") 剖析計(jì)算機(jī)視覺識(shí)別簡(jiǎn)史
剖析計(jì)算機(jī)視覺識(shí)別簡(jiǎn)史
最近,物體識(shí)別已經(jīng)成為計(jì)算機(jī)視覺和 AI 最令人激動(dòng)的領(lǐng)域之一。即時(shí)地識(shí)別出場(chǎng)景中所有的物體的能力似乎已經(jīng)不再是秘密。隨著卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)的發(fā)展,以及大型訓(xùn)練數(shù)據(jù)集和高級(jí)計(jì)算技術(shù)的支持,計(jì)算機(jī)現(xiàn)在可以在某些特定設(shè)置(例如人臉識(shí)別)的任務(wù)中超越人類的識(shí)別能力。
我感覺每當(dāng)計(jì)算機(jī)視覺識(shí)別方面有什么驚人的突破發(fā)生了,都得有人再講一遍是怎么回事。這就是我做這個(gè)圖表的原因。它試圖用最簡(jiǎn)潔的語(yǔ)言和最有吸引力的方式講述物體識(shí)別的現(xiàn)代史。故事開始于2012年 AlexNet 贏得了 ILSVRC(ImageNet大規(guī)模視覺識(shí)別挑戰(zhàn)賽)。
信息圖由2頁(yè)組成,第1頁(yè)總結(jié)了重要的概念,第2頁(yè)則勾畫了歷史。每一個(gè)圖解都是重新設(shè)計(jì)的,以便更加一致和容易理解。所有參考文獻(xiàn)都是精挑細(xì)選的,以便讀者能夠知道從哪里找到有關(guān)細(xì)節(jié)的解釋。

計(jì)算機(jī)視覺 6 大關(guān)鍵技術(shù)
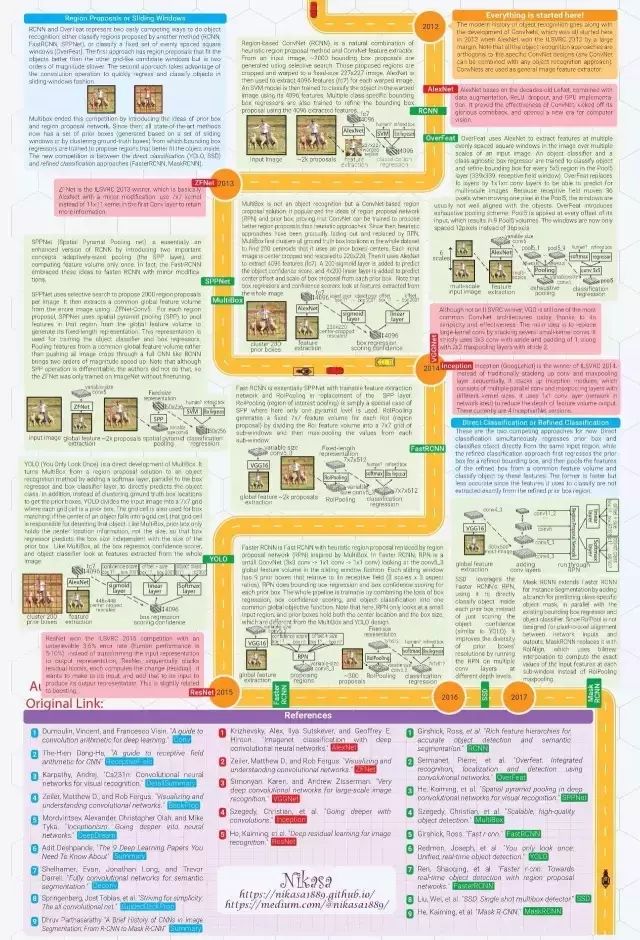
圖像分類:根據(jù)圖像的主要內(nèi)容進(jìn)行分類。數(shù)據(jù)集:MNIST, CIFAR, ImageNet
物體定位:預(yù)測(cè)包含主要物體的圖像區(qū)域,以便識(shí)別區(qū)域中的物體。數(shù)據(jù)集:ImageNet
物體識(shí)別:定位并分類圖像中出現(xiàn)的所有物體。這一過程通常包括:劃出區(qū)域然后對(duì)其中的物體進(jìn)行分類。數(shù)據(jù)集:PASCAL, COCO
語(yǔ)義分割:把圖像中的每一個(gè)像素分到其所屬物體類別,在樣例中如人類、綿羊和草地。數(shù)據(jù)集:PASCAL, COCO
實(shí)例分割:把圖像中的每一個(gè)像素分到其物體類別和所屬物體實(shí)例。數(shù)據(jù)集:PASCAL, COCO
關(guān)鍵點(diǎn)檢測(cè):檢測(cè)物體上一組預(yù)定義關(guān)鍵點(diǎn)的位置,例如人體上或者人臉上的關(guān)鍵點(diǎn)。數(shù)據(jù)集:COCO
關(guān)鍵人物
