 如何去制作目標檢測的訓練樣本圖像
如何去制作目標檢測的訓練樣本圖像
本文從五個問題出發依次遞進講解了該如何去制作目標檢測的訓練樣本圖像,并推薦了訓練樣本圖像制作工具以及使用步驟。
【 看到這個題目相信不少人第一感覺是小題大作、故弄玄虛。不過還請先稍微按捺一下胸中的不快,在腦中給出下面這幾個問題的答案。然后對照一下本文將要給出的答案,看看是否能夠心平氣和。】
像元值應該如何進行歸一化?
樣本圖像的尺寸僅與內存、顯存大小有關嗎?
網絡能檢測的目標框范圍只與圖像大小有關嗎?
卷積網絡真的具有平移和旋轉不變性?
制作目標檢測訓練樣本的最佳方案是什么?
以下為原文:
像元值應該如何進行歸一化?
不能想當然地認為像元值的取值范圍就是0到255,雖然普通數碼相機拍攝出來的圖像各個通道的取值范圍確實是0-255。要知道這個0-255的取值是從更大取值范圍處理得來的。在局部強烈光照下或者均勻光照下,還是弱光環境或者強光環境,人眼能夠感受到相同的顏色,但是數碼相機的傳感器會量化出不同的像元值。RGB的取值對應了固定的顏色,不同環境下傳感器會量化出的像元值要怎么才能映射為一致的顏色?這個技術就叫做寬動態。為了寬動態處理結果更細膩,傳感器的量化范圍通常更大。如下圖,左側是關閉了寬動態的效果,在這個圖上要想把手機檢測出來幾乎是不可能的。
