") 知識圖譜與BERT相結(jié)合助力語言模型
知識圖譜與BERT相結(jié)合助力語言模型
感謝清華大學(xué)自然語言處理實驗室對預(yù)訓(xùn)練語言模型架構(gòu)的梳理,我們將沿此脈絡(luò)前行,探索預(yù)訓(xùn)練語言模型的前沿技術(shù),紅框中為已介紹的文章,綠框中為本期介紹的模型,歡迎大家留言討論交流。
在之前的一期推送中,我們給大家介紹過百度的ERNIE。其實清華大學(xué)NLP實驗室,比百度更早一點,也發(fā)表了名為ERNIE的模型,即Enhanced Language Representation with Informative Entities。
他們認為現(xiàn)存的預(yù)訓(xùn)練語言模型很少會考慮與知識圖譜(Knowledge Graph: KG)相結(jié)合,但其實知識圖譜可以提供非常豐富的結(jié)構(gòu)化知識和常識以供更好的語言理解。他們覺得這其實是很有意義的,可以通過外部的知識來強化語言模型的表示能力。在這篇文章中,他們使用大規(guī)模語料的語言模型預(yù)訓(xùn)練與知識圖譜相結(jié)合,更好地利用語義,句法,知識等各方面的信息,推出了Enhanced language representation model(ERNIE),在許多知識驅(qū)動的任務(wù)上獲得了巨大提升,而且更適用于廣泛通用的NLP任務(wù)。
作者提出,要將知識嵌入到自然語言模型表達中去,有兩個關(guān)鍵的挑戰(zhàn):
知識的結(jié)構(gòu)化編碼
對于一個給定的文本,如何從知識圖譜中,高效地將和文本相關(guān)的常識或知識抽取出來并編碼是一個重要問題。
異構(gòu)信息融合
語言模型表示的形式和知識圖譜的表達形式是大不相同的,是兩個獨立的向量空間。怎么樣去設(shè)計一個獨特的訓(xùn)練任務(wù)來將,語義,句法,知識等信息融合起來是另一個挑戰(zhàn)。
針對這些挑戰(zhàn), 清華NLP實驗室提出方案是 Enhanced Language RepresentatioN with Informative Entities (ERNIE)
首先,通過識別文本中的命名實體,然后將其鏈指到知識圖譜中的相應(yīng)實體上,進行知識的抽取和編碼。相比于直接使用知識圖譜中基于圖結(jié)構(gòu)的信息,作者通過TranE這樣的知識嵌入算法,對知識圖譜的圖結(jié)構(gòu)實體進行編碼,然后將這富有信息的實體表示作為ERNIE的輸入,這樣就可以把知識模塊中的實體的信息表示,引入到模型下層的語義表示中去。
其次,和BERT類似,采用了MLM和NSP的預(yù)訓(xùn)練目標(biāo)。除此以外,為了更好地融合文本信息和知識信息,設(shè)計了一個新的預(yù)訓(xùn)練目標(biāo),通過隨機地mask一些命名實體,同時要求模型去知識圖譜中尋找合適的實體,來填充被mask掉的部分。這個訓(xùn)練目標(biāo)這樣做就可以要求語言模型,同時利用文本信息和知識圖譜來對token-entity進行預(yù)測,從而成為一個富有知識的語言表達模型。