這種圖列出了物體識(shí)別技術(shù)中的關(guān)鍵人物:J. Schmidhuber;Yoshua Bengio ;Yann Lecun;Georey Hinton ;Alex Graves ;Alex Krizhevsky ;Ilya Sutskever ;Andrej Karpathy;Christopher Olah ;Ross Girshick;Matthew Zeiler ;Rob Fergus ;Kaiming He ;Pierre Sermanet ;Christian Szegedy ;Joseph Redmon ;Shaoqing Ren ;Wei Liu ;Karen Simonyan;Andrew Zisserman;Evan Shelhamer ;Jonathan Long ;Trevor Darrell;Springenberg ;Mordvintsev ;V. Dumoulin ;Francesco Visin;Adit Deshpande ……
重要的 CNN 概念
1. 特征 (圖案,神經(jīng)元的激活,特征探測(cè))

當(dāng)一個(gè)特定的圖案(特征)被呈現(xiàn)在輸入?yún)^(qū)(接受域)中時(shí),一個(gè)隱藏的神經(jīng)元就被會(huì)被激活。
神經(jīng)元識(shí)別的團(tuán)可以被進(jìn)行可視化,其方法是:1)優(yōu)化其輸入?yún)^(qū),將神經(jīng)元的激活(deep dream)最大化;2)將梯度(gradient)可視化或者在其輸入像素中,引導(dǎo)神經(jīng)元激活的梯度(反向傳播以及經(jīng)引導(dǎo)的反向傳播)3)將訓(xùn)練數(shù)據(jù)集中,激活神經(jīng)元最多的圖像區(qū)域進(jìn)行可視化。
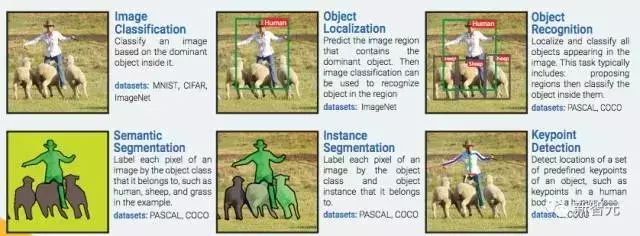
2. 感受野 (特征的輸入?yún)^(qū))
輸入圖像區(qū)會(huì)影響特征的激活。換句話說,它就是特征參考的區(qū)域。
通常,越高層上的特征會(huì)的接受域會(huì)更寬,這能讓它能學(xué)會(huì)捕捉更多的復(fù)雜/抽象圖案。ConvNet 的架構(gòu)決定了感受野是如何隨著層數(shù)的改變而改變的。
3. 特征地圖(feature map,隱藏層的通道)
指的是一系列的特征,通過在一個(gè)滑動(dòng)窗口(例如,卷積)的方式,在一個(gè)輸入地圖中的不同位置應(yīng)用相同的特征探測(cè)器來創(chuàng)造。在相同的特征地圖上的特征,有著一致的可接收形狀,并且會(huì)尋找不同位置上的相同圖案。這構(gòu)成了ConvNet的空間不變性。
4. 特征量(卷積中的隱藏層)
這是一組特征地圖,每一張地圖會(huì)在輸入地圖中的一些固定位置搜尋特定的特征。所有的特征的接受域大小都是一樣的。
5.作為特征量的全連接層

全連接層(fc layers,在識(shí)別任務(wù)中通常粘附在一個(gè)ConvNet的尾端),這一特征量在每一張?zhí)卣鞯稳肷隙加幸粋€(gè)特征,其接收域會(huì)覆蓋整張圖像。全連接層中的權(quán)重矩陣W可以被轉(zhuǎn)化成一個(gè)CNN核。
