 關于圖像修復詳細解析全局和局部一致性的圖像補全
關于圖像修復詳細解析全局和局部一致性的圖像補全
全局一致讓圖像補全的內容契合上下文,局部一致性讓紋理更加真實。
這里只是對我們之前所學內容的一個簡單回顧。
對于圖像修復,填充像素的紋理細節是很重要的。有效的像素和填充的像素應該是一致的,填充的圖像應該看起來真實。
粗略的說,研究者采用逐像素的重建損失(即L2損失)來確保我們可以用“正確”的結構來填補缺失的部分。另一方面,GAN損失(即對抗損失)和/或[紋理損失]應用于獲得具有更清晰的生成像素紋理細節的填充圖像。

圖1,一個例子來說明為圖像修復任務生成新的片段的需求。
對于基于patch的方法,一個很大的假設是我們相信我們可以在缺失區域之外找到相似的patch,這些相似的補丁將有助于填充缺失區域。這個假設對于自然場景可能是正確的,因為天空和草坪在一個圖像中可能有許多相似的patch。如果缺失區域之外沒有任何類似的patch,就像圖1中所示的人臉圖像修復的情況。在這種情況下,我們找不到眼睛的patch來填補相應的缺失部分。因此,魯棒的修復算法應該能夠生成新的片段。
現有的基于GAN的修復方法利用一個鑒別器(對抗損失)來增強填充區域的銳度,將填充區域輸入到鑒別器(即欺騙鑒別器)。有些人可能會在預訓練的網絡中比較缺失區域內部和外部的局部神經響應,以確保缺失區域內部和外部的局部小塊的紋理細節相似。如果我們同時考慮圖像的局部和全局信息來加強局部和全局一致性呢?我們會得到更好的完整圖像嗎?讓我們看看。
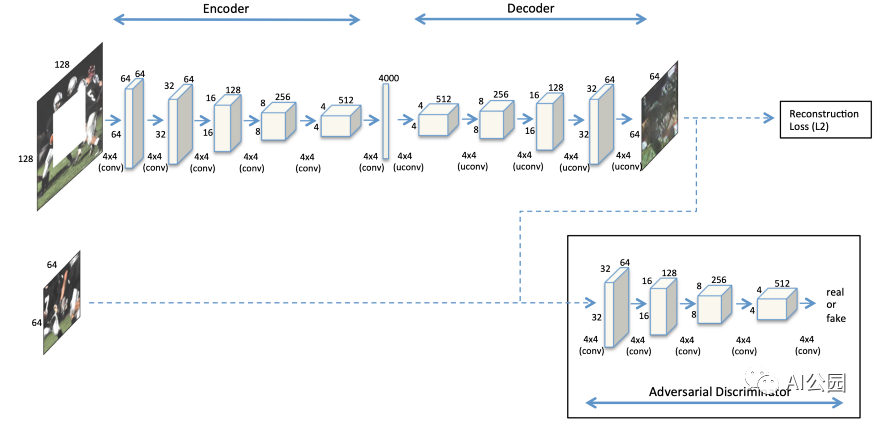
如何處理高分辨率圖像?我們之前已經討論過第一種基于GAN的修復方法,上下文編碼器。他們假設測試圖像總是128×128和一個64×64中心缺失的洞。然后,我們還在上一篇文章中介紹了上下文編碼器的改進版本,稱為Multi-Scale Neural Patch Synthesis。他們提出了一種多尺度的方法來處理測試圖像,最大的分辨率為512×512,中心缺失的孔為256×256。簡而言之,他們采用了三種不同尺度的圖像網絡,即128×128、256×256和512×512。因此,速度是他們提出的方法的瓶頸。使用Titan X GPU填充512×512的圖像大約需要1分鐘。這是個有趣的問題!我們如何處理高分辨率圖像,只需一個單一的的網絡?給你幾秒鐘的思考時間,你可能會從圖2所示的架構中發現一些提示(注意中間層)。一個快速的解決方案是去掉中間的全連接層,并采用全卷積網絡!你很快就會知道怎么做,為什么要這樣做!
介紹
現有的方法大多假設可以找到相似的圖像patch來填補同一幅圖像中缺失的部分。這種情況并不總是適用于圖像修復,見圖1。更準確地說,我們應該看整個圖像,了解它的上下文,然后根據它的上下文來填補缺失的部分。
