 探究學術界AV1編碼優化技術的進展
探究學術界AV1編碼優化技術的進展
學術界的一些優化工作實涵蓋了編碼過程的大部分模塊。很 明顯的趨勢就是許多深度學習的網絡或者方法已經開始與編碼的模塊進行結合,并取得了很多不錯的收益。本文將按照編碼過程的大致順序分享學術界AV1編碼優化技術的進展。
各位專家以及屏幕前的各位觀眾大家好!我是朱辰,目前是上海交通大學圖像所的在讀博士生。本次分享的主題是學術界AV1編碼優化技術的進展。
AV1編碼標準
首先介紹一下AV1編碼標準。AV1是由開放媒體聯盟AOM陣營提出的面向互聯網流媒體的開發編碼標準開放編碼標準。AOM是由谷歌主導,并且吸納了很多ICT領域的大廠加入,例如我們國內的騰訊還有愛奇藝都是聯盟成員。AOM建立的初衷是想解決專利問題,形成一些免費開源的編碼方案,同時性能超過HEVC。
AV1核心編碼工具
此處是對AV1新增的一些核心編碼工具進行了一些整理總結。首先,最大的編碼單元目前已經擴展到了128×128的大小;同時劃分模式是支持2等分和4等分。幀內預測方面,除了擴展了方向性的預測模式以外,還添加了比如交叉分量、遞歸濾波的預測模式。幀間預測方面是最多支持7個參考幀,同時支持仿射運動軌跡,混合預測模式等。
變換是支持包含DCT在內的4種模式。熵編碼使用的是一種多符號的上下文字適應的算術碼。環路濾波共支持區塊濾波,方向增強濾波,還有修復濾波,總共三種算子。最后特別的對于屏幕內容編碼,還涉及了一些例如調色板,塊匹配等技術。
AV1編解碼器
AV1在生態建設方面步伐非常快,現在可以看到已有三款開源的編碼器和一款開源的解碼器。另外我們也已經看到已經有三款商用的AV1編碼器。對于AV1性能,相比于HEVC標準下的x265, AV1的前身VP9,大概有20~30%的增益。在商業應用方面,從去年開始AV1已經開始有規模在一些比如瀏覽器端、安卓客戶端、OTT以及智能電視設備上得到支持和使用。
AV1優化技術工作
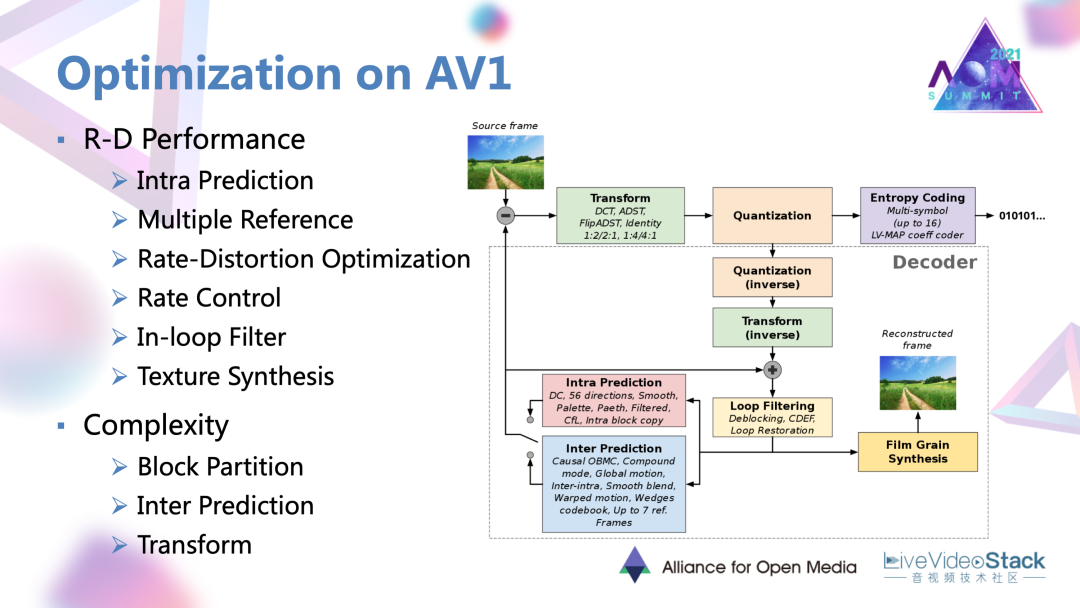
接下來是對AV1上的一些優化技術和優化工作進行一些介紹。因為現在我們的市場上的視頻應用種類是非常多的,例如點播、直播,互動類的場景。對于不同類的應用,實際上對編碼的需求也有一定差異。
對于AV1定稿的編碼標準而言,往往沒有辦法同時滿足這樣多方面的需求的。所以對標準編碼器還會衍生出很多方面的優化,含R-D性能、復雜度、延遲,一些硬件實現上的優化。對此整理了AV1定稿以后近兩三年在學術界或者說以論文形式發表的優化工作,發現目前主要就是集中在性能和復雜度優化方面。上圖中列出了優化方法的編碼模塊,實際上也可以看到其中的大部分編碼過程中的大部分模塊都已經有相應的優化路徑。