將一個(gè)核wxhxk 卷積成一個(gè)CNN 特征量wxhxd會(huì)得到一個(gè)1x1xk特征量(=FC layer with k nodes)。將一個(gè)1x1xk 的過濾核卷積到一個(gè)1x1xd特征量,得到一個(gè)1x1xk的特征量。通過卷積層替換完全連接的圖層可以使ConvNet應(yīng)用于任意大小的圖像。
6. 反卷積
這一操作對(duì)卷積中的梯度進(jìn)行反向傳播。換句話說,它是卷積層的反向傳遞。反向的卷積可以作為一個(gè)正常的卷積部署,并且在輸入特征中不需要任何插入。

左圖,紅色的輸入單元負(fù)責(zé)上方四個(gè)單元的激活(四個(gè)彩色的框),進(jìn)而能從這些輸出單元中獲得梯度。這一梯度反向傳播能夠通過反卷積(右圖)部署。
7. 端到端物體識(shí)別管道(端到端學(xué)習(xí)/系統(tǒng))
這是一個(gè)包含了所有步驟的物體識(shí)別管道 (預(yù)處理、區(qū)域建議生成、建議分類、后處理),可以通過優(yōu)化單個(gè)對(duì)象函數(shù)來進(jìn)行整體訓(xùn)練。單個(gè)對(duì)象函數(shù)是一個(gè)可差分的函數(shù),包含了所有的處理步驟的變量。這種端到端的管道與傳統(tǒng)的物體識(shí)別管道的完全相反。在這些系統(tǒng)中,我們還不知道某個(gè)步驟的變量是如何影響整體的性能的,所以,么一個(gè)步驟都必須要獨(dú)立的訓(xùn)練,或者進(jìn)行啟發(fā)式編程。
重要的目標(biāo)識(shí)別概念
1. Bounding box proposal
提交邊界框(Bounding box proposal,又稱興趣區(qū)域,提交區(qū)域,提交框)
輸入圖像上的一個(gè)長(zhǎng)方形區(qū)域,內(nèi)含需要識(shí)別的潛在對(duì)象。提交由啟發(fā)式搜索(對(duì)象、選擇搜索或區(qū)域提交網(wǎng)絡(luò)RPN)生成。
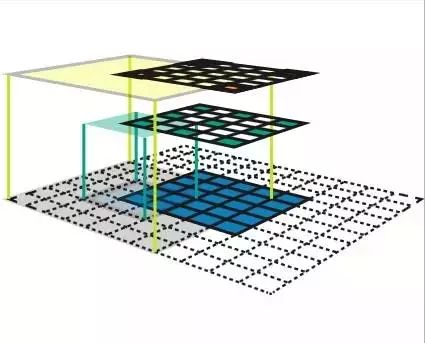
一個(gè)邊界框可以由4 元素向量表示,或表達(dá)為 2 個(gè)角坐標(biāo)(x0,y0,x1,y1),或表達(dá)為一個(gè)中心坐標(biāo)和寬與高(x,y,w,h)。邊界框通常會(huì)配有一個(gè)信心指數(shù),表示其包含對(duì)象物體的可能性。
兩個(gè)邊界框的區(qū)別一般由它們的向量表示中的 L2 距離在測(cè)量。w 和 h 在計(jì)算距離前會(huì)先被對(duì)數(shù)化。
2. Intersection over Union
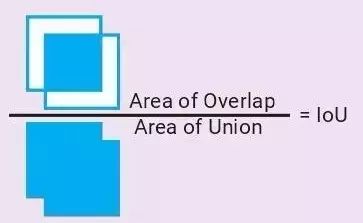
重疊聯(lián)合比(Intersection over Union,又稱 IoU,Jaccard 相似度)
兩個(gè)邊界框相似度的度量值=它們的重疊區(qū)域除以聯(lián)合區(qū)域
3. 非最大抑制(Non Maxium Suppression,又稱 NMS)
一個(gè)融合重疊邊界框(提交或偵測(cè)出的)的一般性算法。所有明顯和高信度邊界框重疊的邊界框(IoU 》 IoU_threshold)都會(huì)被抑制(去除)。
