 攝像頭在汽車上的輔助駕駛功能是如何實現的?
攝像頭在汽車上的輔助駕駛功能是如何實現的?
引言
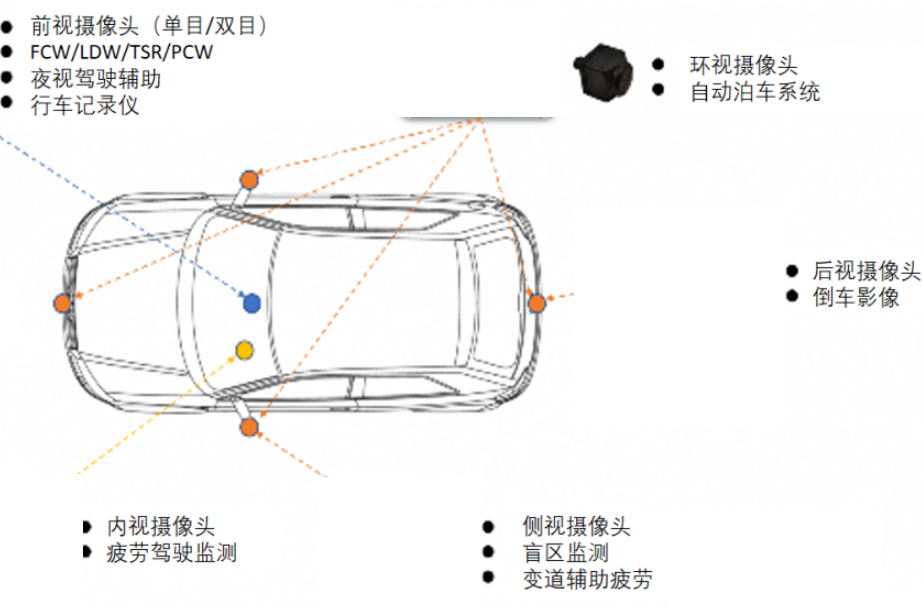
相信很多小伙伴們通過之前攝像頭的基礎知識講解,已經對車載攝像頭有一定的了解,攝像頭兩大主要功能是定位和感知,我們通過不同的軟硬件來實現前向碰撞預警、行人探測與防撞預警、車道保持與危險預警、車道偏離預警、交通標志識別等功能,那么攝像頭在我們現有汽車上這些輔助駕駛功能是如何實現的呢?本期小編整理了一些視覺傳感器相關技術方面的資料,讓我們一起來探究一下吧。
01視覺感知概述
目前自動駕駛的視覺感知算法,業內一般分成傳統視覺算法和深度學習算法,兩者既有著關聯,也有著不同點。本期小編通過傳統視覺感知的幾個關鍵步驟來為大家講解,我們下期再聊關于深度學習方面的視覺感知算法。
02標定及特征提取
一、標定
標定,是為了幫助攝像頭最終成像時獲得清晰圖像或通過攝像頭獲得物體大小、測量距離結果準確度所作的軟硬件校準及相應算法調試的過程。標定的精度及算法的穩定性將直接影響攝像頭的準確性。
根據攝像頭自身產品因素和外部安裝因素,自身內部標定簡稱內參,外部安裝的標定簡稱外參。
1 內參
攝像可以用來標定的自身參數稱為內參。內參的參數一般包含鏡頭畸變,焦距,像素尺寸寬,像素尺寸高,中心點坐標寬,中心點坐標高,圖片尺寸。下面我們就來探究一下關鍵的內參值:鏡頭畸變、光心以及焦距。
鏡頭畸變
我們所熟知的攝像頭鏡頭是由幾片透鏡組成的光學儀器,但是由于透鏡的固有特性(凸透鏡匯聚光線、凹透鏡發散光線)會導致相機成像存在著透視失真,透視失真也被統稱為鏡頭畸變。因為這種鏡頭畸變是物理層面無法消除的,只能改善,所以就需要對鏡頭畸變進行校準標定。
鏡頭畸變根據成像效果又分為徑向畸變和切向畸變。
徑向畸變,被攝物體在經過光學系統成像時,會造成圖像點從主點開始沿著徑向線發生位移,如下圖所示:
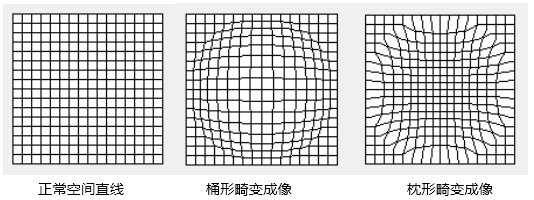
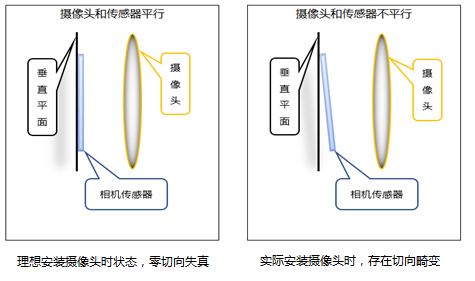
切向畸變,由于裝配方面的誤差,相機傳感器(CMOS或CCD)與光學鏡頭之間并非完全平行,因此成像存在切向畸變,但在成像方面通常沒有徑向畸變那么嚴重。
光心,是位于透鏡主軸上中央的一個特殊點,凡是通過該點的光,其傳播方向不變。通過標定光心的真實位置,才能計算出攝像頭的焦點和焦距所在的準確位置。
焦距,也稱為焦長,以相機為例,焦距是從鏡片光心到底片、CCD或CMOS等成像平面的距離。當對同一距離遠的同一個被攝目標拍攝時,鏡頭焦距長的所成的像大,鏡頭焦距短的所成的像小。標定焦距后的準確度將決定相機最終成像的清晰度和成像大小。
2 外參
外參標定,是攝像頭將自身的位置坐標與被觀測物體的現實世界坐標系之間建立相對位置關系。攝像頭不僅需要上述的內部標定,也需要在安裝到汽車內后進行外部軟硬件聯動調試,以確保攝像頭的成像效果和物體位置測量距離的準確度。
二、傳統圖像特征提取
眾所周知,計算機是不認識圖像的,只認識數字0和1。為了使計算機能夠“理解”圖像,從而具有真正意義上的“視覺”,于是我們通過從圖像中提取有用的數據或信息,得到圖像的“非圖像表示或描述”,如數值、向量和符號等,這一過程就是特征提取,而提取出來的這些“非圖像表示或描述”就是特征。