此次分享會按照編碼過程的大致順序,對各類工作進行一些介紹。
#1. 性能優化方面
1.1 幀內預測的優化

首先是性能優化方面的工作。其中首先是幀內預測的優化工作。AV1本身是有56個方向性模式,5個非方向的幀內模式。這個工作的出發點是發現相鄰塊的選擇的幀內模式往往是相同的或者是相近的,但目前的AV1里面還沒有應用到相鄰塊的模式信息。
此外,AV1幀內預測本身只用了一個相鄰的參考線中的中間塊作為參考,但當對于一些像紋理圖案這種相鄰樣本變化比較大的區域的時,如還是使用單一的參考線,可能會導致殘差較大、預測誤差較大的現象。所以針對這兩點,工作提出了自適應預測角度,非相鄰的參考線兩種方法。
1.1.1 自適應預測角度
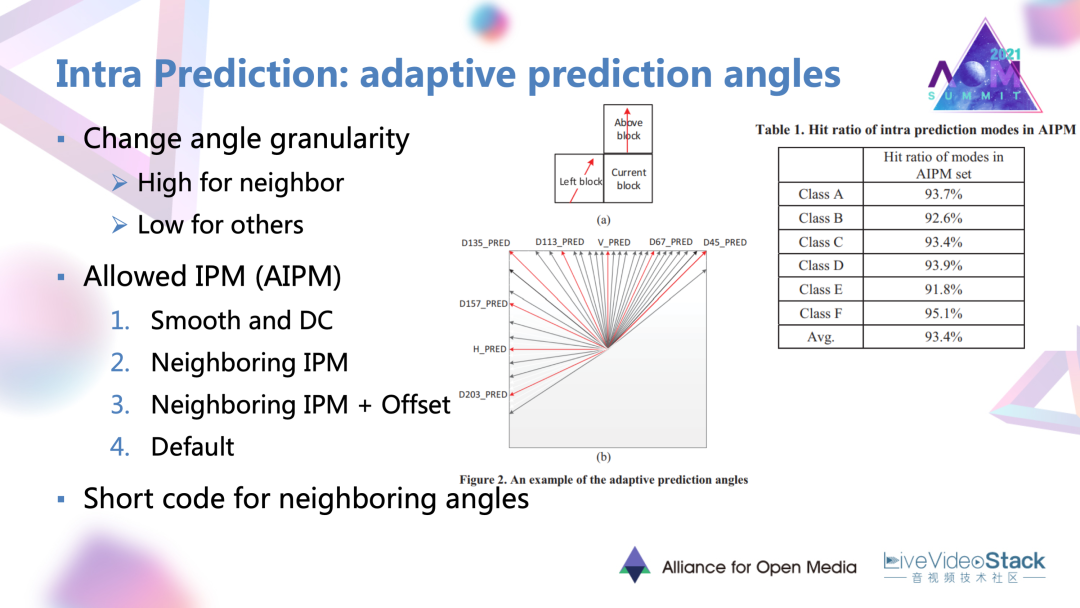
自適應預測角度,首先要做的是改變候選角度的一個粒度。意思是說根據剛剛說的相鄰塊的模式,往往會被當前塊選中。上圖中間圖中所示,對于相鄰塊方向的候選角度仍然保持一個細粒度。
其他方向的候選角度,可以用一個粗粒度去進行選擇。在此基礎上它提出了一個叫做“Allowed”,叫做允許的幀內測模式集合。最大數量有40個,意思就是將AV1原有大概60多個可能的幀內模式,按照一定的優先級順序去填滿 AIPM集合。
它的一個選擇順序:首先是非方向性的模式,這些模式的選中概率是最高的;然后是剛剛說的相鄰塊的方向性模式;其次是優先級,相鄰塊方向性模式加上一些細致度偏置以后的角度模式;最后當集合數量還沒填滿的時候,加入一些默認的模式進行填充。這個工作對這提出的集合進行了一個驗證;發現在CTC序列上的命中率可以有93%左右,是非常有效的一個方法。
文章還相應提出了說對相鄰塊的角度,用一個短碼進行編碼替代原來的相同碼上編碼,實現更優質的編碼。
1.1.2 自適應的非近鄰參考線
自適應的非近鄰參考線的概念比較易懂的。在原來只有單個參考線的基礎上,額外的添加了三個稍微相鄰的但是較遠的參考線,僅針對Y分量有效。但如果直接增加這樣幾條參考線,文章中也給出會增加成倍的編碼事,要進行一個復雜度和性能提升之間的權衡。它也利用了一些快速終止以及較遠參考線簡化候選模式,只保留方向性模式,去達到平衡。
1.1.3 幀內預測的結果
這樣的兩個方法最終取得了Y分量在兩個編碼模式里面2%的一個性能提升。
1.2 幀間預測的優化
1.2.1 針對于幀間預測的多層、多參考幀的框架
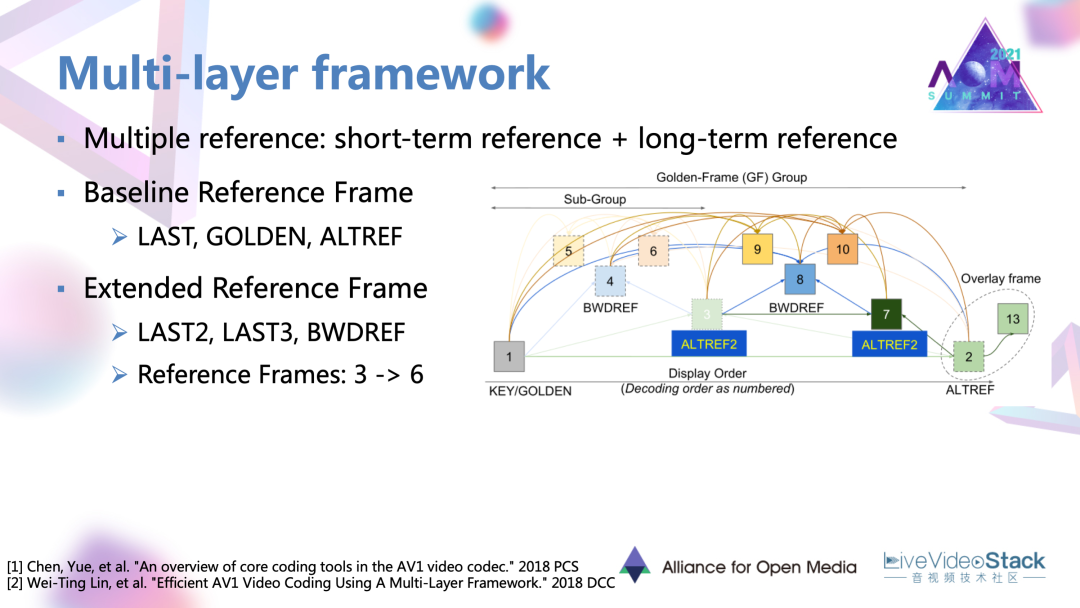
這個框架目前應用在 AV1官方編碼器Libaom中,用到短期參考和長期參考,多參考幀的概念去適應不同運動內容,不同運動特性,或者不同種類內容的視頻,去達到一個更好的幀間預測。