本文在兩個知識驅(qū)動的NLP任務(wù)entity typing 和 relation classification進行了實驗,ENRIE在這兩個任務(wù)上的效果大幅超越BERT,因為其充分利用了語義,句法和知識信息。在其他的NLP任務(wù)上,ENRIE的效果也很不錯。
定義
首先,定義我們的文本token序列為{w1, 。 . 。 , wn},n為token序列的長度。同時,輸入的token可以在KG中對應(yīng)entity。所對應(yīng)entity的序列為{e1, 。 . 。 , em}, m是序列中entity的數(shù)量。因為不一定每一個token都對應(yīng)得到KG中的一個entity,所以在大多數(shù)情況下m不等于n。所有token的集合也就是字典為V,在KG中所有entity的列表為E。如果,某個在V中的token w ∈ V 在KG中有對應(yīng)的entity e ∈ E。那么這個對應(yīng)關(guān)系定義為f(w) = e
我們可以看下方的模型結(jié)構(gòu)圖,大概包括兩個模塊。
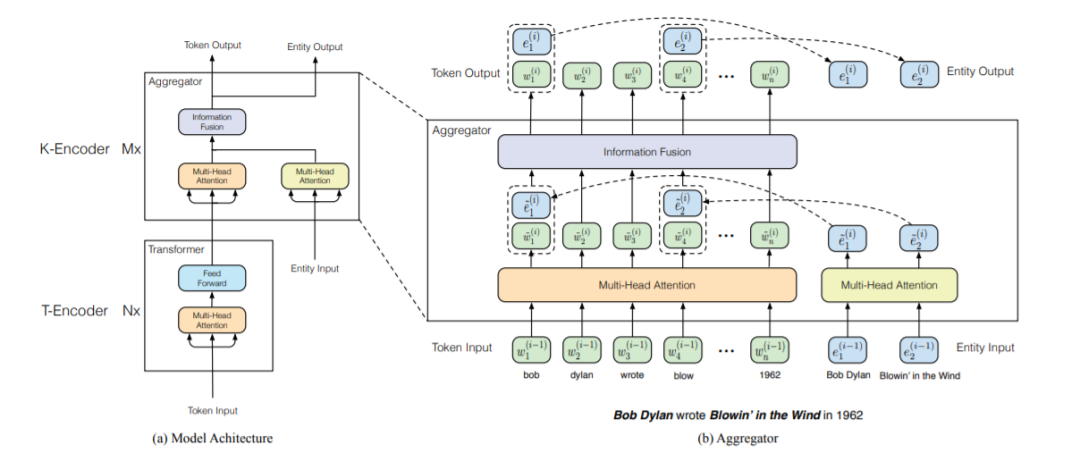
下層的文本編碼器(T-Encoder),負責(zé)捕捉基本的詞法和句法的信息,其與BERT的encoder實現(xiàn)是相同的,都是多層的Transformer,層數(shù)為N。
上方的知識編碼器(K-Encoder),負責(zé)將跟entity相關(guān)的知識信息融入到下方層傳來的文本編碼信息中,兩者可以在統(tǒng)一的特征空間中去表示。T-Encoder的輸出是{w1, 。 . 。 , wn},實體輸入通過TranE得到的知識嵌入為{e1, 。 . 。 , em}。兩者通過K-Encoder計算出對應(yīng)的特征以實現(xiàn)特定任務(wù)。
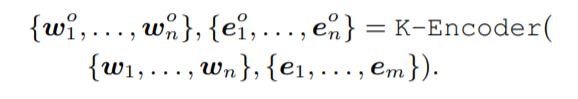
K-Encoder的結(jié)構(gòu)和BERT略微不同,包含M個stacked aggregators。首先對token的輸出和entity的embedding通過兩個多頭自注意力進行self attention。
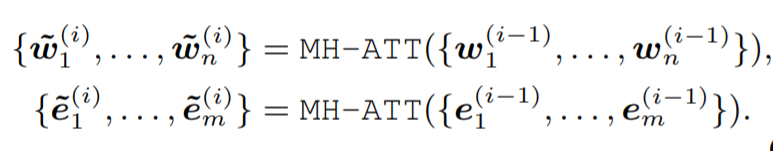
接著,通過以下的式子進行兩者的結(jié)合。Wt和We分別是token和Embedding的attention權(quán)重矩陣。
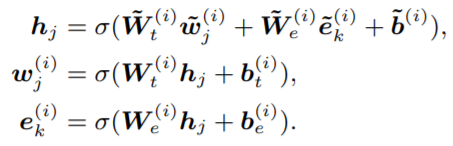
Pre-training for Injecting Knowledge
除了結(jié)構(gòu)的改變以外,文章提出了特殊的預(yù)訓(xùn)練語言模型訓(xùn)練目標(biāo)。通過隨機地mask一些entity然后要求模型通過知識圖譜中實體來進行選擇預(yù)測,起名為denoising entity auto-encoder(dEA)。由于知識圖譜中entity的數(shù)量規(guī)模相對softmax層太大了,會首先在KG中進行篩選找到相關(guān)的entity。有時候token和entity可能沒有正確的對應(yīng),就需要采取一些措施。