4. 邊界框回歸(邊界框微調(diào))
觀察一個(gè)輸入?yún)^(qū)域,我們可以得到一個(gè)更適合隱含對(duì)象的邊界框,即使該對(duì)象僅部分可見。下圖顯示了在只看到一部分對(duì)象時(shí),得出真實(shí)邊界框(ground truth box)的可能性。因此,可以訓(xùn)練回歸量,來觀察輸入?yún)^(qū)域,并預(yù)測(cè)輸入?yún)^(qū)域框和真實(shí)框之間的 offset △(x,y,w,h)。如果每個(gè)對(duì)象類別都有一個(gè)回歸量,就稱為特定類別回歸量,否則就稱為不可知類別(class-agnostic,一個(gè)回歸量用于所有類別)。邊界框回歸量經(jīng)常伴有邊界框分類器(信度評(píng)分者),來評(píng)估邊界框中在對(duì)象存在的可信度。分類器既可以是特定類別的,也可以是不可知類別的。如果不定義首要框,輸入?yún)^(qū)域框就扮演首要框的角色。
5. 首要框(Prior box,又稱默認(rèn)框、錨定框)

如果不使用輸入?yún)^(qū)域作為唯一首要框,我們可以訓(xùn)練多個(gè)邊界框回歸量,每一個(gè)觀測(cè)相同的輸入?yún)^(qū)域,但它們各自的首要框不同。每一個(gè)回歸量學(xué)習(xí)預(yù)測(cè)自己的首要框和真實(shí)框之間的 offset。這樣,帶有不同首要框的回歸量可以學(xué)習(xí)預(yù)測(cè)帶有不同特性(寬高比,尺寸,位置)的邊界框。相對(duì)于輸入?yún)^(qū)域,首要框可以被預(yù)先定義,或者通過群集學(xué)習(xí)。適當(dāng)?shù)目蚱ヅ洳呗詫?duì)于使訓(xùn)練收斂是至關(guān)重要的。
6. 框匹配策略

我們不能指望一個(gè)邊界框回歸量可以預(yù)測(cè)一個(gè)離它輸入?yún)^(qū)域或首要框(更常見)太遠(yuǎn)的對(duì)象邊界框。因此,我們需要一個(gè)框匹配策略,來判斷哪一個(gè)首要框與真實(shí)框相匹配。每一次匹配對(duì)回歸來說都是一個(gè)訓(xùn)練樣本。可能的策略有:(多框)匹配每一個(gè)帶有最高 IoU 的首要框的真實(shí)框;(SSD,F(xiàn)asterRCNN)匹配帶有任何 IoU 高于 0.5 的真實(shí)框的首要框。
7. 負(fù)樣本挖掘(Hard negative example mining)
對(duì)于每個(gè)首要框,都有一個(gè)邊界框分類器來評(píng)估其內(nèi)部含有對(duì)象的可能性。框匹配之后,所有其他首要框都為負(fù)。如果我們用了所有這些負(fù)樣本,正負(fù)之間本會(huì)有明顯的不平衡。可能的解決方案是:隨機(jī)挑選負(fù)樣本(FasterRCNN),或挑選那些分類器判斷錯(cuò)誤最嚴(yán)重的樣本,這樣負(fù)和正之間的比例大概是3:1 。
重要視覺模型發(fā)展:AlexNet→ZFNet→VGGNet
→ResNet→MaskRCNN