它以AV1前身VP9作為base line,VP9用到三種參考幀,一個是LAST就是緊鄰的前一幀,另一個是golden frame。一個起始的golden frame加上一定數量的幀,就可以形成一個golden frame group。另一幀叫做ALT幀參考幀,利用一些較遠的未來幀去通過時域濾波構建的,這個幀本身主要用于參考,是不用于具體的顯示的。
在一個golden frame group里會共用golden frame,還有 ALT幀。在此基礎上工作就擴展了候選幀的數量是添加了兩再添加了兩個緊鄰的過去幀,還添加了一個叫做“BWD”可以用于后項參考的參考幀。參考幀數量達到翻倍的效果。在目前的AV1版本里面,還會生成新的一幀,中間的ALT幀作為golden frame和原來的ALT參考幀的一個過渡的形態。所以可以總共有七幀參考。
1.2.2 選候參考幀集合后編碼增益情況
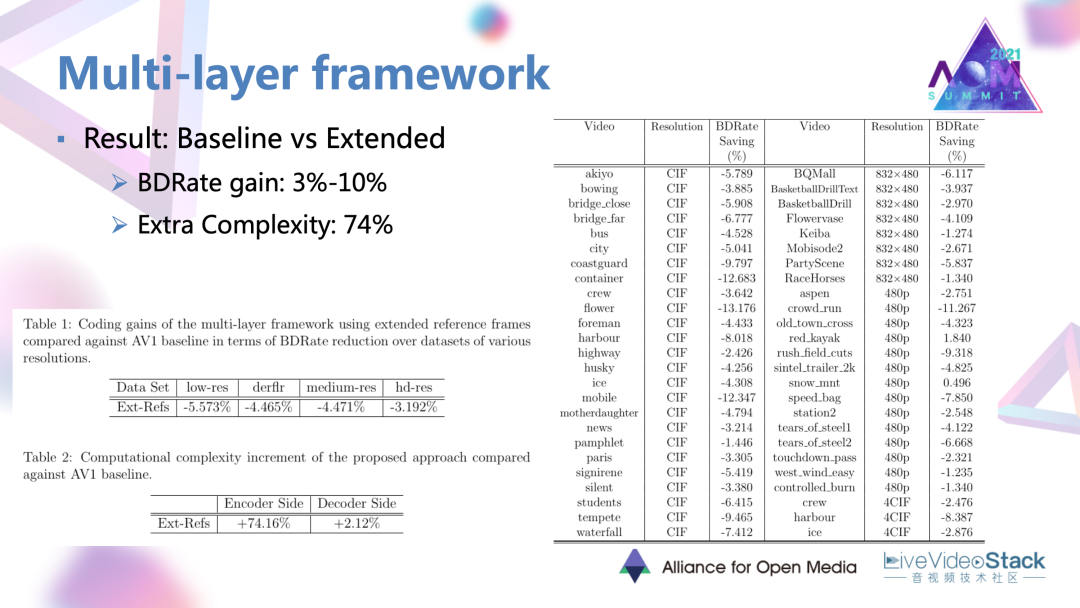
有這樣一個很豐富的選候參考幀集合后,可以發現確實是有非常明顯的效果,有3~10%的一個不同序列上的編碼增益。但是因為參考幀的數量較多,它的一些模式選擇性較多,復雜度增加也是較大。
#2. 率失真優化和RDO的優化工作
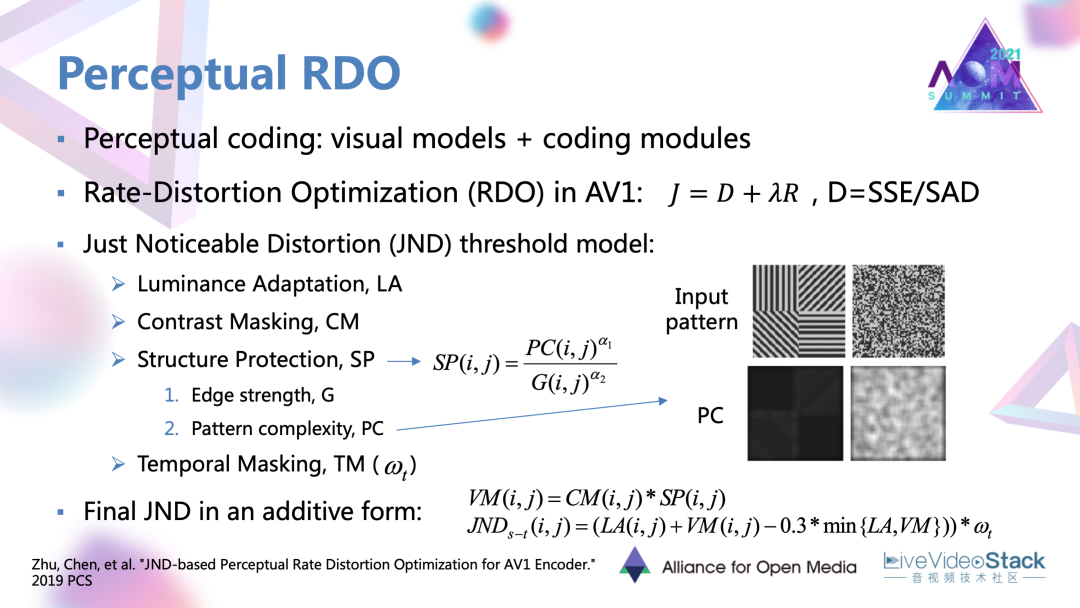
接下來是一個對于率失真優化和RDO的優化工作,是我們實驗室團隊和谷歌共同合作。它對原有的RDO進行了一個感知優化。整體的感知編碼的概念是想把很多反映人眼主觀感受的一些視覺模型。最常見的可能就是SSIM、VMAF這種質量指標模型。它與特定的編碼模塊相結合,達到一種去除感知冗余的目標。
我們這里的模塊是RDO。像AV1這種主流的編碼器中用到的拉格朗日RDO中使用的失真準則。它會用一些SSE/SAD這種很簡單的數學統計量去作為度量,再用于后續的一個推導。實際上這種統計量與主觀的感受的差距還是很大的,確實應該加入一些感知的因素。對此我們就加入了叫做恰可覺察失真的這個模型。
這個模型是表示大部分觀看者恰好感受到失真時的閾值,也代表了一種失真可容忍的閾值。當這種可容忍閾值越高的時表示人眼對于這塊區域的敏感度越低,有相反的關系。
在使用JND時,通常首先會生成一些考慮不同視覺感受的,不同視覺因素的因子。這里用到的就是亮度適應性、對比度掩蔽、結構性保護、時域掩蔽。它分別表示人眼對于不同的背景亮度、對比度,邊緣結構強度,運動強度的差異化敏感度。有了這樣的很多因子以后,采用像素JND,它會利用一種非線性疊加的形式,把各類因子結合起來,形成一個最終的整體模型。
