 我們在如何基于深度學習做實時噪聲抑制
我們在如何基于深度學習做實時噪聲抑制
在實時通訊技術迅猛發展的今天,人們對通話時的降噪要求也不斷提高。深度學習也被應用于實時的噪聲抑制。本次LiveVideoStackCon 2021 上海站中,我們邀請到了聲網Agora音頻算法負責人馮建元老師為我們分享深度學習落地移動端的范例,遇到的問題和未來的展望。
今天給大家介紹一下我們在如何基于深度學習做實時噪聲抑制,這也是一個深度學習落地移動端的范例。 我們就按照這樣一個順序來進行介紹。首先噪聲其實是有一些不同的種類,它們是如何進行分類的,如何選擇算法并怎樣通過算法去解決這些噪聲的問題;另外,會介紹如何通過深度學習的方式去設計一些這樣的網絡,如何通過AI的模型去進行算法的設計;
另外,我們都知道深度學習網絡的算力,模型不可避免的都會比較大。我們在落地一些RTC的場景時,不可避免會遇到一些問題,有哪些問題是需要我們解決的,如何解決模型大小的問題、算力的問題;最后會介紹目前降噪能達到什么樣的效果和一些應用的場景,以及如何能將噪聲抑制等做得更好。
01.噪聲的分類與降噪算法的選擇
先了解下我們平時的噪聲都有哪些種類。

其實噪聲不可避免的會跟著你所處的環境,所面臨的物體都會發出各種各樣的聲音。其實每一個聲音都有自己的意義,但如果你在進行實時溝通時,只有人聲是有意義的,那其他聲音你可能會把它認為是噪音。其實很多噪聲是一個穩態的噪聲,或者說平穩的噪聲。比如說我這種錄制的時候可能會有一些底噪,你現在可能聽不到。
比如說空調運行時會有一些呼呼的風聲。像這些噪聲都是一些平穩的噪聲,它不會隨著時間變化而去變化。這種可以通過我知道這個噪聲之前是什么樣的,我把它estimate出來,就通過這樣的方式,在之后如果這個噪聲一直出現就可以通過很簡單的減法的方式把它去掉。像這種平穩的噪聲其實很常見,但其實不是都那么平穩,都能那么方便的去去除。
另外,還有很多噪聲是不平穩的,你不能預測這個房間里會不會有人突然手機鈴聲響起來了;突然有人在旁邊放了一段音樂或者在地鐵、在馬路上車子呼嘯而過的聲音。這種聲音都是隨機出現的,是不可能通過預測的方式去解決的。其實這塊也是我們會用深度學習的原因,像傳統的算法對于非穩態的噪聲會難以消除和抑制。
在使用場景上來說,就算你是很安靜的會議室或者在家,可能也不可避免的會被設備引入的一些底噪或一些突發的噪聲都會產生一些影響。這一塊也是在實時通訊中不可避免的一道前處理的工序。
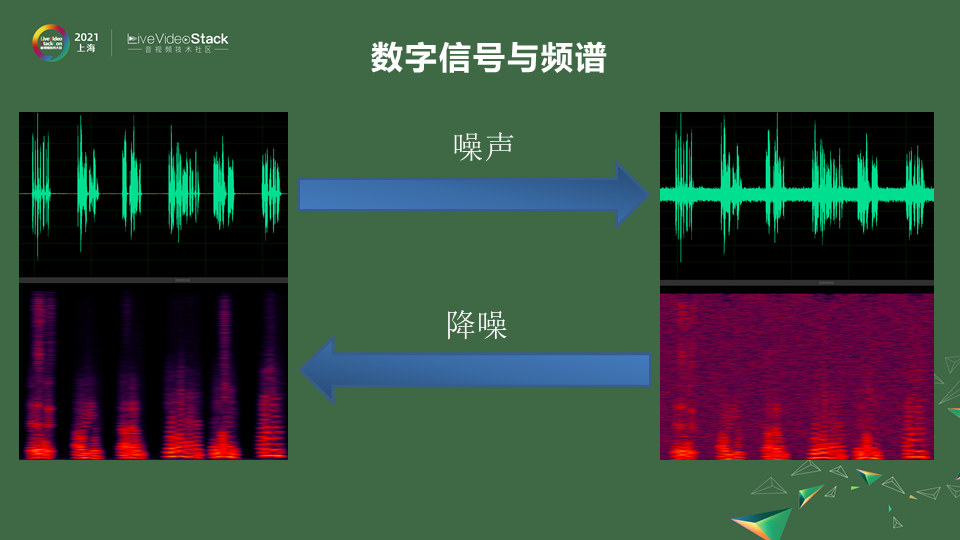
拋開我們平時會碰到的這些噪聲在感官上的理解。看到它在數字方面,在信號層面是一個怎么樣的表現。噪聲,聲音都是通過空氣的傳播介質的傳播最后到你耳朵里,通過你耳毛的感應,最后形成心里的感知。在這些過程中,比如我們采用一些麥克風的信號,在一些采集的時候它是一個wave的信號。
它是一些上下震蕩的一些波形。那如果是干凈的人聲,他說話的時候會看到一些波形,他不說話的時候基本就是0,那如果加上一些噪聲它就會變成右邊一樣,會有波形上的一些混疊,噪聲的震動會和人聲的震動混疊在一起,會有一些模糊不清。即使不在說話也會有一些波形。這是直接從wave信號的層面,如果說把它通過傅里葉變換,變到頻域上來看,在不同的頻率上,人聲的發音一般在20赫茲到2k赫茲之間,人還會有基頻、振峰、諧波的產生。