如果使用全連接層,輸入圖像的大小必須是固定的。因此,網絡不能處理不同分辨率的測試圖像。回想一下,完全連接的層完全連接了兩層之間的所有神經元,因此它對前一層輸出大小的變化很敏感,測試圖像的大小必須固定。另一方面,對于卷積層,神經元之間沒有全連接。更小的輸入特征映射將導致更小的輸出特征映射。所以,如果一個網絡只由卷積層組成,它就可以處理不同大小的輸入圖像。我們稱這種網絡為全卷積網絡(FCNs)。
方案
采用膨脹卷積代替全連接層,這樣我們仍然可以理解圖像的上下文,構建一個全卷積網絡(Fully Convolutional Network, FCN)來處理不同大小的圖像。
使用兩個鑒別器來保證完成(填充)圖像的局部和全局一致性。一個鑒別器在全局意義上看整個圖像,而一個在局部意義上看被填充區域周圍的子圖像。
使用簡單的后處理。有時很明顯可以看出生成的像素和有效像素之間的區別。為了進一步提高圖像的視覺質量,本文采用了兩種傳統的方法,即Fast Marching method和Poisson image blend。這兩種技術超出了本文的范圍。之后,在一定程度上將后處理步驟以細化網絡的形式嵌入到網絡中。我們將在后面的文章中討論它。
貢獻
提出一種全卷積的網絡擴展卷積圖像修復。它允許我們在不使用全連接的層的情況下理解圖像的上下文,因此訓練過的網絡可以用于不同大小的圖像。這個架構實際上是后來基于深度學習的圖像修復方法的基礎。這就是為什么我認為這篇文章是圖像修復的一個里程碑。
建議使用兩個判別器(一個局部的和一個全局的)。多尺度鑒別器似乎可以在不同尺度上提供較好的完整圖像紋理細節。
強調圖像修復任務中產生新片段的重要性。實際上,訓練數據是非常重要的。簡單地說,你不能生成你以前沒見過的東西。
方法
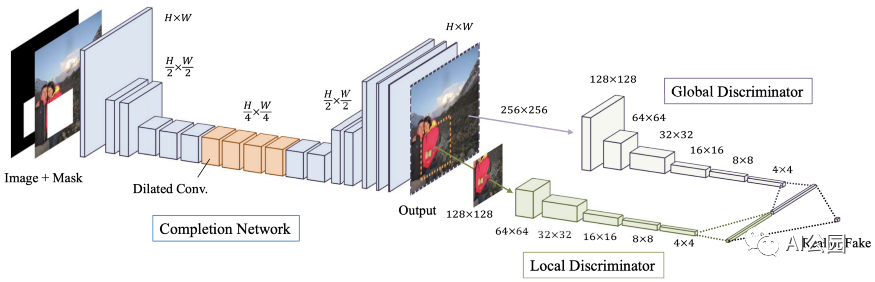
圖3,提出方法的結構
圖3顯示了提出的方法的網絡架構。它由三個網絡組成,分別是Completion網絡(即生成器,既用于訓練又用于測試)、局部鑒別器和全局鑒別器(用于剛訓練時作為輔助網絡用于學習)。快速回顧一下這個GAN框架。Generator負責補全圖像以欺騙discriminator,而discriminator負責將完整圖像與真實圖像區分開來。
CNNs中的膨脹卷積
膨脹卷積的概念對于讀者理解本文的網絡設計是很重要的。所以,我想盡力為那些不熟悉膨脹卷積的讀者解釋一下。對于非常了解它的讀者,也請快速回顧一下。
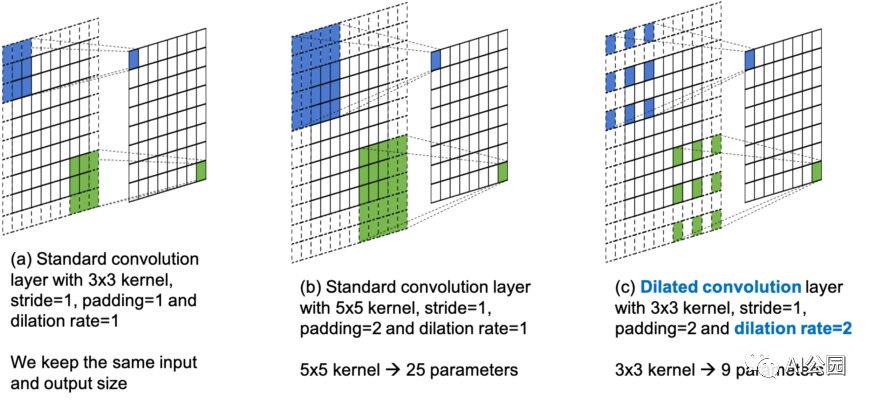
圖4,標準卷積和膨脹卷積的圖解
在論文中,作者用了半頁的篇幅來描述cnn、標準卷積和擴張卷積。并給出了相應的卷積方程供參考。我需要澄清一點,膨脹卷積并不是本文作者提出的,他們是將其用于圖像修復。