2.1 JND模型與RDO更好融合的過程
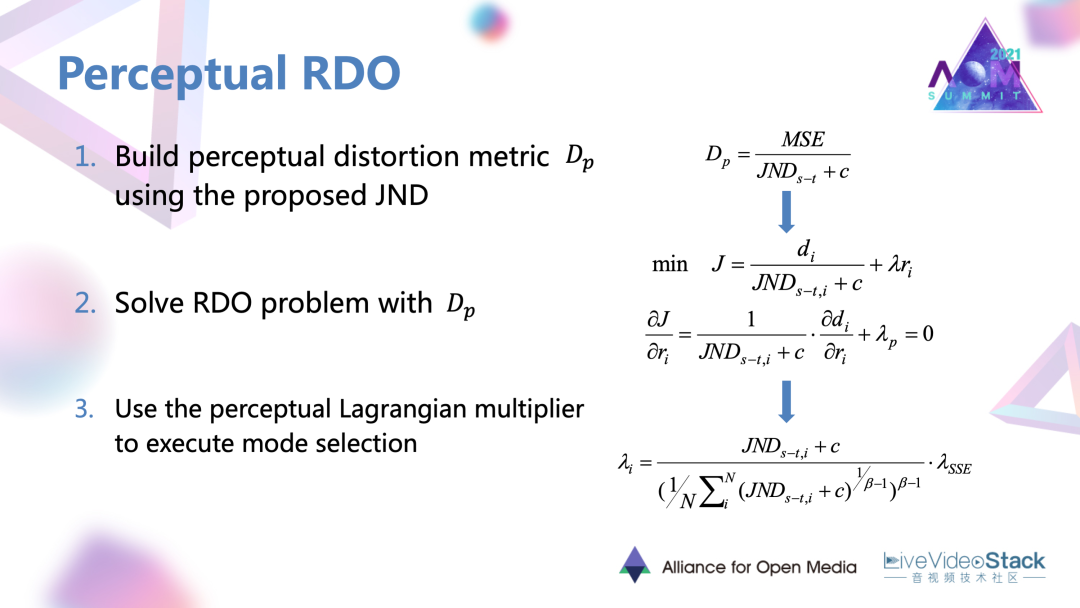
為了把得到的JND模型與RDO更好融合,進行了以下過程:首先是提出了一個感知的指標,它是將MSE還有整體JND結合起來形成的一個指標。它對于同類不同類的區域,如果存在相同的MSE失真,當它的JND閾值越大,對于人眼的敏感度越低時,它的感知失真應該更小,有比較定性的關系。
利用提出的感知指標作為RDO里面新的失真準則進行后續的數學推導,最后可以推導出一個包含JND,包含以原來SSE 失真為為推導的拉格朗日乘子的形式。生成一個感知的拉格朗日乘子,去調節每個編碼塊的編碼模式,將它往更偏向感知的方向去進行編碼。
2.2 JND模型與RDO融合增益情況
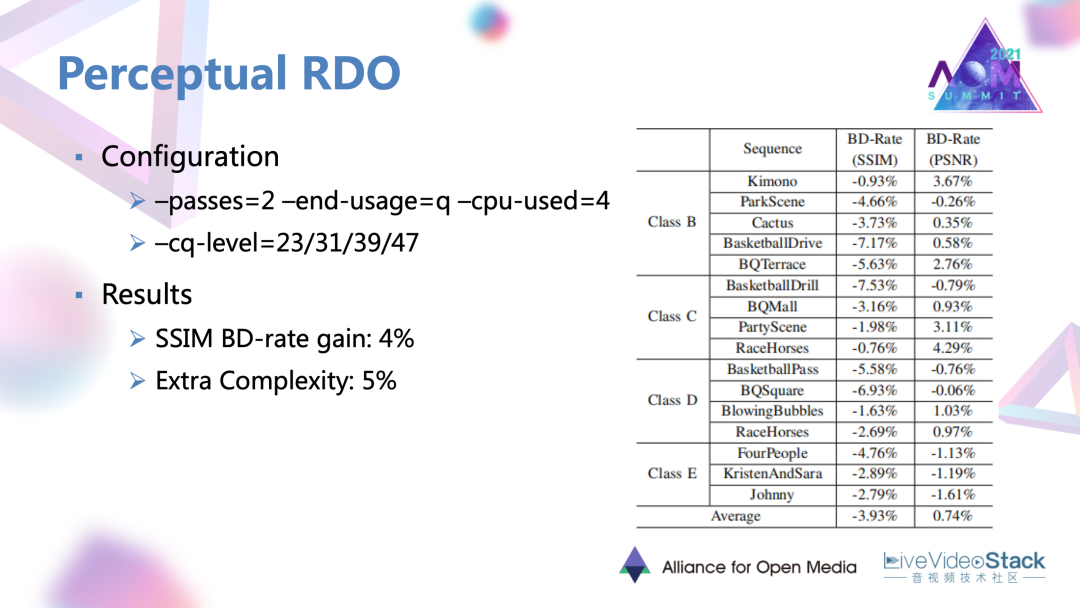
這個工作是在一個質量較高,速度又比較快的檔位進行測試的,得到了4%的 SSIM BD-rate增益。
同時它的額外復雜度因為JND計算非常簡便,額外復雜度并不高。
#3. AV1碼率控制模塊優化
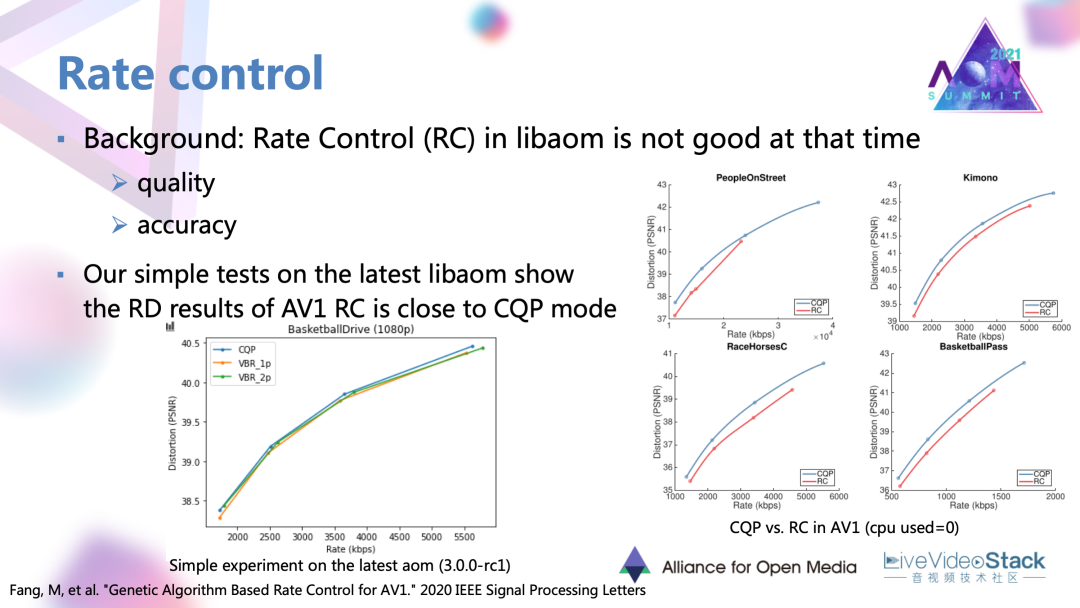
碼控模塊的目標是對序列各幀、各個編碼模塊去分配一定的碼率,使得實際輸出的碼率接近目標的給定碼率。這個工作里面首先也是對當時版本的碼率控制進行了測試,發現AV1當時版本的碼率控制在RD性能以及碼控準確度方面有所不足。我們也對目前版本的碼控方案進行了簡單的測試,發現它在性能上其實與 CQP已經比較接近。不過在碼控準確度方面還可以有一定的改進。
3.1 優化工作的思路
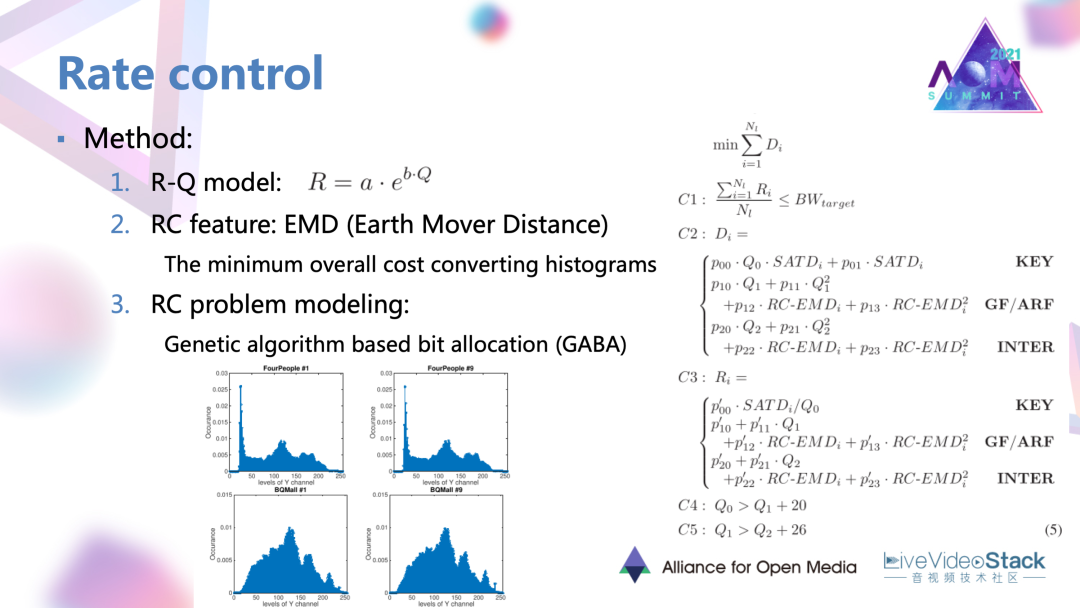
把碼控的一般過程去進行一個介紹。首先是要找到碼率和具體編碼參數的一個關系,才能作用到實際的編碼。在這個工作里面就找到了碼率與量化步長 RQ的模型。其次要確定一些失真準則或特征去作為碼率分配的標準。這也是找了一個叫做EMD的特征用于后續的碼率估計。最后在這兩點的基礎上就可以對碼率問題進行建模和求解。
3.2 碼率約束
一般的碼率碼控條件是在碼率約束下尋求最小的失真,在其他給定的失真或者特征情況下,限定一些額外的條件。最后的話這個工作使用了一種遺傳算法的求解方式。是找到了一組碼控的局部最優解去優化碼率控制。
3.3 增益情況
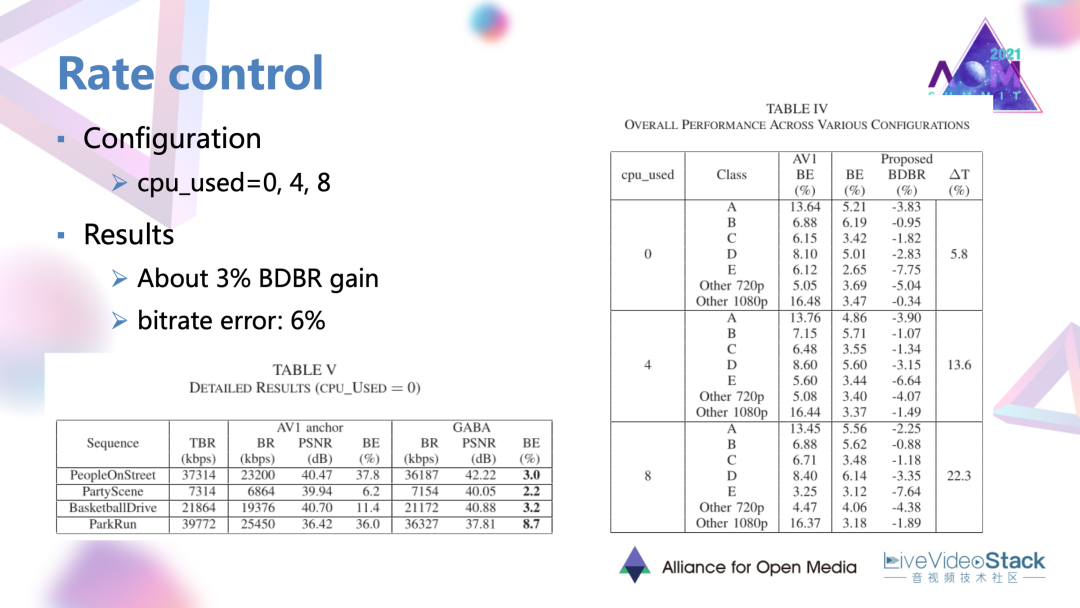
這個方法是在三種編碼模式下取得了平均百分之三的增益,但是還會有一定的碼控誤差。
#4. AV1的環路濾波優化

