù)據(jù)刷入到磁盤的頻率,則可以通過參數(shù)innodb_flush_log_at_trx_commit來決定。
Buffer Pool的LRU算法
了解完了InnoDB的內(nèi)存結(jié)構(gòu)之后,我們來仔細(xì)看看Buffer Pool的LRU算法是如何實(shí)現(xiàn)將最近沒有使用過的數(shù)據(jù)給過期的。
原生LRU
首先明確一點(diǎn),此處的LRU算法和我們傳統(tǒng)的LRU算法有一定的區(qū)別。為什么呢?因?yàn)閷?shí)際生產(chǎn)環(huán)境中會(huì)存在全表掃描的情況,如果數(shù)據(jù)量較大,可能會(huì)將Buffer Pool中存下來的熱點(diǎn)數(shù)據(jù)給全部替換出去,而這樣就會(huì)導(dǎo)致該段時(shí)間MySQL性能斷崖式下跌。
對(duì)于這種情況,MySQL有一個(gè)專用名詞叫緩沖池污染。所以MySQL對(duì)LRU算法做了優(yōu)化。
優(yōu)化后的LRU
優(yōu)化之后的鏈表被分成了兩個(gè)部分,分別是 New Sublist 和 Old Sublist,其分別占用了 Buffer Pool 的3/4和1/4。
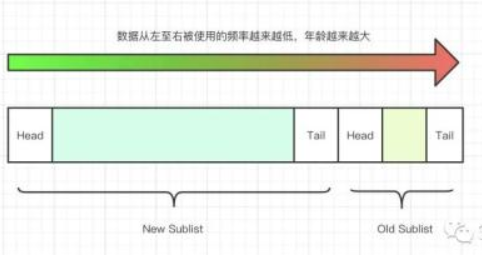
鏈表的前3/4,也就是 New Sublist 存放的是訪問較為頻繁的頁,而后1/4也就是 Old Sublist 則是反問的不那么頻繁的頁。Old Sublist中的數(shù)據(jù),會(huì)在后續(xù)Buffer Pool剩余空間不足、或者有新的頁加入時(shí)被移除掉。
了解了鏈表的整體構(gòu)造和組成之后,我們就以新頁被加入到鏈表為起點(diǎn),把整體流程走一遍。首先,一個(gè)新頁被放入到Buffer Pool之后,會(huì)被插入到鏈表中 New Sublist 和 Old Sublist 相交的位置,該位置叫MidPoint。
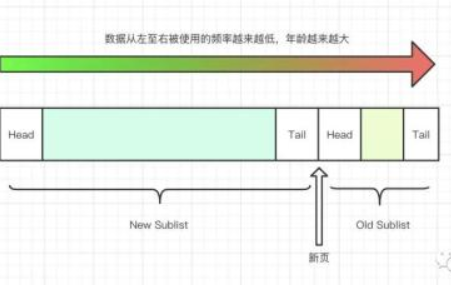
該鏈表存儲(chǔ)的數(shù)據(jù)來源有兩部分,分別是:
MySQL的預(yù)讀線程預(yù)先加載的數(shù)據(jù)
用戶的操作,例如Query查詢
默認(rèn)情況下,由用戶操作影響而進(jìn)入到Buffer Pool中的數(shù)據(jù),會(huì)被立即放到鏈表的最前端,也就是 New Sublist 的 Head 部分。但如果是MySQL啟動(dòng)時(shí)預(yù)加載的數(shù)據(jù),則會(huì)放入MidPoint中,如果這部分?jǐn)?shù)據(jù)被用戶訪問過之后,才會(huì)放到鏈表的最前端。
這樣一來,雖然這些頁數(shù)據(jù)在鏈表中了,但是由于沒有被訪問過,就會(huì)被移動(dòng)到后1/4的 Old Sublist中去,直到被清理掉。
優(yōu)化Buffer Pool的配置
在實(shí)際的生產(chǎn)環(huán)境中,我們可以通過變更某些設(shè)置,來提升Buffer Pool運(yùn)行的性能。
例如,我們可以分配盡量多的內(nèi)存給Buffer Pool,如此就可以緩存更多的數(shù)據(jù)在內(nèi)存中
當(dāng)前有足夠的內(nèi)存時(shí),就可以搞多個(gè)Buffer Pool實(shí)例,減少并發(fā)操作所帶來的數(shù)據(jù)競(jìng)爭(zhēng)
當(dāng)我們可以預(yù)測(cè)到即將到來的大量請(qǐng)求時(shí),我們可以手動(dòng)的執(zhí)行這部分?jǐn)?shù)據(jù)的預(yù)讀請(qǐng)求
我們還可以控制Buffer Pool刷數(shù)據(jù)到磁盤的頻率,以根據(jù)當(dāng)前MySQL的負(fù)載動(dòng)態(tài)調(diào)整
那我們?cè)趺粗喇?dāng)前運(yùn)行的 MySQL 中 Buffer Pool 的狀態(tài)呢?我們可以通過命令show engine innodb status來查看。這個(gè)命令是看 InnoDB 整體的狀態(tài)的, Buffer Pool 相關(guān)的監(jiān)控指標(biāo)包含在了其中,在Buffer Pool And Memory模塊中。
樣例如下。