你可以看到人在頻譜上是這樣一些形狀,但是你加上噪聲會發現頻譜變得模糊不清,頻譜不該出現能量的地方有很多能量。
做噪聲抑制其實就是做一個inverse,一個反向的過程。把這些時域的信號通過一些濾波的方式變成一個純凈的信號。也可以通過頻域的方式把這些嘈雜的噪點去掉,形成一些比較純凈的語料。
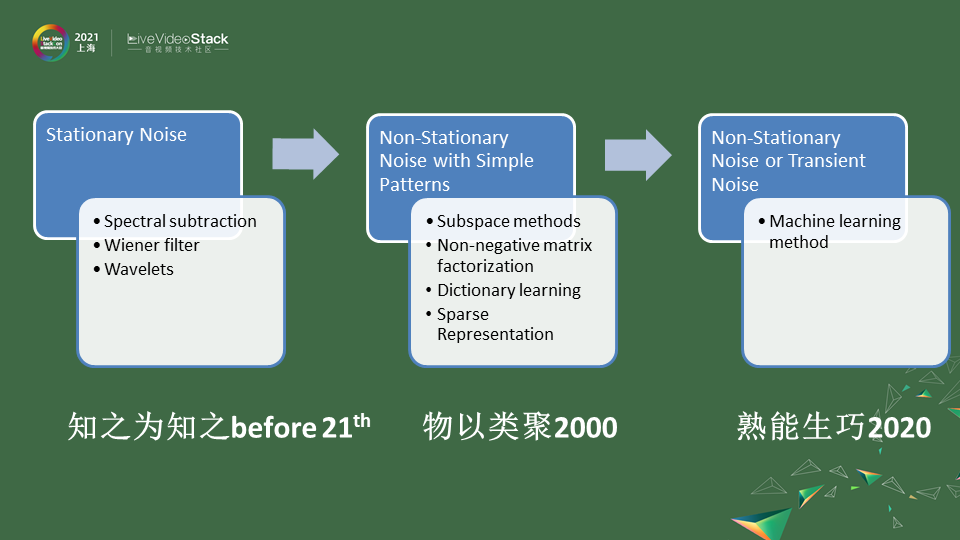
降噪這種算法很早之前就有了,在貝爾實驗室發明電話的時候就發現噪聲會有很大的通信的影響。不同的信噪比會導致由于香農定理影響你的帶寬,你是一個純凈的信號甚至可以用比較小的帶寬進行一個傳輸。在2000年之前我們可以把這些算法統稱為,知之為知之。 第一塊,它們主要針對比較穩態的噪聲就是Stationary Noise,為什么叫知之為知之呢,就是你不再說話沒有人聲的時候就只有噪聲,另外你去通過靜音段噪聲的捕捉去構建出噪聲的一些分布。
因為它是穩態的噪聲,它隨著時間的變化也沒有那么劇烈,以后就算是有人聲了,你也可以通過你estimate好的模型去進行一些譜減或者是維納濾波的方式解決。像這種Stationary Noise是因為一開始我們的元器件有很多底噪,所以他們第一個會干掉這種Stationary Noise的噪聲。其實方法來說就是一些譜減法、維納濾波,后來可能有高級一點波差、小波分解,這些方法都萬變不離其宗,它會通過靜音段estimate它的這樣的noise,在以后的過程中就可以通過一些譜減的方法來解決。
慢慢大家會發現除了Stationary Noise其實平時通話中想要只保有人聲,其他的噪聲也要處理,這塊到了2000年之后我們會說,因為其實人的聲音的分布和風的聲音的分布是不一樣的,有些風聲經過麥克風的,比如我這樣吹的,低頻部分可能會高一些,高頻部分可能衰減的更快。其實都是通過聚類的方式可以把人聲和噪聲分解開來,主要的思想都是把聲音的信號投射到更高維的空間進行聚類,聚類的方式就會有些自適應的方法慢慢可以去使用,也類似于深度學習的前身,會把聲音分成不同的種類,在高維空間進行降噪時把符合人聲的特點保留下來,其他部分舍去就可以做到。
這塊方法來說比如Subspace 空間分解,在圖像領域大獲成功,在音頻領域去風噪也比較好的非負矩陣分解。再比如說不止一種噪聲,要分解出好多種噪聲,像字典學習這種方式也是可以做的。 像常見的一種噪聲我們把它叫Non-Stationary Noise with Simple Patterns,是不穩定的噪聲,像呼呼的風聲,但它可能有固定的模式。
比如呼呼的風聲有時出現有時沒有出現,但它是遵循風的低頻比較密集等等這種特征。其中是可以通過一個一個去學習,比如風聲、雷電的聲音、底噪的聲音等等,可以通過學習的方式去實現。現在我們發現,物以類聚的話,噪聲的種類是無窮無盡的,每一種機械每一種摩擦每一種風吹過的聲音導致的渦流可能都是不一樣的。