接下來的話就說一下AV1的環路濾波的優化。AV1里面已經有三種濾波器,還包括一種叫做電影(紋理)顆粒合成的,后處理的模塊。這幾個濾波器或者模塊在相應的位置以一種串聯的方式對單幀進行增強的。
4.1 基于CNN的環路濾波
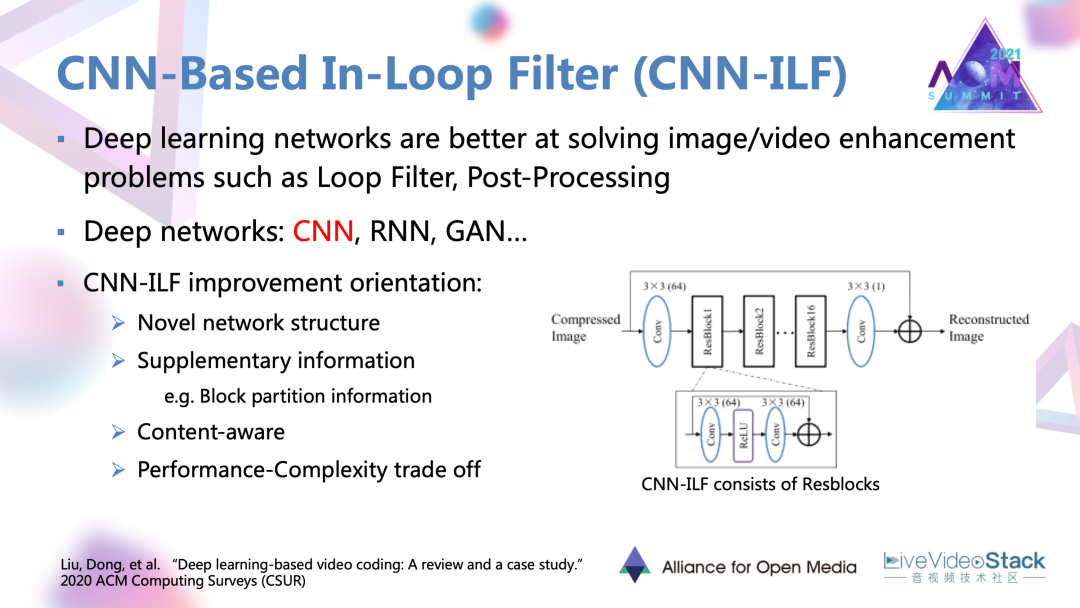
近年來有很明顯的趨勢,就是深度學習網絡越來越多的被用在環路濾波中,可以取得非常大的增益。編碼的環路濾波更多的是基于CNN的環路濾波,濾波器也有很多優化的方向。最主要是第一種設計一些新的網絡架構。上圖右側給出的以Resblock為單位的殘差網絡,現在越來越多的被作為一種基本架構去優化。除此之外,利用輔助的編碼信息,還有基于內容自適應去進行深度學習濾波,對這種深度網絡進行復雜度的優化。
4.2 案例
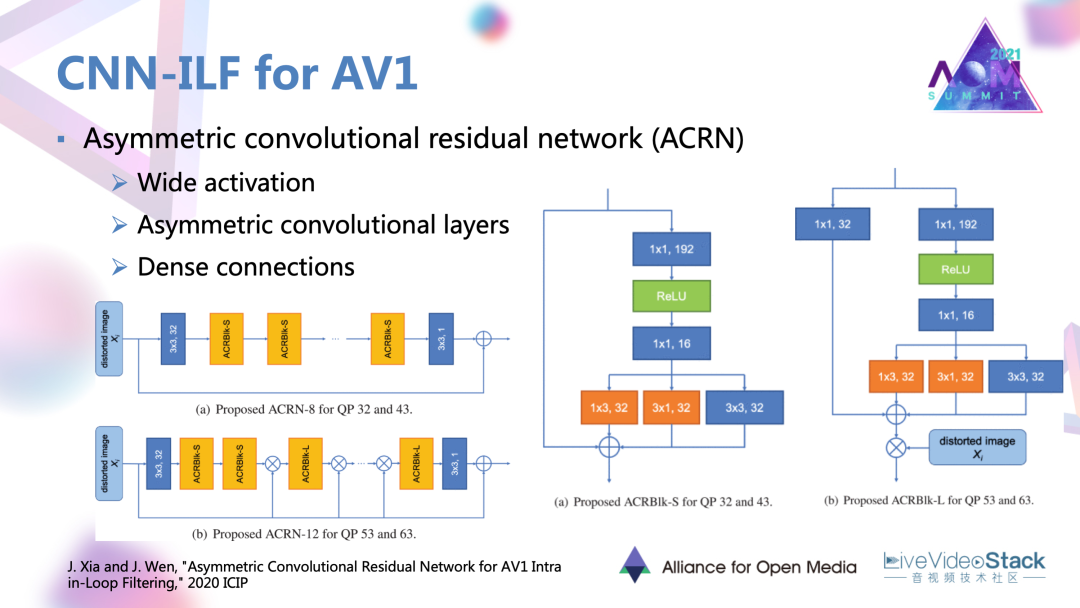
分享以去年ICIP的一個工作為例,它設計了一種非對稱的卷機殘差網絡-ACRN,在網絡里面還有這樣的幾種設計,例如寬激活,還有非對稱的卷積層,以及稠密連接。這幾種設計可以更細致的捕獲到底層的一些特征,捕獲一些方向性的特征,以及在網絡中不斷的去強化輸入或者說失真圖像本身的一些信息,比如說編碼的塊信息,達到上述效果。
4.3 CNN濾波器增益效果
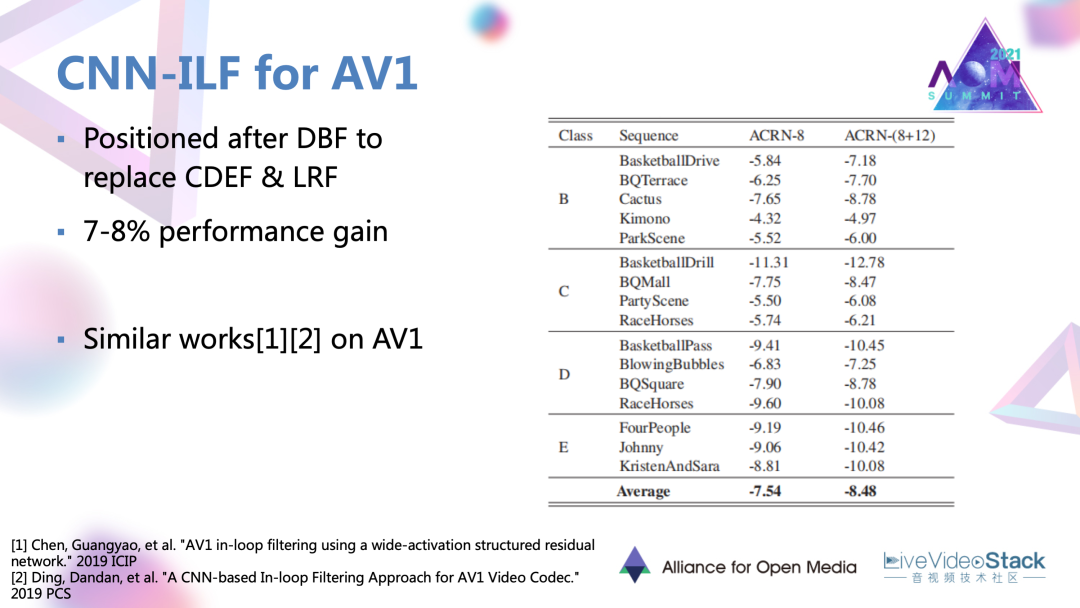
通過CNN濾波器設計替代 AV1新引入的兩種濾波器,可以達到7~8%的一個編碼增益,相對于其他模塊是比較高的增益。
#5. 紋理合成性能優化
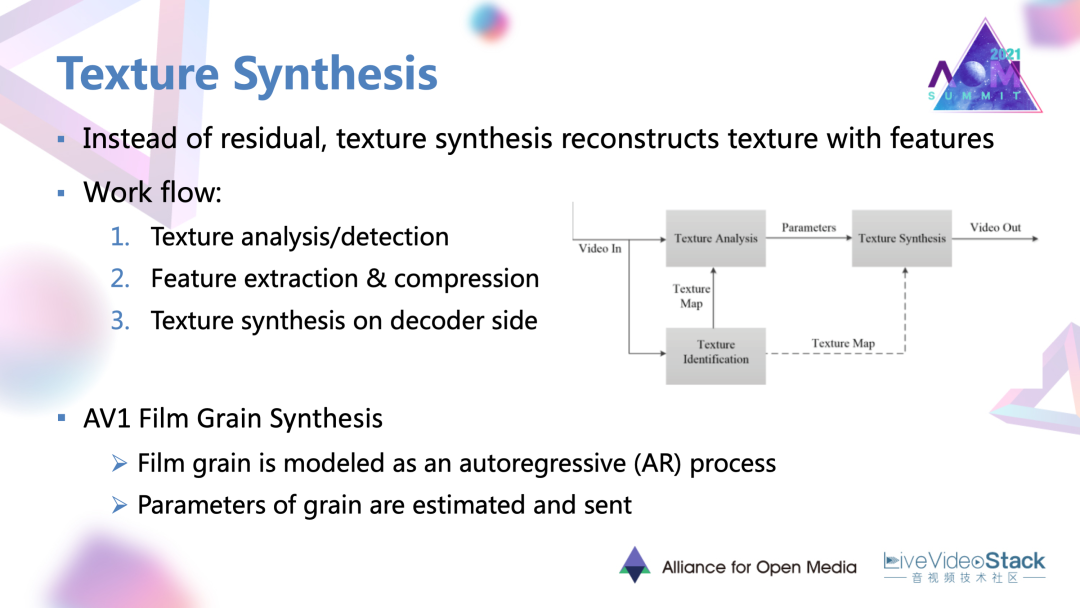
性能優化里面的最后一個方向,紋理合成。相比于一些簡單靜態的場景,復雜的紋理在基于殘差塊的編碼框架下是非常難編的。所以紋理合成要做的是直接利用紋理本身的特征去進行編碼和恢復。
它的一個常規的工作流主要包含首先是對紋理進行探測,那些被認為是紋理的區域,就直接去對特征進行編碼,并傳到解碼端,在解碼端也是利用紋理本身的這種特征去還原和合成紋理。例如剛剛提到的AV1電影顆粒合成也是一種紋理合成的方法。
這個方法中電影的顆粒被建模為是一種叫做自回歸AR的過程,AR的過程里面的一些系數就可以作為顆粒的參數或者表達在解碼端去合成逼真的電影顆粒。
5.1 AV1上的紋理合成工作
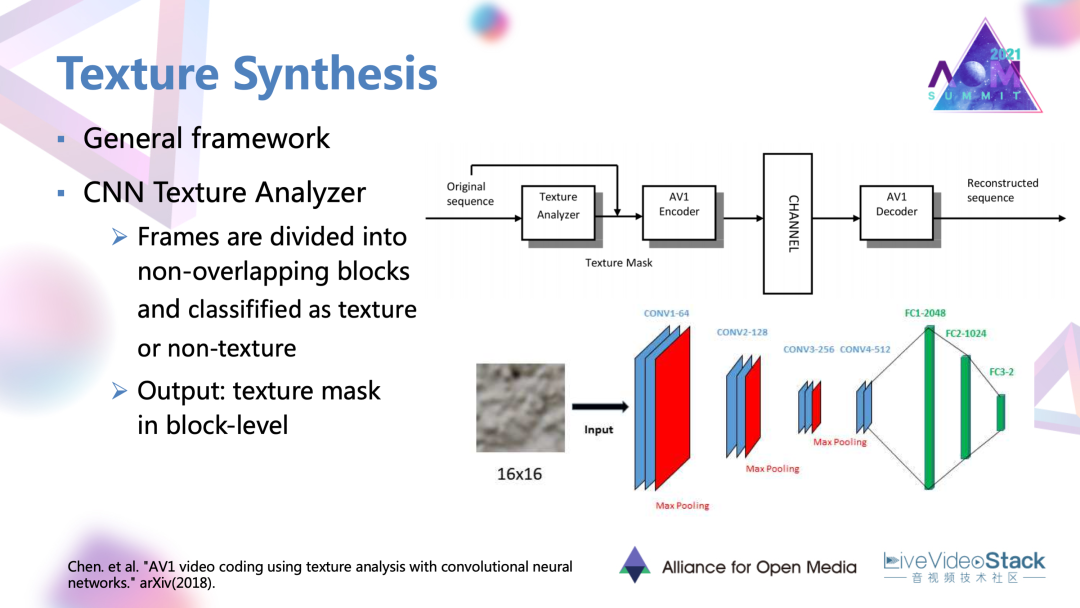
這里要介紹的一個在AV1上的紋理合成工作,也采用了比較常規的框架。首先是一個CNN的紋理分析器。它將原始幀去分割成非重疊的小塊,每個小塊過分析器得到二分類的判斷是否為紋理的標簽。最后可以在整幀上得到一個基于塊級別的紋理mask。在mask指導下,被認為是紋理的區域就直接通過紋理模式編碼而不再進行基于殘差塊的編碼。