由于數碼相機做過了寬動態處理,對普通數碼照片進行歸一化,可以簡單的將0-255線性映射到0-1。而醫學圖像、遙感圖像則不能簡單的利用最小最大像元值歸一化到0-1。由于白噪聲的存在,醫學圖像、遙感圖像的直方圖通常如下圖所示(橫軸代表像元值范圍,紅色縱軸表示歸一化后的取值,綠色縱軸表示不同像元值的像素頻數,綠色曲線就是直方圖)。
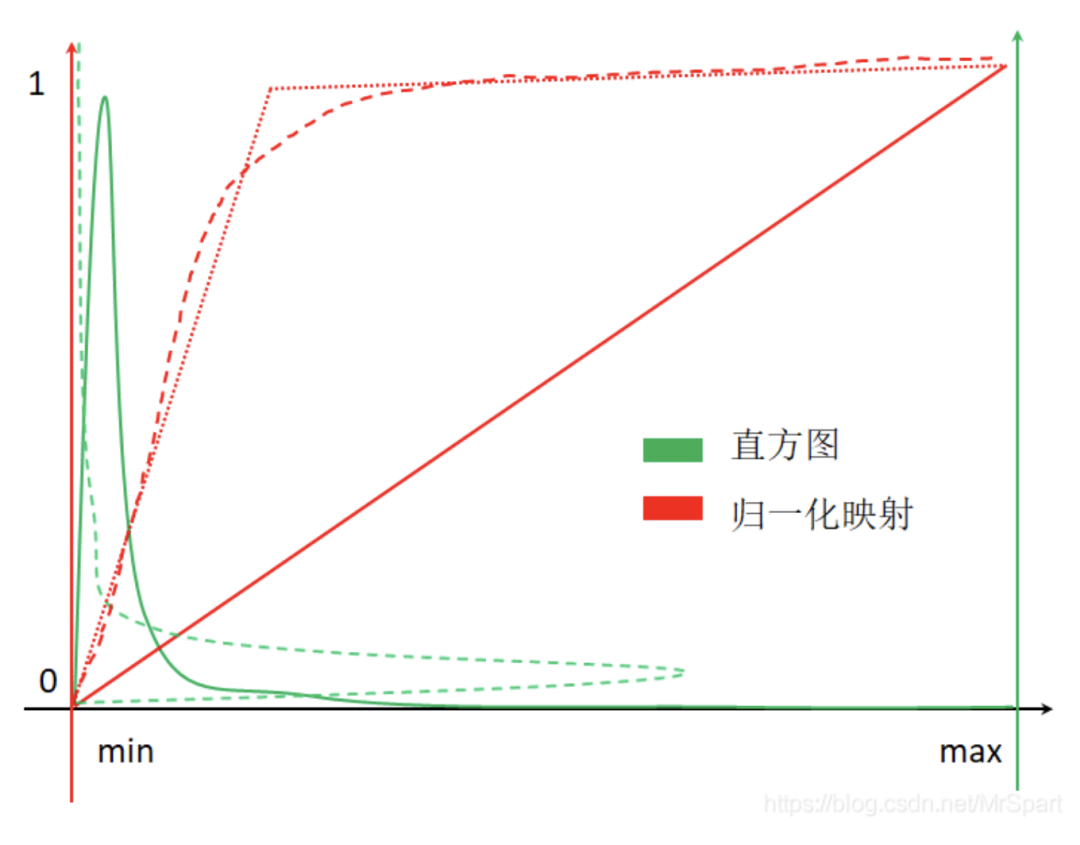
如果按照紅色實線代表的歸一化映射進行處理,最終絕大多少像素取值集中在0附近,整幅圖像一片黑(翻轉后的綠色虛曲線就是歸一化后的直方圖。最佳的處理方式是按照紅色長線段虛線代表的映射進行歸一化,但是這個映射難以求解,一般按照紅色點虛線代表的映射進行處理就行。
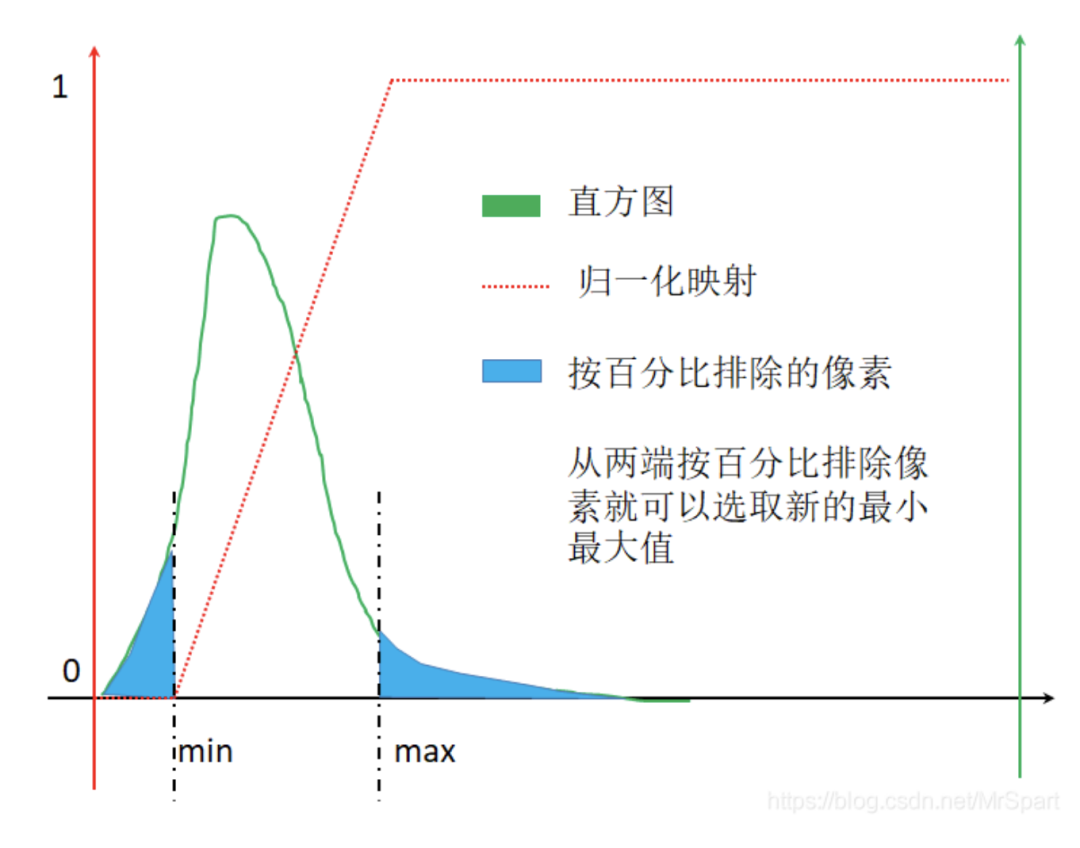
紅色點虛線代表的映射其實挺簡單的,選取合適的最小最大值,小于最小值的置為0,大于最大值的置為1,中間的線性映射。最大最小值的選取方法有均值+-x*標準差和排除兩端一定占比的像素。排除兩端一定占比的像素的示意圖如下,從兩端按照百分比排除像素時就能夠選取新的最小最大值,此時的歸一化映射圖像為紅色點虛線。
樣本圖像的尺寸僅與內存、顯存大小有關嗎?