一切從這里開始:現(xiàn)代物體識(shí)別隨著ConvNets的發(fā)展而發(fā)展,這一切始于2012年AlexNet以巨大優(yōu)勢(shì)贏得ILSVRC 2012。請(qǐng)注意,所有的物體識(shí)別方法都與ConvNet設(shè)計(jì)是正交的(任意ConvNet可以與任何對(duì)象識(shí)別方法相結(jié)合)。ConvNets用作通用圖像特征提取器。
2012年 AlexNet:AlexNet基于有著數(shù)十年歷史的LeNet,它結(jié)合了數(shù)據(jù)增強(qiáng)、ReLU、dropout和GPU實(shí)現(xiàn)。它證明了ConvNet的有效性,啟動(dòng)了ConvNet的光榮回歸,開創(chuàng)了計(jì)算機(jī)視覺的新紀(jì)元。

RCNN:基于區(qū)域的ConvNet(RCNN)是啟發(fā)式區(qū)域提案法(heuristic region proposal method)和ConvNet特征提取器的自然結(jié)合。從輸入圖像,使用選擇性搜索生成約2000個(gè)邊界框提案。這些被推出區(qū)域被裁剪并扭曲到固定大小的227x227圖像。
然后,AlexNet為每個(gè)彎曲圖像提取4096個(gè)特征(fc7)。然后訓(xùn)練一個(gè)SVM模型,使用4096個(gè)特征對(duì)該變形圖像中的對(duì)象進(jìn)行分類。并使用4096個(gè)提取的特征來訓(xùn)練多個(gè)類別特定的邊界框回歸器來改進(jìn)邊界框。
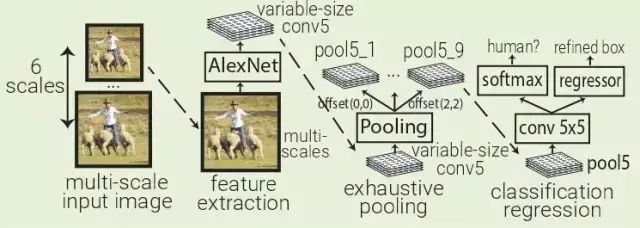
OverFeat:OverFeat使用AlexNet在一個(gè)輸入圖像的多個(gè)層次下的多個(gè)均勻間隔方形窗口中提取特征。訓(xùn)練一個(gè)對(duì)象分類器和一個(gè)類別不可知盒子回歸器,用于對(duì)Pool5層(339x339接收域窗口)中每5x5區(qū)域的對(duì)象進(jìn)行分類并對(duì)邊界框進(jìn)行細(xì)化。
OverFeat將fc層替換為1x1xN的卷積層,以便能夠預(yù)測(cè)多尺度圖像。因?yàn)樵赑ool5中移動(dòng)一個(gè)像素時(shí),接受場(chǎng)移動(dòng)36像素,所以窗口通常與對(duì)象不完全對(duì)齊。OverFeat引入了詳盡的池化方案:Pool5應(yīng)用于其輸入的每個(gè)偏移量,這導(dǎo)致9個(gè)Pool5卷。窗口現(xiàn)在只有12像素而不是36像素。
2013 年 ZFNet:ZFNet 是 ILSVRC 2013 的冠軍得主,它實(shí)際上就是在 AlexNet 的基礎(chǔ)上做了鏡像調(diào)整(mirror modification):在第一個(gè)卷積層使用 7×7 核而非 11×11 核保留了更多的信息。