---------------------- BUFFER POOL AND MEMORY ---------------------- Total large memory allocated 137428992 Dictionary memory allocated 972752 Buffer pool size 8191 Free buffers 4596 Database pages 3585 Old database pages 1303 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 1171, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 655, created 7139, written 173255 0.00 reads/s, 0.00 creates/s, 0.00 writes/s No buffer pool page gets since the last printout Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 3585, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0]
解釋一些關(guān)鍵的指標(biāo)所代表的含義:
Total memory allocated:分配給 Buffer Pool 的總內(nèi)存
Dictionary memory allocated:分配給 InnoDB 數(shù)據(jù)字典的總內(nèi)存
Buffer pool size:分配給 Buffer Pool 中頁的內(nèi)存大小
Free buffers:分配給 Buffer Pool 中 Free List 的內(nèi)存大小
Database pages:分配給 LRU 鏈表的內(nèi)存大小
Old database pages:分配給 LRU 子鏈表的內(nèi)存大小
Modified db pages:當(dāng)前Buffer Pook中被更新的頁的數(shù)量
Pending reads:當(dāng)前等待讀入 Buffer Pool 的頁的數(shù)量
Pending writes LRU:當(dāng)前在 LRU 鏈表中等待被刷入磁盤的臟頁數(shù)量
都是些很常規(guī)的配置項(xiàng),你可能會(huì)比較好奇什么是 Free List。
Free List 中存放的都是未被使用的頁。因?yàn)镸ySQL啟動(dòng)的時(shí)候,InnoDB 會(huì)預(yù)先申請(qǐng)一部分頁。如果當(dāng)前頁還未被使用,就會(huì)被保存在 Free List 中。
知道了 Free List,那么你也應(yīng)該知道 Flush List,里面保存的是所有的臟頁,都是被更改后需要刷入到磁盤的。
自適應(yīng)哈希索引
自適應(yīng)哈希索引(Adaptive Hash Index)是配合Buffer Pool工作的一個(gè)功能。自適應(yīng)哈希索引使得MySQL的性能更加接近于內(nèi)存服務(wù)器。
如果要啟用自適應(yīng)哈希索引,可以通過更改配置innodb_adaptive_hash_index來開啟。如果不想啟用,也可以在啟動(dòng)的時(shí)候,通過命令行參數(shù)--skip-innodb-adaptive-hash-index來關(guān)閉。
自適應(yīng)哈希索引是根據(jù)索引Key的前綴來構(gòu)建的,InnoDB 有自己的監(jiān)控索引的機(jī)制,當(dāng)其檢測(cè)到為當(dāng)前某個(gè)索引頁建立哈希索引能夠提升效率時(shí),就會(huì)創(chuàng)建對(duì)應(yīng)的哈希索引。如果某張表數(shù)據(jù)量很少,其數(shù)據(jù)全部都在Buffer Pool中,那么此時(shí)自適應(yīng)哈希索引就會(huì)變成我們所熟悉的指針這樣一個(gè)角色。