如果柵格的邊長減去1后不能被stride整除,卷積的降采樣過程會丟棄邊緣的像素,結果是特征圖像素與輸入圖像位置映射會產生偏移。最終的特征圖是不能完整映射到輸入圖像范圍的,拿一個錯位的特征圖像素去預測原圖上的目標,想想都不靠譜。目前所有的深度學習框架都沒有考慮這里的映射錯位關系,就算用Mask-RCNN提供的ROIAlign也是錯位的。
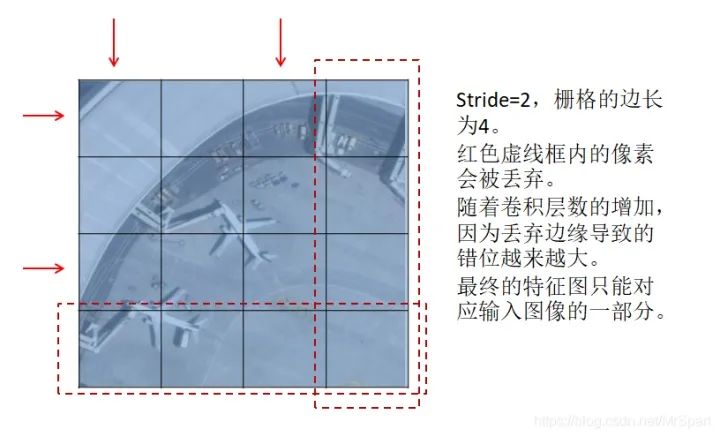
所以訓練時輸入樣本圖像的大小和檢測時切塊的大小只能用最終特征圖的尺寸反推回去,保證在卷積過程中不丟棄邊緣。
網絡能檢測的目標框范圍只與圖像大小有關嗎?
感受野是直接或者間接參與計算特征圖像素值的輸入圖像像素的范圍,直接感受野就是卷積核大小,隨著卷積層數的加深之前層次的感受野會疊加進去。感受野小了缺乏環境信息,感受野大了引入太多環境干擾,所以一個網絡能夠檢測的目標框范圍與特征圖像素或者特征向量的感受野有關,通常能夠檢測的目標框邊長范圍是感受野邊長的0.1-0.5倍。
詳細結論參考論文:Understanding the effective receptive field in semantic image segmentation
https://www.onacademic.com/detail/journal_1000040207575210_3759.html
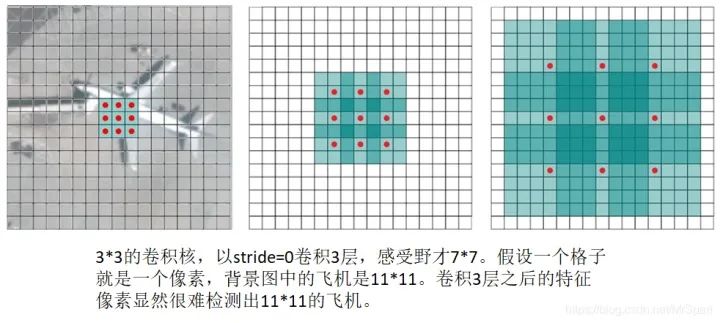
拿到了一個網絡要做感受野分析,然后確定它能夠檢測多少像素的目標。實際目標檢測任務需要綜合網絡結構設計和圖像分辨率選擇。如果目標框的像素范圍超過了網絡的感受野,就需要將原始圖像縮小后再檢測。
卷積網絡真的具有平移和旋轉不變性?
