") 深蘭在自然語(yǔ)言處理領(lǐng)域歐洲頂會(huì)上取得好成績(jī)
深蘭在自然語(yǔ)言處理領(lǐng)域歐洲頂會(huì)上取得好成績(jī)
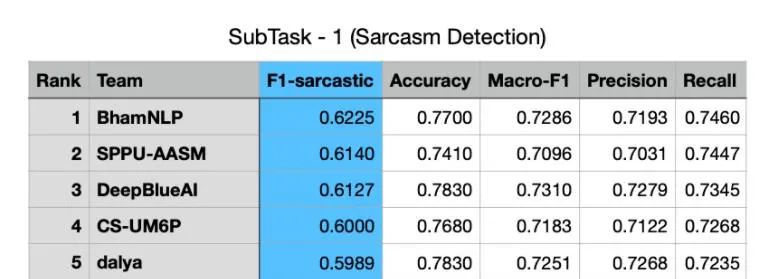
2021年4月19-23日,EACL2021因疫情影響于線上正式召開(kāi),這是計(jì)算語(yǔ)言學(xué)和自然語(yǔ)言處理領(lǐng)域的重要國(guó)際會(huì)議,在Google Scholar計(jì)算語(yǔ)言學(xué)刊物指標(biāo)中排名第七。深蘭科技DeepBlueAI團(tuán)隊(duì)參加了Shared Task on Sarcasm and Sentiment Detection in Arabic 比賽,并在其兩個(gè)子任務(wù)諷刺檢測(cè)和情感識(shí)別中,分別獲得了第二名和第三名的好成績(jī),在深蘭榮譽(yù)榜上再添新篇。
獲獎(jiǎng)技術(shù)方案分享
任務(wù)介紹
諷刺檢測(cè)要求識(shí)別一段文字中是否包含諷刺的內(nèi)容,諷刺是當(dāng)前情感分析系統(tǒng)的主要挑戰(zhàn)之一,因?yàn)榫哂兄S刺性的句子通常用積極的表達(dá)方式去表示消極的情感。文本所表達(dá)的情感以及作者真正想表達(dá)的情感之間存在不同,這種情況給情感分析系統(tǒng)帶來(lái)了巨大的挑戰(zhàn)。
諷刺檢測(cè)、情感識(shí)別在其他語(yǔ)言中引起了很大的關(guān)注,但是在阿拉伯語(yǔ)上則沒(méi)有太多進(jìn)展,該任務(wù)則是針對(duì)阿拉伯語(yǔ),針對(duì)給定的一個(gè)推特文本,判斷是積極、消極或者中立情感,以及是否具有諷刺性。
數(shù)據(jù)分析
任務(wù)數(shù)據(jù)集名字為ArSarcasm-v2[1],數(shù)據(jù)包含以下幾個(gè)字段,tweet, sarcasm, sentiment, dialect,tweet代表推特文本,sarcasm為諷刺檢測(cè)的標(biāo)簽,sentiment為情感分類的標(biāo)簽,dialect表示當(dāng)前文本確切屬于阿拉伯語(yǔ)中的哪個(gè)方言。
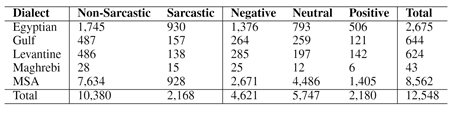
數(shù)據(jù)集統(tǒng)計(jì)如上圖所示,Arsarcasm-V2 共有12548條訓(xùn)練文本,其中MSA占比達(dá)到了68.2%,Maghrebi占比較少,僅有42條。此外我們還分析了具有諷刺文本中的情感分布情況,占比如下圖所示。可以看出諷刺文本中89%具有消極情感,只有3%具有正面情感,可見(jiàn)諷刺一般情況下傳遞消極的信息。
模型
模型采用當(dāng)前比較流行的預(yù)訓(xùn)練模型,因?yàn)檎Z(yǔ)言為阿拉伯語(yǔ),我們采用了專門(mén)針對(duì)阿拉伯語(yǔ)的預(yù)訓(xùn)練模型bert-large-arabertv02[2],以及多語(yǔ)言預(yù)訓(xùn)練模型xlm-roberta-large[3]。其中模型結(jié)構(gòu)如下,選取模型多層[CLS]位置的輸出進(jìn)行加權(quán)平均得到[CLS]位置向量,然后經(jīng)過(guò)全連接層,之后經(jīng)過(guò)Multi-sample dropout[4]得到損失。對(duì)于諷刺檢測(cè)為二分類,我們采用Binary Cross Entropy 損失函數(shù),對(duì)于情感識(shí)別為三分類,我們采用Cross Entropy損失函數(shù)。