SPPNet:SPPNet(Spatial Pyramid Pooling Net)本質(zhì)上是 RCNN 的升級(jí),SFFNet 引入了 2 個(gè)重要的概念:適應(yīng)大小池化(adaptively-sized pooling,SPP 層),以及對(duì)特征量只計(jì)算一次。實(shí)際上,F(xiàn)ast-RCNN 也借鑒了這些概念,通過鏡像調(diào)整提高了 RCNN 的速度。
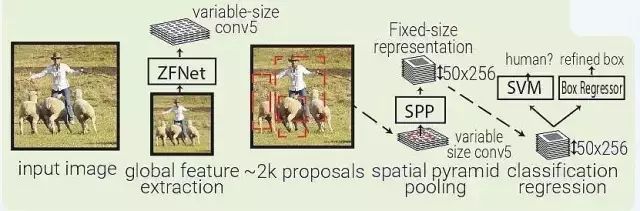
SPPNet 用選擇性搜索在每張圖像中生成 2000 個(gè)區(qū)域(region proposal)。然后使用 ZFNet-Conv5 從整幅圖像中抓取一個(gè)共同的全體特征量。對(duì)于每個(gè)被生成的區(qū)域,SPPNet 都使用 spatial pyramid pooling(SPP)將該區(qū)域特征從全體特征量中 pool 出來,生成一個(gè)該區(qū)域的長(zhǎng)度固定的表征。
這個(gè)表征將被用于訓(xùn)練目標(biāo)分類器和 box regressor。從全體特征量 pooling 特征,而不是像 RNN 那樣將所有圖像剪切(crops)全部輸入一個(gè)完整的 CNN,SPPNet 讓速度實(shí)現(xiàn)了 2 個(gè)數(shù)量級(jí)的提升。
需要指出,盡管 SPP 運(yùn)算是可微分的,但作者并沒有那么做,因此 ZFNet 僅在 ImageNet 上訓(xùn)練,沒有做 finetuning。
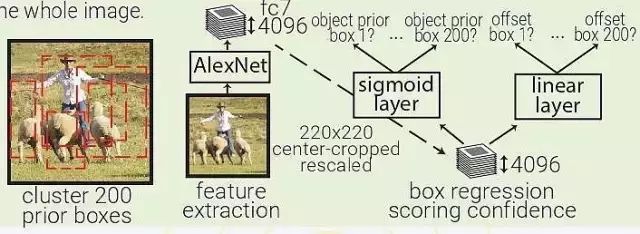
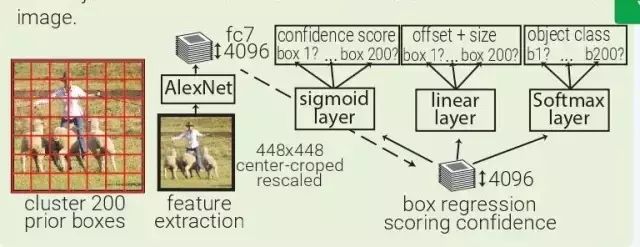
MultiBox:MultiBox 不像是目標(biāo)識(shí)別,更像是一種基于 ConvNet 的區(qū)域生成解決方案。MultiBox 讓區(qū)域生成網(wǎng)絡(luò)(region proposal network,RPN)和 prior box 的概念流行了起來,證明了卷積神經(jīng)網(wǎng)絡(luò)在訓(xùn)練后,可以生成比啟發(fā)式方法更好的 region proposal。自此以后,啟發(fā)式方法逐漸被 RPN 所取代。
MultiBox 首先將整個(gè)數(shù)據(jù)集中的所有真實(shí) box location 聚類,找出 200 個(gè)質(zhì)心(centroid),然后將其用于priorbox的中心。每幅輸入的圖像都會(huì)被從中心被裁減和重新調(diào)整大小,變?yōu)?220×220。
然后,MultiBox 使用 ALexNet 提取 4096 個(gè)特征(fc7)。再加入一個(gè) 200-sigmoid 層預(yù)測(cè)目標(biāo)置信度分?jǐn)?shù),另外還有一個(gè) 4×200-linear 層從每個(gè) prior box 預(yù)測(cè) centre offset 和 box proposal。注意下圖中顯示的 box regressors 和置信度分?jǐn)?shù)在看從整幅圖像中抓取的特征。