直覺上同一個卷積核,只要不是中心對稱的像素團,旋轉之后的卷積值肯定是不一樣的,也就是說卷積網絡顯然不具有旋轉不變性。那么卷積是否具有平移不變性呢?好像具有平移不變性啊,同一個像素團不管放在哪里,只要卷積核對齊了,卷積值都是一樣的。但是不要忘記了padding,每一層卷積都加padding的話,圖像邊緣的像素混入的padding影響肯定更大。對于卷積網絡來說,同一個像素團離圖像中心的距離不同卷積值肯定是不同的,所以加了padding的卷積網絡平移不變性也是不存在的。不帶padding的網絡每一層都必須進行嚴密的設計,就像不帶padding的UNet一樣的,顯然是很麻煩的。通常為了網絡設計的簡單,對訓練樣本做平移增廣是很有必要的。
可能有些人還記著以前關于CNN具有各種不變性的尬解釋,轉不過來彎的讀讀下面的論文,CNN啥不變性都沒得,就靠蠻力擬合大量得數據。
Making Convolutional Networks Shift-Invariant Again
SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep
Mind the Pad -- CNNs Can Develop Blind Spots
On Translation Invariance in CNNs: Convolutional Layers can Exploit Absolute Spatial Location
How much Position Information Do Convolutional Neural Networks Encode
Why do deep convolutional networks generalize so poorly to small image transformations
制作目標檢測訓練樣本的最佳方案是什么?
1.做感受野分析,確定能夠檢測目標邊長范圍
這一步得自己算。現成的網絡都能搜到別人算好的結果,拿來直接用。
2.用最終特征圖的尺寸反推訓練樣本圖像的尺寸
這一步也得自己算。有了目標邊長范圍,選擇大于目標框最大邊長2倍左右的訓練樣本圖像的尺寸。
3.對原始樣本圖像進行旋轉和成像效果變換增廣
這一步得寫代碼。目前廣泛使用的正框樣本庫,旋轉之后范圍框更加不準,沒得意義。如果自己要做樣本記得一定要用傾斜范圍框去標注,這樣才能做旋轉樣本增廣,從傾斜范圍框生成的正框準一些。旋轉增廣有現成的工具可以用,但是都是基于正框實現的,這里有一個基于python和opencv實現的(https://github.com/XuelianZ/augment)。