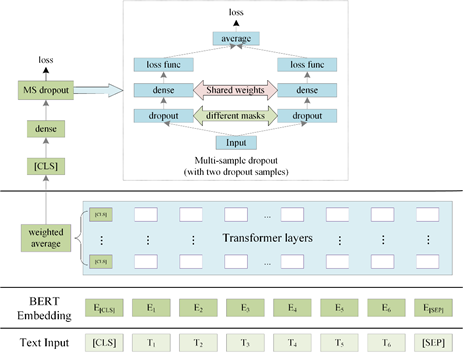
Multi-sample dropout 是dropout的一種變種,傳統(tǒng) dropout 在每輪訓(xùn)練時(shí)會(huì)從輸入中隨機(jī)選擇一組樣本(稱之為 dropout 樣本),而 multi-sample dropout 會(huì)創(chuàng)建多個(gè) dropout 樣本,然后平均所有樣本的損失,從而得到最終的損失,multi-sample dropout 共享中間的全連接層權(quán)重。通過(guò)綜合 M 個(gè) dropout 樣本的損失來(lái)更新網(wǎng)絡(luò)參數(shù),使得最終損失比任何一個(gè) dropout 樣本的損失都低。這樣做的效果類似于對(duì)一個(gè) minibatch 中的每個(gè)輸入重復(fù)訓(xùn)練 M 次。因此,它大大減少訓(xùn)練迭代次數(shù),從而大幅加快訓(xùn)練速度。因?yàn)榇蟛糠诌\(yùn)算發(fā)生在 dropout 層之前的BERT層中,Multi-sample dropout 并不會(huì)重復(fù)這些計(jì)算,所以對(duì)每次迭代的計(jì)算成本影響不大。實(shí)驗(yàn)表明,multi-sample dropout 還可以降低訓(xùn)練集和驗(yàn)證集的錯(cuò)誤率和損失。
訓(xùn)練策略
任務(wù)自適應(yīng)預(yù)訓(xùn)練(TAPT)[5],在當(dāng)前和任務(wù)相關(guān)的數(shù)據(jù)集上進(jìn)行掩碼語(yǔ)言模型(MLM)訓(xùn)練,提升預(yù)訓(xùn)練模型在當(dāng)前數(shù)據(jù)集上的性能。
對(duì)抗訓(xùn)練是一種引入噪聲的訓(xùn)練方式,可以對(duì)參數(shù)進(jìn)行正則化,從而提升模型的魯棒性和泛化能力。我們采用FGM (Fast Gradient Method)[6],通過(guò)在嵌入層加入擾動(dòng),從而獲得更穩(wěn)定的單詞表示形式和更通用的模型,以此提升模型效果。
知識(shí)蒸餾[7]由Hinton在2015年提出,主要應(yīng)用在模型壓縮上,通過(guò)知識(shí)蒸餾用大模型所學(xué)習(xí)到的有用信息來(lái)訓(xùn)練小模型,在保證性能差不多的情況下進(jìn)行模型壓縮。我們將利用模型壓縮的思想,采用模型融合的方案,融合多個(gè)不同的模型作為teacher模型,將要訓(xùn)練的作為student模型。