在這種情況下很多噪聲混疊我們無法去窮盡,這時候我們就想到通過大量數據去訓練一個模型,這樣采集到的噪聲也好人聲的混加也好,能過通過不斷的去學習,我們叫它熟能生巧2020。通過訓練的方式,通過大量的數據樣本,能讓模型學到足夠的知識,對噪聲更加魯棒,不用一個一個去做分解。 按照這樣的思路,已經有很多深度學習的模型可以做到這樣噪聲的抑制,同時保證它對不同的噪聲都有抑制效果。
很多噪聲不是單一存在的,尤其是一些復合的噪聲。比如你在一個咖啡館里可能會聽到那些觥籌交錯的聲音混雜著各種人在聊天談話的聲音。我們把背景的人聲叫Babble noise,Babble就是呢喃的聲音,這種背景的噪聲你也是想去掉的。多個聲音混雜在一起你就會發現它的頻譜就像洪水過路一般所有東西都混雜在里面,會很難去去除。
如果你用傳統的算法,它把明顯的人聲會保留,比較高頻的混疊會更加嚴重,其實很難去區分開,它把在4k以上的高頻統一當成噪聲去除掉了。這是傳統降噪方法的一些缺陷。 像深度學習的方法,判斷一個降噪方法的好壞主要是兩點: 第一點,對原聲人聲的保留程度是怎么樣的,是不是對語譜的損傷盡量的小。 第二點,把噪聲去得盡量的干凈。 滿足這兩點,右邊是深度學習的方法,語譜在高頻也可以得到保留,同時噪聲也沒有混雜在其間。
02.基于深度學習的算法設計
現在針對深度學習方法怎樣去設計。
和其他深度學習一樣也會包括這幾個步驟。
第一步,喂給模型什么樣的輸入,輸入可以去進行選擇,我們的聲波信號可以通過wave的形式通過頻譜的形式或者是更加高維的MFCC的形式甚至心理聽閾BARK域的形式去給到它。不同的輸入決定了你的模型采用的結構也不一樣。在模型結構上,可能會選擇類似圖像的,如果是頻譜可能類似CNN的方法去做。聲音是有一定時間連續性的,你也可以通過waveform直接去做。
這塊選擇不同的模型結構,但是我們發現在移動端的時候,也會受到算力和存儲空間的限制,可能會對模型進行一些組合,不是用單一的模型去做。在模型的選擇這塊會有所考量,另外一塊也會比較重要就是選擇一個合適的數據去訓練模型 。
訓練模型的過程比較簡單,就是把人聲信號和噪聲信號混在一起喂到程序里,這樣模型會給你一個純凈的人聲信號。這時就會選擇我這個數據是不是為了cover所有不同的語言,上一個會議上也提到不同的語言組成的因素也是不一樣的,比如中文會比日文多五六個音素,如果是英文還有五六個音素和中文是不一樣的,為了cover住這些的語言可能會選擇多語言的數據。
另外一塊性別也是不一樣的,如果語料訓練不夠均衡,對男聲和女聲的降噪能力可能有所偏差。另外噪聲上的類型可能會有一些選擇上的考慮,因為不可能把所有噪聲都窮盡,所以會選擇一些typical noise。這邊大概羅列出來,不同Feature 的選擇,模型的設計,以及數據的準備回來看看要注意哪些方向。
我們先看一下我們會選擇什么樣的數據給到模型。 第一個考慮的是把最原始的wave信號做一個端到端的處理生存一個wave信號。這個想法一開始的時候是被否定的,因為wave信號和它的采樣率有關,可能16K的采樣率1幀10毫秒會有160個點,數據量非常龐大如果直接喂的話可能導致模型處理需要很大一個模型才能handle。