成像效果變換樣本指,通過直方圖匹配等算法,仿真夜晚、霧、雨、雪等天氣情況的成像效果。
為什么這兩種增廣放到切圖之前?對于成像效果變換來說需要的統計信息越準確越好,切成小圖之后難以得到較好的算法效果。對于旋轉來說,切完圖進行旋轉,必然要填充值。填充值屬于人為制造的偽顯著區域,不符合檢測時的實際情況。
4.對原始樣本圖像進行切圖,切圖的同時可以做平移樣本增廣
這一步還得寫代碼。已經有的工具很多都是簡單的切圖,只能支持0-255的普通數碼照片,也沒有考慮到能夠檢測的目標邊長范圍。如果有超過能夠檢測的目標邊長范圍的范圍框,需要對圖像進行縮小,且要將這個縮小比率記錄下來。檢測目錄時也要按這個縮放比率進行檢測。對于醫學圖像、遙感圖像在切圖過程中需要進行歸一化處理。歸一化參數需要從原始大樣本圖像上計算出來,切完的小圖的統計信息不夠全面,歸一化參數可能不夠好。
5.其它樣本增廣操作
比如翻轉、加噪、拼接、摳洞、縮放等等,這些操作可以在訓練過程中隨機執行。個人認為拼接、摳洞、縮放對工程應用來說沒有意義。拼接增廣指隨機找幾張圖各取一部分或者縮小之后拼起來作為一幅圖用,拼接出來的圖有強烈的拼接痕。摳洞指隨機的將目標的一部分區域扣掉填充0值。拼接、摳洞屬于人為制造的偽顯著區域,不符合實際情況,白白增加訓練量。
拼接的一個作用是增加了小目標樣本的數量,其實平移增廣也可以增加小目標樣本的數量。因為小目標可以在圖像范圍內平移的次數更多。
訓練過程隨機縮放也是沒必要的,縮放之后的圖像可能會導致特征圖和輸入圖像映射錯位(參考“樣本圖像的尺寸僅與內存、顯存大小有關嗎?”);另外工程應用過程中控制好成像距離就能控制目標尺寸范圍。僅采集符合所設計目標尺寸范圍的樣本圖像即可。
強烈推薦的訓練樣本圖像制作工具(切圖工具)
這套工具在切圖過程中實現了兩種歸一化方案和平移增廣,輸出圖像可以選擇輸出為0-1或者0-255,輸出到0-255的圖像可以用普通看圖工具查看。輸出到0-1的圖像數值精度高一些,可能訓練效果會好一些。對于普通數碼照片,因為原來取值范圍就是0-255,僅以0和255作為最小最大值做個線性映射,不會選取新的最小最大值。這套工具還包含一個統計范圍框寬高范圍并確定切圖縮放比率的工具。
這套工具僅支持yolo格式的范圍框標注,范圍框坐標可以是歸一化的也可以是不歸一化的。建議做樣本時不要歸一化坐標,整數的坐標值還是更準一些,可以利于其它處理。
(一)范圍框寬高統計工具
是命令行工具,有6個參數,參數之間用空格分開。
輸入目錄 范圍框標注格式 c,cx,cy,w,h
輸出目錄
輸入文件擴展名,多個擴展名用半角逗號分隔