2014 年 VGGNet:雖然不是 ILSVRC 冠軍,VGGNet 仍然是如今最常見的卷積架構(gòu)之一,這也是因?yàn)樗?jiǎn)單有效。VGGNet 的主要思想是通過堆疊多層小核卷積層,取代大核的卷積層。VGGNet 嚴(yán)格使用 3×3 卷積,步長(zhǎng)和 padding 都為1,還有 2×2 的步長(zhǎng)為 2 的 maxpooling 層。
2014 年 Inception:Inception(GoogLeNet)是2014 年 ILSVRC 的冠軍。與傳統(tǒng)的按順序堆疊卷積和 maxpooling 層不同,Inception 堆疊的是 Inception 模塊,這些模塊包含多個(gè)并行的卷積層和許多核的大小不同的 maxpooling 層。Inception 使用 1×1 卷積層減少特征量輸出的深度。目前,Inception 有 4 種版本。
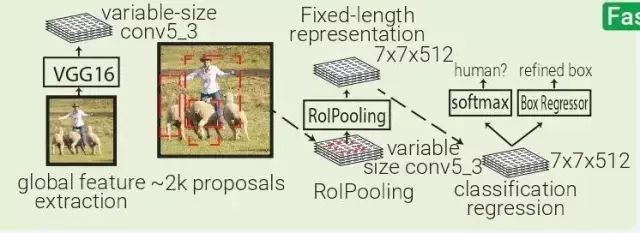
Fast RCNN:Fast RCNN本質(zhì)上源于SPPNET,不同的是 Fast RCNN 帶有訓(xùn)練好的特征提取網(wǎng)絡(luò),用 RolPooling 取代了 SPP 層。
YOLO:YOLO(You Only Look Once)是由 MultiBox 直接衍生而來的。通過加了一層 softmax 層,與 box regressor 和 box 分類器層并列,YOLO 將原本是區(qū)域生成的 MultiBox 轉(zhuǎn)為目標(biāo)識(shí)別的方法,能夠直接預(yù)測(cè)目標(biāo)的類型。
2015 ResNet:ResNet以令人難以置信的3.6%的錯(cuò)誤率(人類水平為5-10%)贏得了2015年ILSVRC比賽。ResNet不是將輸入表達(dá)式轉(zhuǎn)換為輸出表示,而是順序地堆疊殘差塊,每個(gè)塊都計(jì)算它想要對(duì)其輸入的變化(殘差),并將其添加到其輸入以產(chǎn)生其輸出表示。這與boosting有一點(diǎn)關(guān)。
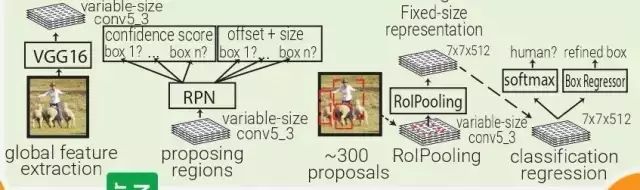
Faster RCNN:受 Multibox 的啟發(fā),F(xiàn)aster RCNN 用啟發(fā)式區(qū)域生成代替了區(qū)域生成網(wǎng)絡(luò)(RPN)。在 Faster RCNN 中,PRN 是一個(gè)很小的卷積網(wǎng)絡(luò)(3×3 conv → 1×1 conv → 1×1 conv)在移動(dòng)窗口中查看 conv5_3 全體特征量。
每個(gè)移動(dòng)窗口都有 9 個(gè)跟其感受野相關(guān)的 prior box。PRN 會(huì)對(duì)每個(gè) prior box 做 bounding box regression 和 box confidence scoring。通過結(jié)合以上三者的 loss 成為一個(gè)共同的全體特征量,整個(gè)管道可以被訓(xùn)練。
注意,在這里 RPN 只關(guān)注輸入的一個(gè)小的區(qū)域;prior box 掌管中心位置和 box 的大小,F(xiàn)aster RCNN 的 box 設(shè)計(jì)跟 MultiBox 和 YOLO 的都不一樣。