5.2 AV1上的紋理合成工作過程
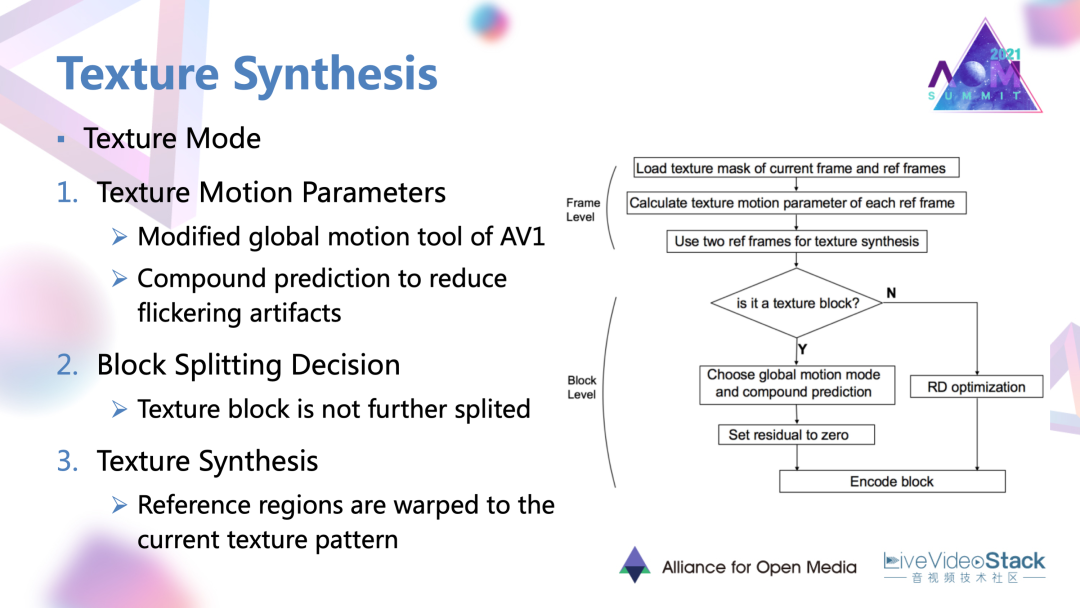
它的一個過程是這樣的:首先是估計紋理的運動參數。這個參數也是在一種復合或說多參考幀的預測下得到的,也是為了降低紋理合成的閃爍以及塊效應等偽像。運動參數也是被編碼和傳到解碼端的,在解碼端一些用常規編碼的參考區域,就在這種運動參數的指導下進行一種warp變換,扭曲成當前區應有的這種紋理樣式達到紋理合成的效果。
5.3 紋理合成的工作結果
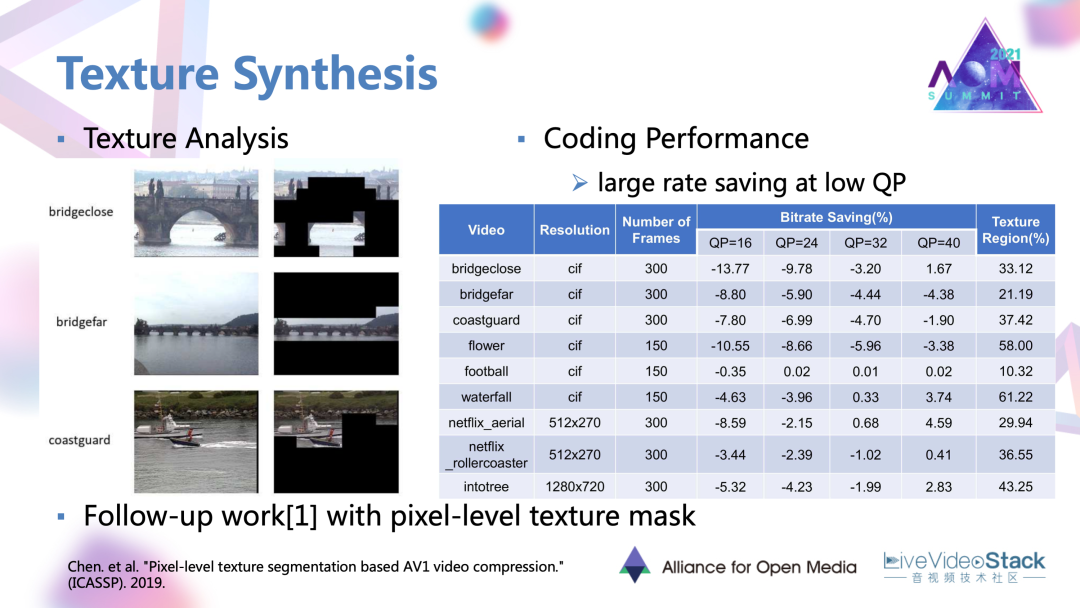
可以看到它工作給的一些結果,在低QP,高碼率的情況下,這種以參數替代殘差塊的編碼方法或者說合成方法是可以取得一定的碼率節省的。
#6. AV1復雜度優化

接下來是復雜度優化方面,AV1新增的很多編碼工具實際上帶來了大量的編碼時間,所以對AV1去進行復雜度的優化很有必要,而且會帶來很大的收益。目前看到在AV1上的復雜度優化工作主要包含塊劃分、幀間預測、變換搜索方面的加速工作。盡管這些加速工作是針對不同模塊,它們也有一些比較共通的路徑。
主要有這樣三種:
第一點是去人為的定義一些特征,并且基于這些特征手工制定相關的快速決策準則的傳統方法。
第二點是人為設定的特征輸入網絡去學習的機器學習方法。
第三點是直接定義輸入輸出,讓網絡自己去學習決策過程的深度學習方法。
目前看到的AV1上的工作主要集中于前兩條路徑。
6.1 一個塊劃分的加速方法

首先要介紹的是一個塊劃分的加速方法,這個方法可以算作一個傳統的路徑。比較特殊的點在于它是基于跨分辨率的加速方法。首先是對同一視頻在不同分辨率下的塊劃分情況進行了一個查看,發現精細的分割區域其實是共通的或者說相似的,主要是一些復雜的紋理以及快速運動的物體。
基于這個現象,這個文章中就假定了一種特征f,它是表現細節的精細度以及物體運動快慢程度的一個特征。有了這樣一個特征后,每個塊被劃分的概率或者趨勢E(X),與這種特征有一個正相關的關系,進一步的去假定這個特征。f有一個分辨率不變性以后,那f就可以與兩種或者多種分辨率的劃分結果。
比如說E(X1)、E(X2)有兩種映射關系,比如說g1和g2。進一步把這個f作為中間連接的一個橋梁以后,最終可以達到這樣一種目的:在得到一個低分辨率的塊劃分結果E(X2)以后,就可以通過反映射的方式轉換為高分辨率的劃分結果。通過推導后,實際上,f就并不用具體的去提取某一種特征,只是在推導里面被用到。
6.2 應用場景
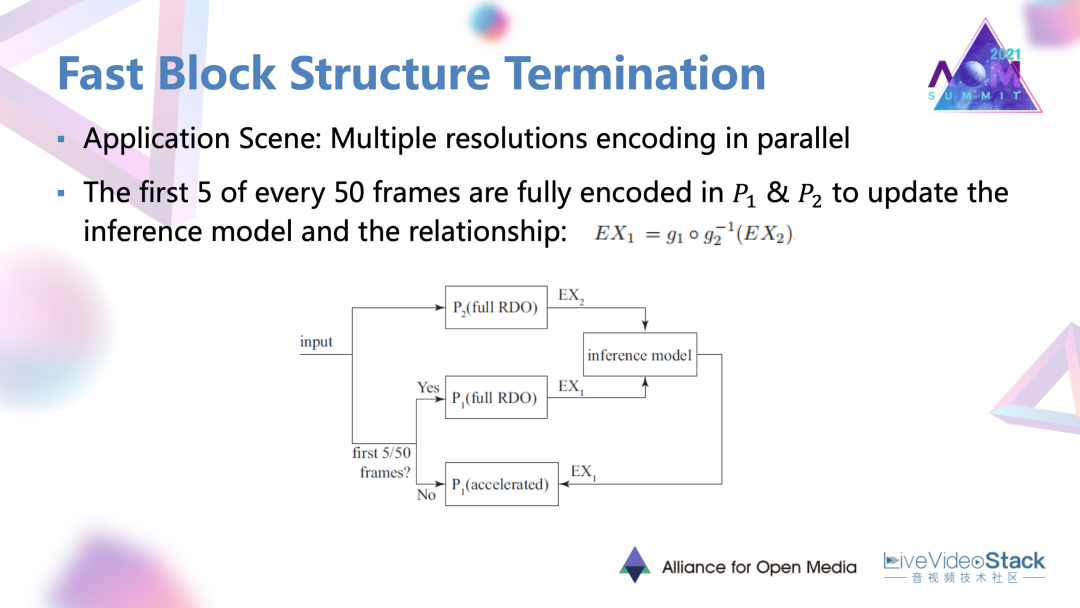