有了這些數值或向量形式的特征,再通過建立特征庫,我們就可以通過訓練過程教會計算機如何懂得這些特征,從而使計算機具有識別圖像的本領。
上述的特征提取一般包括點、線,圖像分割,光流,機器學習特征,SVM行人車輛識別等要素提取。
看起來挺簡單的原理,其實是個十分復雜的過程,小編曾在《攝像頭基礎介紹》里面舉過一個例子,比如說我們打開搜索網站搜索“桌子”,會發現有很多種的樣子。
雖然桌子樣式有很多,但是它也是由點、線、面組成的。計算機為了更好的識別出物體是什么,還會將圖片上相同顏色區域進行圖像分割,再配合光流變化和機器學習得到的特征要素等,計算機就能識別出圖片上的物體是桌子而不是椅子。
目前圖像特征的提取主要有兩種方法:傳統圖像特征提取方法和深度學習方法。
傳統的特征提取方法:基于圖像本身的特征進行提取;
深度學習方法:基于樣本自動訓練出區分圖像的特征分類器;
傳統的圖像特征提取一般分為三個步驟:預處理、特征提取、特征處理;然后在利用機器學習等方法對特征進行分類等操作。
預處理:預處理的目的主要是排除干擾因素,突出特征信息;主要的方法有:
圖片標準化:調整圖片尺寸;
圖片歸一化:調整圖片重心為0;
特征提取:利用特殊的特征子空間,完成對圖像的特征提取。涉及算法主要有:Harris、SIFT、SURF、LBF、HOG、DPM;
特征處理:主要目的是為了排除信息量小的特征,減少計算量等。常見的特征處理方法是降維,常見的降維方法有:主成分分析、奇異值分解、線性判別分析;
實話說,小編看到這么多的傳統圖像特征提取算法真的是非常佩服工程師們的技術能力。那么下面小編抽取了一些常用的特征提取算法為大家簡單講解個概要:
Harris算法是一種角點特征描述子;角點對應于物體圖像關鍵的局部結構特征,通過鄰近像素點灰度差值概念,從而判斷是否為角點、邊緣、平滑區域。例如:道路的十字路口等。
SIFT算法尺度不變特征變換(Scale invarialt feature transform)是基于物體上的一些局部外觀的興趣點,該算法與影像的旋轉、尺度大小縮放、亮度變化無關;對視角變化、仿射變換、噪聲也保持一定程度的穩定性;基于這些特性,SIFT算法在龐大的特征數據庫中,很容易辨識出物體而且鮮有誤認。使用SIFT特征描述對于部分物體遮蔽的偵測率也相當高,甚至只需要3個以上的SIFT物體特征就足以計算出位置與方位。
SURF算法(Speeded Up Robust Features)直譯為:加速版的具有魯棒特性的特征算法,該算法對經典的尺度不變特征變換算法(SIFT算法)進行了改進,以更高效的方式改進了特征提取和描述的方式。SURF算法采用了Haar特征以及積分圖像的概念,這大大的加速了程序的運行時間,需要硬件或者專門的圖像處理器進行加速。SURF算法一般應用于計算機視覺中的物體識別、圖像拼接、圖像配準以及3D重建中。
HOG算法(Histogram of Oriented Gradient) 方向梯度直方圖,是通過計算和統計圖像局部區域的梯度方向直方圖來構成特征提取的算法。Hog特征結合SVM(Surpport Vector Machine)分類器特別適合于做圖像中的行人檢測。
DPM算法(Deformable Parts Model)是一個目標檢測算法,已成為眾多分類器、分割、人體姿態和行為分類的重要部分。DPM可以看做是HOG算法的擴展,大體思路與HOG一致。先計算梯度方向直方圖,然后用SVM訓練得到物體的梯度模型(Model)。有了這樣的模板就可以直接用來分類了,簡單理解就是模型和目標匹配。DPM只是在模型上做了很多改進工作。