當(dāng)然,創(chuàng)建、維護(hù)自適應(yīng)哈希索引是會(huì)帶來一定的開銷的,但是比起其帶來的性能上的提升,這點(diǎn)開銷可以直接忽略不計(jì)。但是,是否要開啟自適應(yīng)哈希索引還是需要看具體的業(yè)務(wù)情況的,例如當(dāng)我們的業(yè)務(wù)特征是有大量的并發(fā)Join查詢,此時(shí)訪問自適應(yīng)哈希索引被產(chǎn)生競(jìng)爭(zhēng)。并且如果業(yè)務(wù)還使用了LIKE或者%等通配符,根本就不會(huì)用到哈希索引,那么此時(shí)自適應(yīng)哈希索引反而變成了系統(tǒng)的負(fù)擔(dān)。
所以,為了盡可能的減少并發(fā)情況下帶來的競(jìng)爭(zhēng),InnoDB對(duì)自適應(yīng)哈希索引進(jìn)行了分區(qū),每個(gè)索引都被綁定到了一個(gè)特定的分區(qū),而每個(gè)分區(qū)都由單獨(dú)的鎖進(jìn)行保護(hù)。其實(shí)通俗點(diǎn)理解,就是降低了鎖的粒度。分區(qū)的數(shù)量我們可以通過配置innodb_adaptive_hash_index_parts來改變,其可配置的區(qū)間范圍為[8, 512]。
Change Buffer
聊完了 Buffer Pool 中索引相關(guān),剩下的就是 Change Buffer 了。Change Buffer是一塊比較特殊的區(qū)域,其作用是用于存儲(chǔ)那些當(dāng)前不在 Buffer Pool 中的但是又被修改過的二級(jí)索引。
用流程來描述一下就是,當(dāng)我們更新了非聚簇索引(二級(jí)索引)的數(shù)據(jù)時(shí),此時(shí)應(yīng)該是直接將其在Buffer Pool中的對(duì)應(yīng)數(shù)據(jù)更新了即可,但是不湊巧的是,當(dāng)前二級(jí)索引不在 Buffer Pool 中,此時(shí)將其從磁盤拉取到 Buffer Pool 中的話,并不是最優(yōu)的解,因?yàn)樵摱?jí)索引可能之后根本就不會(huì)被用到,那么剛剛昂貴的磁盤I/O操作就白費(fèi)了。
所以,我們需要這么一個(gè)地方,來暫存對(duì)這些二級(jí)索引所做的改動(dòng)。當(dāng)被緩存的二級(jí)索引頁被其他的請(qǐng)求加載到了Buffer Pool 中之后,就會(huì)將 Change Buffer 中緩存的數(shù)據(jù)合并到 Buffer Pool 中去。
當(dāng)然,Change Buffer也不是沒有缺點(diǎn)。當(dāng) Change Buffer 中有很多的數(shù)據(jù)時(shí),全部合并到Buffer Pool可能會(huì)花上幾個(gè)小時(shí)的時(shí)間,并且在合并的期間,磁盤的I/O操作會(huì)比較頻繁,從而導(dǎo)致部分的CPU資源被占用。
那你可能會(huì)問,難道只有被緩存的頁加載到了 Buffer Pool 才會(huì)觸發(fā)合并操作嗎?那要是它一直沒有被加載進(jìn)來,Change Buffer 不就被撐爆了?很顯然,InnoDB在設(shè)計(jì)的時(shí)候考慮到了這個(gè)點(diǎn)。除了對(duì)應(yīng)的頁加載,提交事務(wù)、服務(wù)停機(jī)、服務(wù)重啟都會(huì)觸發(fā)合并。
編輯:lyn
-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3004瀏覽量
73900 -
MySQL
+關(guān)注
關(guān)注
1文章
802瀏覽量
26452 -
索引
+關(guān)注
關(guān)注
0文章
59瀏覽量
10465
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
DDR5內(nèi)存的工作原理詳解 DDR5和DDR4的主要區(qū)別
DDR內(nèi)存的工作原理與結(jié)構(gòu)
Windows管理內(nèi)存的三種主要方式
如何使用反射內(nèi)存交換機(jī)
內(nèi)存緩沖區(qū)和內(nèi)存的關(guān)系
內(nèi)存管理的硬件結(jié)構(gòu)
堆棧和內(nèi)存的基本知識(shí)
華納云:InnoDB 具有哪四大特性
集成芯片原理圖詳解
FreeRTOS內(nèi)存機(jī)制詳解

Windows服務(wù)器虛擬內(nèi)存的設(shè)置建議
詳解內(nèi)存條和內(nèi)存顆粒






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論