輸入影像的比例尺,0表示從影像中讀取,沒有空間參考的影像的比例尺默認為1,普通照片就是沒有空間參考的,遙感影像才有空間參考
輸出樣本圖片邊長
裁剪出的樣本圖片上的目標框邊長范圍,有四個值半角逗號分隔,頭兩個是“按照所需縮放比例縮放之后最佳目標框邊長的范圍”,后兩個是“按照所需縮放比例縮放之后有效目標框邊長的范圍”
“最佳目標框邊長的范圍”指需要對圖像進行縮放,讓所有的范圍框的邊長都能落入這個范圍。“有效目標框邊長的范圍”指按照某個比例縮放后,還是有目標框不能落在最佳范圍,但是只要在有效范圍內就保留。
下面是一個運行示例,路徑參數中有空格需要用半角引號包起來。
sidelen_cwh.exe"D:DOTAv1.5trainimagesimages"D:Testpng,jpg057621,405,10,567
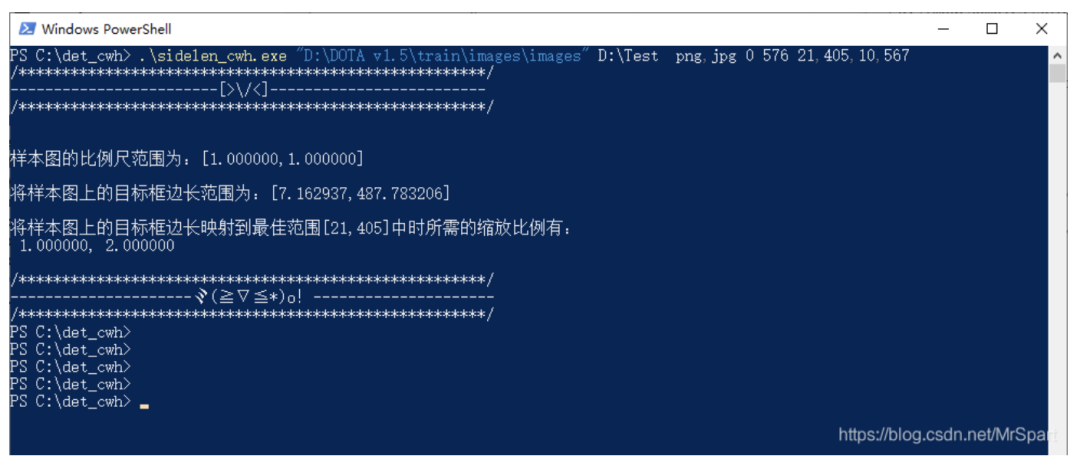
這個工具會輸出一個文本文件STATS.txt。其中內容為
1.000000,2.0000001.000000,1.0000007.162937,487.783206
這里為了兼容遙感影像,引入了比例尺的概率。第一行縮放比例是一個像素對應的地理長度,普通數碼照片的比例尺默認為1,還有一個為2的縮放比例,意思是將圖像寬高都縮小為原來的二分之一。第二行是所有圖像的原始比例尺范圍,因為沒有空間參考,所以比例尺都是1。第三行是范圍框邊長的范圍,以地理長度為單位的,如果沒有空間參考也就是像素單位。
從中可以看出DOTA數據集范圍框邊長的最大值有488,對于yolov3的感受野來說不能全都檢測出來,除了在原始比例尺檢測外,還得在縮小后的圖像上檢測。當然訓練也是一樣的需要在多個比例尺上進行。
(二)訓練樣本裁剪工具
也是命令行工具,有12個參數,參數之間用空格分開。
輸入目錄 范圍框標注格式 c,cx,cy,w,h
輸出目錄
輸入文件擴展名,多個擴展名用半角逗號分隔
輸入影像的比例尺,0表示從影像中讀取,沒有空間參考的影像的比例尺默認為1,普通照片就是沒有空間參考的,遙感影像才有空間參考
輸出樣本的比例尺,也就是縮放比例,多個值用半角逗號分隔。采用范圍框寬高統計工具輸出文件的第一行。
輸出樣本圖像的通道組合,將原始樣本圖像的多個通道按順序輸出,通道編號從1開始
歸一化映射參數,有mg、mo、sg、so四種方式,其后跟的數值是相應方式的歸一化參數。m表示最大最小值拉伸,其后的數值表示像元數目截斷的百分比;s表示均值加減標準差拉伸,其后的數值表示標準差的倍數;g表示拉伸到0-255,如果本來就是8位的則不拉伸;o表示拉伸到0-1,如果本來就是8位的則直接將0-255映射到0-1。