5%的情況下,會將token對應(yīng)的entity替換成一個隨機的entity,這是讓模型能夠在align錯的時候,能夠糾正過來。
15%的情況下,會將entity mask掉,糾正沒有把所有存在的entity抽取出來和entity進行對應(yīng)的問題。
其余的情況下,保持token-entity alignments 不變,來將entity的表示融合進token的表示,以獲得更好的語言理解能力。
Fine-tuning for Specific Tasks
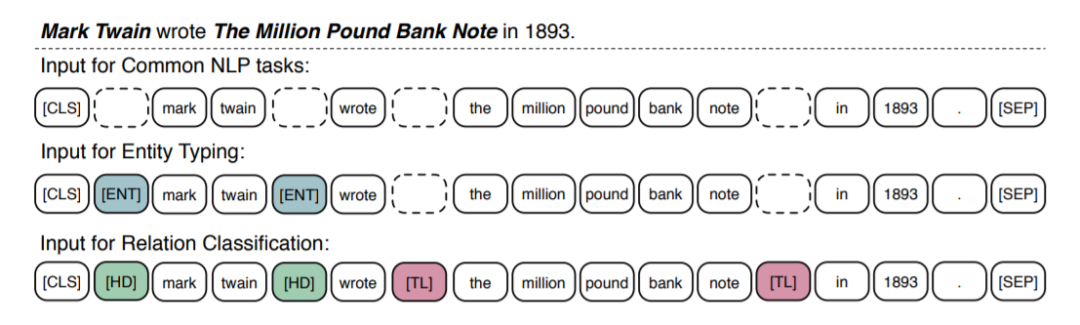
對于大量普通的NLP任務(wù)來說,ERNIE可以采取和BERT相似的finetune策略,將[CLS]的輸出作為輸入文本序列的表示。對于一些知識驅(qū)動的任務(wù),我們設(shè)計了特殊的finetune流程。
對于關(guān)系分類任務(wù),任務(wù)要求模型根據(jù)上下文,對給定的entity對的關(guān)系進行分類。本文設(shè)計了特殊的方法,通過加入兩種mark token來高亮實體。[HD] 表示head entity, [TL]表示tail entity。
對于實體類別分類任務(wù),finetune的方式是關(guān)系分類的簡化版,通過[ENT]標(biāo)示出entity的位置,指引模型同時結(jié)合上下文和實體的信息來進行判斷。
模型細節(jié)
從頭開始訓(xùn)ENRIE的代價太大了,所以模型用了BERT的參數(shù)初始化。利用英文WIKI作為語料,和WiKidata進行對應(yīng),語料中包含大約4500M個subwords,和140M個entities,將句中小于三個實體的樣本丟棄。通過TranE算法在WiKidata上訓(xùn)練entity的embedding。使用了部分WiKidata,其中包含5040986個實體和24267796個三元組。
模型尺度上來說,T-encoder的層數(shù)N為6,K-encoder層數(shù)M為6。隱藏層維度兩個網(wǎng)絡(luò)分別Hw = 768, He = 100。Attention的頭數(shù)分別 Aw = 12, Ae = 4。總參數(shù)量大約114M。
ERNIE僅在語料上訓(xùn)練了一輪,最大文本長度由于速度原因設(shè)為256,batch-size為512。除了學(xué)習(xí)率為5e-5,其他參數(shù)和BERT幾乎一樣。
實驗效果
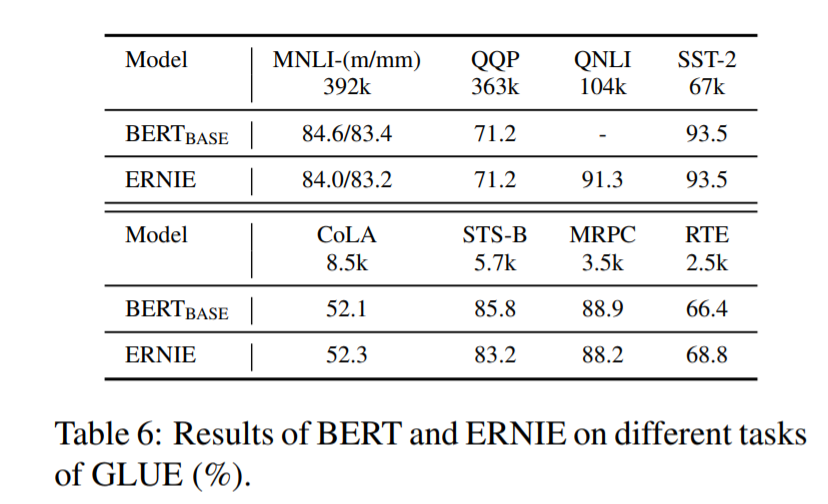
直接放圖吧,比當(dāng)時的state-of-the-art :BERT在很多任務(wù)上都提升了不少。