理論去具體去用的時候會存在應用場景。這個場景就是多分辨率同時編碼的一個情況。這種場景在一些流媒體的服務器端是經常存在的。在具體實現的時候對于編碼的每50幀,所有的50幀都是對于低分辨率,都是常規的進行RDO去進行完整編碼,對于50幀里的前5幀的高分辨率編碼,它也是進行完整的 RDO過程,然后會得到 E(X1)以及低分辨率的E(X2)的劃分結果。
首先要通過一個influence Model去推理出這兩種劃分結果的一個映射關系。基于前5幀的一個結果,對于之后的90%,大概是45幀,利用 influence結果以及實際編碼的低分辨率劃分結果,直接去推導出高分辨率的劃分結果,不再進行完整的RDO,達到一個加速的目的。
6.3 節省效果

方法最終是實現大約30~40%的時間節省。這里還設定了一個預估錯誤的閾值,閾值越高的話,就會導致比較大的碼率損失。
#7. 幀間預測加速工作
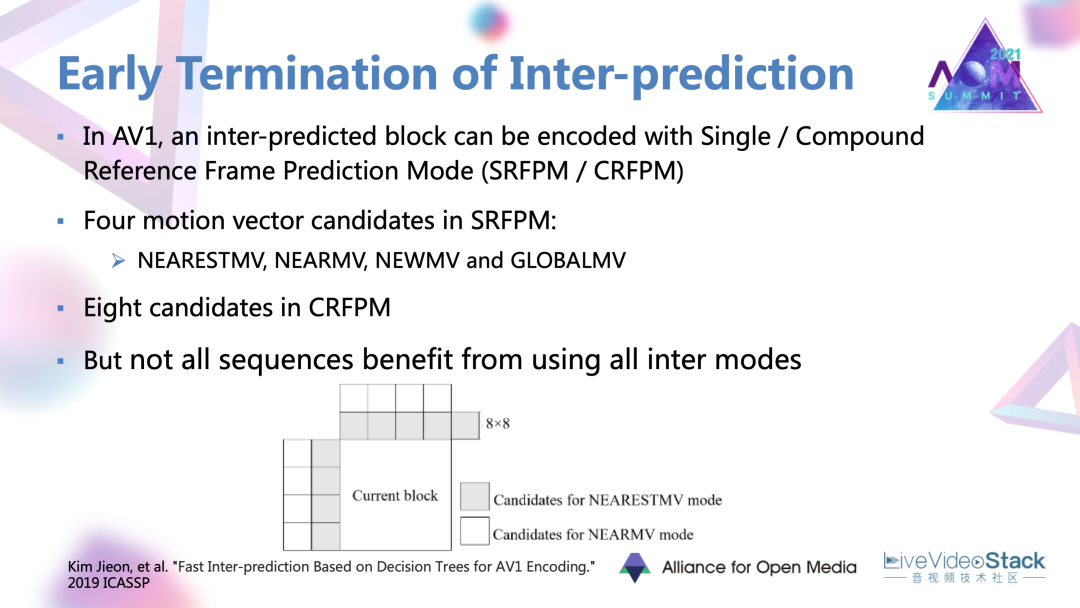
在AV1里面。目前提供了基于單參考幀,以及混合的基于雙參考幀的幀間預測模式。在這兩種模式下都有一些很豐富的運動向量。這篇文章的出發點,發現并不是所有的序列都會因為這些豐富的候選模式而產生很大的編碼增益的,可以進行一些簡化。
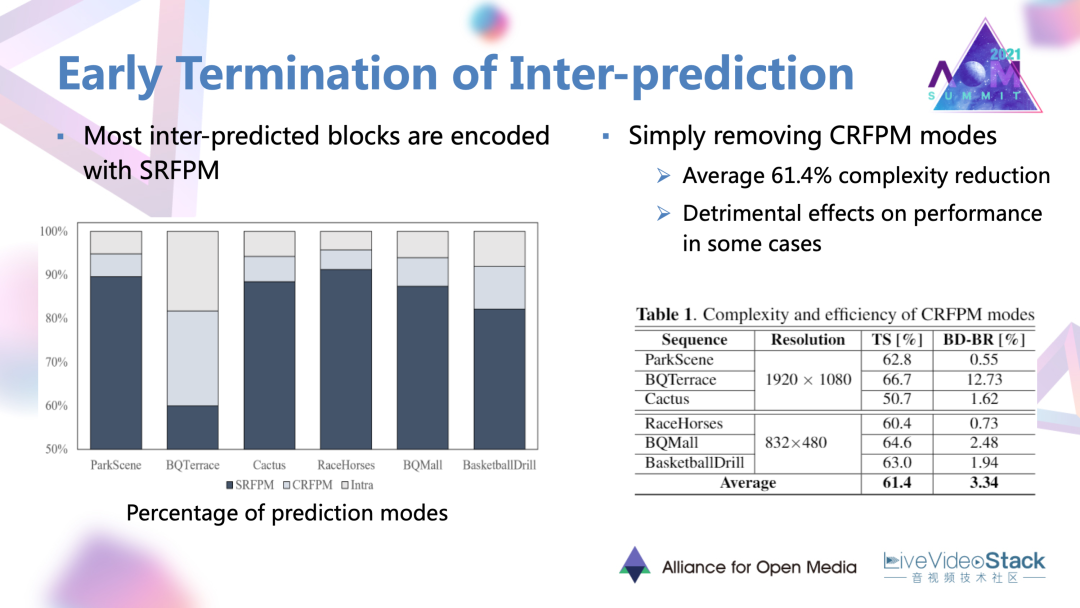
文章首先對各個序列的編碼結果進行了評估,發現了大部分的幀間預測塊都是以單參考幀的模式被編碼的,所以一個很直接很簡單的嘗試就是去除混合預測模式。結果發現會有很大的編碼復雜度的降低,但同時對于一些序列會產生很嚴重的性能損失。還是要找一種能保住性能的穩妥做法。
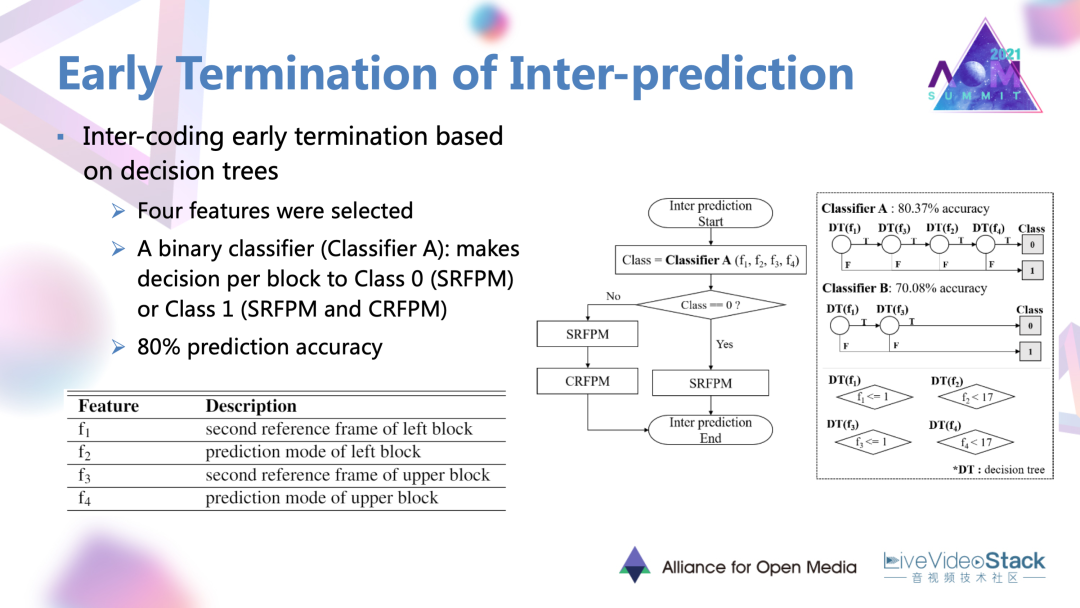
文章中也是使用了基于機器學習的決策樹的網絡。在網絡里面首先設定了4種特征輸入網絡。特征分別是當前塊相鄰的左塊與上塊的預測模式,左塊、上塊在第二參考幀中的相應內容。特征輸入以后,一個二分類的分類器就對每一塊進行決策,決定當前塊是進行單參考幀的預測模式,還是遍歷兩種幀間預測模式。這樣一個分類器可以最終達到80%的預測精度。
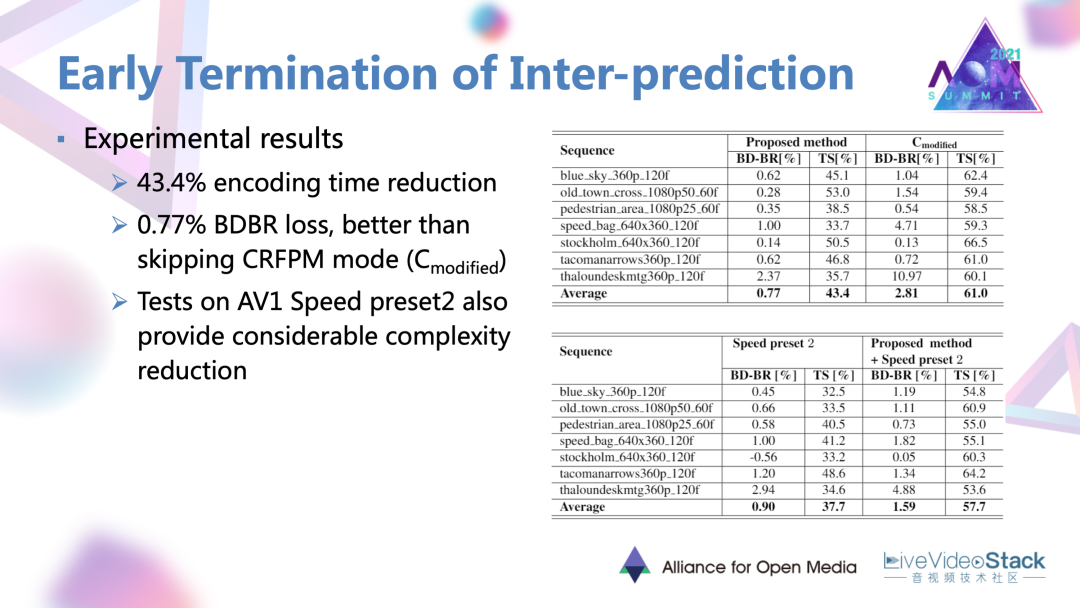
通過這樣一種做法相比于原有的AV1編碼器可以達到43%的編碼時間降低,以及0.77%的比較小的性能損失。
#8. 變換搜索加速方法
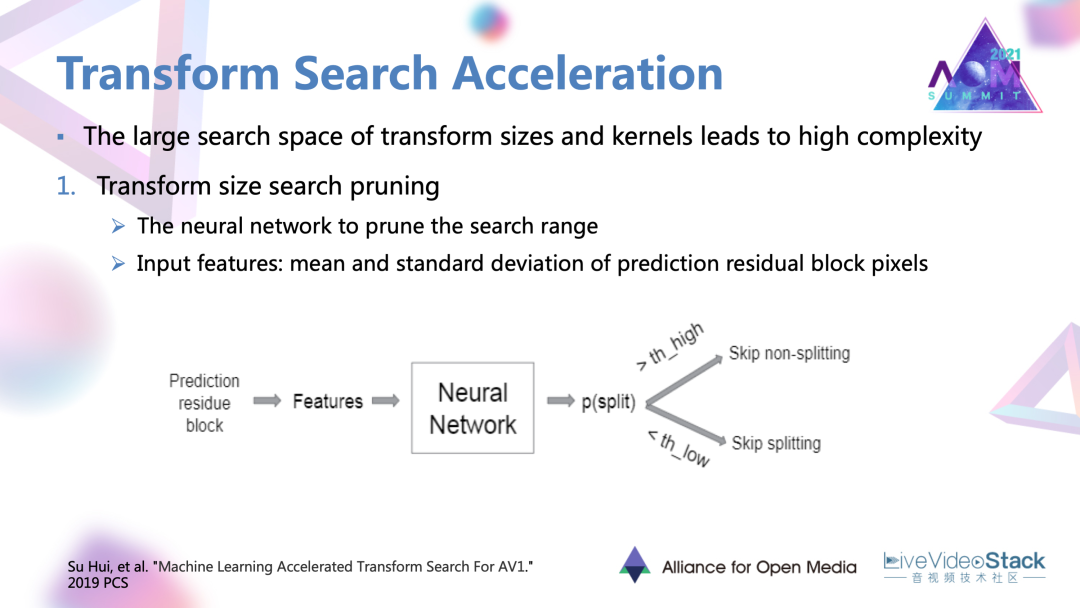
最后是一個變換搜索的加速方法。AV1提供了很豐富的變化和帶來了很大的復雜度。這一個工作是對變換尺寸以及變換核搜索進行一個裁剪。