這里,我想用一個簡單的圖來說明標準卷積和膨脹卷積的區別。
圖4(a)是帶有3×3 kernel, stride=1, padding=1,膨脹率=1的標準卷積層。這種情況的設置中,8×8輸入給出8×8的輸出,每個相鄰的9個位置在輸出中貢獻一個元素。
圖4(b)也是一個標準的卷積層。這次我們使用5×5 kernel,stride=1, padding=2(為了保持相同的輸入和輸出大小)和膨脹率=1。在這種情況下,每個相鄰的25個位置對輸出的每個元素都有貢獻。這意味著對于輸出的每個值,我們必須更多地考慮(查看)輸入。我們通常指更大的感受野。對于一個大的感受野,更多的來自遙遠空間位置的特征將被考慮進去,在輸出時給出每個值。
然而,對于圖4(b)中的情況,我們使用一個更大的kernel (5×5)來獲得更大的感受野。這意味著需要學習更多的參數(3×3=9,而5×5=25)。有沒有辦法在不增加更多參數的情況下增加感受野?答案是膨脹卷積。
圖4(c)是一個膨脹卷積層,使用3×3 kernel, stride=1, padding=2,膨脹率=2。當比較圖4(b)和(c)中的kernel的覆蓋時,我們可以看到它們都覆蓋了輸入處的5×5局部空間區域。3×3的kernel可以通過跳過連續的空間位置來獲得5×5 kernel的感受野。跳躍的step是由膨脹率決定的。例如,一個3×3內核的膨脹率=2給出5×5感受野,一個3×3核的膨脹率=3給出一個7×7的感受野,以此類推。顯然,膨脹卷積通過跳過連續的空間位置來增加感受野,而不需要添加額外的參數。這樣做的優點是,我們有更大的感受野,同時有相同數量的參數。缺點是我們會跳過一些位置(我們可能會因此丟失一些信息)。
為什么要用膨脹卷積?
在回顧了膨脹卷積的概念之后,我將討論為什么作者在他們的模型中使用膨脹卷積。你們中的一些人可能已經猜到原因了。
如前所述,了解整個圖像的上下文對于圖像修復的任務是重要的。以前的方法使用全連接層作為中間層,以便理解上下文。記住,標準卷積層在局部區域執行卷積,而全連接層則完全連接所有的神經元(即每個輸出值取決于所有的輸入值)。然而,全連接層限制了輸入圖像的大小,并引入了更多的可學習參數。
為了解決這些限制,我們使用膨脹卷積來構建一個全卷積的網絡,允許不同大小的輸入。另一方面,通過調整標準kernel(通常是3×3)的膨脹率,我們可以在不同的層次上擁有更大的感受野,以幫助理解整個圖像的上下文。
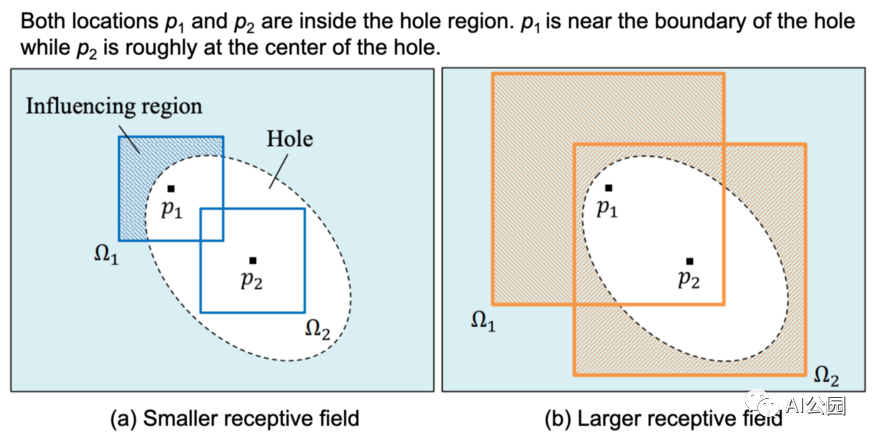
圖5,不同大小的感受野的影響。
圖5是一個展示膨脹卷積的有用性的例子。你可能認為(a)是帶有3×3核(較小的感受野)的標準卷積,(b)是帶有3×3核且擴張率≥2(較大的感受野)的膨脹卷積。位置p1和p2在孔內區域,p1靠近邊界,p2大致在中心點。對于(a),可以看到p1位置的感受野(影響區域)可以覆蓋有效區域。這意味著可以使用有效像素來填充位置p1的像素。另一方面,p2位置的感受野不能覆蓋有效區域,因此不能使用有效區域的信息進行生成。