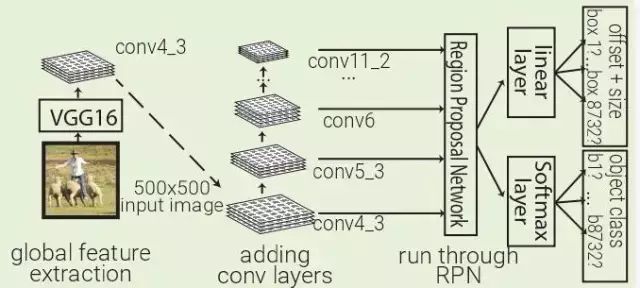
2016 年 SSD:SSD 利用 Faster RCNN 的 RPN,直接對(duì)每個(gè)先前的 box 內(nèi)的對(duì)象進(jìn)行分類,而不僅僅是對(duì)對(duì)象置信度(類似于YOLO)進(jìn)行分類。通過在不同深度的多個(gè)卷積層上運(yùn)行 RPN 來改善前一個(gè) box 分辨率的多樣性。
2017 年 Mask RCNN:通過增加一支特定類別對(duì)象掩碼預(yù)測(cè),Mask RCNN 擴(kuò)展了面向?qū)嵗指畹腇aster RCNN,與已有的邊界框回歸量和對(duì)象分類器并行。由于 RolPool 并非設(shè)計(jì)用于網(wǎng)絡(luò)輸入和輸出間的像素到像素對(duì)齊,MaskRCNN 用 RolAlign 取代了它。RolAlign 使用了雙線性插值來計(jì)算每個(gè)子窗口的輸入特征的準(zhǔn)確值,而非 RolPooling 的最大池化法。
編輯:jq
-
SVM
+關(guān)注
關(guān)注
0文章
154瀏覽量
32337 -
卷積
+關(guān)注
關(guān)注
0文章
94瀏覽量
18466 -
分類器
+關(guān)注
關(guān)注
0文章
152瀏覽量
13149 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1685瀏覽量
45810
原文標(biāo)題:計(jì)算機(jī)視覺識(shí)別簡(jiǎn)史:從 AlexNet、ResNet 到 Mask RCNN
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
機(jī)器視覺和計(jì)算機(jī)視覺有什么區(qū)別
計(jì)算機(jī)視覺的工作原理和應(yīng)用
計(jì)算機(jī)視覺與人工智能的關(guān)系是什么
計(jì)算機(jī)視覺與智能感知是干嘛的
計(jì)算機(jī)視覺和機(jī)器視覺區(qū)別在哪
計(jì)算機(jī)視覺在人工智能領(lǐng)域有哪些主要應(yīng)用?
計(jì)算機(jī)視覺屬于人工智能嗎
深度學(xué)習(xí)在計(jì)算機(jī)視覺領(lǐng)域的應(yīng)用
計(jì)算機(jī)視覺的主要研究方向
計(jì)算機(jī)視覺的十大算法

計(jì)算機(jī)視覺與圖像處理、模式識(shí)別、機(jī)器學(xué)習(xí)學(xué)科之間的關(guān)系
工業(yè)視覺與計(jì)算機(jī)視覺的區(qū)別
計(jì)算機(jī)視覺:AI如何識(shí)別與理解圖像
什么是計(jì)算機(jī)視覺?計(jì)算機(jī)視覺的三種方法

最適合AI應(yīng)用的計(jì)算機(jī)視覺類型是什么?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論