假設(shè):采用arabertv模型,F(xiàn)1得分為70,采用不同參數(shù)、不同隨機(jī)數(shù),訓(xùn)練多個(gè)arabertv 模型融合后F1可以達(dá)到71;在采用xlm-roberta模型,訓(xùn)練多個(gè)模型后與arabertv模型進(jìn)行融合得到最終的F1為72。基于最后融合的多個(gè)模型,采用交叉驗(yàn)證的方式給訓(xùn)練集打上 soft label,此時(shí)的soft label已經(jīng)包含多個(gè)模型學(xué)到的知識(shí)。隨后再去訓(xùn)練arabertv模型,模型同時(shí)學(xué)習(xí)soft label以及本來(lái)hard label,學(xué)習(xí)soft label采用MSE損失函數(shù),學(xué)習(xí)hard label依舊采用交叉熵?fù)p失,通過(guò)這種方式訓(xùn)練出來(lái)的arabertv模型的F1可以達(dá)到71點(diǎn)多,最后將蒸餾學(xué)出來(lái)的模型再與原來(lái)的模型融合,得到最后的結(jié)果。
模型融合
為了更好地利用數(shù)據(jù),我們采用7折交叉驗(yàn)證,針對(duì)每一折我們使用了兩種預(yù)訓(xùn)練模型,又通過(guò)改變不同的參數(shù)隨機(jī)數(shù)種子以及不同的訓(xùn)練策略訓(xùn)練了多個(gè)模型,之后對(duì)訓(xùn)練集和測(cè)試集進(jìn)行預(yù)測(cè)。為了更好地融合模型,我們針對(duì)諷刺檢測(cè)采用了線性回歸模型進(jìn)行融合,針對(duì)情感識(shí)別模型,采用支持向量機(jī)SVM進(jìn)行融合。
實(shí)驗(yàn)結(jié)果
評(píng)價(jià)標(biāo)準(zhǔn),針對(duì)諷刺檢測(cè),只評(píng)價(jià)諷刺類的F1,針對(duì)情感分類則對(duì)各個(gè)類的F1求平均,為了更好地評(píng)估模型的好壞,我們采用7折交叉驗(yàn)證的形式,以下結(jié)果是交叉驗(yàn)證結(jié)果的平均。
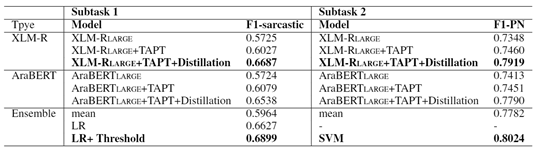
從下表中可以看出,無(wú)論是諷刺檢測(cè)任務(wù)還是情感分類任務(wù)都是XLM-Roberta 模型相對(duì)好一些,經(jīng)過(guò)TAPT和知識(shí)蒸餾后效果都有著顯著提升。對(duì)于諷刺檢測(cè)因?yàn)椴煌P椭g分?jǐn)?shù)相差比較大,直接求平均效果不行,而采用線性回歸后則達(dá)到了一個(gè)不錯(cuò)的水平,由于諷刺檢測(cè)類別不平衡,我們將閾值調(diào)整為0.41,即大于0.41為1類。同樣在情感分類任務(wù)中,由于多個(gè)模型之間的性能相差較大直接求平均也會(huì)造成性能的下降,我們最終采用SVM進(jìn)行模型融合。
原文標(biāo)題:賽道 | 深蘭載譽(yù)自然語(yǔ)言處理領(lǐng)域歐洲頂會(huì)EACL2021
文章出處:【微信公眾號(hào):DeepBlue深蘭科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
AI
+關(guān)注
關(guān)注
87文章
30146瀏覽量
268418 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
287瀏覽量
13332
原文標(biāo)題:賽道 | 深蘭載譽(yù)自然語(yǔ)言處理領(lǐng)域歐洲頂會(huì)EACL2021
文章出處:【微信號(hào):kmdian,微信公眾號(hào):深蘭科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論