對于(b),我們使用膨脹卷積來增加感受野。這一次,兩個位置的感受野都可以覆蓋有效區域。讀者現在可以認識到擴張卷積的有效性了。
Completion網絡
讓我們回到Completion 網絡的結構,如圖3所示。
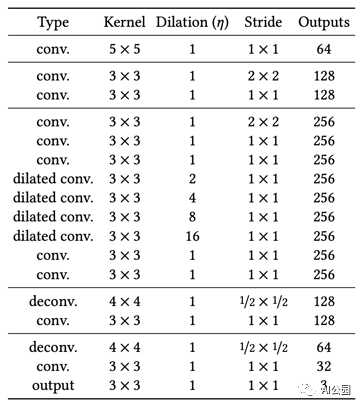
表1,Completion網絡結構。,每個卷積層后面都是ReLU,除了最后一個后面是Sigmoid
Completion 網絡是一個全卷積的網絡,接受不同大小的輸入圖像。該網絡對輸入進行2次2倍的下采樣。這意味著,如果輸入是256×256,中間層的輸入大小是64×64。為了充分利用有效像素,保證像素精度,我們用有效像素替換孔區域以外的像素。
上下文判別器
讓我們來談談局部和全局判別器。沒有什么特別的,就像單個判別器的情況一樣。唯一的不同是這次我們有兩個。
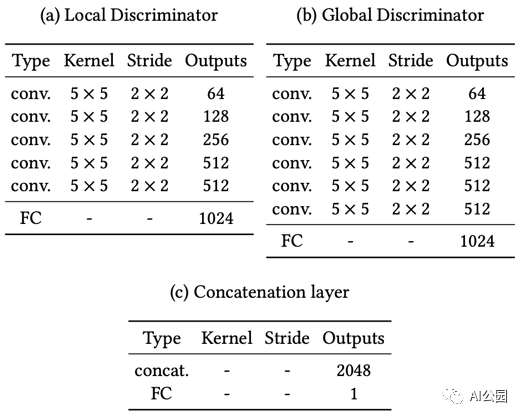
表2,局部和全局鑒別器的結構,FC代表全連接層,連接層(c)的最終FC后面是Sigmoid
局部和全局判別器的架構基本相同。全局判別器的輸入圖像大小為256×256(整個圖像,用于全局一致性),而局部判別器的輸入為128×128,圍繞缺失區域的中心,用于局部一致性。
需要注意的一點是,在訓練過程中,總有一個區域是缺失的。在測試過程中,圖像中可能存在多個缺失區域。除此之外,對于local discriminator,由于真實圖像沒有填充區域,所以對真實圖像采用128×128 patch的隨機選擇。
訓練策略和損失函數
與之前一樣,使用兩個損失函數來訓練網絡,即L2損失和對抗損失(GAN損失)。
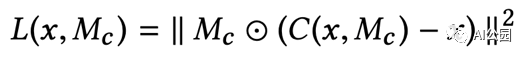
C(x, M_c)將completion網絡表示為函數。x是輸入圖像,M_c是表示缺失區域的二進制掩碼。缺失區域為1,外部區域為0。你可以看到L2損失是在缺失區域內計算的。注意,補全的圖像的外部區域的像素直接被有效像素替換。
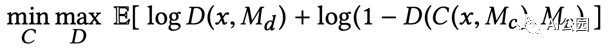
D(x, M_d)將兩個鑒別器表示為一個函數。M_d是一個隨機掩碼,用于為局部判別器隨機選擇一個圖像patch。這是一個標準的GAN損失。我們希望該判別器不能區分完整的圖像和真實的圖像,從而得到具有真實紋理細節的完整圖像。
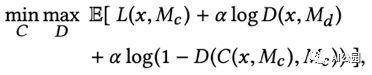
這是訓練網絡的聯合損失函數。alpha是一個加權超參數,以平衡L2損失和GAN損失。