我們在之前就在想能不能轉化成頻域,在頻域上做能減少數據的輸入。在17、18年之前都是在頻域上去做這個事情,但是在2018年像Tasnet模型已經能通過時域端到端的去生成降噪的一個效果。 頻域可能會更早一些,之前在頻域上做噪點的去除,通過掩碼的形式去解決噪聲的問題。比如把噪聲的能量去除掉只保留人聲的能量。
19年有一篇paper做了一個比較,無論從時域還是頻域都可以得到一個比較好的降噪效果,而且模型計算復雜度不是相當的。
這個輸入信號不會很大程度上決定你模型的算力或者效果,就是可以的。 在這個基礎上,時域頻域都是可以的話,我們想要進一步減少模型的算力可能需要選用一些高維度像MFCC這種形式去做,這塊也是一開始設計模型考量的地方。根據算力限制,本來200多個頻點到MFCC只有40個bin,這樣就可以減少輸入。因為聲音存在一些遮蔽效應你可能把它分成一些足夠細小的子帶就能做到噪聲抑制的作用,所以也是行之有效能減少模型算力的方法。
剛剛是講到信號的輸入,在做模型結構選擇的時候也會有很多對模型結構算力的考量,可以把模型算力的復雜度和模型參數量畫一個XY軸去表正。像一些CNN方法,因為是卷積的存在,里面很多算子是可以復用的,卷積核可以在整個頻譜上復用。這種情況下,在同樣參數結構中它的算力復雜度會最高,因為它是復用的它的參數量就很小。
如果一些手機APP對參數量有限制,比如手機APP不能大于200M可能模型給你的空間就1-2兆,這種情況下盡量選擇CNN模型。 參數量并不是一個很大的限制而運算力可能會受到一些挑戰,比如一個算力較差的芯片,只有1GHz。這時卷積神經網絡的方式并不是適合的,這時可能是用一些linear 這種層來表征,所以linear 也是矩陣乘。
矩陣乘在一些DSP芯片和傳統CPU方面表現的算力都不是很高,缺點是每個算子是不可復用的。這種情況下參數量比較大,但計算力上可能會更加的小。但只用linear這種方式就像DNN一樣只有linear 層,就是它參數很大算力也很大。 前面提到人的說話時間是有連續性的,可以用RNN這種有短時或長時記憶的這種方式,把參數通過實時的自適應去記憶出當前噪聲的狀態,這樣可以進一步減少它的算力。
綜合下來說,當你選擇模型時盡量少去使用linear layers,這種會帶來很大參數量的提升和算力的提升。你可以去融合這些不同的結構,比如先用CNN再用RNN這種CRN的形式,那它第一步通過壓縮你輸入的維度,再通過長短時記憶的方式,把模型算力進一步的減少。 根據不同場景,如果做離線的處理,可能使用雙向的人工神經網絡去做效果可能是最好的。在RTC場景中不能去增加延遲。像LSTM這種單向型的網絡可能更加合適。如果想進一步減少算力,三個門的LSTM還是太大那就用兩個門結構的GRU等等,在一些細節上提升算法的能力。

怎么選擇模型結構和使用場景和算力有關。另外一塊就是怎么選擇喂到模型的數據。數據里面一塊是語譜的損傷,要準備更充分干凈的語料,里面包括不同的語言、性別,以及語料本身可能含有底噪,盡量選擇錄音棚消音室錄的比較純凈的語料。這樣你的reference決定了你的目標可能是比較純凈的,效果會更好一些。