首先是尺寸的裁剪,它對于每一個預測殘差塊去提取均值以及標準差這兩個特征,輸入到一個相應的神經網絡里面去學習,并最后輸出一個當前塊是否應該被分割的數值。這一個數值會與已經設定好的兩端的閾值進行比較,當超過閾值的時候可能就不再選取比較大或者比較小的變化尺寸。
第二點就是變化核的裁剪。
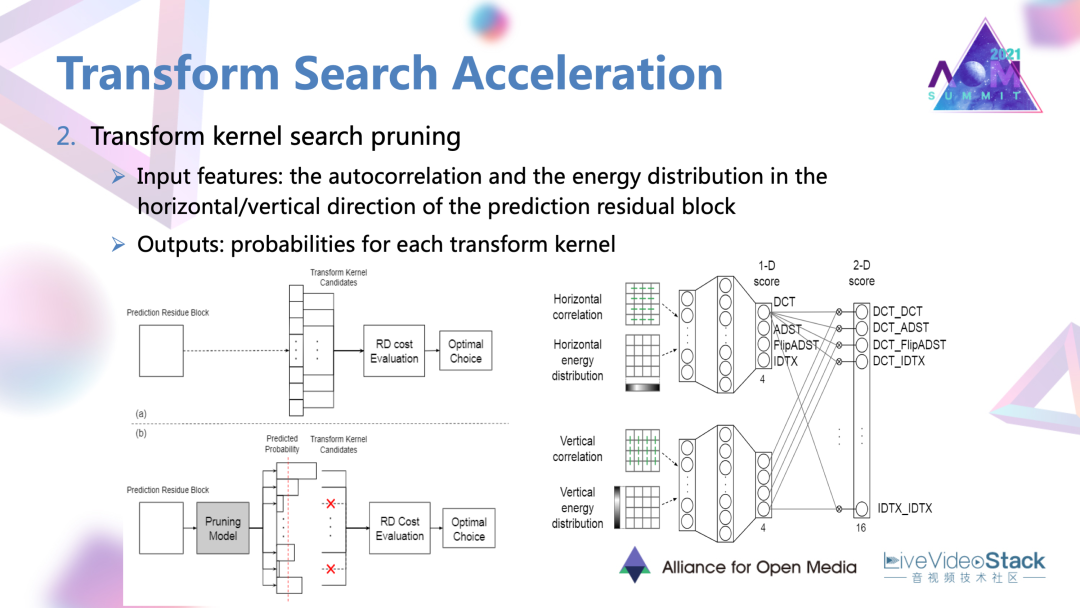
這里的做法就是對每一個殘差塊的縱向和橫向兩個方向分別設置兩個網絡。網絡會輸入一些自相關以及能量分的特征。兩個子網絡的一些輸出進行融合以后,會最終對每一個可能的變換核被選中的概率進行一個評估。在具體的編碼中,如果說被評估的是被選中概率很低的一些變化核,可能直接被舍棄,去達到一個簡化的目的。
8.1 節省效果

最終這樣一個簡化方法可以在不同分辨率下達到大概10%到30%不等的時間的節省。對于變換的簡化,性能損失比較小,在0.1%左右的程度。
#9. 總結

學術界的一些優化工作實際上也涵蓋了編碼過程的大部分模塊。很明顯的趨勢就是許多深度學習的網絡或者方法已經開始與編碼的模塊進行結合,并取得了很多不錯的收益。但是在標準編碼器中,這種AI與Codec到底應該結合到怎樣的一個程度還是需要被探究和摸索的。所以也讓我們期待AOM聯盟的下一代編碼器AV2吧。
以上就是我所有的分享,謝謝大家!
編輯:jq
-
編碼器
+關注
關注
45文章
3597瀏覽量
134171 -
開源
+關注
關注
3文章
3254瀏覽量
42408 -
DCT
+關注
關注
1文章
56瀏覽量
19852
原文標題:學術界AV1編碼優化技術的進展
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
夸克學術搜索受熱捧,成年輕人PC端AI應用首選

如何優化base64編碼的性能
第三屆OpenHarmony技術大會在上海成功舉辦
寶塔面板Docker一鍵安裝:部署GPTAcademic,開發私有GPT學術優化工具
德克薩斯大學將創建一個學術界最強大的生成性人工智能研究中心
AMD & Vindral:全球首個8K 10bit HDR直播方案亮相
中圖儀器與合肥工業大學共探3D顯微形貌測量技術
科技前沿 |?學術交融:中圖儀器與合肥工業大學共探3D顯微形貌測量技術

微軟Teams應用整合AV1編解碼器,降低帶寬需求,提升畫面清晰度
谷歌計劃在Android系統升級中采用libdav1d替換libgav1,提高AV1視頻性能
Vulkan 1.3.277新增AV1 Decode擴展,提升視頻解碼質量
Ansys入選“2023世界智能制造十大科技進展”榜單





 工商網監
工商網監
評論