作者將他們的訓練分為三個階段。i) 訓練僅帶L2損失的completion網絡,迭代次數為T_C。ii) 修正completion網絡,使用GAN損失訓練判別器進行T_D迭代。iii) 交替訓練completion網絡和判別器,直到訓練結束。
對于穩定訓練,除completion網絡的最后一層和判別器外,所有卷積層都采用批處理歸一化(BN)。
為了生成訓練數據,他們隨機地將圖像的最小邊緣大小調整到[256,384]像素范圍。然后,他們隨機截取256×256圖像補丁作為輸入圖像。對于掩模圖像,隨機生成一個區域,每個邊的范圍為[96,128]。
簡單的后處理:如前所述,作者還采用了傳統的Fast Marching方法,隨后采用泊松圖像混合,進一步提高完成圖像的視覺質量。
實驗
作者使用Places2數據集中的8097967張訓練圖像訓練他們的網絡。聯合損失函數中的alpha加權超參數設置為0.0004,batch大小為96。
本文中,completion網絡訓練為T_C = 90000次迭代,訓練判別器T_D = 10,000次迭代,最后聯合訓練所有網絡400,000次迭代。他們聲稱,整個訓練過程在一臺4個k80 GPU的電腦上大約需要2個月的時間。
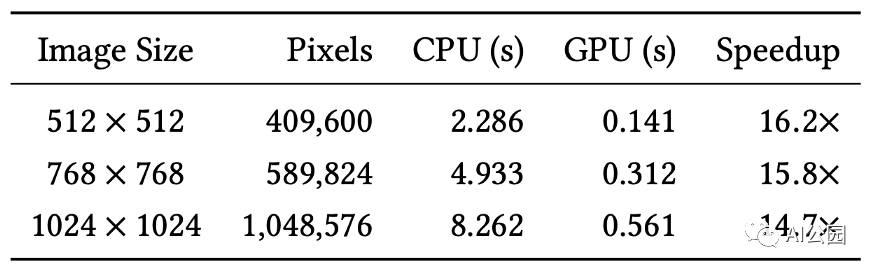
表3,所提出方法的用時
他們使用Intel Core i7-5960X 3.00 GHz 8核CPU和NVIDIA GeForce TITAN X GPU對CPU和GPU進行評估。實際上,速度相當快,只需半秒多一點就可以完成1024×1024的一張圖片。