還有一塊是能不能cover住噪聲,噪聲是無窮無盡的,可以根據你的場景,比如會議場景選擇一些比較典型的辦公室里的人聲、手機提示音等等,這些作為訓練語料。其實很多噪聲是簡單噪聲的一些組合,當簡單噪聲數量足夠多的時,模型的魯棒性也會提升,哪怕是一些沒有見過的噪聲也能cover。噪聲有時不能收集的話可以自己做一些,人工合成一些,比如日光燈管、輝光效應造成的雜音、50赫茲的交流電時時刻刻都在釋放50赫茲、100赫茲的諧波的噪聲。這種噪聲可以通過人造的方法去加入訓練集里面提升模型的魯棒性。
03.RTC移動端困境
假設我們已經有一個比較好的模型了,在落地時會遇到哪些困難呢?

在實時互動的場景中,首先它有別于離線的操作,對實時性的要求更高,它要求逐幀計算,非因果不可用,未來的信息是無法去獲得的,這樣的場景下一些雙向的神經網絡不可用。 另外要去適配不同的手機、不同的移動終端,這里面受到各種芯片算力的影響,如果想使用更加廣泛模型算力會有限制同時模型參數大小也不能過大,尤其是調用芯片是模型參數量很大算力不是很高,但是由于參數的讀取IO的操作也會影響到模型最終表現。
場景的豐富性剛才也有提到,一些比較成功的,不同語音比如中英文、日文的cover程度以及噪聲的類型。在實時互動場景中不可能讓每一個人都在同一個場景說同樣的話,場景的豐富性也要考慮其中。
04.如何落地移動端
在這樣一些條件下,如何去落地深度學習呢?我們可以從兩個方面去解決這些問題。
首先,算法方面可以通過算法突圍的方式。剛剛有提到一點,像全卷積的、全linear的,對它的參數對它的算力都有不同,可以通過不同模型的組合,針對不同算力可以組合出不同算力的結構。效果來說可能會有一些偏頗差異,什么樣的機型能適用什么樣的算法,可以通過這樣的模型結構來解決,整體來說是一個組合式的算法,通過模型組合使它的算力能盡量滿足它的芯片和存儲空間的要求。
第二,整個算法的場景是不一樣的,所以會選擇不一樣的模型去解決,在一開始如果能夠選擇出場景,比如會議場景,不可能會有音樂、動物的叫聲,這些噪聲指標就不用特別關注,這些東西可以作為模型裁剪的方向。
算法本身可能模型就是這么大,出來還是一個5-6兆的參數,你可能覺得它還是不夠。或者說它的算力在移動端不進行優化,它在內存的調用,芯片存儲cache的方面可能都會有問題。會影響到它在推理過程中,實際使用過程中的結果,明明在訓練時跑的是ok的,但在落地不同芯片時跑的是不一樣的。
在工程上也會進行突圍,主要針對模型推理以及一些處理的方式會有所不一樣。首先在模型方面會做一些算子的優化,在訓練搭建模型的時候都是一層層加上去的,但很多算子可以進行一些融合,包括算子融合、凸優化。一些參數做模型的剪枝、量化,這些都是可以進一步減少模型的算力以及參數量的大小。
第一步就是對模型進行一些裁剪量化,這一塊已經能做到讓你的模型是最優的最符合場景的。另外在不同的移動終端它的芯片也是不一樣的,有些手機可能只有CPU有些好點的手機會有GPU NPU甚至會有的DSP芯片甚至能開放它的算力。 這塊我們能更好的去適應芯片,會有一些不同的推理框架,各家都會有一些比較開源的框架可以去使用,比如蘋果的Core ML、谷歌的TensorFlow Lite,它會把芯片調度編譯層的優化做在里面。
