 簡述LTE系統中FPGA速率匹配算法的仿真及實現
簡述LTE系統中FPGA速率匹配算法的仿真及實現
摘要: 速率匹配是LTE系統中重要的組成部分。在詳細分析3GPP協議中Turbo編碼速率匹配算法的基礎上,給出了一種基于FPGA的速率匹配實現方案。該方案通過乒乓操作以減少速率匹配的處理延時;并以Virtex-6芯片為平臺,完成了仿真、綜合、板級驗證等工作。結果表明,基于該方案的速率匹配算法能夠明顯地縮小處理延遲。
LTE(長期演進)是3.9G的全球標準,采用OFDM和MIMO技術作為其無線網絡演進的唯一標準,極大地提高了系統的帶寬[1]。而速率匹配是LTE系統中重要的組成部分,因此速率匹配設計的優劣,決定整個系統性能的好壞[2]。LTE系統中,速率匹配是指傳輸信道上的比特被打孔或者被重發,以匹配物理信道的承載能力。
當輸入的比特數目超過物理信道的承載能力時,就要對輸入的序列進行打孔;而當輸入的比特數目不滿足物理信道的承載能力時,就要對輸入的序列進行重發。根據編碼方式的不同,速率匹配又可分為卷積編碼和Turbo編碼的速率匹配。FPGA在數字信號處理方面性能優越,利用FPGA做乒乓操作能夠明顯地提高數據的處理速度[3]。
1 速率匹配算法
1.1 速率匹配的整體流程
在LTE系統中,基于Turbo編碼的速率匹配過程如圖1所示。該過程主要包括子塊交織、比特收集、比特選擇和修剪[4]。


2.2 乒乓前控制模塊的FPGA實現
數據經過Turbo編碼器后分3路暫存在3個RAM中。當速率匹配模塊中的使能信號Rate_Match_En拉高時,所有的模塊開始工作。如果乒乓前控制模塊的啟動信號Control_Start為高電平并且接收到的碼塊個數是偶數,則子塊交織A模塊的啟動信號Interleavera_Start拉高,此時子塊交織A就會讀取外部RAM中的數據,進行子塊交織;否則子塊交織B模塊的啟動信號Interleaverb_Start拉高,子塊交織B會從外部RAM中讀取數據,進行子塊交織。從而實現了乒乓操作。
2.3 子塊交織的FPGA實現
以子塊交織A模塊為例。當子塊交織A的啟動信號拉高時,子塊交織A模塊會從外部RAM中讀取數據。首先讀取第1路數據。第1路數據讀取完畢后立即讀取第2路數據和第3路數據。第2路數據放在偶數位置,第3路數據放在奇數位置。在Turbo編碼模塊中,輸出的數據已經加入了填充比特。
為了區別填充比特和數據信息,輸入數據的位寬占2 bit,填充比特用3來表示。子塊交織輸出的數據仍然占2 bit的位寬,只有在比特修剪模塊后,數據才按照1 bit的位寬表示。在子塊交織的FPGA實現過程中,將外部RAM模擬成一個交織矩陣。交織矩陣的每一個元素對應RAM的每一個地址,每一個元素的具體內容對應于RAM的每一個數據。
在程序中,第1路數據與第2路數據的交織方法一樣,用變量F_Matrix_Column、S_Matrix_Column、T_Matrix_Column表示3個交織矩陣的列;用變量F_Matrix_Row、S_Matrix_Row、T_Matrix_Row表示3個交織矩陣的行。以讀取第1路數據為例,因為是行寫入列讀出,所以行變量F_Matrix_Row每個時鐘要自加1,直到行變量取到RTCsubblock-1時歸零,同時列變量F_Matrix_Column按照表1所示進行列交織。
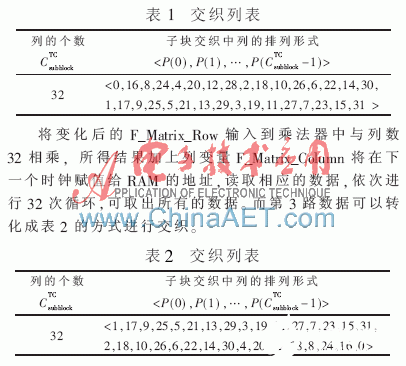
按表2進行交織以后,將RAM交織矩陣中最后一列的第1個地址中的數據放到該列的最后一個地址中,將剩下的數依次向上移一個地址即可。
2.4 乒乓后控制模塊的FPGA實現
在子塊交織A和子塊交織B開始工作時,乒乓后控制模塊也已經開始工作。當子塊交織A的啟動信號Interleavera_Start拉高時,乒乓后控制模塊會將子塊交織A輸入的數據傳輸給比特修剪模塊;反之,則會將子塊交織B輸入的數據傳輸給比特修剪模塊。
2.5 比特修剪模塊的FPGA實現
在比特修剪模塊中,一個碼塊的數據進行子塊交織后會緩存在一個RAM中。此方法可以阻止在輸入數據少于輸出數據需要重發操作時由于數據丟失而引起的傳輸錯誤。本程序中進行了乒乓操作,但由于輸入數據速率小于輸出數據的速率,所以乒乓操作不能做到無縫隙地進行,輸入的碼塊之間會有一定的間隔。
而為了將碼塊之間的間隔限制在最小范圍,將表示速率匹配輸出序列長度的變量E和表示取數起始位置的變量Ko輸出給Turbo編碼模塊,可使碼塊之間的間隔限制在最小。在比特修剪時,設置一個計數器變量counter,初始值設置為零。當RAM中緩存的數據大于Ko時,可以從RAM中讀取數據,若該數據是填充比特,則跳過,計數器counter不變;否則,計數器counter自加1,同時輸出數據。直到計數器counter的值等于E時,讀取數據完畢。等待下一個碼塊子塊交織后輸入的數據。
3 FPGA實現結果分析
圖3和圖4分別是PUSCH信道子塊交織的ModelSim仿真圖形和FPGA實現圖。本程序的時鐘頻率是200 MHz。Virtex-6芯片做為測試平臺。程序中DataOf-Interleaverb和DataOfInterleaverb是PUSCH信道子塊交織的輸出數據和標志位,A_Matrix_Row和A_Matrix_Column分別表示交織矩陣的行和列, A_addrb是RAM交織矩陣的地址。
由于交織矩陣的列數有32個,所以每次輸出數據的地址就要加32,以實現列讀出。變量A_Matrix_Row取到矩陣的最后一行后,又重新取下一列的第一行,直到32列全部取完為止。從PUSCH信道交織的仿真圖和FPGA實現圖可以看出,仿真結果與FPGA實現結果一致,因此FPGA能夠準確地實現PUSCH信道的子塊交織功能。
圖5和圖6分別是PUSCH信道比特修剪的ModelSim仿真圖形和FPGA實現圖。從圖形中可知,仿真結果與板級驗證的結果一致,FPGA能夠穩定、準確地實現比特修剪的功能。