圖6,和已有方法的對比
圖6顯示了與一些現有方法的比較。總的來說,基于patch的方法可以用局部一致的圖像patch來完成,但可能不會是全局一致的。最近的基于GAN的方法,上下文編碼器(第5行),傾向于給出模糊的完整圖像。該方法提供了局部和全局一致的完整圖像。

圖7,和上下文編碼器的對比,在同樣的數據集上訓練填補中心缺失孔洞
為了與最先進的基于GAN的修復方法進行比較,作者進行了中心區域補全,結果如圖7所示。可以看出,CE對于中心區域補全的性能優于任意區域補全(圖6)。在我看來,CE與本文方法在圖7中具有相似的性能。讀者可以放大看其中的差異。

圖8,不同判別器的效果
作者對這兩種判別器進行了消融研究。從圖8(b)和(c)可以看出,當不使用局部判別器時,補全的區域看起來更加模糊。另一方面,對于(d),如果只使用局部判別器,我們可以得到良好的局部一致紋理細節,但不能保證全局一致性。對于(e)中的full方法,我們獲得了局部和全局一致的結果。

圖9,簡單后處理的結果
圖9顯示了簡單后處理的效果。對于圖9(b),我們可以很容易地觀察到邊界。

圖10,使用不同的數據集的修復結果
圖10顯示了在不同數據集上訓練的模型的修復結果。注意,Places2包含了大約800萬張不同場景的訓練圖像,而ImageNet包含了100萬張用于目標分類的訓練圖像。我們可以看到,在Places2上訓練模型的結果比在ImageNet上訓練的結果稍好一些。

圖11,用提出的方法來做目標移除的例子
圖像修復的一個潛在應用是物體移除。圖11顯示了使用所提方法刪除目標的一些例子。

圖12,更多特定數據集的結果
本文的作者還考慮了域特定的圖像修復。他們在CelebA數據集和CMP Facade數據集上微調了他們的預訓練模型,這兩個數據集分別由202599和606張圖像組成。他們使用了Places2數據集上的預訓練模型。對于新的數據集,他們從無到有訓練判別器,然后進行completion網絡和判別器交替訓練。
圖12顯示了本文方法對特定領域圖像的修復結果。對于面部修復,該方法能夠生成眼睛和嘴等新的片段。對于立面的修復,本文提出的方法還能夠生成與整個圖像局部和全局一致的窗口等片段。
作者還對完整的面部圖像進行了用戶研究。結果表明,在10個用戶中,使用該方法得到的77.0%的完整人臉被視為真實人臉。另一方面,96.5%的真實面孔可以被這10個用戶正確識別。
限制和討論
以下是作者對其局限性和未來發展方向的幾點看法。

圖13,失敗的例子 i) mask在圖像的邊緣 ii) 復雜的場景
對于圖13左側的情況,我們可以看到缺失的部分位于上方圖像的邊框。作者聲稱,在這種情況下,可以從鄰近位置借用的信息更少,因此基于GAN的方法(第3行和第4行)比傳統的基于patch的方法(第2行)表現更差。另一個原因是這個例子是自然場景,所以基于patch的方法可以很好地工作。
對于圖13右側的例子,場景要復雜得多。根據這個mask,我們想要移除一個人,我們需要填充一些建筑的細節來完成這個復雜的場景。在這種情況下,所有的方法都不能正常工作。因此,在復雜的場景中填補缺失的部分仍然是的挑戰。