在這步上來說,做和不做差異是非常巨大的,因為整個算法怎么運算是一回事,怎么做內存調用、矩陣的計算、浮點計算還是另一回事。做工程化的優化,這種效果可能是百倍的提升。優化可以用開源的框架去做,也可以自己做一些編譯的優化,如果你對芯片的算力比較熟悉,比如不同的cache的怎么調用,它的大小是什么,你可以自己去做。可能你做出來的結果比這種開源的框架更有針對性,效果會更好。 在我們把模型和推理引擎整合起來之后,就是我們最后的產品,我們幾乎能在所有的終端做好適配,在所有芯片上完整工程化的一個產品,這樣能實時使用。
05.降噪demo試聽
我們現在聽一聽降噪效果是什么樣的。
這邊羅列了幾種比較常見的噪聲。
我們先聽鍵盤上的原聲,再聽鍵盤降噪的效果。鍵盤聲基本上都已經被消除掉了。
風聲我們來聽是這樣子的,這是一段德語在風聲中的演講。來我們聽聽降噪后的效果。
地鐵也是一個比較常見的場景,我們聽聽原聲,這其實是我在上海地鐵10號線在念一段詩。我們聽聽降噪的一個效果。
車內噪聲,比如出租車上的一個噪聲,我們聽一下。我們聽聽暈車大哥在降噪后的效果,這是我們實際在出租車上錄下來的一段語料,并將整個機器引擎的噪聲都把它去掉了。
06.Can we do it better?
聽完這些demo后,看看我們能做什么讓效果變得更好,場景變得更多一些呢?
我們還有很多難以解決的問題。包括一些音樂信息的保留,如果你是在一個音樂場景去開降噪,你會發現伴奏都沒有了只剩下人聲,這些場景可能會通過更精細化的方式,比如音源分離的方式,能不能把樂器的聲音也保留,但有些音樂聽上去像噪聲是比較難以解決的一個領域。另一塊像人聲、像Babble noise,背景的這種噪聲有時和人聲比較難以區別,尤其像雞尾酒效應,大家都在說話,通過AI判定哪個人說話是真正有效的是比較難。
噪聲抑制,比如說我們做的都是單通道的,采用一些麥克風陣列可能會做一些指向性的降噪,但這些也是一個比較難的地方,什么聲音值得保留,人聲和背景聲如何分辨這塊也是比較難的方向,這也是未來我們會去探索的一個比較明確的方向。
編輯:jq
-
噪聲
+關注
關注
13文章
1118瀏覽量
47369 -
RTC
+關注
關注
2文章
529瀏覽量
66318 -
通訊技術
+關注
關注
1文章
90瀏覽量
13906
原文標題:基于深度學習的實時噪聲抑制——深度學習落地移動端的范例
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用

FPGA做深度學習能走多遠?
深度學習算法在嵌入式平臺上的部署
開關電源的紋波噪聲如何抑制
BUCK電路EMI噪聲的有效抑制方法

如何抑制和減少電子噪聲影響?
FPGA在深度學習應用中或將取代GPU
什么是LDO?淺析低壓差穩壓器 (LDO) 中的噪聲及電源抑制比
升壓型DCDC轉換器高頻噪聲的抑制方法
GPU在深度學習中的應用與優勢






 工商網監
工商網監
評論