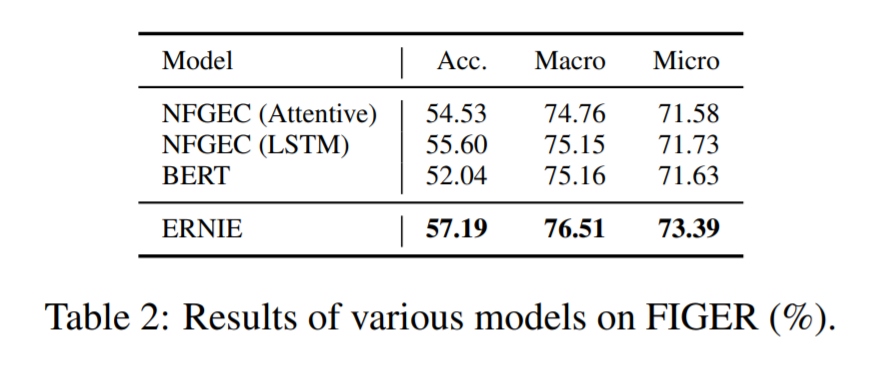
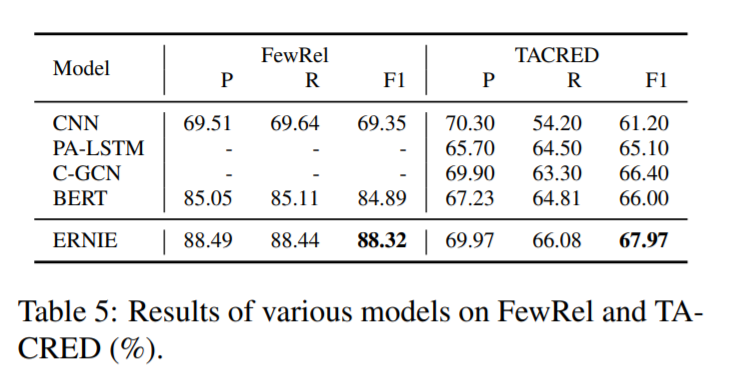
這里作者認識到,有了知識圖譜的介入,可以用更少的數(shù)據(jù)達到更好的效果。
結(jié)論
在文中提出了一種方法名為ERNIE,來將知識的信息融入到語言表達的模型中。具體地,提出了knowledgeable aggregator 和預(yù)訓(xùn)練任務(wù)dEA來更好地結(jié)合文本和知識圖譜兩個異構(gòu)的信息源。實驗表明,ENRIE能更好地在有限的數(shù)據(jù)上進行訓(xùn)練和泛化。
未來還有幾個重要的方向值得研究
將知識嵌入到基于特征的預(yù)訓(xùn)練語言模型如ELMo。
引入更多不同的結(jié)構(gòu)化知識進入到語言表達模型中去,比如ConceptNet,這和WiKidata是完全不同的方式。
進行真實世界更廣泛的語料收集,可以進行更通用和有效的預(yù)訓(xùn)練
編輯:jq
-
編碼器
+關(guān)注
關(guān)注
45文章
3601瀏覽量
134203 -
自然語言
+關(guān)注
關(guān)注
1文章
287瀏覽量
13334 -
nlp
+關(guān)注
關(guān)注
1文章
487瀏覽量
22015 -
知識圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7696
原文標(biāo)題:ENRIE:知識圖譜與BERT相結(jié)合,為語言模型賦能助力
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
三星自主研發(fā)知識圖譜技術(shù),強化Galaxy AI用戶體驗與數(shù)據(jù)安全
【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)知識學(xué)習(xí)
【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)篇
【《大語言模型應(yīng)用指南》閱讀體驗】+ 俯瞰全書
三星電子將收購英國知識圖譜技術(shù)初創(chuàng)企業(yè)
知識圖譜與大模型之間的關(guān)系
Al大模型機器人
【大語言模型:原理與工程實踐】大語言模型的應(yīng)用
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
利用知識圖譜與Llama-Index技術(shù)構(gòu)建大模型驅(qū)動的RAG系統(tǒng)(下)

知識圖譜基礎(chǔ)知識應(yīng)用和學(xué)術(shù)前沿趨勢
模型與人類的注意力視角下參數(shù)規(guī)模擴大與指令微調(diào)對模型語言理解的作用

大語言模型背后的Transformer,與CNN和RNN有何不同






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論