圖14,舉例說明生成新片段的重要性,我們只能生成之前在訓練中看到的內容。
作者提供了額外的例子來強調另外兩點。i) 產生諸如眼睛、鼻子、嘴巴等新穎片段的重要性。ii)訓練數據集的重要性。
對于無法找到相似的圖像patch來填補缺失部分的情況,基于patch的方法(第2行和第3行)無法正常工作,如圖14所示。因此,一個魯棒的修復算法必須能夠生成新的片段。
為了進一步顯示訓練數據集選擇的重要性,作者比較了在Places2 (General dataset, (d))和CelebA (Face dataset, (e))上訓練的兩個模型。顯然,(d)無法用合理的面部細節來填補缺失的部分,因為它是在沒有任何對齊的面部圖像的Places2上訓練的。另一方面,(e)工作得很好,因為它是在CelebA上訓練的,一個有許多對齊的人臉圖像的數據集。因此,我們只能生成我們在訓練中看到的東西。全面的修復還有很長的路要走。
總結
所提議的結構是后來大多數修復論文的基礎。膨脹卷積的全卷積網絡允許我們在不使用全連接的層的情況下理解圖像的上下文,因此網絡可以獲取不同大小的輸入圖像。
多尺度的鑒別器(在這里我們有兩個鑒別器,實際上有些可能有三個!) 對于在不同尺度上增強完整圖像的紋理細節是很有用的。
當場景很復雜的時候,補上缺失的部分仍然很有挑戰性。另一方面,自然場景是比較容易修復的。
要點
在這里,我想列出一些對以后的文章有用的觀點。
請記住,膨脹卷積的全卷積網絡是一種典型的圖像修復網絡結構。它允許不同大小的輸入,并提供類似于全連接層的功能(即幫助理解圖像的上下文)。
事實上,人臉圖像的修復相對來說比一般的圖像修復簡單。這是因為我們總是在人臉數據集上訓練一個模型來進行人臉圖像修復,而該數據集由許多對齊的人臉圖像組成。對于一般的圖像修復,我們可以訓練一個更多樣化的數據集,如Places2,它包含來自不同類別(如城市、建筑和許多其他類別)的數百萬張圖像。對于一個模型來說,學習生成所有具有良好視覺質量的東西要困難得多。不管怎樣,還有很長的路要走。
編輯:lyn
-
GaN
+關注
關注
19文章
1918瀏覽量
72977 -
patch
+關注
關注
0文章
14瀏覽量
8319 -
圖像修復
+關注
關注
0文章
11瀏覽量
2261
原文標題:圖像修復:全局和局部的一致性補全
文章出處:【微信號:cas-ciomp,微信公眾號:中科院長春光機所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一致性測試系統的技術原理和也應用場景
異構計算下緩存一致性的重要性

電感值和直流電阻的一致性如何提高?
新品發布 | 同星智能正式推出CAN總線一致性測試系統

銅線鍵合焊接一致性:如何突破技術瓶頸?

為什么主機廠愈來愈重視CAN一致性測試?

鋰電池組裝及維修的關鍵:電芯一致性的重要性

QSFP一致性測試的專業測試設備
銅線鍵合焊接一致性:微電子封裝的新挑戰

企業數據備份體系化方法論的七大原則:深入理解數據備份的關鍵原則:應用一致性與崩潰一致性的區別

深入理解數據備份的關鍵原則:應用一致性與崩潰一致性的區別

DDR一致性測試的操作步驟
微美全息(NASDAQ:WIMI)探索全局-局部特征自適應融合網絡框架在圖像場景分類中的創新運用





 工商網監
工商網監
評論