輸出樣本圖片邊長
裁剪出的樣本圖片上的目標框邊長范圍,與范圍框寬高統計工具一致。
進行樣本增廣時目標框平移的最小像素數量和平移量占范圍框寬高的比值,當比值乘以實際范圍框寬高小于最小平移量時仍然按最小平移量移動。
目標范圍框在裁剪圖像范圍內的部分占比的閾值,超過這個值才保留。切圖之后范圍框跑到圖像外了,需要排除。
目標框寬高聚類數目。
下面是一個運行示例,路徑參數中有空格需要用半角引號包起來。
splitimg_cwh.exe"D:DOTAv1.5trainimagesimages"D:Testpng,jpg011,2,3sg2.557621,405,10,567237,0.650.679
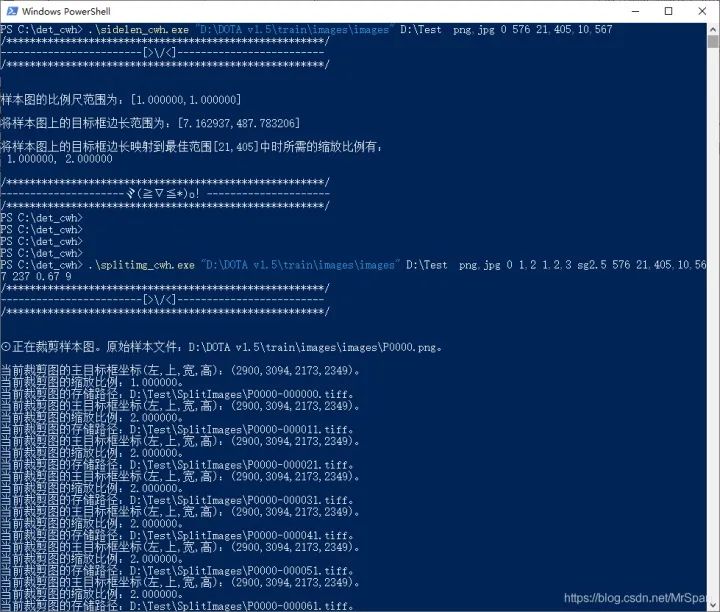
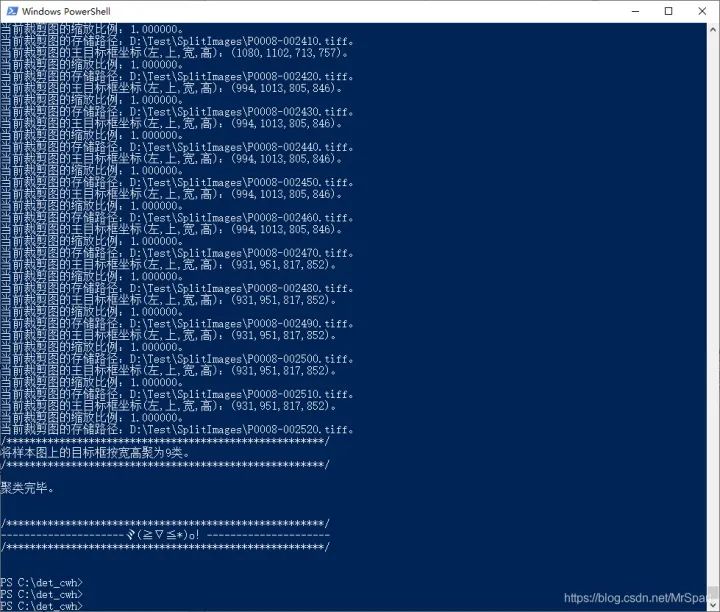
這個工具除了輸出裁剪出來的樣本外,還會輸出一個文本文件ANCHORS.txt和一個圖像HIST.tif。
ANCHORS.txt其中內容為
20,20,57,45,104,78,150,139,169,179,25,89,30,169,42,329,122,407這是范圍框寬高的聚類中心,可以直接用做yolo的錨點框。
HIST.tif是范圍框的二維統計直方圖,像素值累計了各個寬高的范圍框數量。利用范圍框的二維累計直方圖可以加快聚類。
裁剪出來的樣本圖像如下。
挑選了幾個方塊圖,把范圍框疊加顯示看看平移增廣的效果。
責任編輯:lq
-
傳感器
+關注
關注
2548文章
50740瀏覽量
752143 -
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
像素
+關注
關注
1文章
203瀏覽量
18562
原文標題:實操教程|怎樣制作目標檢測的訓練樣本圖像?
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
圖像分割與目標檢測的區別是什么
目標檢測與圖像識別的區別在哪
目標檢測與識別技術有哪些
目標檢測與識別技術的關系是什么
目標檢測識別主要應用于哪些方面
圖像檢測和圖像識別的原理、方法及應用場景
圖像檢測和圖像識別的區別是什么

如何使用Python進行圖像識別的自動學習自動訓練?
大模型訓練loss突刺原因和解決辦法
【飛騰派4G版免費試用】第三章:抓取圖像,手動標注并完成自定義目標檢測模型訓練和測試
【飛騰派4G版免費試用】 第二章:在PC端使用 TensorFlow2 訓練目標檢測模型
圖像處理算法——邊緣檢測





 工商網監
工商網監
評論