子塊交織和比特修剪的Verilog[5]程序已經通過了Xilinx ISE 13.4[6]的編譯、仿真、板級驗證和聯機測試。結果表明,運用FPGA來實現速率匹配算法能夠滿足LTE系統對速率匹配的速度要求,同時也能夠充分發揮FPGA并行操作的優越性。在此基礎上,引用乒乓操作的方法,在不消耗更多資源的情況下,進一步縮短了速率匹配的處理時間,為整體系統的快速運行提供了基本的速度保障。由于該算法的FPGA實現在聯機測試中,性能穩定,故已在TD_LTE射頻一致性項目中得到應用。
參考文獻
[1] 陳發堂,李小文,王丹,等。移動通信接收機設計理論與實現[M]。北京:科學出版社,2011.
[2] Ma Chixiang,Lin Ping.Efficient implementation of rate matching for LTE Turbo codes[C].The 2nd International Conference on Future Computer and Communication(ICFCC 2010),2010:704-708.
[3] 曹華,鄧彬。使用Verilog實現基于FPGA的SDRAM控制器[J]。今日電子,2005,10(1):11-14.
[4] 3GPP TS 36.212 v9.1.0.3rd generation partner-ship project;technical specification group radio access network;evolved universal terrestrial radio access(E-UTRA);rate matching (Release 9)[S].2010.
[5] 夏宇聞.Verilog數字系統設計教程(第2版)[M]。北京:北京航空航天大學出版社,2008.
[6] XilinxInc.Foundation series user guide[EB/OL]。(2010-01-03)。
編輯:jq
-
ofdm
+關注
關注
6文章
349瀏覽量
56988 -
LTE
+關注
關注
15文章
1356瀏覽量
177738 -
MIMO
+關注
關注
12文章
592瀏覽量
76782 -
3GPP
+關注
關注
4文章
417瀏覽量
45189
發布評論請先 登錄
相關推薦
手寫圖像模板匹配算法在OpenCV中的實現

FPGA仿真黑科技\"EasyGo Vs Addon \",助力大規模電力電子系統仿真
如何用FPGA實現一個通信系統的發射端接收機?
為什么FPGA屬于硬件,還需要搞算法?
基于 FPGA 的光纖混沌加密系統
【分享】基于Easygo仿真平臺的三電機實時仿真測試應用
基于多速率DA的根升余弦濾波器的FPGA實現
fpga仿真器接口定義
怎么用FPGA做算法 如何在FPGA上實現最大公約數算法
浮點LMS算法的FPGA實現
雙目影像密集匹配算法的綜合分析






 工商網監
工商網監
評論