03常見視覺算法
VSLAM定位,SLAM(SimultaneousLocalization andMapping)是同步定位與地圖構建,是指根據傳感器的信息,一邊計算自身位置,一邊構建環境地圖的過程,解決在未知環境下運動時的定位與地圖構建問題。VSLAM(VisualSLAM算法)則更為高級,是基于camera圖像做SLAM的算法,即視覺的定位與建圖,中文也叫視覺SLAM,相當于裝上眼睛,通過眼睛來完成定位和掃描,更加精準和迅速。
Sfm(Structurefrom Motion)是一種從運動中實現3D重建。也就是從時間系列的2D圖像中推算3D信息。用于自動駕駛環境稠密點云重建。
MVS(Multi-viewstereo,多視重建),立體視覺法將多個相機設置于視點,或用單目相機在多個不同的視點拍攝圖像以增加穩健性,通常使用環視攝像頭來重建稠密點云。
VADAR(視覺點云,是SFM和MVS統稱),通過VADAR得到和Lidar同樣的點云,可以做更多的檢測和分割功能。目前特斯拉和mobileyeQ5均使用多個攝像頭拍攝的2D圖像進行深度學習處理,生成3D模型,從而為自動駕駛決策提供所需的環境信息。說得簡單一點,就是依靠算法和芯片的強大計算量,將多個攝像頭輸出的2D畫面“升級”為3D畫面實現自動駕駛。
結語:
相信通過上述傳統攝像頭算法的介紹,大家也深深的感受到了單目攝像頭視覺傳感器要幫助我們行車更加安全、便捷,不是一個容易的事情。需要通過工程師們對攝像頭硬件的標定,各種特征點提取軟件算法,還有芯片、視覺方面的硬件匹配等。傳統單目攝像頭視覺算法已經如此的繁瑣,那么深度學習算法又是怎樣實現的呢?帶著這些問題,下期小編繼續為大家整理深度學習視覺算法相關技術資料,敬請期待吧!
原文標題:新·知丨自動駕駛傳感器那點事之 攝像頭傳統視覺技術
文章出處:【微信公眾號:四維圖新NavInfo】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
傳感器
+關注
關注
2548文章
50684瀏覽量
752023 -
自動駕駛
+關注
關注
783文章
13685瀏覽量
166150
原文標題:新·知丨自動駕駛傳感器那點事之 攝像頭傳統視覺技術
文章出處:【微信號:realnavinfo,微信公眾號:四維圖新NavInfo】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
攝像頭及紅外成像的基本工作原理

愛普生 SG-8201CJA可編程晶振車載攝像頭的精準視覺時鐘守護

微測輻射熱計陣列的紅外攝像頭,用于提高自動駕駛的安全性

聚焦MIPI 系列之三:汽車SerDes – 實現更好的ADAS攝像頭傳感器

FPGA在自動駕駛領域有哪些應用?
基于FPGA的攝像頭心率檢測裝置設計
智能攝像頭抄表器是什么?

LG Innotek開發高性能加熱攝像頭模塊,邁向自動駕駛市場領導者地位
高清網絡攝像頭多媒體智能屏

用usb攝像頭替換手機前置攝像頭可以嗎
AHD攝像頭與CVBS的區別
淺談ADAS前置攝像頭設計挑戰
自動駕駛攝像頭分類與功能應用





 工商網監
工商網監
評論